MongoDB

MongoDB
NoSQL 데이터베이스의 한 종류인 Document 데이터베이스로서 거대한 데이터베이스라는 의미의 Humongous(거대한) DB를 줄여 MongoDB라는 이름을 가진 오픈 소스 데이터베이스
- 오픈소스
- 비관계형(NoSQL)
- Document-Oriented 데이터베이스
NoSQL이란?
- Not Only SQL의 약자로, 표준 RDBMS처럼 표준화된 구조적 질의 언어(SQL)가 없거나 관계를 갖지 않는 데이터베이스를 총칭하는 말
NoSQL의 일반적인 특징
- 각 DBMS별로 차이가 있지만, 일반적으로 아래와 같은 특징을 가짐
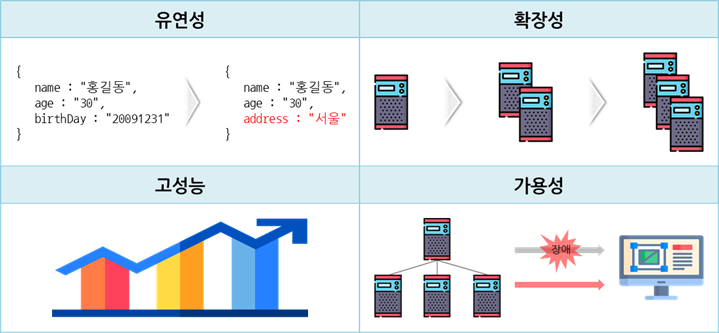
- 유연성 : 스키마 선언 없이 필드의 추가, 삭제가 자유로운 Schema-less 구조
- 확장성 : Scale-Out에 의한 서버 확장 용이
- 고성능 : 대용량 데이터 처리 성능 뛰어남
- 가용성 : 여러 대의 백업 서버 구성이 가능해 장애 발생 시, 무중단 서비스 가능
NoSQL의 종류
- NoSQL은 RDBMS가 아닌 모든 형태의 DB를 의미하지만, 자주 사용되는 유형은 아래와 같다.
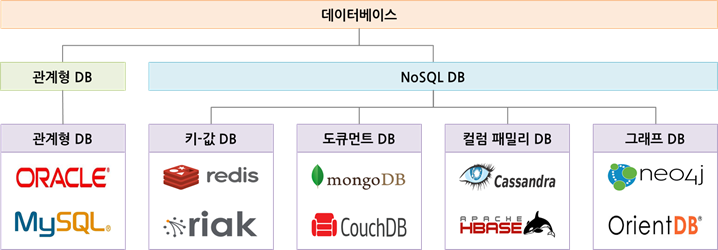
- 키-값 DB : 키와 값으로 구성된 배열 구조의 데이터베이스로 NoSQL DB 중 가장 단순한 구조
- 도큐먼트 DB : 필드와 값의 형태로 구성된 데이터를 JSON 포맷으로 관리하는 데이터베이스로 NoSQL 데이터베이스 중 가장 인기가 높음
- 컬럼 패밀리 DB : 컬럼과 로우로 구성된 데이터베이스로 컬럼은 이름과 값으로 구성되고 로우는 각기 다른 컬럼으로 구성이 가능
- 그래프 DB : 노드와 관계로 구성된 데이터베이스로, 근접한 객체를 모델링할 목적으로 설계됨
NoSQL 종류별 장단점
| 구분 | 키-값 DB | 도큐먼트 DB | 컬럼 패밀리 DB | 그래프 DB |
|---|---|---|---|---|
| 장점 | 빠른 성능 | 다양한 데이터 구조 처리 | 대량의 데이터 처리 | 복잡한 관계 처리 |
| 단점 | 복잡한 구조 처리 어려움 | 대량 데이터 조회 성능 낮음 | 복잡한 관계 처리 어려움 | 데이터 크기가 커지면 확장 및 관리가 어려움 |
RDBMS vs NoSQL
| 구분 | RDBMS | NoSQL |
|---|---|---|
| 데이터 모델 | 고정 행과 열이 있는 테이블 | Key-Value, Document, etc… |
| DB 종류 | Oracle, MySQL, postgreSQL, etc… | Redis, MongoDB, Cassandra, etc… |
| 확장성 | 수직 | 수평 |
| 인터페이스 | SQL을 통해 데이터 저장 및 검색 가능 | 쿼리 외 다양한 API를 통한 데이터 저장 및 검색 가능 |
| 장점 | 데이터 중복 배제로 데이터 이상 발생 및 용량 증가 최소화 | 쿼리 프로세싱이 단순화되어 대용량 데이터 처리 성능 향상 |
| 단점 | 조인이 복잡한 경우 쿼리 프로세싱이 복잡해져 성능 저하 | 데이터 중복에 의해 데이터 일관성 저하 및 용량 증가 |
| 사용 목적 | - 데이터 무결성 및 일관성이 중요한 트랜잭션 업무 - 복잡한 계산 및 실시간 데이터 정합성이 중요한 업무 | - 로그 및 이력 등의 단순 기록형 업무 - 초당 동시 처리량이 중요한 업무 |
MongoDB 상세
MongoDB 용어
| RDBMS | Mongo DB |
|---|---|
| Database | Database |
| Table | Collection |
| Row | Document |
| Index | Index |
| DB server | Mongod |
| DB client | mongo |
| Primary Key | Primary Key(_id) |
1. Document
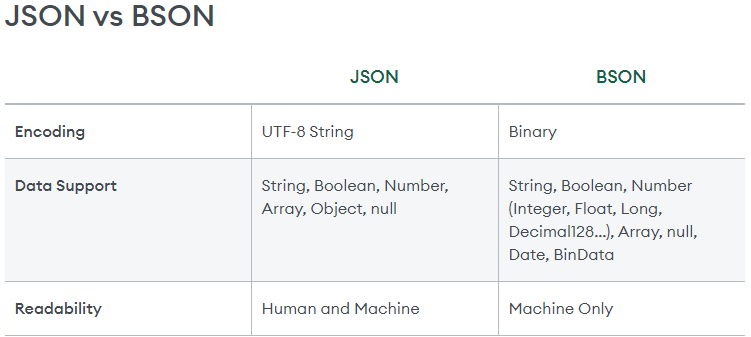
- MongoDB는 데이터를 BSON(Binary JSON) 형태로 저장함
- BSON은 JSON과 유사하게 필드-값의 쌍으로 구성됨
- BSON은 JSON의 이진 직렬화 표현이지만, 더 많은 데이터 타입을 지원함
- 모든 Document는 크기가 16MB보다 작아야 함
Document 구조
{
field1: value1,
field2: value2,
field3: value3,
...
fieldN: valueN
}- 가장 간단한 Field-Value 구조
var mydoc = {
_id: ObjectId("5099803df3f4948bd2f98391"),
name: { first: "Alan", last: "Turing" },
birth: new Date('Jun 23, 1912'),
death: new Date('Jun 07, 1954'),
contribs: [ "Turing machine", "Turing test", "Turingery" ],
views : NumberLong(1250000)
}- 필드의 밸류는 BSON이 지원하는 모든 데이터 타입이 가능함
BSON 데이터 타입 (링크)
| 타입 | 번호 | 별칭(Alias) | 비고 |
|---|---|---|---|
| Double | 1 | "double" | |
| String | 2 | "string" | |
| Object | 3 | "object" | |
| Array | 4 | "array" | |
| Binary data | 5 | "binData" | |
| Undefined | 6 | "undefined" | Deprecated. |
| ObjectId | 7 | "objectId" | |
| Boolean | 8 | "bool" | |
| Date | 9 | "date" | |
| Null | 10 | "null" | |
| Regular Expression | 11 | "regex" | |
| DBPointer | 12 | "dbPointer" | Deprecated. |
| JavaScript | 13 | "javascript" | |
| Symbol | 14 | "symbol" | Deprecated. |
| JavaScript code with scope | 15 | "javascriptWithScope" | Deprecated in MongoDB 4.4. |
| 32-bit integer | 16 | "int" | |
| Timestamp | 17 | "timestamp" | |
| 64-bit integer | 18 | "long" | |
| Decimal128 | 19 | "decimal" | |
| Min key | -1 | "minKey" | |
| Max key | 127 | "maxKey" |
- 필드 이름은 항상 String 형태이어야 함
- 배열의 경우
<array>.<index>형태로 인덱스 값에 접근 가능{ ... contribs: [ "Turing machine", "Turing test", "Turingery" ], ... }- 위와 같은 Document가 있을 때
contribs.2로 접근하면 “Turingery”가 선택됨 - 더 자세한 내용은 공식 문서 참고
- 위와 같은 Document가 있을 때
- 또한 Document 안에 Document를 가지는 Embedded Document를 지원하는데, 이를 접근하는 방법도 배열과 유사하게
<embedded document>.<field>로 하면 됨{ ... name: { first: "Alan", last: "Turing" }, contact: { phone: { type: "cell", number: "111-222-3333" } }, ... }- 위와 같은 Document에서 name 필드의 last 필드 값을 찾으려면
name.last - contact 필드의 phone 필드의 number 필드 값을 찾으려면
contact.phone.number - 더 자세한 내용은 공식 문서 참고
- 위와 같은 Document에서 name 필드의 last 필드 값을 찾으려면
임베디드 방식/레퍼런스 방식
- mongoDB 데이터 모델링 과정에서 데이터의 관계를 표현하는 두 가지 방식
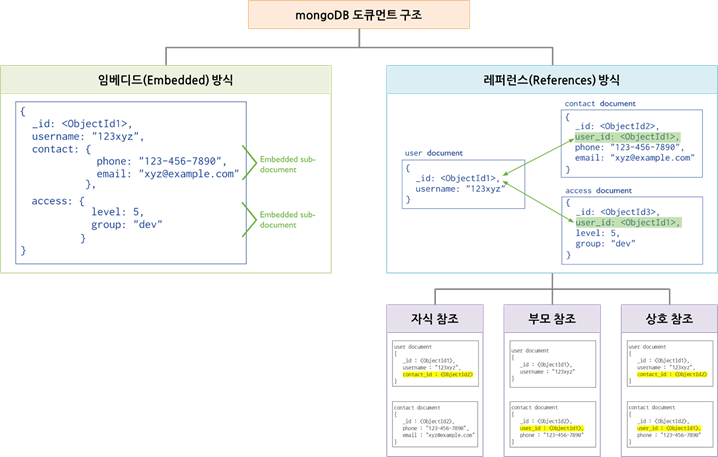
임베디드 방식
- 관계를 갖는 데이터 집합을 단일 도큐먼트에 포함하여 저장하는 방식
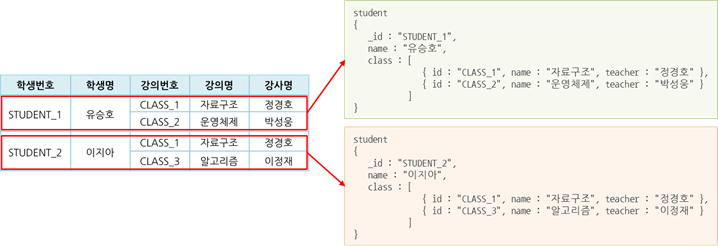
- 동일한 데이터를 각 도큐먼트에 저장하여 구조를 단순화하는 반정규화 모델
| 내용 | |
|---|---|
| 장점 | - 데이터 관리가 직관적 - 쿼리가 단순함 - 조회 성능이 좋음 |
| 단점 | - 단일 도큐먼트의 크기가 16MB를 넘을 수 없음 - 데이터 불일치 문제 발생 가능성 있음 - 데이터 변경, 추가가 많으면 성능 저하 |
레퍼런스 방식
- 도큐먼트의 고유 식별자를 다른 도큐먼트의 참조키로 지정하여 연결 관계를 맺어주는 방식
- RDBMS의 외래키를 사용한 참조와 유사함
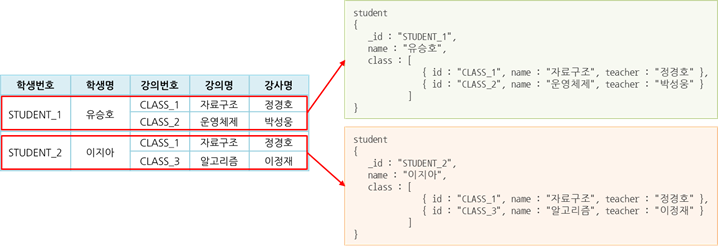

| 내용 | |
|---|---|
| 장점 | - 데이터가 중복되지 않도록 분리 후 참조하므로 데이터 불일치 발생 가능성 적음 - 데이터가 분리되어 도큐먼트의 크기 증가가 작음 - 데이터 수정, 추가가 도큐먼트 구조에 미치는 영향이 적음 |
| 단점 | - 참조가 많은 도큐먼트나 대규모 도큐먼트를 조회하는 경우 2차 쿼리로 인한 처리량 증가로 조회 성능이 떨어짐 - 참조 정보를 정확하게 관리하지 않는 경우 참조 정보 소실에 의한 데이터 정합성 문제 발생 가능 |
- 참조 방식에 따라 자식 참조, 부모 참조, 상호 참조가 있음

- 자식 참조 : 부모 도큐먼트에서 관계를 갖는 자식 도큐먼트의 식별자를 참조키로 저장
- 부모 참조 : 자식 도큐먼트에서 관계를 갖는 부모 도큐먼트의 식별자를 참조키로 저장
- 상호 참조 : 부모와 자식 모두에서 서로의 식별자를 참조키로 저장
임베디드 vs 레퍼런스
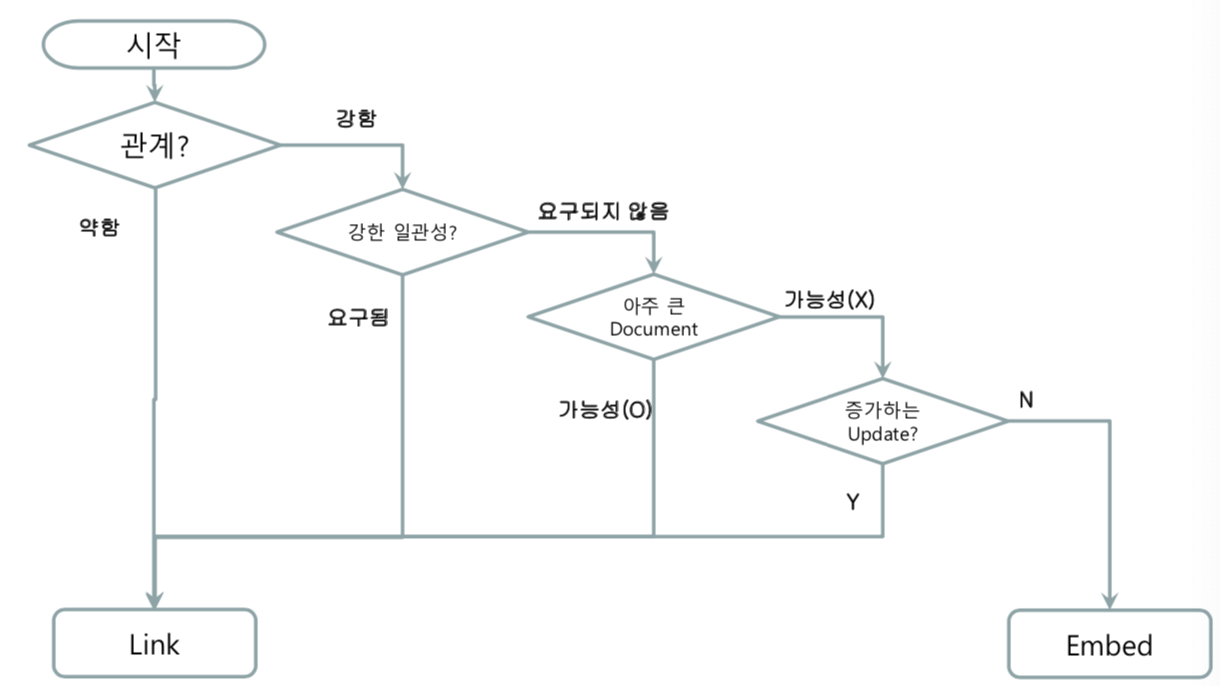
2. Collection
- RDBMS의 테이블과 같은 개념으로, 용도가 같거나 유사한 도큐먼트들의 그룹을 묶는 단위를 의미
- 일반 컬렉션, 캡드 컬렉션, TTL 컬렉션, 시스템 컬렉션으로 나뉨

각 컬렉션의 특징
| 종류 | 내용 |
|---|---|
| 일반 컬렉션 | - 가장 일반적으로 사용되는 컬렉션 |
| 캡드 컬렉션 | - 캡드 컬렉션은 고정된 크기를 갖는 컬렉션으로 높은 성능의 로깅 기능을 위해 설계됨 - 명령어 : db.createCollection( "log", { capped : true, size : 100000, max : 100 } ) 1) "log" 컬렉션 생성 시 캡드 옵션을 설정하고 최대 사이즈와 최대 도큐먼트 수를 설정함 2) size : 최대 저장크기로 단위는 Byte임 3) max : 최대 도큐먼트 수로 옵션 생략이 가능함 - 도큐먼트 추가 시 디스크 공간이 없는 경우 가장 오래전에 추가된 도큐먼트부터 덮어쓰기 함 - 오래된 데이터를 수동으로 삭제하는 작업을 없애 데이터 관리가 편리함 - 로깅을 위해 만들어져 사용자가 임의로 삭제하거나 업데이트할 수 없음 |
| TTL 컬렉션 | - TTL 컬렉션은 특정 시간이 경과한 도큐먼트를 자동으로 삭제하는 컬렉션으로 TTL 인덱스에 의해 지원되는 기능임 - 명령어 : db.member.createIndex( { modify_date : 1 }, { expireAfterSeconds : 3600 } ) 1) modify_date 필드에 인덱스를 생성하여 1시간(3600/60/60)이 지난 도큐먼트는 삭제함 2) expireAfterSeconds : 도큐먼트의 유지시간을 초 단위로 설정함 - "_id" 필드 또는 이미 다른 인덱스가 있는 필드는 TTL 인덱스를 가질 수 없음 - 캡드 컬렉션인 경우 TTL 인덱스를 가질 수 없음 - 단일 인덱스만 사용 가능하며 복합(Compound) 인덱스를 가질 수 없음 |
| 시스템 컬렉션 | - mongoDB 내부에서 사용되는 컬렉션으로 사용자가 지정하여 사용할 수 없음 |
3. 인덱스
- mongoDB는 고정된 스키마는 없지만 원하는 데이터 필드를 인덱스로 지정하여 검색을 빠르게 할 수 있음
- index는 한 쿼리에 하나의 index만 유효함. 두 개 이상의 index가 필요하다면 복합 index를 사용
- 인덱스를 사용한다면 모든 쓰기 작업이 느려지기 때문에 적당한 개수(컬렉션 당 2~3개 이하)의 인덱스를 사용해야 함
인덱스의 종류
단일 필드 인덱스(Single Field Index)
- 하나의 필드 인덱스를 사용하는 것
- 기본적으로 컬렉션에 _id라는 단일 필드 인덱스가 생성됨
**db.user.createIndex({score:1})** 형태로 사용- score 필드 기준 오름차순 정렬한다는 뜻 (1 = 오름차순, -1 = 내림차순)
- 단일 필드 인덱스에서는 오름차순과 내림차순이 크게 중요하지 않음

복합 인덱스(Compound Index)
- 두 개 이상의 필드를 사용해 만드는 인덱스
**db.user.createIndex({userid:1 ,score:-1})**형태로 사용- userid 기준 오름차순, score 기준 내림차순 정렬한다는 뜻

- 복합 인덱스 사용 시 특징 및 주의사항
- 하나의 복합 인덱스에 32개의 필드까지 가능함
- 필드 순서를 고려해야 함
userid-score와score-userid는 다른 인덱스- 필드의 순서에 따라 인덱스의 효율이 달라질 수 있음
- 정렬 방향을 고려해야 함
- 검색 쿼리에 사용할 방향과 인덱스의 방향이 같아야 인덱스가 사용됨
- 생성된 인덱스: { a: 1, b: -1 } - 지원하는 조회 쿼리: { a: 1, b: -1 } - 지원하는 조회 쿼리: { a: -1, b: 1 } - 지원하지 않는 조회 쿼리: { b: 1, a: 1 } - 지원하지 않는 조회 쿼리: { b: -1, a: -1 } - 위와 같이 전체 정렬 방향이 같거나 반대인 경우는 가능하지만, 일부가 다른 경우는 인덱스가 적용되지 않음
- 검색 쿼리에 사용할 방향과 인덱스의 방향이 같아야 인덱스가 사용됨
- Prefixes(접두사)
- 복합 인덱스 생성 시, 왼쪽 인덱스부터 포함하는 부분집합의 인덱스가 자동으로 생성됨
- 생성된 인덱스: { "item": 1, "location": 1, "stock": 1 } - 지원되는 쿼리: { item: 1 } - 지원되는 쿼리: { item: 1, location: 1 } - 지원하지 않는 조회 쿼리: "item" 필드 없이 "location" 필드만 존재 혹은 "stock" 필드만 존재 - 지원하지 않는 조회 쿼리: "item" 필드 없이 "location", "stock" 필드만 존재
- 복합 인덱스 생성 시, 왼쪽 인덱스부터 포함하는 부분집합의 인덱스가 자동으로 생성됨
- Index Intersection
- 각각 다른 필드를 기준으로 생성된 인덱스를 동시에 만족하는 쿼리가 있다면, 자동으로 인덱스가 적용됨
- 인덱스 1: { qty: 1 } - 인덱스 2: { item: 1 } > db.orders.find( { item: "abc123", qty: { $gt: 15 } } ) - 이 경우 “item”과 “qty” 모두 인덱스가 적용되어 검색
- 각각 다른 필드를 기준으로 생성된 인덱스를 동시에 만족하는 쿼리가 있다면, 자동으로 인덱스가 적용됨
기초 CRUD(Docs 링크)
Create

db.collection.insertOne()
db.collection.insertMany()Read

db.collection.find()Update

db.collection.updateOne()
db.collection.updateMany()
db.collection.replaceOne()Delete

db.collection.deleteOne()
db.collection.deleteMany()정리
MongoDB의 장단점
장점
- Schema-less 구조
- 다양한 형태의 데이터 저장 가능
- 데이터 모델의 유연환 변화 가능 (데이터 모델 변경, 필드 확장 용이)
- 많은 양의 데이터에 대한 Read / Write 성능 뛰어남
- Scale Out 구조
- 많은 데이터 저장 가능
- 장비 확장 간단
- JSON(BSON) 구조
- 데이터 직관적 이해 가능
- 사용 방법이 쉽고 개발 편리
단점
- 데이터 업데이트 중 장애 발생 시 데이터 손실 가능
- 많은 인덱스 사용 시 메모리 부족 가능성 존재
- 중복 데이터를 허용하기 때문에 RDBMS보다 저장 공간을 많이 차지
- 복잡한 Join 사용 시 성능이 급격히 하락
- transaction 보장이 RDBMS에 비해 빈약
언제 사용해야 할까?
- 대용량 로그 저장 및 조회
- 공간 인덱스(Geospatial Index) 활용
- 데이터간 연관도가 낮고 빠른 확장이 필요한 서비스
- 고가용성이 필요한 서비스
References
https://www.mongodb.com/docs/manual
https://www.mongodb.com/json-and-bson
https://www.ibm.com/kr-ko/topics/mongodb
https://meetup.nhncloud.com/posts/275
https://hoing.io/archives/1379
https://wikidocs.net/190392
https://azderica.github.io/00-db-nosql/
https://velopert.com/479
https://inpa.tistory.com/entry/MONGO-📚-몽고디비의-데이터-관계-모델링-💯-정리
https://kciter.so/posts/about-mongodb
https://ryu-e.tistory.com/1
https://velog.io/@suhongkim98/MongoDB-기본#챕터-3-도큐먼트-생성-갱신-삭제
https://jaehoney.tistory.com/314
https://tychejin.tistory.com/349

기억은 유한, 기록은 무한