
Redis란?
풀네임은 REmote DIctionary Server
직역하면 외부 Dictionary 형태(Key-Value의 쌍으로 데이터를 저장하는 자료구조)의 서버이다.
Redis 공식 Docs에서는 Redis를 다음과 같이 소개하고 있다.
Redis is an open source (BSD licensed), in-memory data structure store used as a database, cache, message broker, and streaming engine. Redis provides data structures such as strings, hashes, lists, sets, sorted sets with range queries, bitmaps, hyperloglogs, geospatial indexes, and streams. Redis has built-in replication, Lua scripting, LRU eviction, transactions, and different levels of on-disk persistence, and provides high availability via Redis Sentinel and automatic partitioning with Redis Cluster.
You can run atomic operations on these types, like appending to a string; incrementing the value in a hash; pushing an element to a list; computing set intersection, union and difference; or getting the member with highest ranking in a sorted set.
To achieve top performance, Redis works with an in-memory dataset. Depending on your use case, Redis can persist your data either by periodically dumping the dataset to disk or by appending each command to a disk-based log. You can also disable persistence if you just need a feature-rich, networked, in-memory cache.
Redis supports asynchronous replication, with fast non-blocking synchronization and auto-reconnection with partial resynchronization on net split.
위의 내용 중 주요 키워드는 아래와 같다.
- In-Memory
- Cache
- strings, hashes, lists, sets, … 다양한 자료 구조(Collection) 지원
- 데이터의 영속성 지원
해당 키워드를 중심으로 Redis를 알아보자.
1. In-Memory DB
In-Memory DB는 데이터를 Disk에 저장하는 것이 아니라 Memory에 저장하는 DB를 말한다.
컴퓨터의 메모리 계층 구조
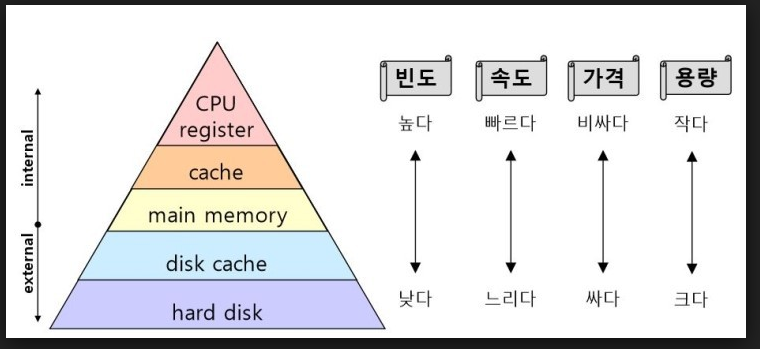
- 그림에서 볼 수 있는 것처럼 위로 갈수록 속도가 빠르고 저장 용량이 작아진다.
- 메모리(RAM)는 전원이 꺼질 경우 데이터가 사라지는
휘발성,
HDD, SSD와 같은 Disk는비휘발성이다.
장점
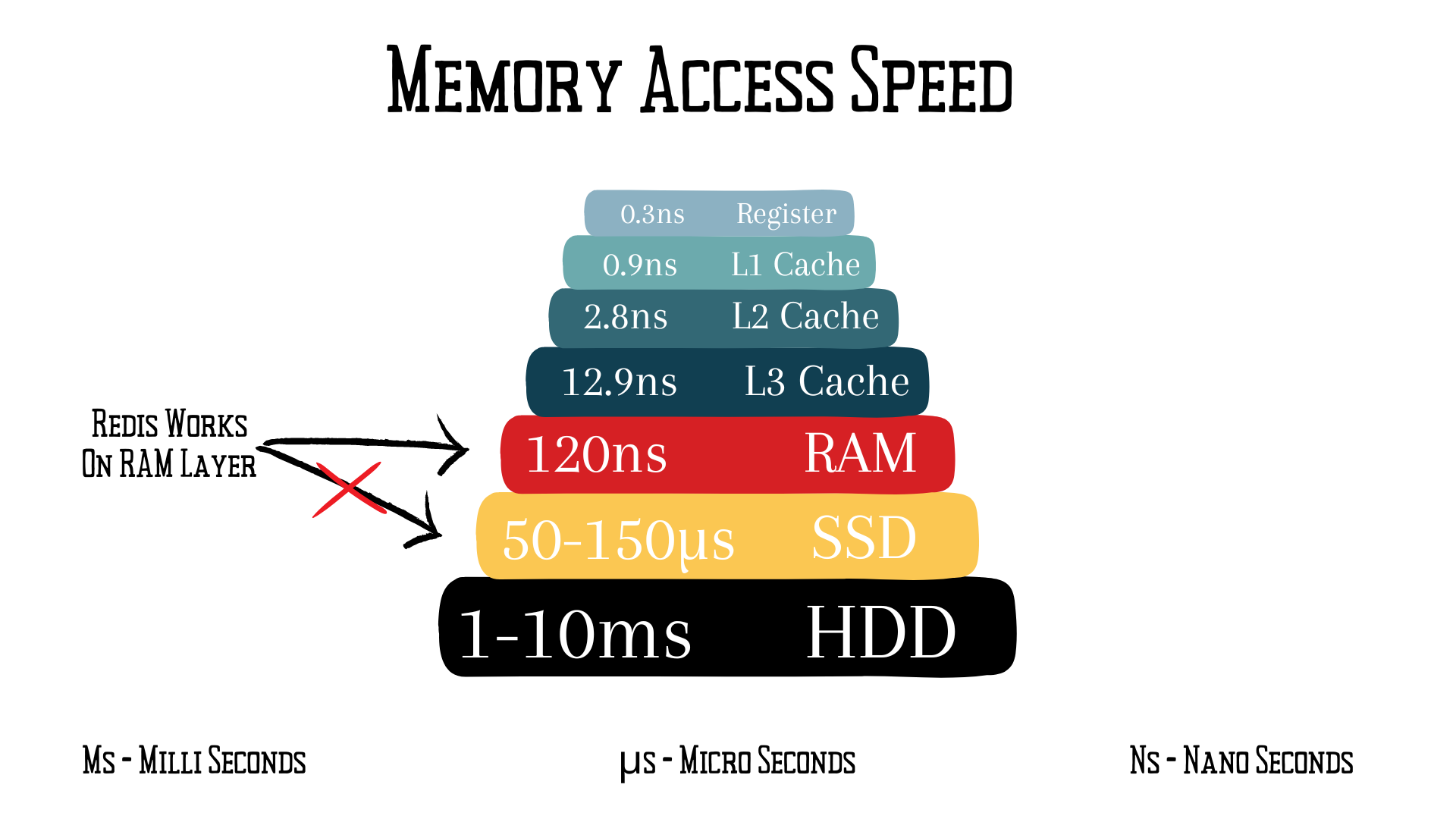 !
!
- Disk-based DB에 비해 속도가 월등히 빠르다.
단점
휘발성이기 때문에 ram에 저장된 데이터는 유실 가능성이 있다. (영속성을 보장하지 않는다.)- Disk에 비해 용량이 작다.
In-Memory의 단점을 보완한 Redis의 특징은 아래에서 설명하겠다.
2. 캐시(Cache)
Cache는 자주 쓰이는 결과를 미리 저장해두었다가 다음 요청 시 저장해놓은 것을 서비스해주는 개념이다. 매 요청마다 DB or API를 참조하지 않고 Cache에 먼저 접근하여 Cache에 해당 정보가 있다면 요청을 Cache에서 처리하여 응답 속도를 높인다. 20%의 요구사항이 80%의 리소스를 사용한다는 파레토의 법칙을 기반으로 자주 요청되는 20%의 리소스를 캐싱함으로써 성능을 대폭 향상할 수 있다.
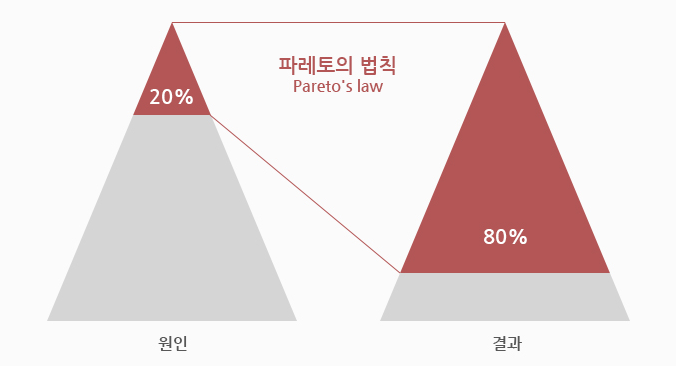
Redis는 In-Memory DB이므로 Disk-based DB와 비교했을 때 용량은 작고, 속도는 빠르다. 그렇기에 Cache 작업을 수행하는데 효과적이다.
캐싱 전략(Caching Strategies)
캐시로 사용할 때 어떤 방식으로 배치하는지가 시스템 성능에 큰 영향을 끼친다. 이를 캐싱 전략이라고 한다. 이 글에서는 여러 Caching 전략 중 2가지를 알아보자.
- Look-Aside
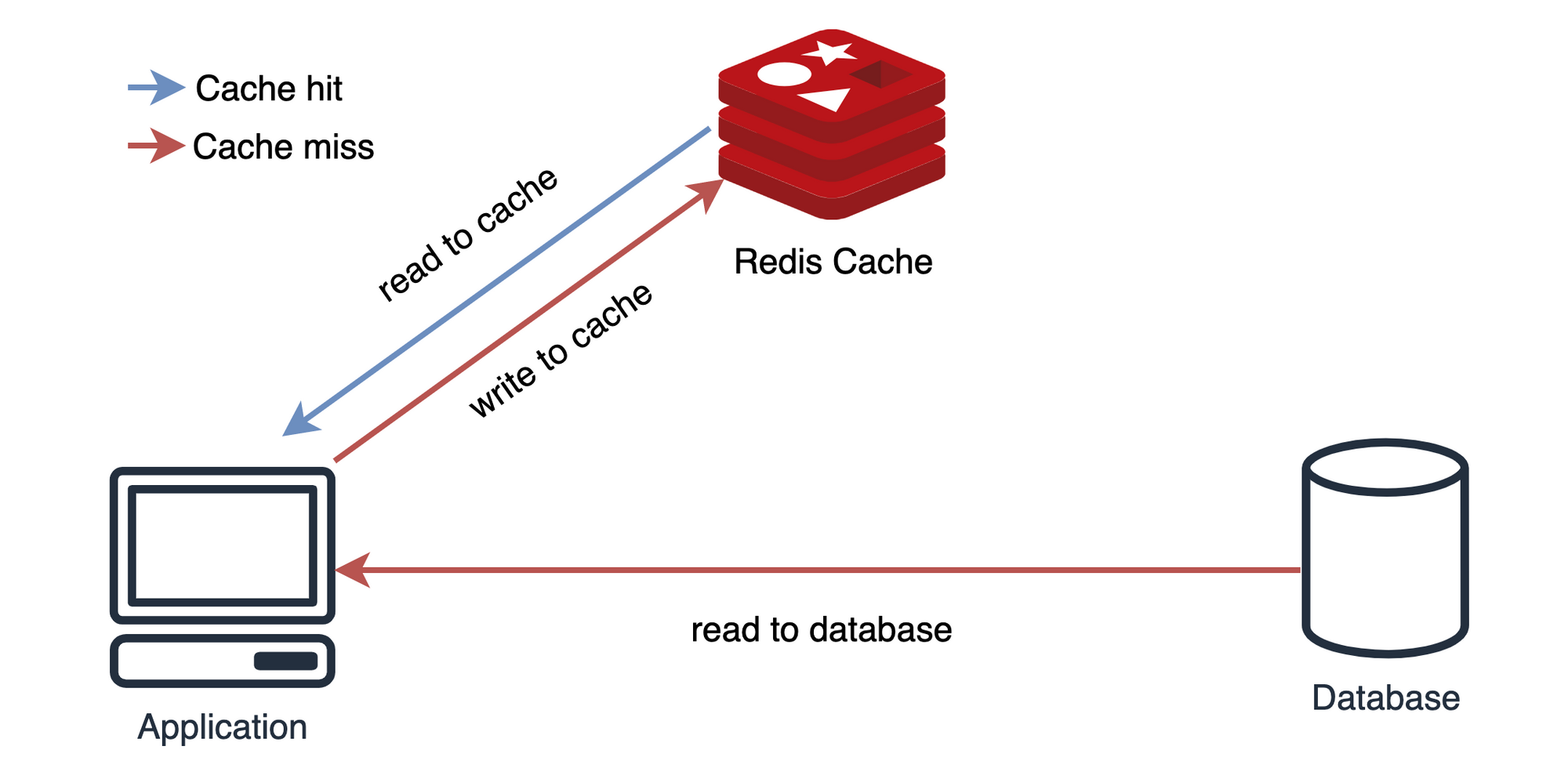
- 클라이언트가 웹 서버로 요청을 보낸다.
- 웹 서버는 먼저 캐시를 확인해, 데이터가 존재하는지 체크한다.
- 데이터가 존재한다면 캐시에서 웹 서버에 돌려준다.
- 데이터가 존재하지 않는다면(Cache Miss) 3번을 수행한다.
- DB에서 데이터를 조회해 캐시에 저장하고, 데이터를 웹 서버에 돌려준다.
이 구조는 캐시가 다운되더라도 DB에서 데이터를 가져올 수 있다.
Redis가 다운되거나 DB에만 데이터가 있다면 Cache Miss로 인해 DB에 많은 부하가 발생할 수 있다.
-
Write-Back
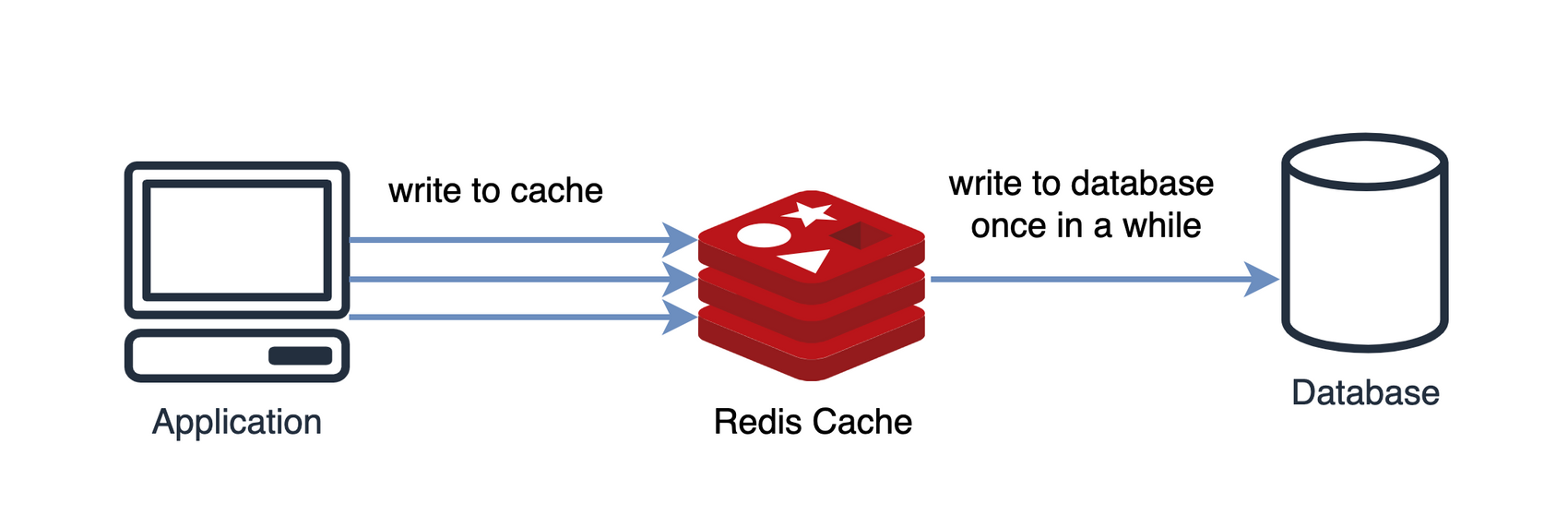
- 데이터를 임시로 캐시에 저장한 후, 특정 시점마다 캐시에 저장된 모든 데이터를 DB에 저장하는 방식이다.
이 구조는 DB 쓰기 비용을 절약할 수 있다.
데이터를 옮기기 전에 캐시 장애가 발생하면 데이터 유실이 발생할 수 있다.
3. 다양한 자료구조(Collection) 지원
Redis가 다른 in-memory DB와 차별화되는 점이 다양한 자료구조다.

Redis Collection에서 제공하는 자료구조
Redis는 데이터를 저장할 때 Key-Value 형태이므로, 어떤 자료구조를 사용하더라도 Key 값은 필요하다.
String: 기본 자료 구조, 문자열 데이터를 저장 및 조회 가능하다.Bitmap: String의 변형으로 bit 단위 연산이 가능하다. 저장 공간 절약에 큰 장점이 있다. (하나의 비트가 하나의 정보를 의미하므로)Bitfield: unsigned 1bit 정수 ~ signed 63bit 정수의 집합을 다루는 자료구조이다. 하나의 키에서 여러 정수를 다뤄야 할 경우 사용한다.Set: 중복된 데이터를 담지 않기 위해 사용하는 자료구조이다. 순서가 보장되지 않는다.List: Linked List 형식의 순서가 있는 집합이다.Sorted Set: Set에 Score라는 field가 추가된 자료구조이다. Score을 기준으로 정렬되며 Score 값이 같다면 사전 순으로 정렬된다.Hash: field-value로 구성된 자료구조이다. key의 하위에 subkey를 이용해 추가적인 Hash Table을 제공하는 것으로 볼 수 있다.Hyperloglog: 매우 많은 양의 데이터를 dump할 때 사용하는 자료구조이다. 중복되지 않는 데이터를 count할 때 주로 쓰이며(오차범위 0.81%), set과 비슷하지만 저장되는 용량이 12kb로 고정되어 있다. 저장된 데이터는 다시 확인할 수 없다.Stream: append-only(가장 뒤에 추가만 가능)이며 중간에 데이터가 바뀌지 않는다. id값 기반으로 시간 범위로 검색한다.- 다른 데이터 타입과 비교
- List
List Stream 마지막에 삽입 O(1) O(logN) 마지막 검색 RPOP : O(1), 읽고 삭제 LINDEX : O(N), 읽기 O(logN) 특정 위치 삭제 O(N) O(logN) 값 비교 값(String)을 비교하므로 느림 ID(숫자)를 비교하므로 빠름 데이터 중간 삽입 가능, O(N) 불가능 - Sorted Set
Sorted Set Stream 마지막에 삽입 O(logN) O(logN) 마지막 검색 O(logN) O(logN) 특정 위치 삭제 O(N) O(logN) 데이터 중복 허용 X 중복 허용 O 데이터 중간 삽입 가능, O(logN) 불가능 - Hash : 필드를 갖는다는 점은 비슷하지만, Hash는 순서가 보장되지 않는다.
- List
- 다른 데이터 타입과 비교
Collection 활용 사례
-
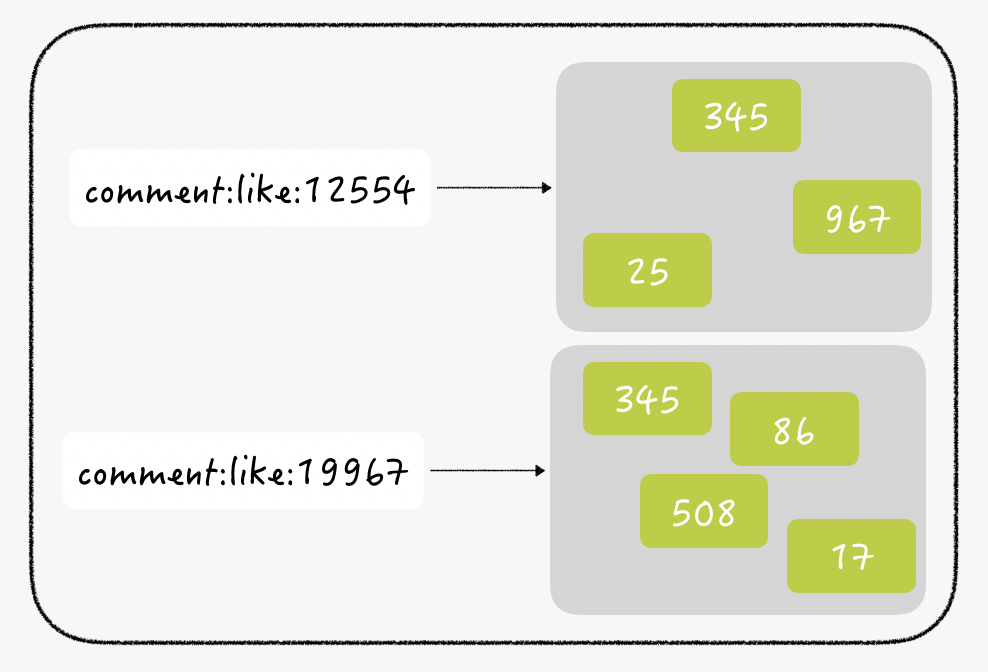
SNS 게시물 좋아요 처리
- 한 사용자가 하나의 글에 좋아요 한 번 가능
- RDBMS에서는 유니크 조건으로 구현 ⇒ 좋아요 기능은 insert & update가 수시로 발생하므로 성능 저하가 발생
- Redis는
Set을 이용하여 간단하게 구현 및 빠른 시간에 처리 가능
-
일일 순 방문자 수 구하기
-
순 방문자수 : 한 유저가 여러 번 방문했어도 한 번만 카운팅되는 값, 중복 방문을 제거한 방문자의 지표.
-
Redis의
Bitmap을 이용하여 구현 가능하다.

-
각 bit를 하나의 유저로 생각할 수 있다. 7번 유저가 방문했다면 7번 비트를 1로 변경해주면 된다.
Redis의 Hyperloglog 타입으로도 구할 수 있다.
-
-
최근 검색 목록 표시하기
- 만약 ID가 123인 사용자가 최근 검색한 사용자 목록을 보고 싶다면 RDBMS에서는 아래와 같이 쿼리를 보내야 한다.
select * from KEYWORD where ID = 123 order by reg_date desc limit 5; - 이렇게 RDBMS를 이용한다면 중복 제거, 멤버별 저장된 데이터 개수 확인, 오래된 검색어 삭제 등의 작업을 전부 수행해야 한다.
- Redis의
Sorted Set을 이용하면 쉽게 구현할 수 있다. Sorted Set은 Score 기준 오름차순 정렬되기 때문에 Score를 검색 당시의 시간으로 설정한다면 마지막에 검색한 결과가 가장 마지막에 저장된다.
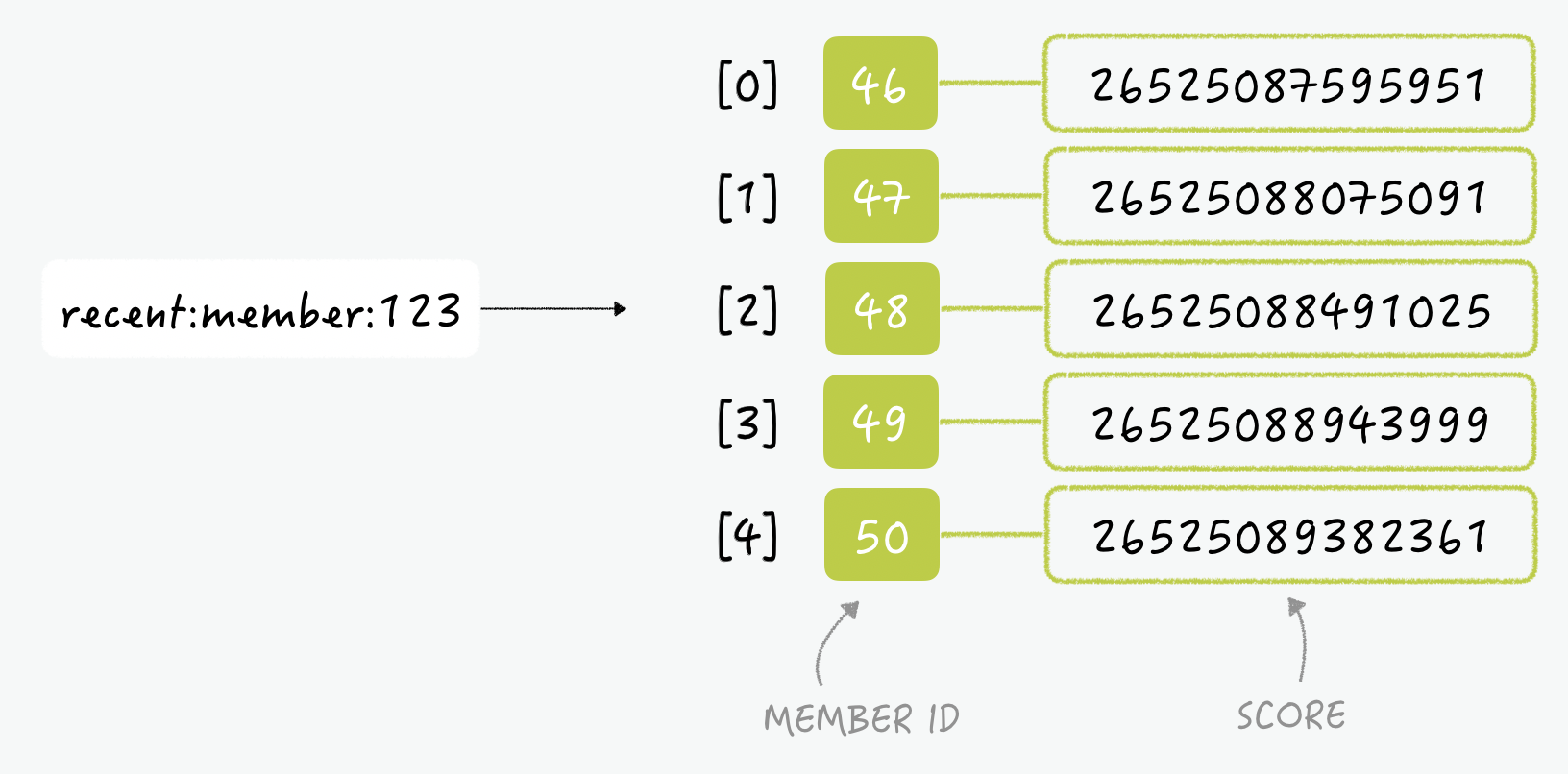
만약 최대 5개만을 저장하고 싶다면 데이터를 추가한 뒤 항상 -6번째 데이터를 삭제하는 과정을 수행하면 된다.
ZREMRANGEBYRANK recent:member:123 -6 -6 - 만약 ID가 123인 사용자가 최근 검색한 사용자 목록을 보고 싶다면 RDBMS에서는 아래와 같이 쿼리를 보내야 한다.
Collection의 장점
- 개발 편의성
- ex) 실시간 랭킹 서버 기능
RDBMS Redis 구현 방법 DB에 데이터 저장 후 저장된 SCORE 값 기준으로 정렬하여 다시 읽어옴 Sorted-Set을 이용하여 저장하고 읽어옴
- ex) 실시간 랭킹 서버 기능
- 개발 난이도
- 싱글 스레드로 동작하는 서버의 모든 자료구조는 atomic하기 때문에, race-condition을 피해 데이터의 정합성을 보장하기 쉽다.
즉, Redis의 Collection은 개발자가 비즈니스 로직에 집중할 수 있게 해준다.
4. 데이터의 영속성 지원
위에서 In-Memory DB는 데이터의 유실이 있다고 설명했다. 그럼 Redis는 어떤 방식으로 데이터의 영속성을 지원하는 걸까?
Redis는 크게 두 가지 방식으로 영속성을 보장한다.
- RDB(Snapshotting) 방식
- AOF(Append On File) 방식
RDB 방식
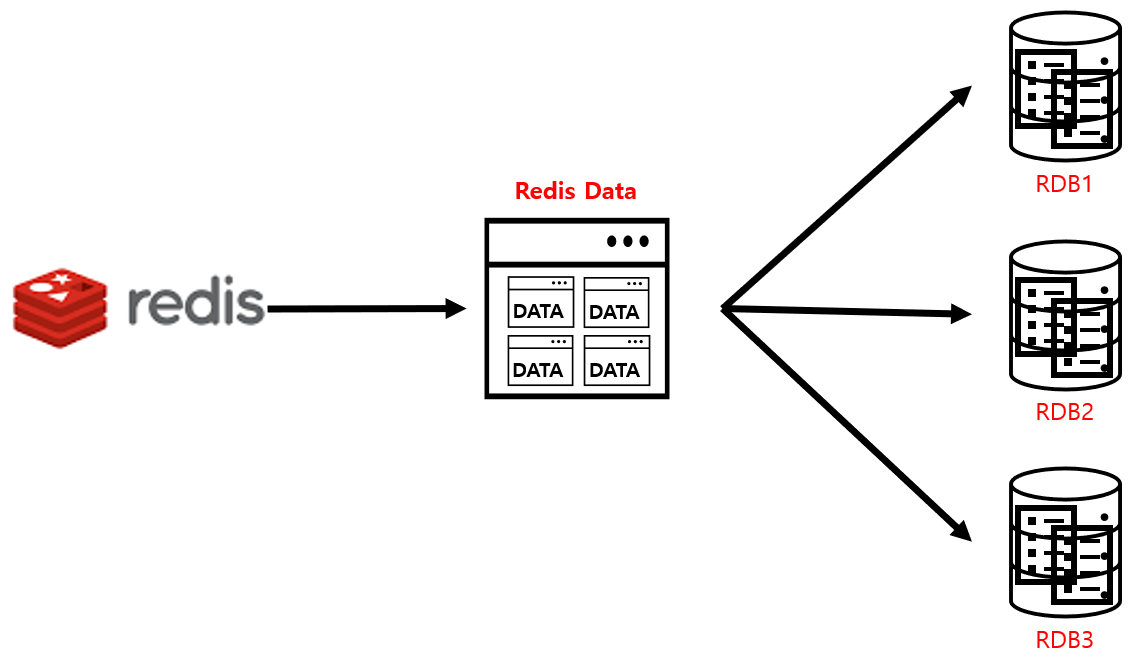
-
특정한 간격마다 메모리에 있는 Redis 데이터 전체를 Disk에 쓰는 것이다.
-
장점
- Redis의 데이터를 그대로 압축하여 저장하기 때문에 데이터의 크기가 작다.
- 크기도 작고 단일 파일이므로 복구 속도가 빠르다.
-
단점
- 전체 데이터를 지정 시간마다 백업하는 것이므로 실시간 데이터 백업이 아니다.
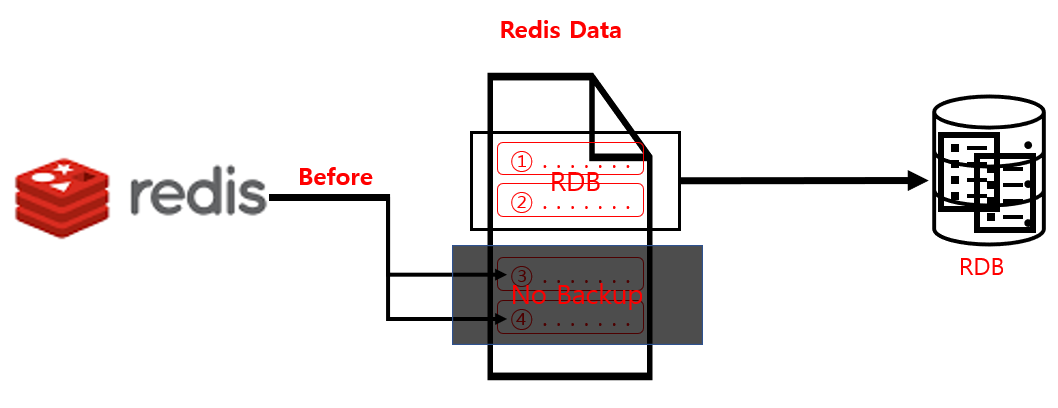
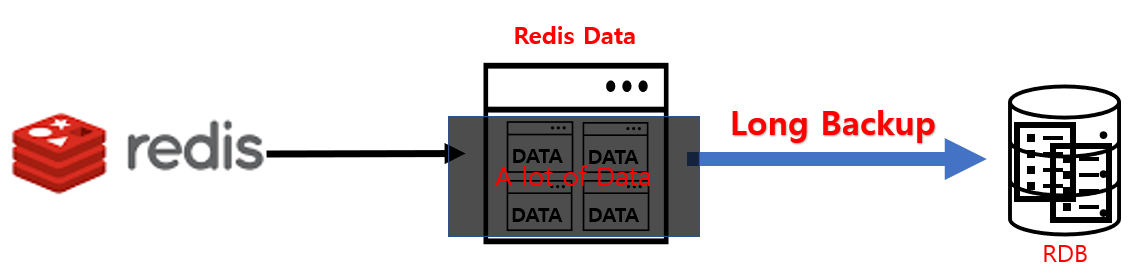
- 전체 데이터를 백업하므로 백업 속도가 느리다.
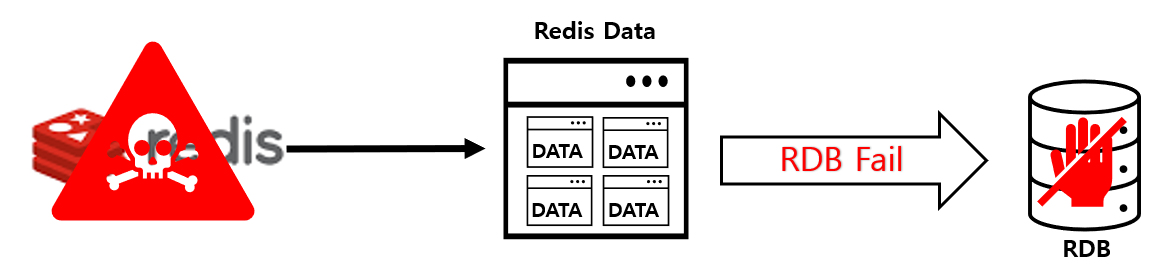
- 데이터 백업 과정 중 서버가 다운되면 데이터가 유실될 가능성이 있다.
- 전체 데이터를 지정 시간마다 백업하는 것이므로 실시간 데이터 백업이 아니다.
AOF 방식

- 입력, 수정, 삭제 명령을 실행할 때마다 log 파일에 저장하는 방식이다.
- 장점
- 실시간으로 데이터가 저장된다.
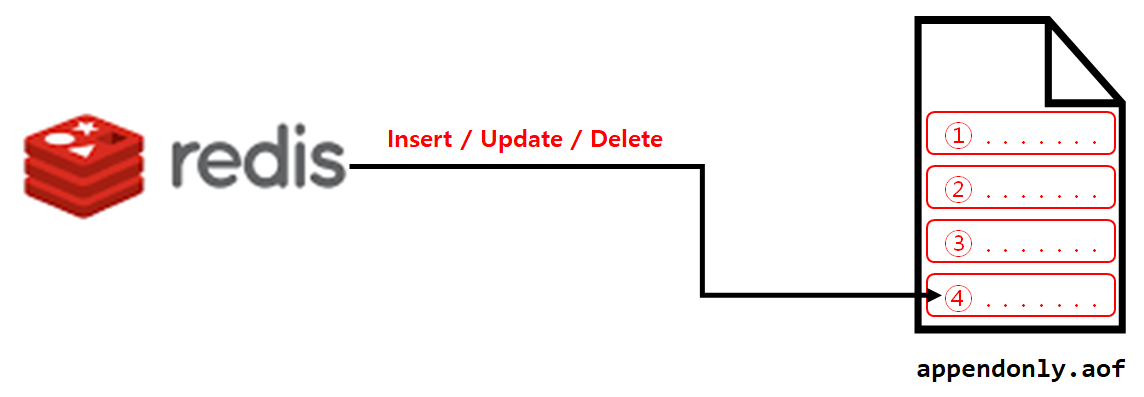
- 데이터 저장 속도가 빠르다.

- 기록된 명령어를 수정하고 복원할 수 있다. 실수로 모든 데이터를 삭제한 경우 AOF 파일에 기록된 삭제 명령을 수정하고 복원이 가능하다.
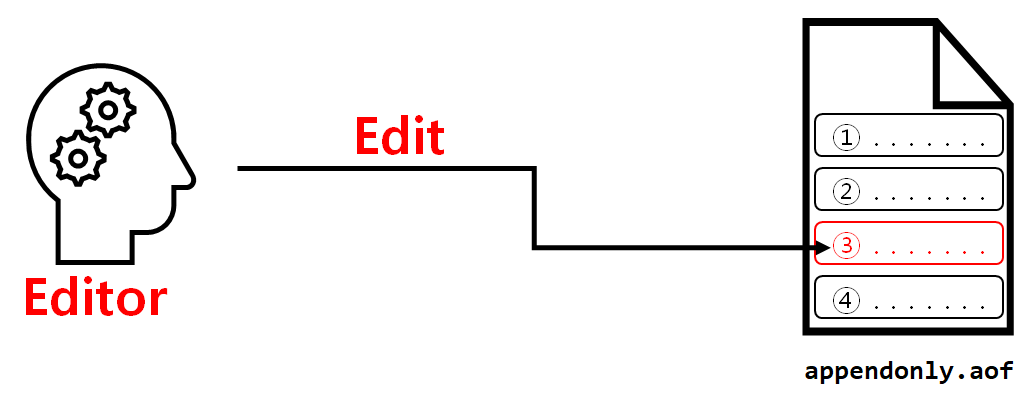
- 실시간으로 데이터가 저장된다.
- 단점
- 모든 변경 기록을 저장하므로 로그 파일의 크기가 커진다.
- 로그 파일의 크기가 크므로 데이터 복구 속도가 느리다.
RDB vs AOF 선택 기준
- 백업은 필요하지만, 어느 정도 데이터 손실이 발생해도 되는 경우 ⇒ RDB 단독 사용
- 장애 상황 직전까지 모든 데이터가 보장되어야 할 경우 ⇒ AOF 사용
- 제일 강력한 내구성이 필요한 경우 ⇒ RDB & AOF 사용
RDB와 AOF의 장/단점으로 인해 RDB로는 주기적으로 백업을, RDB 백업 기준으로 AOF 로그를 초기화하여 시간 절약과 실시간 데이터 유지하는 방법이 많이 사용된다.
Redis 언제 쓰면 좋을까?
- 여러 서버에서 같은 데이터를 공유할 때
- 주로 많이 사용되는 곳
- 인증 토큰 저장(String or Hash)
- Ranking 보드로 사용(Sorted Set)
- 유저 API Limit (참고)
- 잡 큐(List)
References
https://redis.io/docs
https://yoongrammer.tistory.com/101
https://www.youtube.com/watch?v=mPB2CZiAkKM&ab_channel=우아한테크
https://velog.io/@yukina1418/Redis가-사랑받는-이유에-대하여-작성중
https://dev.to/yogini16/redis-remote-dictionary-server-cache-20ie
https://sihyung92.oopy.io/database/redis/1
https://velog.io/@hope1213/Redis란-무엇일까
https://www.linkedin.com/pulse/why-heck-single-threaded-redis-lightning-fast-beyond-in-memory-kapur/
https://meetup.nhncloud.com/posts/224
https://aws.amazon.com/ko/elasticache/what-is-redis/
https://inpa.tistory.com/entry/REDIS-📚-데이터-타입Collection-종류-정리
https://server-talk.tistory.com/489
https://loosie.tistory.com/803#Redis사용하는방식
