범주형 변수
- 회귀에서 범주형 변수의 경우 특별히 변환을 해주어야 함
범주형 변수
- 수치형 데이터가 아닌 문자형 데이터로 이루어져 있는 변수가 범주형 변수
범주형 변수 종류
- ex) 성별, 지역 등이 있으며, 더미 변수로 변환하여 회귀분석에 사용.
- 순서가 있는 범주형 변수
- 옷 사이즈, 수능 등급과 같이 범주형 변수라도 순서가 있는 변수에 해당.
- 이런 경우 문자를 임의의 숫자로 변환해도 문제 없음
- 순서가 없는 범주형 변수
- 성별, 지역과 같이 순서가 없는 변수에 해당
- 2개 밖에 없는 경우 임의의 숫자로 바로 변환해도 문제 없지만
- 3개 이상인 경우 무조건 원-핫 인코딩(하나만 1이고 나머지는 0인 벡터)변환을 해주어야 한다 -> pandas의 get_dummies를 활용하여 쉽게 구현 가능
- ex) = [1,0,0,0], 대전 = [0,1,0,0], 광주 = [0,0,0,1]
- 순서가 있는 범주형 변수
범주형 변수 어떻게 사용하나
범주형 변수를 찾고 더미 변수로 변환한 후 회귀 분석 수행
- 성별, 근무 경력과 연봉 간의 관계
- 성별과 근무 경력이라는 요인변수 중 성별이 범주형 요인변수에 해당
- 해당 변수를 더미 변수로 변환
- 회귀 수행
# 예시 데이터 생성
data = {'Gender': ['Male', 'Female', 'Female', 'Male', 'Male'],
'Experience': [5, 7, 10, 3, 8],
'Salary': [50, 60, 65, 40, 55]}
df = pd.DataFrame(data)
# 범주형 변수 더미 변수로 변환
# drop_first란 범주형 변수 개수 중 1개를 빼는것
# 어차피 마지막 1개 변수는 있으나 마나한 존재이기 때문에
df = pd.get_dummies(df, drop_first=True)
# 독립 변수(X)와 종속 변수(Y) 설정
X = df[['Experience', 'Gender_Male']]
y = df['Salary']
# 단순선형회귀 모델 생성 및 훈련
model = LinearRegression()
model.fit(X, y)
# 예측
y_pred = model.predict(X)
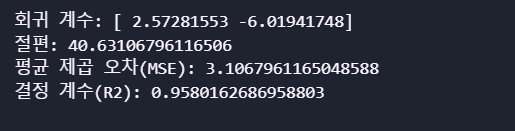
# 회귀 계수 및 절편 출력
print("회귀 계수:", model.coef_)
print("절편:", model.intercept_)
# 모델 평가
mse = mean_squared_error(y, y_pred)
r2 = r2_score(y, y_pred)
print("평균 제곱 오차(MSE):", mse)
print("결정 계수(R2):", r2)