이 글은 구글 브레인 팀에서 발표한 “Attention Is All You Need”(2017) 논문에 대한 리뷰입니다.
Introduction
기존 모델들의 한계
기존 모델들은 주로 RNN(LSTM, GRU 등)이나 CNN 기반의 인코더-디코더 구조로 시퀀스 변환을 했습니다. 또한, Attention은 RNN의 보조 도구로 활용되며 순차적 계산에 의존했습니다. 이는 긴 시퀀스를 처리할 때 병렬화가 어렵고 시퀀스 길이가 길어짐에 따라 연산량과 메모리 사용량이 증가하게 됩니다.
Transformer 는 RNN이나 CNN을 전혀 사용하지 않고도 Attention 메커니즘만으로 시퀀스 변환을 수행하는 아키텍처를 제안합니다.
이 모델은 시퀀스 내 모든 위치간의 관계를 병렬적으로 학습할 수 있어 기존 모델의 단점을 개선했습니다.
Background
본 논문에서는 Attention 메커니즘에 대해 간략히 소개하며 중요한 매커니즘이라고 생각해 정리하며 작성합니다.
Attention 메커니즘은 시퀀스 내에서 멀리 떨어진 토큰 간의 관계를 효율적으로 계산합니다.
RNN 기반 접근법은 토큰 간의 거리가 멀어질수록 중간 단계들을 거쳐야 하므로 연산량과 메모리 사용량이 증가하는 단점이 있습니다.
반면 Attention은 쿼리(Query), 키(Key), 값(Value) 구조를 통해 시퀀스 내 모든 위치의 토큰들이 병렬적으로 서로 영향을 주도록 설계되었습니다.
즉, Transformer는 순차적 계산에 의존하지 않고도, 한 번의 Attention 연산으로 시퀀스 내 모든 토큰 간 상호작용을 병렬적으로 처리합니다.
Architecture
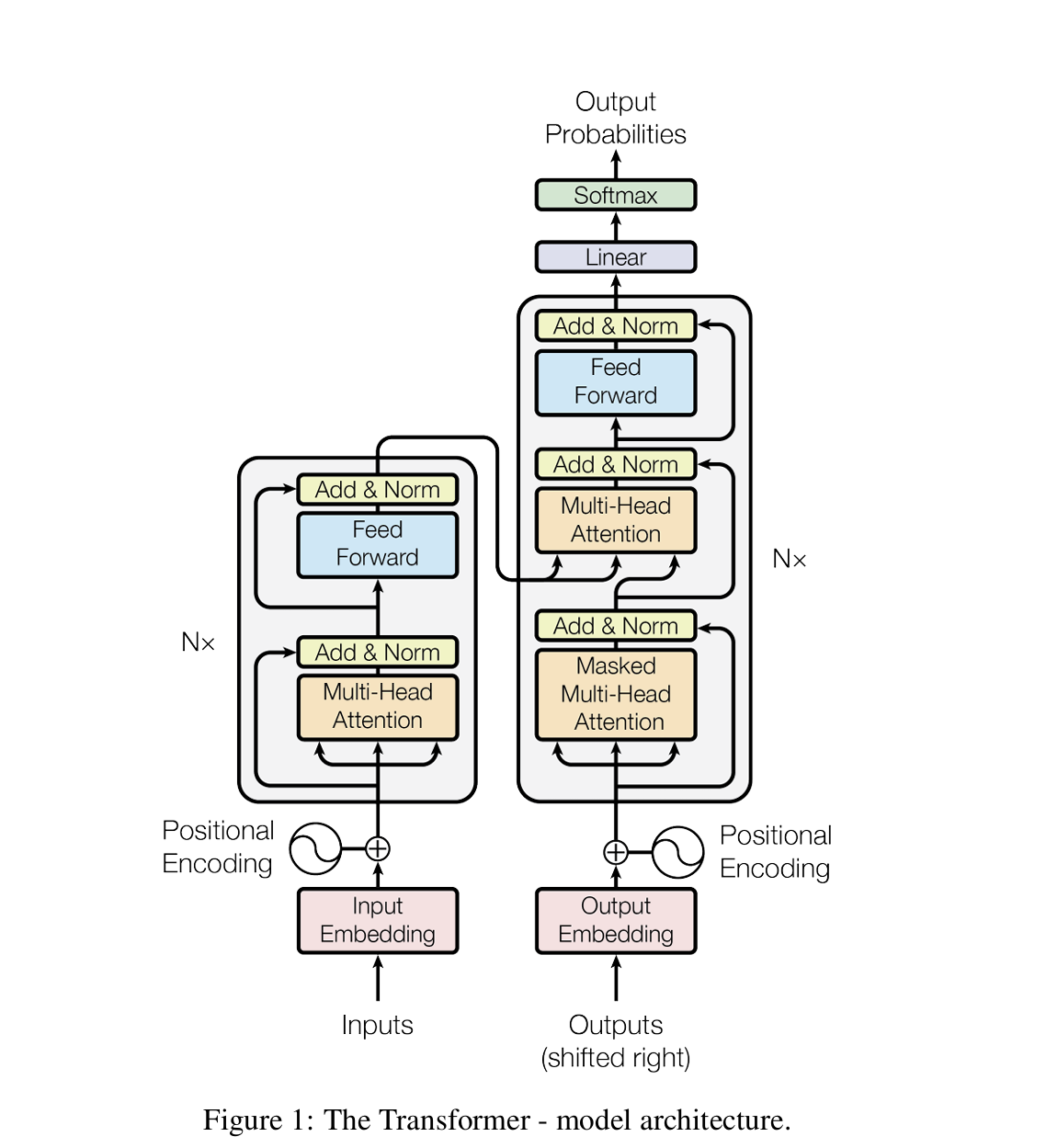
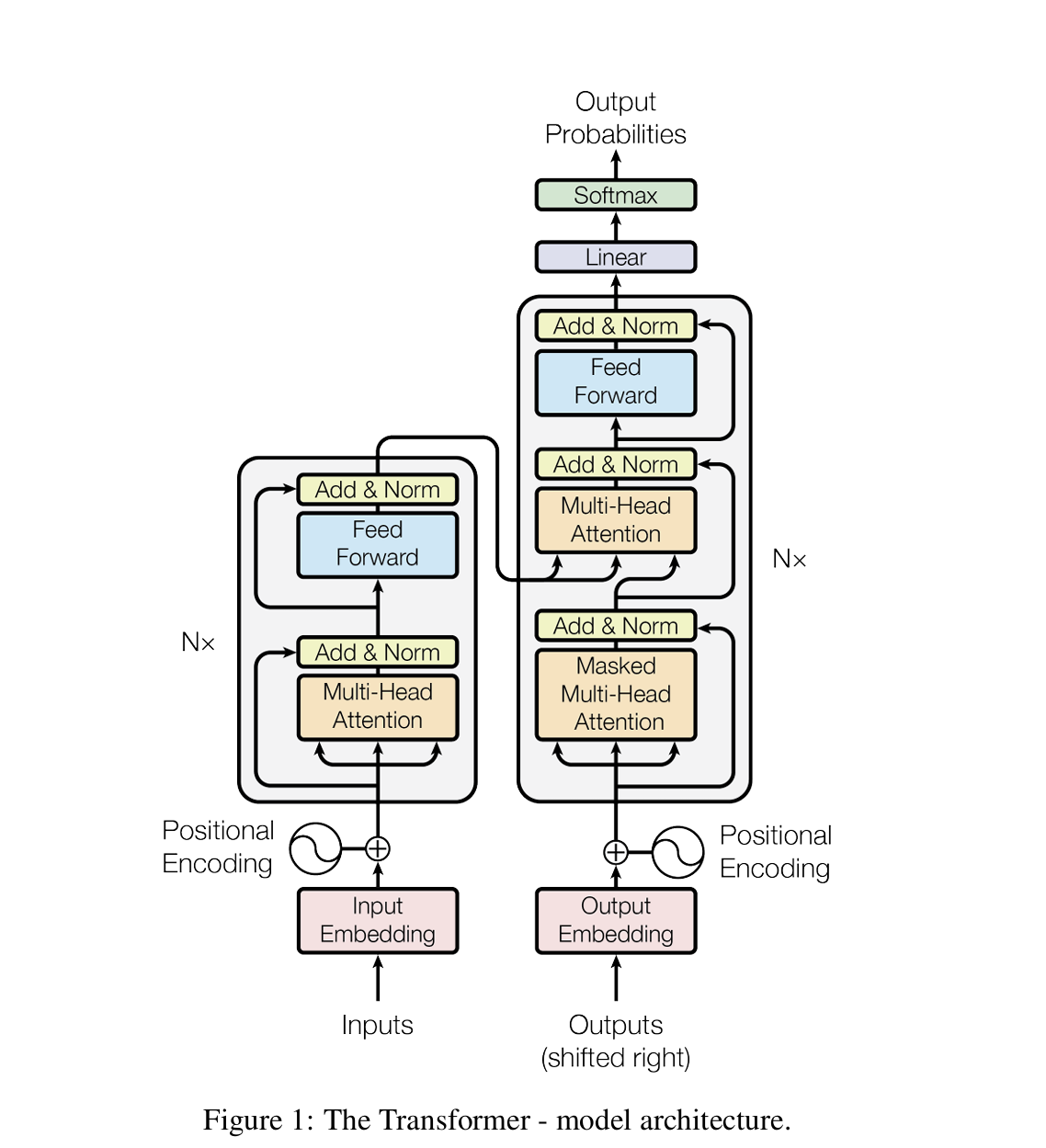
- 인코더(Encoder)
- 입력 임베딩에 위치 정보를 담기 위한 Positional Encoding을 더한 뒤, Multi- head Self-Attention과 Point-wise Fully Connected Feedforward Network를 거칩니다.
- 각 서브 레이어마다 Residual Connection과 Layer Normalization을 적용해 학습 안정성과 성능을 높입니다.
- 디코더(Decoder)
- 디코더 역시 인코더와 유사한 구조로 구성되어 있지만, 중간에 인코더의 출력을 참고하는 Multi-head Attention 모듈을 추가로 갖습니다.
- Masked Self-Attention을 적용해 , n번째의 출력을 대상으로 할 때 n-1번 순서의 시퀀스까지 참조하도록, softmax 단계에 미래 코큰은 무한대로 치환해 정규화를 거치고 0 이 되도록 합니다.
- Positional Encoding
- Transformer는 RNN이나 CNN처럼 시퀀스 순서 정보가 직접적으로 반영되는 구조가 아닙니다. 토큰의 인코딩 작업을 할 경우 위치 정보를 추가하여 인코딩합니다.
- Point-wise Fully Connected Feedforward Network
- 두 개의 선형변환과 ReLu 활성홤수로 구성됩니다. 입력과 출력의 차원은 512 이고, 내부 차원은 2048 입니다.
Attention
self attention 의 필요성
논문에서는 Self Attention이 필요한 주요 이유를 네 가지 관점에서 설명하고 있습니다.
- 계산 복잡도
- RNN 레이어는 시퀀스의 길이에 따라 계산 복잡도가 증가합니다. 반면 self attention 레이어는 시퀀스의 길이가 표현 차원보다 작을 때 더 빠릅니다.
- 병렬화
- RNN은 순차적 계산을 요구하는 것과 달리, Self-Attention은 모든 위치의 계산을 동시에 수행할 수 있습니다.
- 장거리 의존성 학습에 유리
- RNN에서 멀리 떨어진 토큰 간의 관계를 학습하기 위해서는 O(n)의 순차적 연산이 필요한 반면, Self-Attention은 모든 토큰 간의 관계를 일정한 수의 순차적 연산으로 연결할 수 있다고 합니다.
- 모델 해석력 증가
- 입력 시퀀스의 각 토큰이 다른 토큰에 얼마나 영향을 주는 지, 학습하면서 그들의 의존성의 크기를 파악할 수 있어 모델이 문장을 학습하는 방식을 이해하는 데 도움이 됩니다.
Scaled Dot-Product Attention
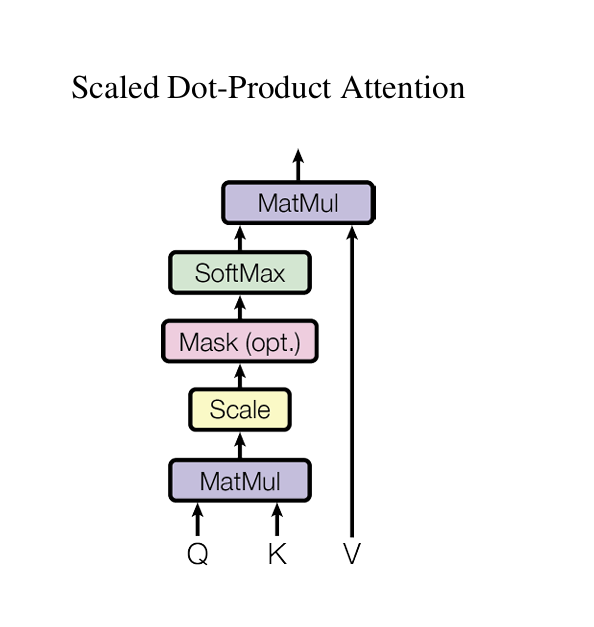
Scaled Dot-Product Attention은 쿼리(Query,Q), 키(Key,K), 값(Value,V) 간의 연산을 통해 입력 토큰 간의 중요도를 학습하고, 이를 바탕으로 문맥 정보를 반영한 출력을 생성하는 메커니즘입니다.
-
쿼리 - 키 유사도 검사
Q 와 K 의 dot product 를 통해 각 쿼리 와 키의 유사도를 계산합니다. 두 벡터의 내적을 기반으로 하며 입력 시퀀스 내의 각 토큰의 관련성을 수치화 합니다.
-
스케일링
계산된 값을 벡터의 차원 수 의 제곱근으로 나누어 스케일링 합니다. 이는 안정적인 계산을 위한 단계입니다.
-
소프트맥스 및 가중치 적용
소프트맥스를 적용하여 가중치를 생성하고 , 이를 Value 벡터 V에 곱하여 최종적으로 토큰간의 관계를 기반으로 한 문맥 정보를 반영한 weighted sum 을 생성합니다.
-
선택적으로 Mask 를 적용하여 n번의 단어의 미래 단어들을 참조하지 않게 만듭니다.
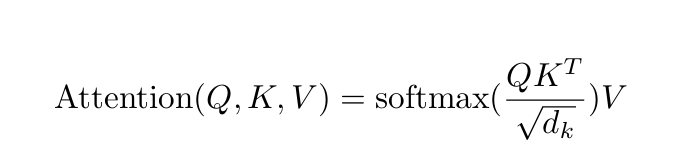
Multi Head Attention
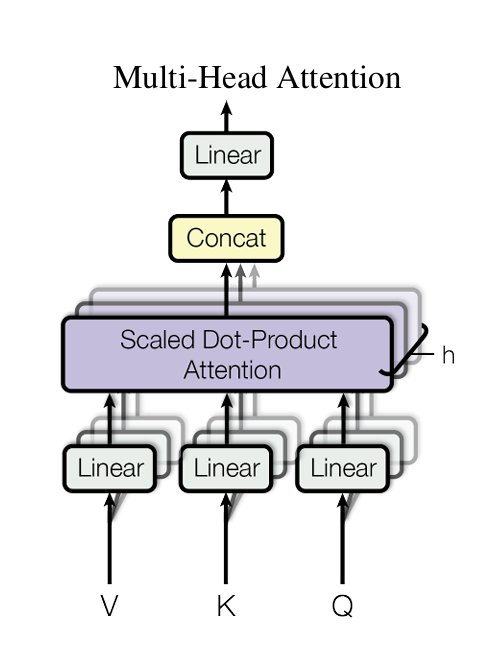
여러 개의 Attention 연산을 병렬적으로 수행합니다. 모델은 다양한 관점에서 입력데이터를 학습할 수 있고 표현력과 학습 성능이 향상됩니다.
- 입력 데이터의 투영
- Q,K,V를 각각 h개의 하위공간에 투영합니다.
- 독립적으로 Attention 연산을 수행합니다.
- 독립적 Attention 수행
-
h개의 Attention 결과를 병렬적으로 구한 뒤, 이를 결합(Concatenate)하여 최종 출력을 생성합니다.

-
이를 통해 각각 다양한 관계를 학습하여 더 풍부한 문맥 정보를 학습할 수 있게 됩니다.
Train
Parameter 및 학습 관련 정보
- 데이터셋 : WMT 2014 영어-독일어(En-De) 450 만 문장 쌍 , WMT 2014 영어-프랑스어(En-Fr) 3600만 문장 쌍 ****
- 37,000개의 토큰으로 구성된 source - target 어휘 사용
- train batch : 25000개 source token 과 25000개 target token
- 8개 NVIDIA P100 GPU
- 기본 모델 총 12시간 동안 훈련, 큰 모델 3.5일 동안 훈련
-
하이퍼파라미터
- 임베딩 차원(d_model), 피드포워드 차원(d_ff), Attention 헤드 수(h), 레이어 수(N) dmodel=512 dff=2048 N=6 h=8
- 임베딩 차원(d_model), 피드포워드 차원(d_ff), Attention 헤드 수(h), 레이어 수(N) dmodel=512 dff=2048 N=6 h=8
-
옵티마이저 & 정규화
- Adam 옵티마이저 , β1=0.9 β2=0.98
- Dropout과 Layer Normalization을 통해 모델의 일반화 성능을 높입니다.
- Adam 옵티마이저 , β1=0.9 β2=0.98
-
병렬화
- 순차 계산에 얽매이지 않고 모든 토큰에 대한 Self-Attention을 병렬적으로 수행할 수 있어, GPU/TPU 클러스터에서 대규모 연산이 효율적으로 가능합니다.
- 이는 RNN 기반 모델 대비 훨씬 빠른 학습 속도를 보장하며, 대규모 데이터셋에서도 우수한 확장성을 제공합니다.
Result
- WMT 2014 En-De 번역 작업에서 BLEU 스코어 28.4를 기록하며 당시 최고 성능을 뛰어넘었습니다.
- WMT 2014 En-Fr 작업에서는 BLEU 스코어 41.0을 달성하여, RNN/CNN 기반의 다른 아키텍처보다 더 적은 연산량으로도 뛰어난 번역 성능을 보였습니다.
모델 변형
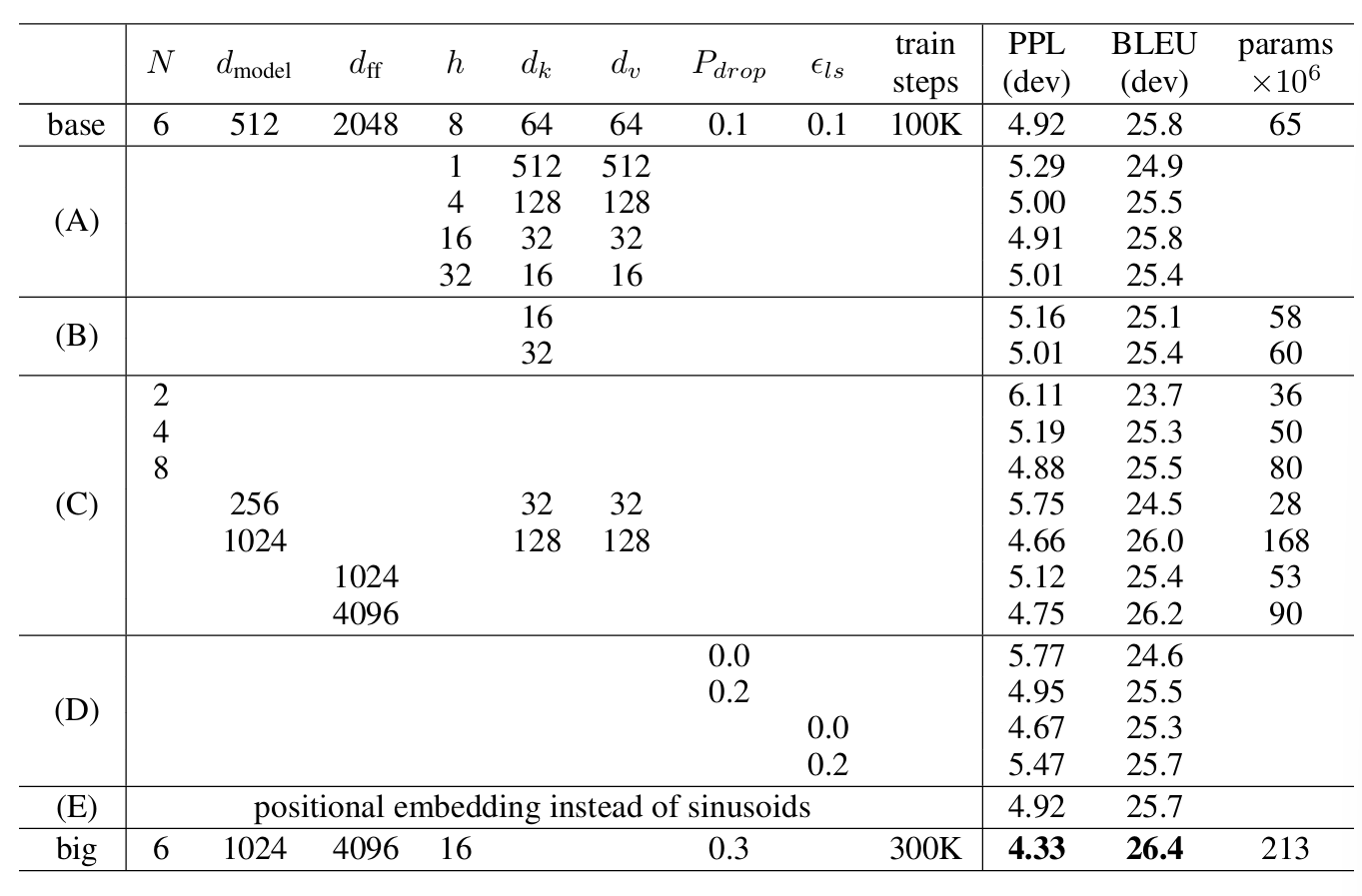
- Attention 헤드 수와 크기
- 단일 헤드(h=1)는 성능이 저하되었으며, 헤드 수가 너무 많아질 경우에도 성능이 감소했습니다.
- 키/값 벡터 크기(dk,dv)가 작아질 경우, 정보 손실로 인해 성능이 저하되었습니다.
- 모델 크기
- 임베딩 차원과 피드포워드 네트워크 크기를 늘릴수록 성능이 향상되었으며, 드롭아웃 적용은 과적합 방지에 효과적이었습니다.
