You Only Look Once : Unified, RealTime Object Detection 논문을 읽고 정리한 글입니다.
1.Introduction
현재의 탐지 시스템은 classifier를 재사용하여 탐지를 수행합니다. 예를 들어, DPM 은 슬라이딩 윈도우 기법을 적용하여 classifier를 이미지 전체 일정한 간격으로 실행합니다. R-CNN은 복잡한 파이프라인을 거치며, 이러한 구조는 느리고 최적화하기 어렵습니다. 각 독립적인 구성요소를 개별적으로 최적화하고 훈련해야하기 때문입니다.
하지만 YOLO는 매우 간단합니다. 단일 컨볼루션 네트워트로 이루어진 YOLO는 동시에 전체적인 이미지의 경계상자와 클래스 확률을 예측합니다. 이 통합된 모델은 앞서 설명한 탐지 시스템과 달리 3가지의 이점을 갖습니다.
- 속도: 초당 45 프레임을 처리하며 fast YOLO 는 초당 150 프레임 이상을 처리하며 실시간 처리를 할 수 있습니다.
- 전체 이미지 분석: 클래스와 출현 위치에 대한 맥락 정보를 파악하고 해당 정보를 암묵적으로 인코딩합니다. 그리하여 YOLO는 FasterRCNN에 비해 배경 오류를 절반 이하로 줄일 수 있습니다.
- 일반화: 학습한 데이터 와 다른 예상치 못한 도메인이 입력으로 들어와도 잘 작동합니다.
2. Architecture
2.1 confidence score
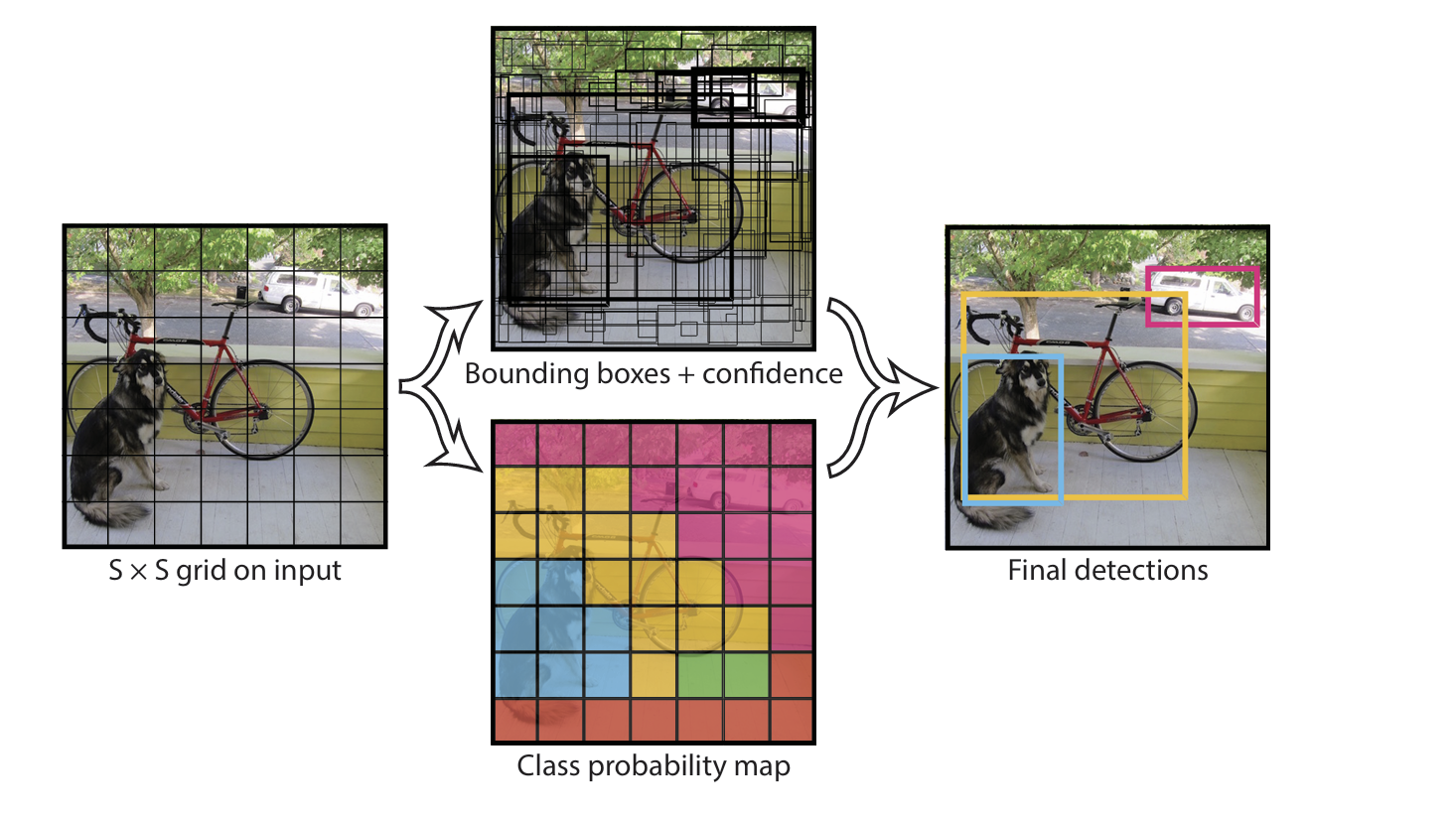
-
입력 이미지를 SxS 그리드로 나누어줍니다.
-
만약 그리드 셀 안에 객체의 중앙이 포함되어 있다면 해당 셀은 객체를 탐지하는 중요한 역할을 맡습니다.
-
다음 2가지 기준으로 신뢰도 점수를 측정합니다. 신뢰도 점수는 예측된 상자가 얼마나 정확한지를 반영합니다.
- 각 그리드 셀은 B 개의 경계상자와 해당 상자에 대한 신뢰도 점수를 측정합니다. 만약 셀에 객체가 없다면 신뢰도 점수는 0이 될 것입니다.
- 각 그리드 셀은 조건부 클래스 확률을 예측합니다. 이 확률은 그리드 셀이 객체를 포함하고 있다는 조건하에 예측됩니다.
-
이렇게 구한 값을 곱하여 점수를 얻습니다. 이 점수는 상자에 해당 클래스가 나타날 확률과 예측된 box 가 객체와 얼마나 잘 맞는지를 나타냅니다.
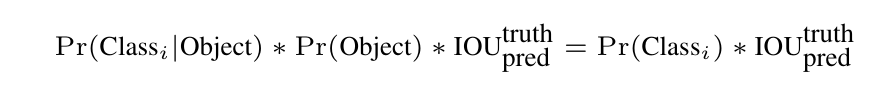
2.2 Network Design
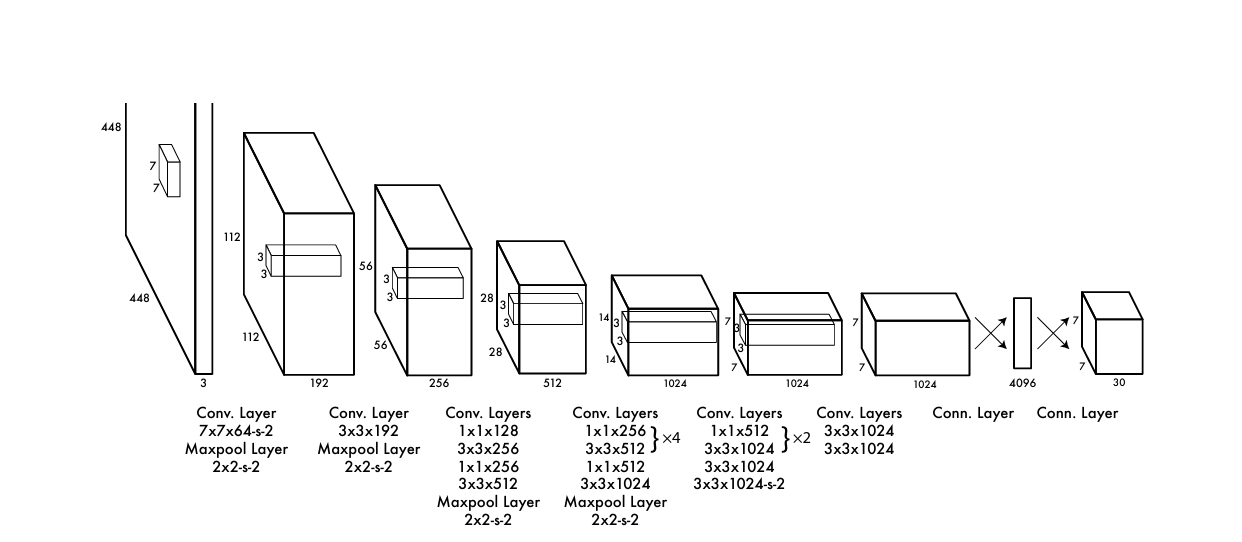
24개의 Convolution layer 와 2개의 fully connected layer로 구성되어집니다. convolution layer 는 1x1 reduction layer 3x3 convolution layer를 사용합니다. fast YOLO 는 9개의 convolution layer인 구조입니다
3. Train
사전 학습을 위해 20개의 convolution layer 와 average pooling layer, 그리고 fully connected layer를 사용합니다.
약 일주일 동안 훈련하여 single crop top-5 정확도를 88% 달성합니다.
사전 훈련된 네트워크에 무작위로 초기화된 가중치를 가진 4개의 convolution layer 와 2개의 fully connected layer를 추가합니다.
또한, 탐지는 세밀한 시각 정보를 필요로 하므로 네트워크의 입력해상도를 224x224 에서 448x 448로 증가시킵니다.
최종 레이어는 클래스 확률과 경계상자 좌표를 모두 예측합니다.
activation function 은 다음과 같습니다.
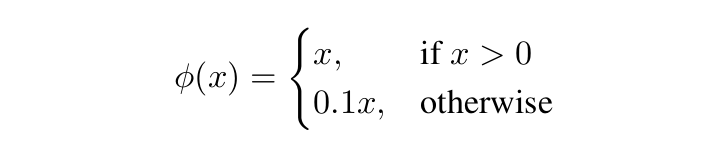
3.1 Parameter
- 에포크 수: 135
- 데이터 셋 : Pascal VOC 2007 과 2012
- 배치 사이즈: 64
- 모멘텀: 0.9
- 감쇠율: 0.0005
- 학습률: 처음 epoch 동안은 0.001 에서 0.01 로 천천히 증가 시키고 이후 75epoch 동안 0.01로 훈련을 계속합니다. 다음 30epoch는 0.001로, 나머지 30epoch동안 0.0001로 훈련합니다.
과적합을 방지하기 위한 방법은?
- 첫 번째FC 레이어 후에 dropout 레이어를 사용하여 레이어 간의 co- adaption을 방지합니다.
- 원본이미지 의 최대 20%까지 무작위로 스케일링 변환을 하여 데이터를 증강합니다.
(추가) HSV 색상공간에서 노출과 채도를 최대 1.5배까지 무작위로 조정합니다.
4. Limitations
- 각 그리드 셀이 두 개의 상자만 예측할 수 있고 하나의 클래스만 가질 수 있기 때문에 경계 상자 예측에 강한 공간적 제약을 가집니다. 따라서 군집을 형성한 여러 작은 객체를 탐지하는 데 어려움을 겪습니다.
- 새롭거나 비정상적인 정횡비 또는 구성에 일반화가 어렵습니다.
- 입력 이미지에 여러 다운샘플링 레이어를 거치기 때문에 bounding box를 예측할 때 상대적으로 거친 features 를 사용합니다.
- 탐지성능을 근사하는 손실 함수로 훈련하지만, 이는 작은 bounding box 와 큰 bounding box의 오류를 동일하게 취급합니다. 작은상자에서 작은 오류는 IoU에 큰 영향을 줍니다.
5. Comparison
- DPM
- 슬라이딩 윈도우 접근 방식
- 정적 특징을 추출하고 영역을 분류
- 높은 점수를 받은 영역에 대해 경계상자를 예측
분리된 파이프라인을 사용하는 DPM 에 비해 YOLO는 모든 분리된 부분을 단일 신경망으로 대체합니다. 이런 구조는 DPM 보다 빠르고 정확한 모델을 제공합니다.
- R-CNN
- Region Propasal 방식
- 복잡한 파이프라인
- 결과 시스템은 테스트 시 이미지당 40초 이상 소요됨.
각 그리드셀이 잠재적인 경계 상자를 제안하고, 컨볼루션 특징을 사용하여 상자를 점수화하는 유사한 특징을 가집니다. 하지만 YOLO는 Selective Search 보다 더 적은 경계 상자를 제안하며, 단일 통합 시스템으로 개별 구성요소를 결합합니다.
- Fast R-CNN 및 Faster-RCNN
- RCNN 의 느린 속도를 개선
- 신경망을 사용하여 영역을 제안함
속도를 개선했지만 YOLO 처럼 실시간 탐지 성능은 불가능합니다.
- MultiBox
- 단일 클래스 예측으로 신뢰도 예측을 대체하여 단일 객체 탐지를 수행할 수 있습니다.
- YOLO와 MultiBox는 모두 컨볼루션 네트워크를 사용하여 이미지에서 경계 상자를 예측하지만, YOLO는 완전한 탐지 시스템입니다.
- OverFeat
- Sermanet 등은 컨볼루션 신경망을 훈련하여 지역화를 수행하고, 그 지역화기를 탐지로 적응시킵니다.
- 일관된 탐지를 생성하기 위해 상당한 후처리가 필요합니다.
6. Experiments
본 논문에서는 총 4가지의 실험을 진행합니다.
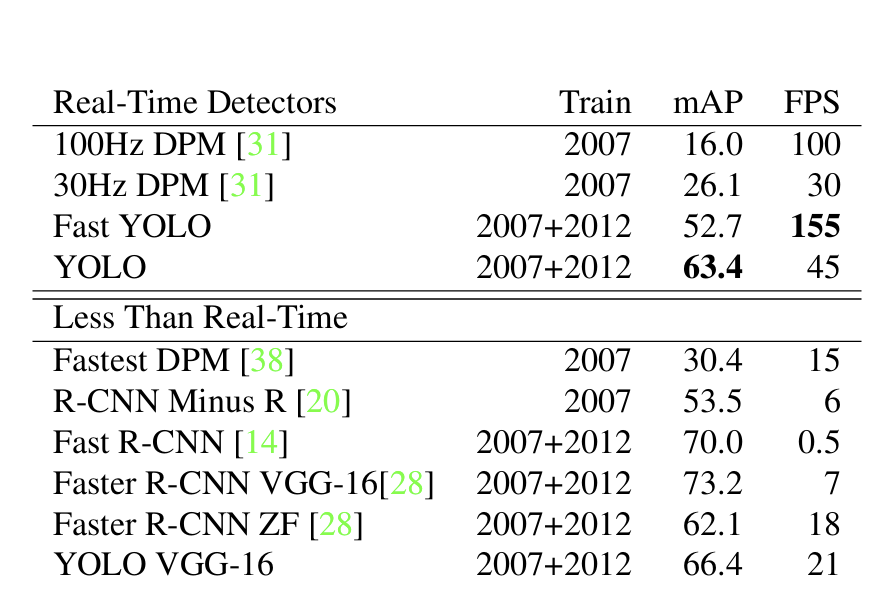
6.1 실시간 탐지 시스템
객체 탐지 모델들의 FPS 뿐만아니라 mAP까지 비교하여 정확도-속도 간의 트레이드오프를 조사합니다.
실시간 탐지 유형들을 비교했을 때 Fast YOLO 가 가장 빠른 속도로 실시간 성능이 뛰어난 것을 확인할 수 있습니다. yolo는 mAP를 63.4% 까지 올리면 가장 높은 정확도를 가집니다.
반면에 DPM은 속도는 준수하지만 mAP 지수에서 너무 낮은 성능을 보입니다.
실시간 탐지가 아닌 유형들을 비교해보겠습니다.
Faster RCNN VGG-16 버전이 mAP 지수가 가장 높지만 일반 YOLO 에 비해 속도가 6배가 느린 것을 확인할 수 있습니다.
6.2 Faster RCNN vs YOLO
Faster RCNN 은 가장 높은 mAP 지수의 성능을 가진 모델입니다. 반면 YOLO 는 속도 측면에서 가장 앞서고 있습니다. 이 둘의 VOC 2007 에서의 결과를 상세히 분석해보겠습니다.
지역화 오류는 YOLO의 오류 중 가장 큰 비중을 차지합니다. Fast R-CNN은 YOLO보다 배경 탐지를 거의 3배 더 많이 예측합니다.
YOLO와 FasterRCNN 을 결합한다면 fasterRCNN 의 배경 오류 문제를 개선하고 YOLO 의 loc 오류를 개선할 수 있을 것으로 보입니다.

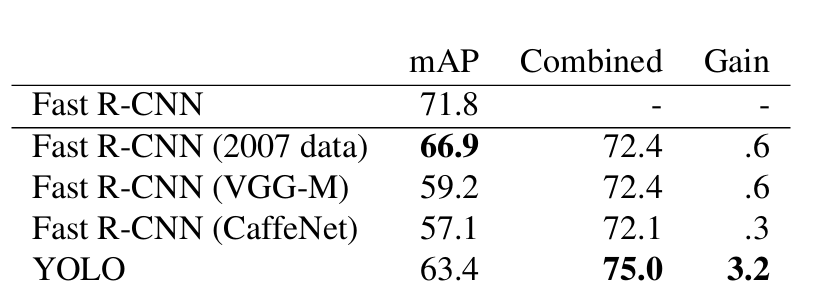
6.3 Faster + YOLO
YOLO를 사용하여 Fast R-CNN의 배경 탐지를 제거하면 성능이 크게 향상됩니다. 또한 Fast R-CNN 모델은 VOC 2007 테스트 세트에서 mAP 71.8%를 달성합니다. YOLO와 결합하면 mAP가 3.2% 증가하여 75.0%가 됩니다.
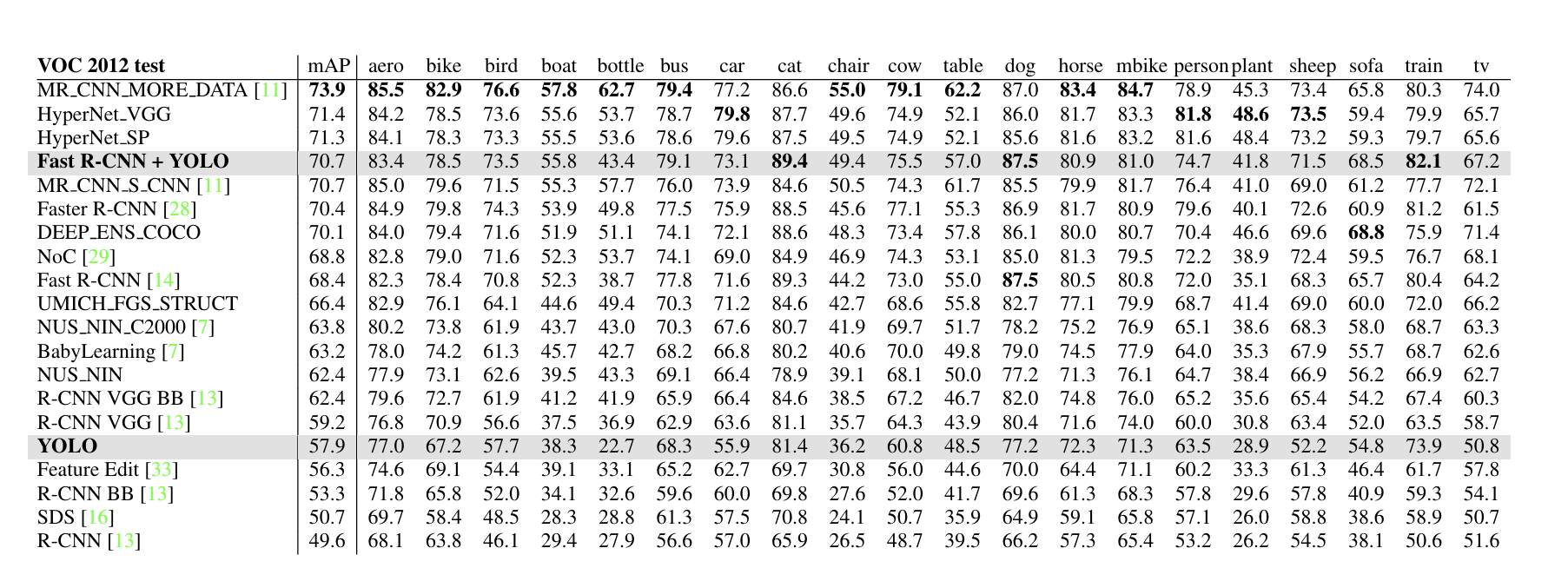
VOC 2012 결과를 확인해보면 Fast R-CNN과 YOLO의 결합 모델은 가장 높은 성능을 보이는 탐지 방법임을 확인할 수 있습니다.
YOLO 의 작은 객체 탐지 정확도가 떨어진다는 문제도 확인할 수 있습니다. bottle, sheep,TV 와 같은 카테고리에서 낮은 점수를 기록합니다. 반면 cat,train같은 다른 카테고리에서는 높은 성능을 보입니다.
6.4 일반화 성능
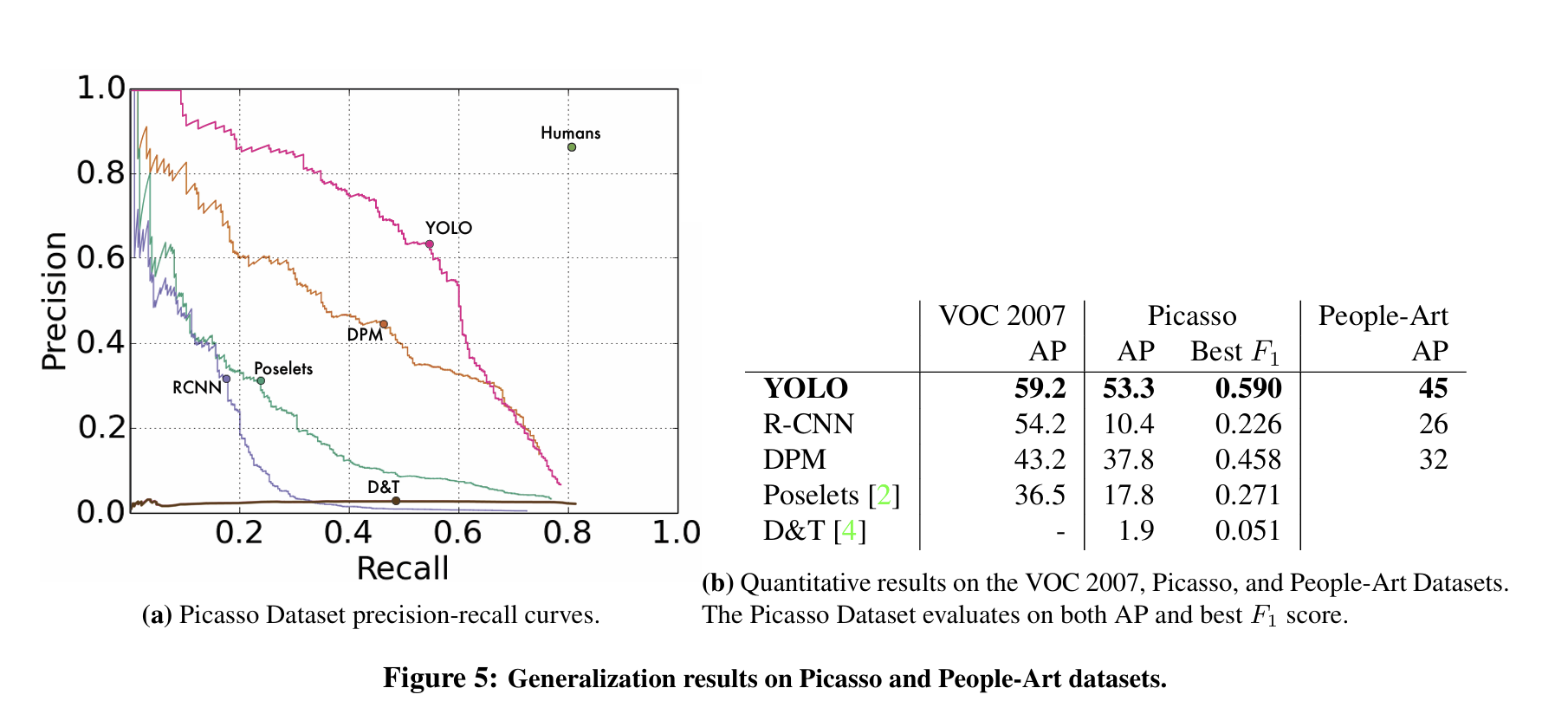
일반적으로 학술 데이터셋은 훈련데이터와 테스트 데이터는 동일한 분포에서 추출됩니다. 실제 응용 사례에서는 예측하기 어렵고 다양한 도메인의 데이터가 모델의 입력이 될 수 있습니다. 다른 도메인의 데이터에서도 준수한 성능을 보이는 지 확인하고자 Picasso Dataset 과 People-Art Dataset 에서 사람을 탐지하는 것을 비교하겠습니다.
YOLO는 VOC 2007에서 최고의 AP와 F1score 높은 점수를 보입니다. 이는 다른 방법들보다 일반화 성능이 좋다는 것을 의미합니다.
7. Conclusion
본 논문은 컴퓨터 비전 분야에서 빠르고 안정적인 새로운 모델인 YOLO(You Only Look Once)를 소개합니다. YOLO는 객체 탐지를 단일 회귀 문제로 프레임화하여, 전체 이미지를 한 번에 평가하여 경계 상자와 클래스 확률을 예측합니다. 이 통합된 아키텍처는 탐지 성능을 최적화할 수 있습니다.
YOLO의 두 가지 주요 변형인 Fast YOLO와 일반 YOLO는 각각 실시간 처리와 준수한 성능을 제공합니다. Fast YOLO는 초당 155 프레임을 처리할 수 있어 실시간 응용 프로그램에 적합하며, 일반 YOLO는 높은 정확도를 유지하면서도 실시간 성능을 제공합니다. 이러한 특성으로 인해, 객체 탐지 모델에 YOLO를 적용하는 것을 고려하는 것이 좋아보입니다.
비교 모델인 Faster R-CNN은 작은 객체 탐지 분야에서 뛰어난 성능을 보이며, 가장 높은 정확도의 성능을 보입니다. 따라서 높은 정확도가 요구되는 분야에서는 Faster R-CNN을 사용하는 것이 적합하며, 실시간 처리가 필요한 응용 분야에서는 YOLO를 사용해야 합니다.
또한, YOLO와 Faster R-CNN을 결합하여 두 모델의 장점을 극대화하고, 정확도와 트레이드 오프, 배경 이미지 오류 등의 단점을 최적화하는 것도 좋은 방법입니다.
이런 방식은 필요 분야의 최적의 객체 탐지 모델을 생성하는 데 큰 도움이 된다고 생각합니다.
출처
You Only Look Once: Unified, Real-Time Object Detection, Redmon et al., 2016–05–09
