
Go 동시성 프로그래밍의 내용을 참고하여 작성했습니다.
파이프라인
파이프라인은 데이터 스트림 처리나 일괄 작업을 할 때 유용하게 사용할 수 있는 추상화 방법입니다. 컴퓨터 과학에서 파이프라인이란, 데이터를 가져와서 그 데이터를 대상으로 작업을 수행하고 결과 데이터를 다시 전달하는 일련의 작업을 말합니다. 파이프라인상의 각 작업은 스테이지라고 부릅니다.
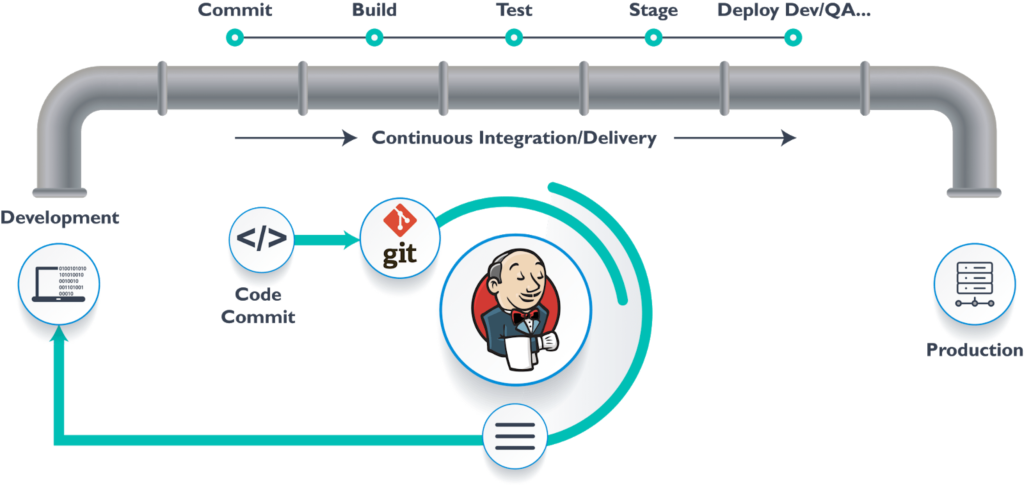
위 이미지는 젠킨스 파이프라인입니다. CI/CD를 위한 일련의 작업을 파이프라인으로 추상화하고 각 작업 단계인 스테이지에 구체적인 작업 내용을 기술하여 CI/CD 작업을 완성합니다.
젠킨스의 예를 보면 알 수 있듯이 파이프라인은 각 스테이지의 관심사를 분리할 수 있어서 많은 이점을 얻을 수 있습니다.
- 상호 독립적으로 각 스테이지를 수정할 수 있음
- 각 스테이지의 수정과 무관하게 스테이지들을 결합할 수 있음
- 각 스테이지를 동시에 처리할 수 있음
- 특정 스테이지를 팬 아웃하거나 속도를 제한할 수 있음
Go 언어에서는 파이프라인 구성을 위해서 주로 채널을 사용하지만, 채널을 이용한 파이프라인 구성의 장점을 알아보기 위해서 먼저 채널을 사용하지 않은 채널을 구성해 보겠습니다.
채널을 사용하지 않은 파이프라인 구성
func main() { multiply := func(values []int, multiplier int) []int { multipliedValues := make([]int, len(values)) for i, v := range values { multipliedValues[i] = v * multiplier } return multipliedValues } add := func(values []int, additive int) []int { addedValues := make([]int, len(values)) for i, v := range values { addedValues[i] = v + additive } return addedValues } // <1> ints := []int{1, 2, 3, 4} for _, v := range add(multiply(ints, 2), 1) { fmt.Println(v) } } <출력결과> 3 5 7 9
multiply 함수는 입력받은 정수 슬라이스를 반복하면서 입력받은 승수를 곱하여 만들어진 결과를 새 슬라이스로 만들어 반환합니다. add 함수도 유사한 구조로 곱셈 대신 덧셈을 한 결과를 반환합니다. 이제 <1>에서 이 둘을 이용하여 정수 슬라이스에 연산을 적용하는 파이프라인을 구성합니다. 위 예제를 통해서 파이프라인의 특성을 유추해 볼 수 있습니다.
- 각 스테이지는 동일한 타입을 소비하고 리턴
- 각 스테이지는 전달될 수 있도록 프로그래밍 언어에 의해 지원되어야 함
Go 언어에서 함수는 고차 함수로 위 두 가지 특성을 잘 지원하고 있습니다. 위 예제에서 multiply, add 함수는 파이프라인 스테이지의 특성을 만족합니다. 이런 특성들로 인해 각 스테이지를 수정하지 않고 스테이지를 결합하는 방법으로 높은 수준의 추상화를 달성할 수 있습니다. 예를 들어 연산으로 변경하고자 한다면 새로운 multiply 스테이지를 추가하기만 하면 됩니다.
ints := []int{1, 2, 3, 4} for _, v := range multiply(add(multiply(ints, 2), 1), 2) { fmt.Println(v) } <출력결과> 6 10 14 18
위 예제에서는 각 스테이지가 각각 일괄 처리를 수행하고 있습니다. 일괄 처리란, 한 번에 하나의 값을 처리하는 대신 모든 데이터를 한 번에 처리한다는 것을 의미합니다. 이를 위해서 각 단계는 아래와 같은 단점이 존재합니다.
- 반환값을 위해 스테이지별로 원본과 동일한 크기의 슬라이스를 생성
- 스테이지별로 각각 반복 처리를 수행
위 예제를 스트림 지향으로 변환해 보겠습니다.
func main() { multiply := func(value, multiplier int) int { return value * multiplier } add := func(value, additive int) int { return value + additive } ints := []int{1, 2, 3, 4} for _, v := range ints { fmt.Println(multiply(add(multiply(v, 2), 1), 2)) } } <출력결과> 6 10 14 18
각 스테이지는 한 번에 하나의 값을 "수신 -> 처리 -> 반환" 하여 메모리 사용량이 파이프라인의 입력 크기로 줄어듭니다. 여기엔 또다시 몇 가지 문제가 있습니다.
- 파이프라인을
for루프 내부로 이동시키고range가 파이프라인에 데이터를 공급하는 책임을 갖게 함 - 이로 인해 파이프라인에 데이터를 공급하는 방식을 재사용 할 수 없으며, 확장성을 제한함
- 루프를 반복할 때마다 파이프라인이 인스턴스화됨
- 아직 다루지 않았지만 각 스테이지를 동시에 실행할 수 없음
채널을 사용한 파이프라인 구성
다음과 같은 이유로 채널은 파이프라인 구성에 적합합니다.
- Go 언어는 채널을 언어의 기본 요소로 지원
- 값을 받아들일 수 있음
- 값을 내보낼 수 있음
- 동시 실행에 안전함
앞선 예제를 채널을 사용하여 재작성 해보겠습니다.
func main() { generator := func(done <-chan interface{}, integers ...int) <-chan int { intStream := make(chan int) go func() { defer close(intStream) for _, i := range integers { select { case <-done: return case intStream <- i: } } }() return intStream } multiply := func( done <-chan interface{}, intStream <-chan int, multiplier int, ) <-chan int { multipliedStream := make(chan int) go func() { defer close(multipliedStream) for i := range intStream { select { case <-done: return case multipliedStream <- i * multiplier: } } }() return multipliedStream } add := func( done <-chan interface{}, intStream <-chan int, additive int, ) <-chan int { addedStream := make(chan int) go func() { defer close(addedStream) for i := range intStream { select { case <-done: return case addedStream <- i + additive: } } }() return addedStream } // <1> done := make(chan interface{}) defer close(done) // <2> intStream := generator(done, 1, 2, 3, 4) // <3> pipeline := multiply(done, add(done, multiply(done, intStream, 2), 1), 2) // <4> for v := range pipeline { fmt.Println(v) } } <출력결과> 6 10 14 18
결과는 동일하지만 몇 배나 많은 코드를 필요로 합니다. 그렇다면 코드가 많아진 것을 대가로 얻게된 것은 무엇일까요?
우선 이제 generator, multiply, add의 3개 함수를 갖습니다. 각 함수는 내부에서 하나의 고루틴을 실행하며, done 채널을 이용해 고루틴의 종료 신호를 기다립니다. 모든 함수는 읽기 전용 정수 채널을 반환하고, multiply, add 함수는 읽기 전용 정수 채널을 입력으로 받습니다.
프로그램은 <1>에서 먼저 done 채널을 만들고 main 함수가 종료되면 채널이 닫힐 수 있도록 처리합니다. 이를 통해서 고루틴이 누수되지 않도록 예방합니다.
그리고 <2>에서 generator 함수를 호출하여 [1, 2, 3, 4]에 대한 읽기 전용 정수 채널을 생성합니다. generator 함수는 내부에서 intStream 채널을 생성하는데, intStream 채널은 입력받은 integers 슬라이스와 같은 크기를 갖는 버퍼링 된 채널입니다. 고루틴을 생성하여 integers 슬라이스를 순회하면서 그 값을 하나씩 intStream 채널에 보냅니다. 정리하면 generator 함수는 정수 값들의 집합을 채널의 데이터 스트림으로 변환합니다. 이런 유형의 함수를 생성기라고 부릅니다. 파이프라인을 시작할 때는 일련의 값을 채널로 변환해야 하는데, 이 때문에 파이프라인 생성 시 자주 생성기를 볼 수 있습니다.
<3>에 코드는 채널을 사용하지 않은 파이프라인 코드와 비슷해 보이지만, 중요한 차이점이 있습니다.
- 채널을 사용
- 파이프라인 출력에서
range구문을 사용해 값을 읽을 수 있음 - 입/출력이 동시에 실행되는 컨텍스트에서 안전함
- 즉, 각 스테이지는 동시성 컨텍스트에서 안전함
- 파이프라인 출력에서
- 각 스테이지가 동시에 실행
이제 끝으로 <4>에서 파이프라인의 결과를 순회하여 처리 결과를 받아옵니다. 아래 표는 파이프라인의 각 스테이지별 입/출력값 및 채널이 닫히는 시점을 보여줍니다.
| for 반복 횟수 | Generator | Multiply | Add | Multiply | 출력 값 |
|---|---|---|---|---|---|
| 0 | 1 | ||||
| 0 | 1 | ||||
| 0 | 2 | 2 | |||
| 0 | 2 | 3 | |||
| 0 | 3 | 4 | 6 | ||
| 1 | 3 | 5 | |||
| 1 | 4 | 6 | 10 | ||
| 2 | (닫힘) | 4 | 7 | ||
| 2 | (닫힘) | 8 | 14 | ||
| 3 | (닫힘) | 9 | |||
| 3 | (닫힘) | 18 |
파이프라인의 각 단계는 입력 채널을 순회하여 데이터를 처리하고 채널이 닫히면 range를 종료합니다. 또한 done 채널이 닫히면 스테이지는 강제로 종료됩니다.
파이프라인 데모
간단한 데모 앱을 만들어 보겠습니다. 전체 소스 코드는 Github에서 확인해 주세요. 발표를 준비하는 과정에서 간단한 데모 앱을 만들었는데, 전체를 구현하는데 시간이 부족해서 정작 파이프라인 구현이 조잡해졌습니다 🥺 추후 시간을 들여서 더 개선해보고 싶지만, 아마도 안 할 겁니다 😈
데모 앱은 이미지 URL과 이미지 프로세싱 옵션을 입력받아서 이미지 프로세싱을 수행한 결과 이미지를 돌려줍니다. 백엔드에서 이미지 프로세싱 과정을 옵션 별로 스테이지로 나누어 구현하고 이를 하나의 파이프라인으로 구성하여 이미지 프로세싱을 구현합니다. 아래는 스크린샷입니다. (아이유님 최고 👍 )
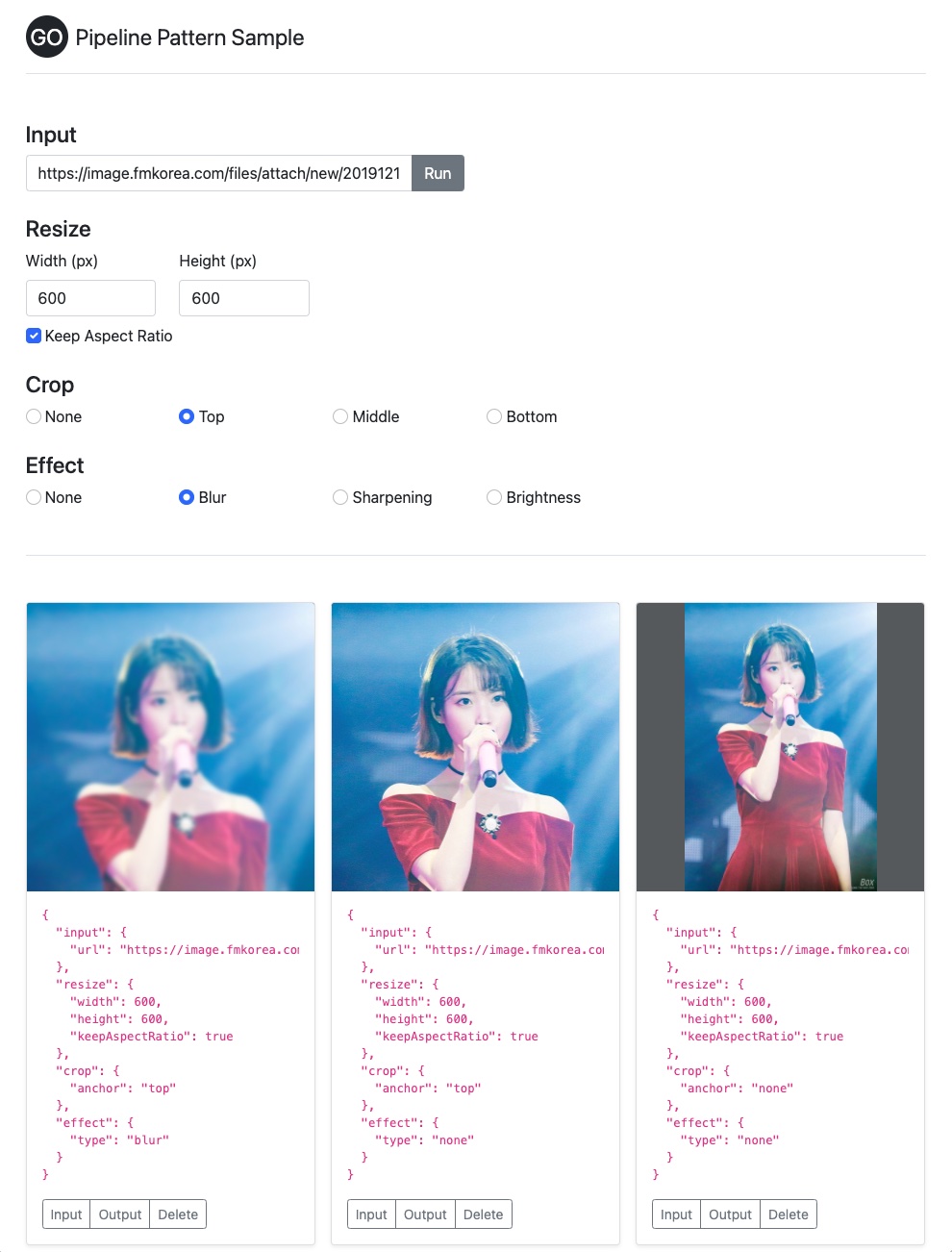
데모앱 구현을 위해서 Echo와 Imaging을 사용했습니다. 여기서는 파이프라인 구성 부분만 간단히 살펴보겠습니다.
type Stage interface { Process(in <-chan *task.Task) <-chan *task.Task }
Stage는 파이프라인상의 스테이지 인터페이스를 정의합니다. Process 함수는 읽기 전용 Task 채널을 받아서 읽기 전용 Task 채널을 반환합니다. Process 구현에서는 해당 스테이지 고유의 연산을 정의합니다.
type Task struct { Spec *spec.Spec Filename string Img image.Image Ticket chan<- *Result }
파이프라인을 통해 흘려보낼 Task를 정의합니다. Spec은 입력받은 이미지 프로세싱 명세서에 해당합니다. Ticket은 파이프라인 작업이 완료되면 결과를 알려주기 위한 목적의 읽기 전용 채널입니다. REST API를 통해서 이미지 프로세싱 작업이 추가될 때 Ticket을 받습니다.
type Resize struct { } func NewResize() *Resize { return &Resize{} } func (r *Resize) Process(in <-chan *task.Task) <-chan *task.Task { out := make(chan *task.Task, cap(in)) go func() { defer close(out) for t := range in { fmt.Println("Resize Stage") r.resize(t) fmt.Println(" - Image Resize Success") out <- t } }() return out } func (r *Resize) resize(task *task.Task) { if task.Spec.Resize.KeepAspectRatio { if task.Spec.Resize.Width != 0 { task.Img = imaging.Resize(task.Img, task.Spec.Resize.Width, 0, imaging.Lanczos) } else { task.Img = imaging.Resize(task.Img, 0, task.Spec.Resize.Height, imaging.Lanczos) } } else { task.Img = imaging.Resize(task.Img, task.Spec.Resize.Width, task.Spec.Resize.Height, imaging.Lanczos) } }
"입력 처리 -> 리사이즈 -> 자르기 -> 효과적용 -> 출력 처리"의 총 5개 스테이지를 갖지만 여기서는 리사이즈 스테이지만 살펴보겠습니다. 리사이즈 스테이지는 Stage 인터페이스를 구현하고 있습니다. Process 메서드에서는 반환값에 해당하는 out 채널을 생성한 후 고루틴을 실행하여 연산을 수행합니다. 이와 같이 스테이지의 각 단계는 동시적으로 실행이 됩니다. 채널을 사용했기 때문에 입/출력이 동시에 발생하는 컨텍스트에서 안전하게 수정됨이 보장됩니다.
Imaging을 사용하는 부분은 그냥 리사이즈 하는구나 하고 생각해 주세요.
const maxQueueTask = 4 var uniqueInstance *executor type executor struct { Queue chan *task.Task Pipeline []Stage } func GetInstance() *executor { if uniqueInstance == nil { uniqueInstance = new(executor) uniqueInstance.Queue = make(chan *task.Task, maxQueueTask) uniqueInstance.Pipeline = []Stage{ stages.NewInput(), stages.NewResize(), stages.NewCrop(), stages.NewEffect(), stages.NewOutput(), } } return uniqueInstance } func (e *executor) Start() { go func() { for { select { case t := <-e.Queue: in := make(chan *task.Task, 1) in <- t close(in) e.processPipeline(in) } } }() } func (e *executor) Enqueue(spec *spec.Spec) <-chan *task.Result { ticket := make(chan *task.Result) e.Queue <- &task.Task{ Spec: spec, Filename: e.randInt(), Img: nil, Ticket: ticket, } return ticket } func (e *executor) processPipeline(in <-chan *task.Task) { var nextChannel <-chan *task.Task for _, pipe := range e.Pipeline { if nextChannel == nil { nextChannel = pipe.Process(in) } else { nextChannel = pipe.Process(nextChannel) } } } func (e *executor) randInt() string { s := rand.NewSource(time.Now().UnixNano()) r := rand.New(s) return fmt.Sprintf("%d", r.Intn(math.MaxInt)) }
이제 개별 스테이지이지를 결합하여 파이프라인을 완성해 보겠습니다. 예제 구현을 단순화하기 위해서 executor 객체를 생성하는 시점에 파이프라인을 생성했습니다. executor.Pipeline 슬라이스에 추가된 스테이지를 processPipeline 메서드가 순서대로 실행시켜 줍니다. Enqueue 메서드는 REST API에서 이미지 프로세싱 요청이 들어온 경우 호출되며, 이미지 프로세싱 요청 Spec을 포함하는 Task 객체를 생성하여 파이프라인 큐 채널에 추가합니다. 채널에 값이 추가되면 Start 메서드에서 실행한 고루틴의 for ~ select 루프가 동작하고 파이프라인이 실행됩니다.
type ImageProcessing struct { } func NewImageProcessing() *ImageProcessing { return &ImageProcessing{} } func (*ImageProcessing) Handle(c echo.Context) error { spec := spec2.NewSpec() if err := c.Bind(spec); err != nil { log.Println(err) return c.NoContent(http.StatusBadRequest) } if err := c.Validate(spec); err != nil { log.Println(err) return c.NoContent(http.StatusBadRequest) } ticket := pipeline.GetInstance().Enqueue(spec) result := <-ticket data, err := ioutil.ReadFile(result.OutputPath) if err != nil { return c.NoContent(http.StatusInternalServerError) } response := base64.StdEncoding.EncodeToString(data) return c.Blob(http.StatusOK, "text/plain", []byte(response)) }
REST API에서는 요청 내용을 확인해서 이미지 프로세싱 Spec을 생성한 후 이미지 프로세싱 요청을 합니다. 이때 Ticket 채널을 받는데, 채널에 입력을 기다리는 것으로 이미지 프로세싱 완료 여부를 수신합니다.
이로써 간단하게 파이프라인 예제를 살펴봤습니다. 간단한 내용이지만, 이미지 프로세싱 요구 사항이 점차 복잡해져도 어렵지 않게 확장해 나갈 수 있도록 추상화되었습니다.
