Attention Is All You Need
Transformer 이전의 흐름
RNN
RNN은 강력한 기억력을 자랑하는 아키텍쳐로 80년대 중반에 처음 선을 보였다.
각 input을 RNN encoder에 넣으면, 그 가공된 정보가 hidden state에 저장되어 전체 문장을 설명하는 sentence embedding을 만들어내는 구조를 가지고 있다.
input = 여우는 | 그릇 | 입구가 | 좁아서 | 그것을 | 결국 | 두루미에게 | 환불했다
encoder : 여우는 | 그릇 | 입구가 | 좁아서 | 그것(?)을
초기의 RNN은 컨베이어 벨트와 같았기 때문에, 순방향으로 단어를 처리하다보면 '그것을'에 도달했을 때 encoder는 그것이 무엇인지 이해할 수 있는 맥락 정보('환불했다')를 포함하지 못한 채 hidden state를 도출했다. 즉, '그것'을 decoding 했을 때의 품질을 보장할 수 없었던 것이다.
- bi-directional RNN
이러한 문제를 해결하기 위해, 순방향뿐 아니라 역방향으로도 encoding을 진행하는 RNN 기법이 제안된다.
forward encoder : 여우는 | 그릇 | 입구가 | 좁아서 | 그것(?)을
backword encoder : 환불했다 | 두루미에게 | 결국 | 그것(?)을
하지만 여전히 문장의 형태에 따라, 전체를 조망하지 않으면 '그것'이 무엇인지 hidden state에 포함할 수 없는 구조적인 문제가 발생했다.
문장이 길어질수록 기울기 소실로 인해 먼저 등장한 단어들은 잊혀지게 되는 Long term dependency 문제도 발생하였다.
이후 LSTM, Seq2Seq와 같은 발전된 형태의 모델이 등장했지만 고정된 크기의 context vector를 사용하기 때문에 병목 현상에 따른 성능적인 한계도 드러나게 되었다.
Attention
따라서 필요한 부분을 조명하는, Attention mechanism이 2015년 등장하며 큰 각광을 받게 된다.
Attention은 타겟을 생성할 때 원본의 여러 부분을 한꺼번에 참고하기 위해 만들어진 구조이다. 그렇다면 '그것'을 번역할 때 '그릇', '환불했다'와 같은 단어를 참고하면 되겠다. 또한, '결국' 같이 그것을 판별하는 데에 관련성이 적은 단어는 적게 참고할 수 있지 않을까?
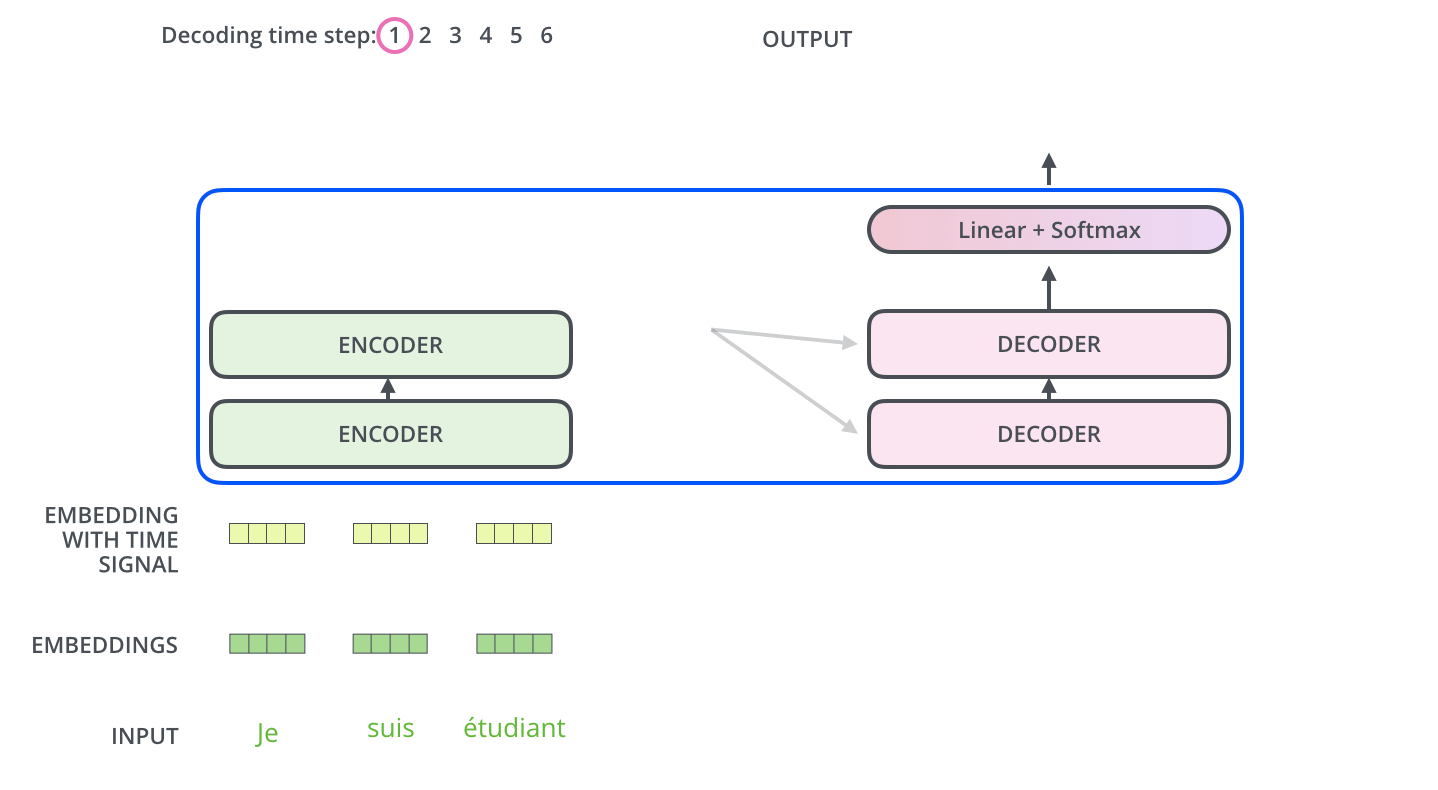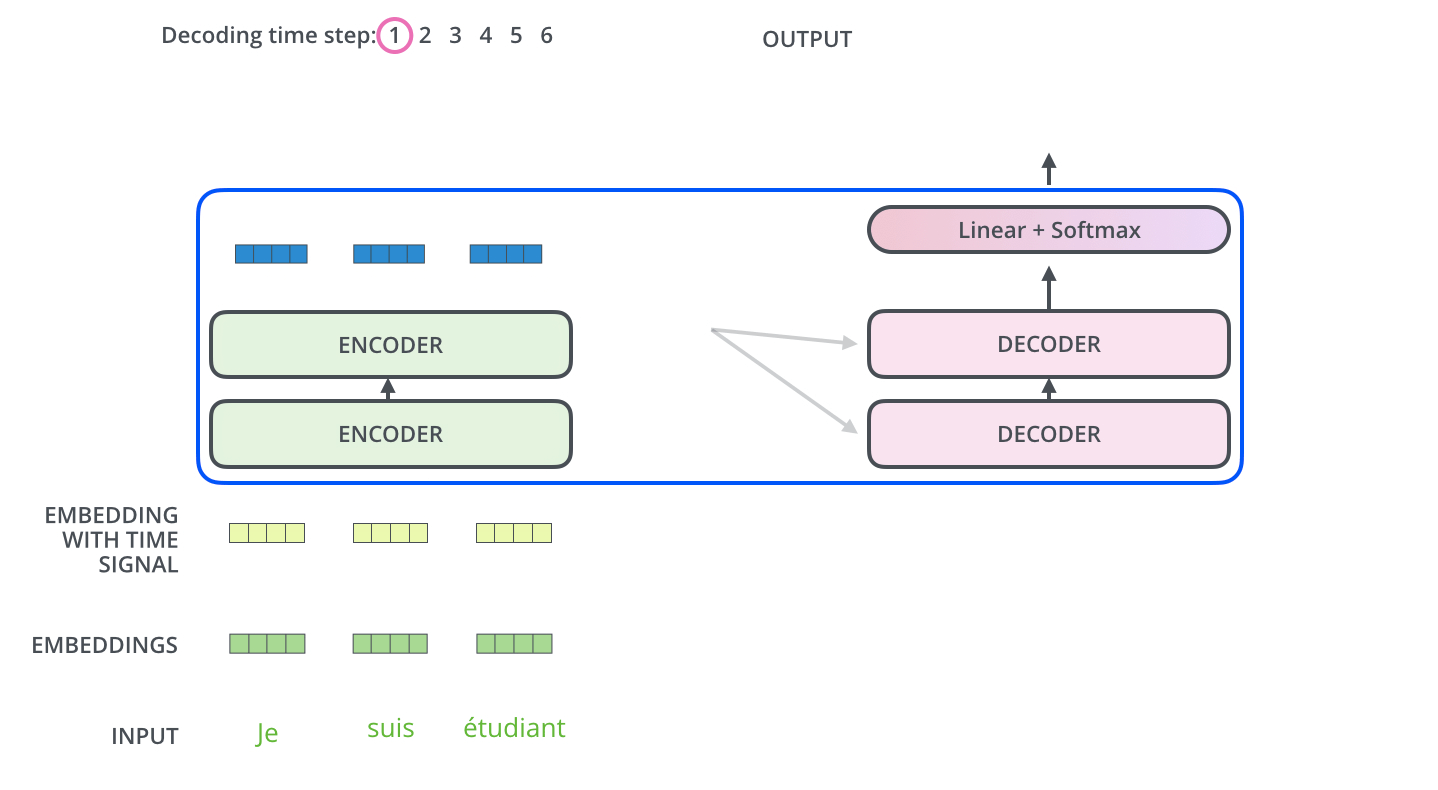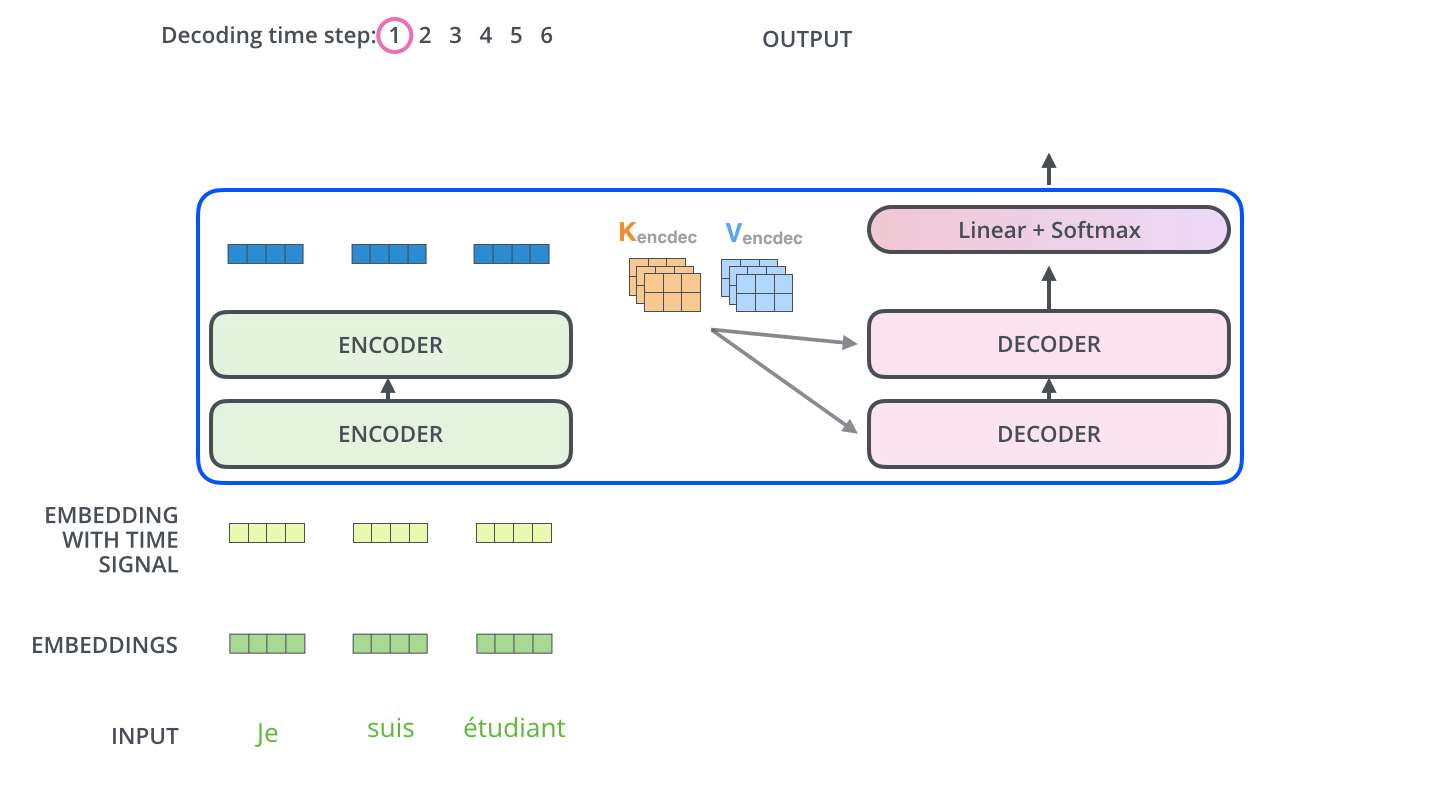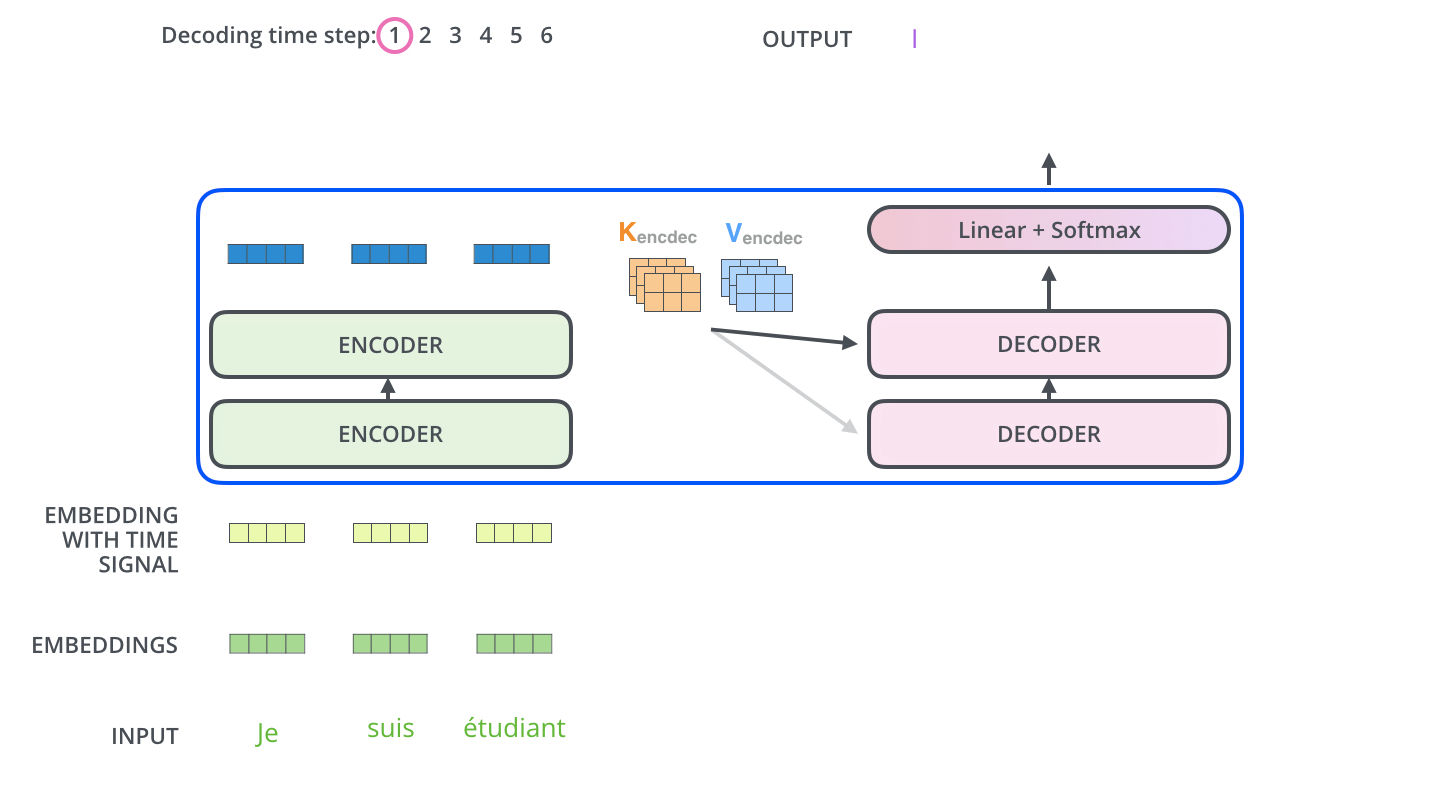
Transformer의 제안
Attention mechanism으로의 전면 전환
Tranksformer의 연구진들은 하나의 질문을 마주쳤다. 'Attension으로 타겟 전후가 모두 고려 가능한데, RNN를 사용해야할까?' 이에 따라 입력 문장 전체에서 정보를 추출하는 방향으로 새로운 아키텍쳐를 개발하게 되었다.
Self-Attention
다시 위에서 사용한 예제를 가져와보자.
input = 여우는 | 그릇 | 입구가 | 좁아서 | 그것을 | 결국 | 두루미에게 | 환불했다
Transformer의 Self-Attention은 타겟을 encoding하기 위해 입력 문장의 다른 단어들을 참조하는 기법이다. 아래 그림처럼 특정 단어와 연관되는 Attention을 시각화해서 확인할 수 있는 툴도 존재한다.

Self-Attention 계산
1. query, key, value 벡터를 생성한다.
2. 3개 벡터 간 연산과정 거친 뒤 softmax를 적용한다. 이때의 softmax 점수는 현재 위치의 endocing에 각 단어들의 표현(피쳐)이 얼마나 들어가는 지를 의미한다.
3. 각 단어 value의 벡터에 softmax 점수를 곱해 weighted value를 생성한다. 이 과정은 관련 없는 단어를 삭제하기 위함이다.
4. weighted value 벡터를 모두 합한 것이 Self-Attention layer의 출력값이 된다.
Multi-headed Attention
위에서 설명한 Self-Attention이 자기 자신의 위치를 잘 설명해준다면, Multi-headed Attention은 Attention layer가 표현할 수 있는 공간을 확장시켜준다. encoder를 쌓아올려 단어의 조합 가지수를 늘려주는 것이다. 즉, input의 '그것'이 무엇인지를 알아내는 데에 매우 유용한 기법이 된다.

Parallelization
Transformer가 가져온 혁신에 Parallelization를 빼놓을 수 없다.
기존의 RNN은 특유의 순차성으로 인해 병목 현상이 발생했다는 점을 기억하자. 이와 달리 Transformer는 어떤 위치에서도 모든 문장을 볼 수 있기 때문에 분산 컴퓨팅이 가능하다는 이점이 있다.
![]()
