※ 지난 게시글(바로가기)에서 이미 추출적 요약을 간단히 다뤘기 때문에, 본 포스팅에는 중복된 내용이 등장할 수 있습니다.
Extractive Text Summarization
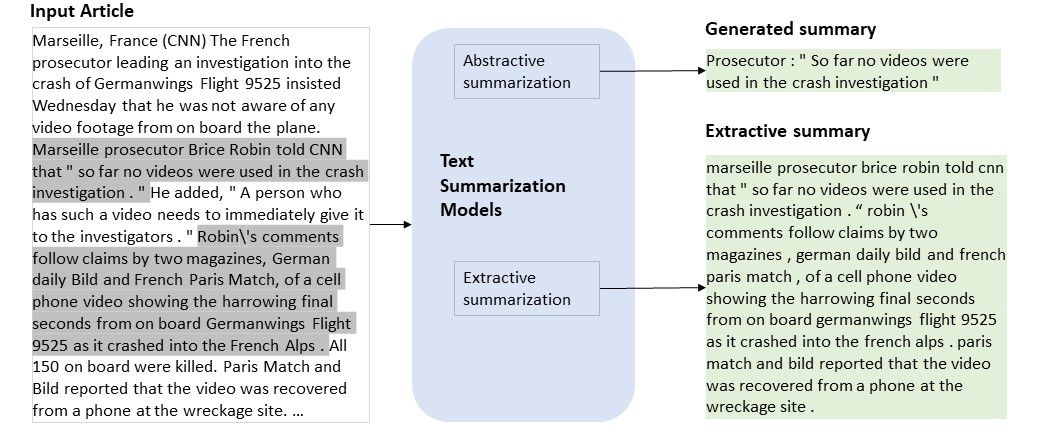
추출적 요약(Extractive Text Summarization)은 말그대로 원문에 있는 중요한 핵심 문장 또는 구를 뽑아 요약 결과를 내는 방식을 말합니다. 원문에 하이라이트를 친 값을 합친 결과를 상상해 볼 수도 있습니다.
추출적 요약이 해결하고자 하는 문제는 무엇인가?
추상적 요약이 여러 예술 도메인에서 활용될 수 있을 거라 기대되듯이, 추출적 요약이 요구되는 분야도 존재합니다.
만약 사실 전달이 중요한 민감한 주제를 다뤄야한다면, 추상적 요약의 결과물이 원문의 의도와 달라질 경우 공급자의 주관으로 오독되는 리스크를 지게될 수도 있습니다. ('올림픽 요약 기사에 왜 한국 선수는 안보이지?') 따라서 원문을 출처삼아 소재를 분명히 밝힐 수 있는 추출적 요약은 그만의 특장점을 갖고 있습니다.
CNN / Daily Mail
오늘 소개할 CNN / Daily Mail 데이터셋은 특히나 다음의 이유에 근거해 추출적 요약에 잘 맞는 데이터라 할 수 있습니다.
- 훈련된 글쓰기 전문가(기자)에 의해 작성
- 기사 본문은 문법적인 오류나 내용 중복이 거의 없음
- 기사 본문은 문서 형식이 갖춰짐
- 기사 본문은 사실에 기반한 정보로 구성됨
CNN / Daily Mail의 구성
총 train set 286,817개, validate set 13,368개, test set 11,487개로 이루어져있습니다.
그 중 train set의 소스 문서는 평균 29.74개의 문장과 766개의 단어로 구성되었으며, 요약은 53개의 단어와 3.72개의 문장으로 구성됩니다.
추가로, 소스 문서는 기사의 제목이 아닌 본문만을 제공합니다. 작업자가 중요도를 산정해 본문을 추상화한 아웃풋인 '기사 제목' 데이터를 함께 학습시키면 더욱 유의미한 결과가 나올지 문득 궁금해집니다.
더 알아보기 : https://github.com/abisee/cnn-dailymail
SoTA Models
MatchSum
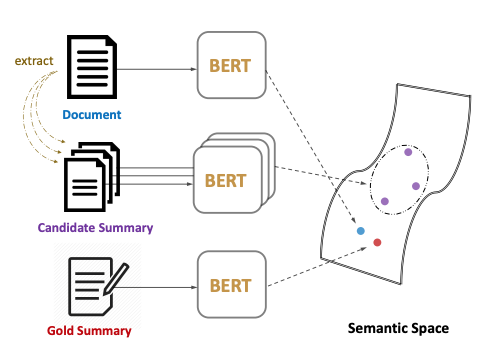
MatchSum은 기존의 문장 간의 관계를 도출하는 방식에서 벗어나, 의미론적 텍스트 매칭 방법론으로 문서를 요약하는 프레임워크입니다.
MatchSum은 두 가지의 요약을 구축하는데, 첫 번째 Candidate Summary는 원문을 요약한 값이고 두 번째 Gold Summary는 이를 수정한 값입니다. Bert를 기반으로 원문과 두 요약값을 의미장에 위치시켜, 원문이 Gold Summary에 일치하도록 조정하는 것이 이같은 절차의 목적입니다.
더 알아보기 : https://arxiv.org/pdf/2004.08795v1.pdf
NeRoBERTa
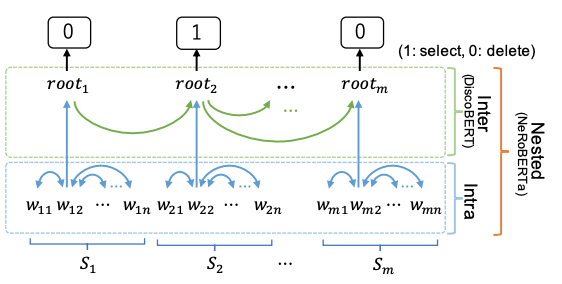
NeRoBERTa는 Nested Tree 기반 추출 요약 모델입니다.
문장 표현 사이의 관계를 포착하기 위해 Nested Tree(통사 트리+담화 트리)를 사용하여, 문장 내부와 문장 간 정보를 모두 고려할 수 있다는 특징을 갖고 있습니다.



수림님 글은 언제나 퀄리티가 좋네요 이해도 빠르게 되고 좋은 글인 것 같습니다. 수고하셨습니다.