프로세스의 생성
프로세스는 실행 중인 프로그램의 인스턴스이다.
운영 체제는 프로세스를 생성, 스케줄링 및 관리하는 책임을 지닙니다.
프로세스 생성은 하나의 프로세스가 새로운 프로세스를 만드는 과정을 말합니다. 이 과정은 일반적으로 시스템 호출을 통해 이루어집니다.
가장 대표적인 시스템 호출은 fork()입니다. fork()는 호출한 프로세스(부모 프로세스)의 정확한 복사본을 생성하는 새로운 프로세스(자식 프로세스)를 만듭니다. 이때, 자식 프로세스는 부모 프로세스의 데이터, 코드, 파일 디스크립터 등을 상속받습니다.
fork() 후에 자식 프로세스는 보통 exec() 계열의 함수를 호출하여 새로운 프로그램을 실행합니다. 이는 자식 프로세스가 부모 프로세스와 동일한 프로그램을 실행하지 않고, 다른 작업을 수행할 수 있게 합니다. exec() 호출은 현재 프로세스의 메모리 공간에 새로운 프로그램을 덮어씌우며, 이 프로그램은 완전히 다른 실행 코드를 가집니다.
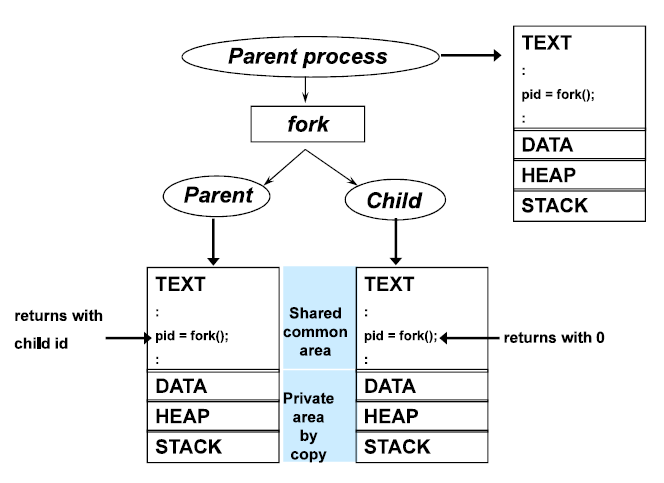
위 그림은 운영 체제에서 프로세스 생성 과정을 시각적으로 설명하는 그림 입니다.
1. 부모 프로세스(Parent process): 실행 중인 원래 프로세스입니다. 이 프로세스는 fork() 시스템 호출을 사용하여 자식 프로세스를 생성
2. fork 시스템 호출: 부모 프로세스가 fork()를 호출하면, 운영 체제는 부모 프로세스의 복사본을 만들어 새로운 자식 프로세스를 생성합니다. 이 호출은 부모 프로세스와 자식 프로세스에게 다른 반환 값을 제공합니다: 부모에게는 자식 프로세스의 PID(프로세스 식별자), 자식 프로세스에게는 0을 반환합니다.
3. 부모와 자식 프로세스: fork() 후에 두 프로세스는 독립적으로 실행됩니다.
다이어그램의 중앙에 있는 파란색 부분은 부모와 자식 프로세스가 공유하는 공통 영역을 나타내며, 일반적으로 코드 섹션이 여기에 해당합니다.
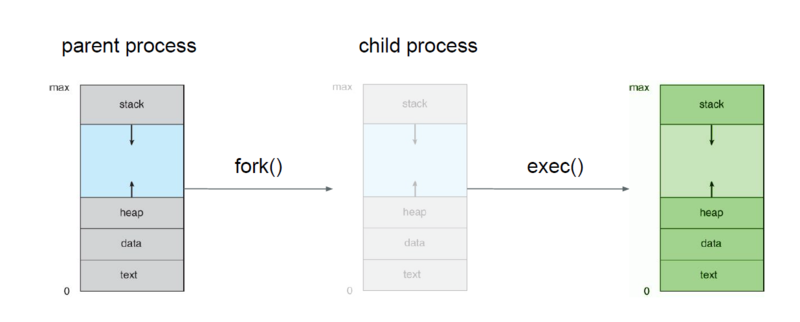
실제로 fork() 호출이 일어나면, 대부분의 현대 운영 체제는 '복사 시 쓰기'(Copy-On-Write, COW) 최적화를 사용합니다. 이는 자식 프로세스가 생성될 때, 실제 메모리의 복사가 일어나지 않고, 부모 프로세스의 메모리 페이지들이 자식 프로세스와 공유될 수 있도록 합니다. 그러나 이것은 단지 초기 상태에서만 적용됩니다.
자식 프로세스가 exec()를 호출할 경우, 새로운 프로그램의 코드가 메모리에 로드되고 기존의 코드 섹션을 대체합니다. 이때, 부모 프로세스의 코드 섹션은 변경되지 않습니다. exec() 호출은 오직 호출한 그 프로세스의 메모리 공간만을 대체합니다.
fork()에 의해 부모와 자식 프로세스가 공유하는 것은 메모리의 초기 상태입니다. 실제로 데이터를 수정하거나 exec() 같은 시스템 호출을 통해 새로운 코드를 로드하면, 그 변경 사항은 해당 프로세스에만 영향을 미칩니다. 이는 부모 프로세스의 메모리 공간은 그대로 유지되고, 자식 프로세스만 새로운 코드로 변경되어 다른 행동을 취하게 됨을 의미합니다.
프로세스 생성 상황 예시
상황 예시: 웹 서버
웹 서버가 있습니다. 이 서버는 클라이언트의 요청을 받아 처리한 후 결과를 반환하는 역할을 합니다. 각 클라이언트 요청을 효율적으로 처리하기 위해, 서버는 각 요청을 별도의 프로세스로 관리하려고 합니다. 이때 fork()와 exec() 시스템 호출이 중요한 역할을 합니다.
-
클라이언트 요청 수신
웹 서버는 클라이언트로부터 요청을 받습니다. 이 서버는 요청을 처리하기 위해 새로운 프로세스를 생성해야 합니다. -
fork()를 사용한 프로세스 생성
서버는 fork() 시스템 호출을 사용해 자기 자신의 복사본, 즉 자식 프로세스를 생성합니다. 이 자식 프로세스는 부모 프로세스(즉, 원래의 서버 프로세스)와 동일한 코드와 데이터를 가지고 있지만, 독립적인 실행 흐름을 가집니다. 이 시점에서, 두 프로세스(부모와 자식)는 거의 동일한 상태를 가지고 있지만, 이후에는 각기 다른 작업을 수행할 수 있습니다. -
exec()를 사용한 프로그램 실행
자식 프로세스는 exec() 계열의 시스템 호출을 사용하여 자신을 클라이언트 요청을 처리할 새로운 프로그램으로 대체합니다. 예를 들어, exec() 호출을 통해 CGI 스크립트나 특정 처리 로직을 실행하는 프로그램으로 자신을 대체할 수 있습니다. 이 과정에서 자식 프로세스의 메모리 이미지는 새 프로그램으로 완전히 바뀌게 되며, 이 프로그램은 클라이언트의 요청을 처리한 후 결과를 반환합니다. -
요청 처리와 프로세스 종료
자식 프로세스는 클라이언트 요청을 처리하고, 결과를 웹 서버를 통해 클라이언트에게 반환합니다. 처리가 완료되면, 자식 프로세스는 종료됩니다(exit() 호출). 부모 프로세스는 자식 프로세스의 종료를 기다리거나(wait() 호출), 다른 클라이언트 요청을 계속해서 수신할 준비를 합니다.
운영체제가 프로세스를 종료하는 경우
- 프로세스가 운영체제의 종료 서비스(exit())를 호출해 정상 종료하는 경우
- 프로세스의 실행 시간 또는 특정 이벤트 발생을 기다리는 시간이 제한된 시간을 초과한 경우
- 프로세스가 파일 검색 또는 입출력에 실패하는 경우
- 오류가 발생하거나 메모리 부족 등이 발생하는 경우
부모 프로세스는 다음과 같은 경우에 자식 프로세스를 종료
- 자식 프로세스가 할당된 자원을 초과해 사용할 때
- 자식 프로세스에 할당된 작업이 없을 때
fork() 함수의 반환값이 두개라는 부분을 이해하기 어려울 수 있으니 시스템 콜을 호출하는 코드를 보고 이해해보자
자식 프로세스에서는 0을 반환: 이는 코드가 현재 자식 프로세스 내에서 실행되고 있음을 나타냅니다.
부모 프로세스에서는 자식 프로세스의 PID(프로세스 ID)를 반환: 이를 통해 부모 프로세스는 생성된 자식 프로세스를 추적하고 관리할 수 있습니다.
에러 발생 시 -1을 반환: fork() 호출이 실패한 경우, 예를 들어 메모리 부족 등의 이유로 새 프로세스를 생성할 수 없는 경우입니다.
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main() {
pid_t pid;
pid = fork(); // fork() 시스템 호출
if (pid == -1) {
// fork() 실패
perror("fork failed");
return 1;
} else if (pid == 0) {
// 자식 프로세스
printf("This is the child process. PID = %d\n", getpid());
} else {
// 부모 프로세스
printf("This is the parent process. PID = %d, Child PID = %d\n", getpid(), pid);
}
return 0;
}
[출력값]
This is the parent process. PID = 12345, Child PID = 12346
This is the child process. PID = 12346
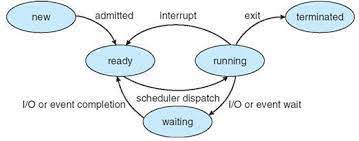
프로세스 상태도
프로세스 상태도(Process State Diagram)는 운영 체제의 프로세스 관리 부분에서 매우 중요한 개념입니다
운영 체제가 프로세스를 효율적으로 관리하기 위해 프로세스의 생명 주기 동안 발생할 수 있는 상태 변화를 추적
생성 (New): 프로세스가 PCB를 가지고 있지만 OS로부터 승인(admit) 받기전
준비 (Ready): OS로부터 승인받은 후 준비 큐에서 CPU 할당을 기다림
실행 (Running): 프로세스가 CPU를 할당받아 실행함
대기 (Waiting): 프로세스가 입출력이나 이벤트 발생을 기다려야 해서 CPU 사용을 멈추고 기다림
종료 (Terminated): 프로세스 실행을 종료함
멀티 프로세스와 멀티 스레드
멀티 프로세스와 멀티 스레드는 현대 컴퓨팅 시스템에서 병렬 처리와 자원 활용을 최적화하기 위해 사용되는 두 가지 기본적인 방식입니다.
이 두 방식은 운영 체제가 작업을 동시에 처리하는 방법에 대한 다른 접근 방식 입니다.
먼저 동시성과 병렬성에 대해 알아보자
동시성과 병렬성
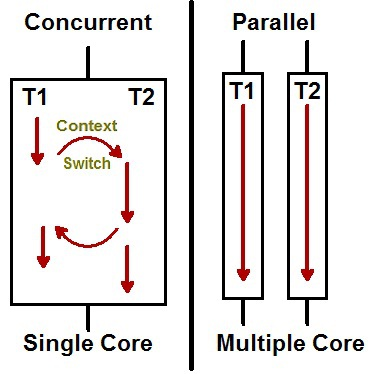
동시성(Concurrency)과 병렬성(Parallelism)은 모두 여러 작업을 동시에 처리하는 방법이지만 차이가 있다.
동시성은 여러 작업이 번갈아 가며 실행되어 동시에 처리되는 것처럼 보이는 것입니다. 이는 작업 처리의 효율성과 응답성 향상에 중점을 둡니다. 하ㅣ나의 CPU에서 여러 작업을 번갈아 가면서 처리하기 위해 처리 중인 작업을 교체하는 것이 콘텍스트 스위칭(context switching)이라고 한다.
병렬성은 여러 작업이 실제로 동시에 실행되는 것으로, 작업 처리의 속도 향상에 초점을 맞춥니다.
멀티 프로세스
멀티 프로세스는 동시에 여러 프로세스(실행 중인 프로그램 인스턴스)를 실행하는 방식입니다. 각 프로세스는 독립된 메모리 주소 공간을 가지며, 한 프로세스의 오류가 다른 프로세스에 영향을 미치지 않아 안정성이 높습니다. 프로세스 간 통신(IPC) 방법을 사용하여 데이터를 교환할 수 있습니다. 하지만, 프로세스 간 컨텍스트 스위칭(context switching)이 비용이 많이 들고, IPC가 상대적으로 복잡하고 공유할 메모리를 직접 참조하는 것보다 비효율적일 수 있습니다.
멀티 스레드
멀티 스레드는 하나의 프로세스 내에서 여러 개의 스레드(실행 흐름)를 동시에 실행하는 방식입니다. 모든 스레드는 부모 프로세스의 메모리, 자원을 공유합니다. 이로 인해 스레드 간의 데이터 공유가 용이하고, 컨텍스트 스위칭 비용이 프로세스에 비해 낮습니다. 그러나, 자원의 공유로 인해 동기화 문제가 발생할 수 있으며, 하나의 스레드에서 발생한 오류가 전체 프로세스에 영향을 줄 수 있습니다.
멀티 스레딩 환경에서 스레드들은 메모리 공간(힙 메모리), 코드 세그먼트 등을 공유 합니다.
반면, 스레드는 자신만의 스택 메모리를 가지며, 이는 함수 호출, 지역 변수 저장 등에 사용됩니다. 스택 메모리는 스레드가 생성될 때 할당되며, 스레드가 종료될 때 해제됩니다.
멀티 스레딩 환경에서 공유 자원의 접근을 관리하기 위해 동기화 메커니즘(예: 뮤텍스, 세마포어, 모니터 등)이 필수적입니다. 이러한 동기화 도구를 사용하여 데이터 일관성을 유지하고, 경쟁 상태(race conditions)를 방지합니다.
콘텍스트 스위칭
콘텍스트 스위칭(context switching)은 컴퓨터 운영 체제가 CPU 사용을 여러 프로세스나 스레드 간에 효율적으로 분배하기 위해 사용하는 기법
이 과정은 현재 실행 중인 태스크(프로세스 또는 스레드)의 상태(콘텍스트)를 저장하고, 다른 태스크의 상태를 CPU에 로드하여 실행 상태로 만드는 것을 포함
콘텍스트에는 프로그램 카운터, 레지스터 세트, 시스템 메모리 주소 공간 등의 정보가 포함됩니다.
콘텍스트 스위칭 과정
현재 실행 중인 태스크의 콘텍스트 저장: CPU는 현재 실행 중인 태스크의 상태를 프로세스 제어 블록(PCB)에 저장합니다.
다음 실행할 태스크의 콘텍스트 로드: 스케줄러가 결정한 다음 태스크의 PCB로부터 필요한 정보를 CPU에 로드합니다.
새 태스크 실행: CPU는 로드된 새 태스크의 실행을 시작합니다.
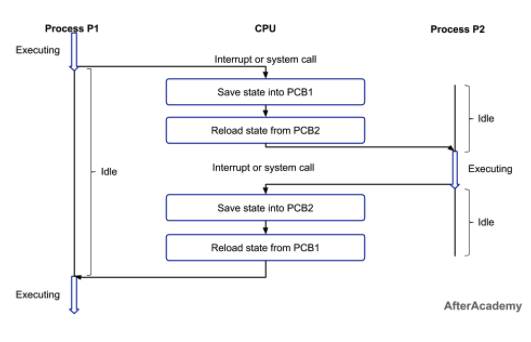
CPU에서 처리 중인 프로세스가 중간에 변경되어도 이전에 실행하던 코드를 이어서 실행 할 수 있는 이유는 PCB에 프로그램 카운터와 스택 포인터 값이 저장되어 있기 때문이다.
프로그램 카운터(PC)는 프로세스가 이어서 처리해야 하는 명령어의 주소 값이고, 스택 포인터는 스택 영역에서 데이터가 채워진 최상단(스택의 가장 낮은 메모리)주소값을 가르킨다.
프로그램 카운터(PC)
프로그램 카운터는 현재 프로세서가 실행 중인 명령어의 주소를 가리키는 레지스터입니다. CPU가 명령어를 실행할 때마다 PC는 자동으로 다음 명령어의 주소로 업데이트됩니다. 이를 통해 CPU는 프로그램의 코드를 순차적으로 실행할 수 있습니다.
스택 포인터(SP)
스택 포인터는 프로그램의 메모리 내 스택 영역의 최상단을 가리키는 레지스터입니다. 스택은 함수 호출, 지역 변수 저장, 함수 호출 시의 인자 전달 등에 사용되는 메모리 구조로, LIFO(Last In First Out) 방식으로 작동합니다. 함수 호출 시, 반환 주소, 파라미터, 지역 변수 등이 스택에 저장되며, 이러한 작업이 발생할 때마다 SP는 새로운 스택의 최상단을 가리키도록 업데이트됩니다. 함수가 반환될 때, SP는 다시 이전 위치로 복귀하여 함수 호출 전의 상태를 복원합니다.
레지스터(register)
레지스터(register)는 컴퓨터 프로세서 내부에 있는 매우 빠른 속도로 데이터를 저장할 수 있는 작은 메모리 단위
이들은 CPU가 프로그램을 실행하는 동안 임시 데이터를 저장하거나, 계산 중에 사용되는 값을 보관하는 데 사용됩니다. 레지스터는 CPU의 작업 효율성을 크게 향상시키는 역할을 합니다.
-
범용 레지스터(General Purpose Registers): 다양한 종류의 데이터를 저장할 수 있는 레지스터입니다. 산술 연산, 데이터 이동, 메모리 주소 지정 등 여러 목적으로 사용됩니다.
-
특수 레지스터(Special Purpose Registers): 특정 기능을 위해 사용되는 레지스터입니다. 예를 들어, 프로그램 카운터(Program Counter, PC), 스택 포인터(Stack Pointer, SP), 상태 레지스터(Status Register) 등이 있습니다.
프로세스 제어 블록(Process Control Block, PCB)
운영 체제가 프로세스를 관리하기 위해 사용하는 중요한 자료 구조입니다. PCB는 특정 프로세스에 대한 중요한 정보를 저장하며, 프로세스가 실행 중이거나 실행 대기 중일 때 그 상태를 추적하는 데 사용됩니다. 운영 체제의 스케줄러와 프로세스 관리자는 PCB를 참조하여 프로세스 간의 전환(context switching)을 수행하고, 시스템의 자원 할당 및 회수를 관리합니다.
PCB에 저장되는 정보는 다음과 같은 여러 종류가 있습니다:
1. 프로세스 식별자(Process Identifier, PID)
각 프로세스에 고유하게 할당된 식별 번호입니다. 이 번호를 통해 운영 체제는 프로세스를 구별하고 관리합니다.
2. 프로세스 상태(Process State)
프로세스의 현재 상태(예: 실행 중, 대기 중, 준비 완료, 중지됨 등)를 나타냅니다. 운영 체제는 이 정보를 기반으로 프로세스 스케줄링을 결정합니다.
3. 프로그램 카운터(Program Counter, PC)
프로세스가 다음에 실행할 명령어의 주소를 가리킵니다. 프로세스가 실행을 재개할 때, 이 위치부터 실행이 시작됩니다.
4. 레지스터 세트(Register Set)
CPU 레지스터의 현재 값을 저장합니다. 이 값들은 프로세스가 중단될 때 저장되고, 프로세스가 다시 실행될 때 복원됩니다.
5. 프로세스 우선순위(Process Priority)
프로세스 스케줄링에 사용되는 우선순위 정보입니다. 우선순위가 높은 프로세스는 낮은 우선순위를 가진 프로세스보다 먼저 실행될 가능성이 높습니다.
6. 메모리 관리 정보(Memory Management Information)
프로세스가 사용하는 메모리 영역의 주소, 메모리 할당량 등 메모리 관리와 관련된 정보를 포함합니다.
PCB는 운영 체제의 커널 영역에 저장됩니다.PCB는 운영 체제가 프로세스의 정보를 관리하기 위해 필요한 중요한 데이터 구조이기 때문에, 안정적이고 보안이 유지되는 메모리 영역인 커널 공간에 위치하는 것이 필수적입니다.
PCB는 프로세스의 생성 시점에 생성되며, 프로세스가 종료되면 해당 PCB는 운영 체제에 의해 삭제됩니다. PCB를 통해 운영 체제는 프로세스에 대한 중요한 정보를 효율적으로 관리하고, 시스템의 안정성과 성능을 유지할 수 있습니다.
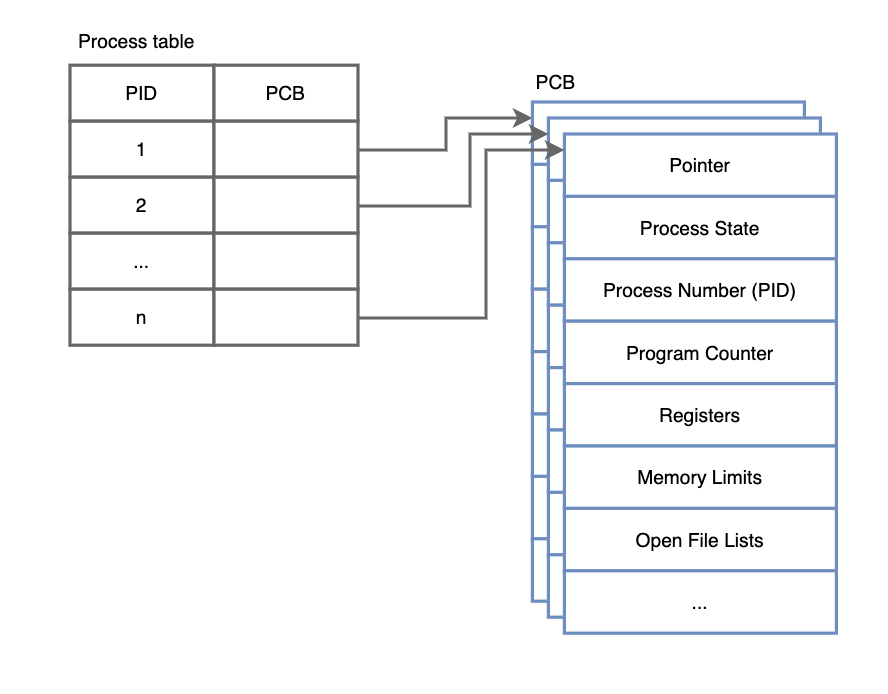
운영 체제는 PCB 리스트나 테이블을 관리하여, 현재 시스템에서 실행 중이거나 실행 대기 중인 모든 프로세스의 PCB를 추적합니다.
인터럽트
프로세스 또는 하드웨어로부터의 신호로서, 현재 실행 중인 작업을 잠시 중단시키고, 긴급하게 처리해야 할 작업(인터럽트 서비스 루틴)을 처리한 후, 원래의 작업으로 돌아가 계속 실행할 수 있게 하는 기능
인터럽트는 운영 체제가 다양한 I/O 장치와 효율적으로 통신하게 하고, 비동기적인 이벤트들을 관리할 수 있게 해줍니다.
하드웨어 인터럽트: 주변 장치나 하드웨어로부터 발생한 인터럽트로, 예를 들어 키보드 입력이나 네트워크 패킷 수신과 같은 외부 이벤트에 의해 발생합니다.
소프트웨어 인터럽트(예외): 프로그램 실행 중에 발생하는 인터럽트로, 잘못된 명령어 실행, 분할 오류, 또는 사용자 정의 인터럽트 요청(SWI) 같은 내부 이벤트에 의해 발생합니다.
인터럽트 처리 과정
1. 인터럽트 발생: 프로그램 실행 중에 하드웨어 또는 소프트웨어 인터럽트가 발생합니다.
2. 현재 실행 중인 작업 중단: 현재 CPU가 처리하고 있는 작업의 상태를 저장합니다.
3. 인터럽트 서비스 루틴(ISR) 실행: 인터럽트에 해당하는 처리 루틴(인터럽트 핸들러)을 실행합니다.
4. 원래 작업으로 복귀: 인터럽트 처리가 완료되면, 중단되었던 작업의 상태를 복구하고 작업을 계속 진행합니다.
인터럽트의 중요성
1. CPU는 인터럽트를 통해 I/O 작업과 같이 대기 시간이 긴 작업을 처리하는 동안 다른 작업을 수행할 수 있어 자원 활용도를 높일 수 있습니다.
2. 사용자 입력과 같은 중요한 이벤트에 대해 신속하게 반응할 수 있게 해줍니다.
