산업 협력 과제로 진행했던 Voice Assistant Android Application 개발 과정을 포스팅하겠습니다.
프로젝트 시연 영상도 같이 포스팅하고 싶지만 내부적인 보안 때문에 겪었던 문제상황과 고민에 대해 어떻게 해결방안을 생각하고 진행했는지를 위주로 적어보겠습니다.
일단 제안 받았던 목표는 약 20개의 명령어를 인식하고 굴삭기 동작을 제어하는 Voice Assistant를 개발하는 것이였습니다.
굴삭기 소음속에서도 음성인식이 잘 이루어져야한다는 것과 네트워크가 연결되지 않은 상황에서도 동작 해야한다는 것과 STT를 이용했으면 좋겠다는 프로젝트의 복잡한 요구사항들은 적절한 애플리케이션 설계에 대한 깊은 고민을 필요로 했습니다.
문제 상황 및 해결
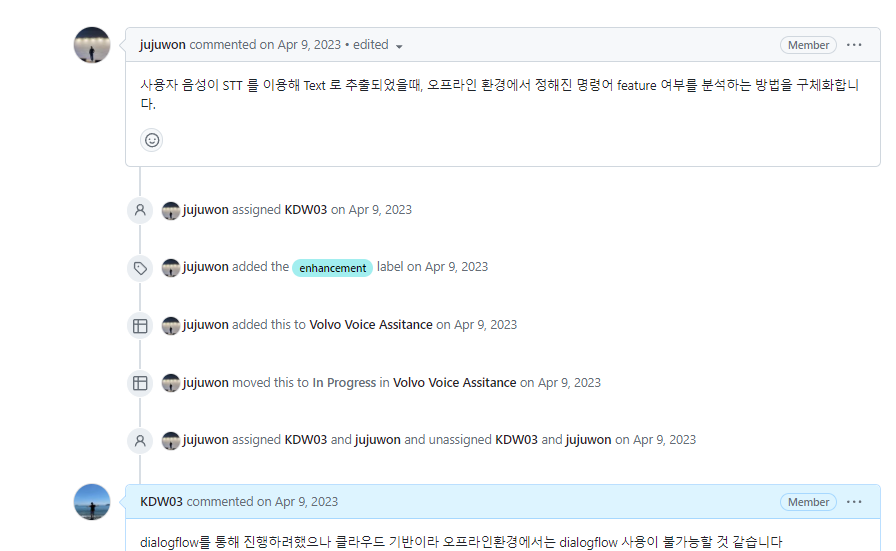
1. On-Device AI 도입 결정
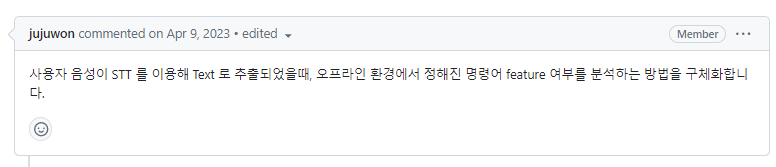
초기에는 AI 모델을 고려했습니다 하지만 데이터 수집의 문제로 저희 팀은 약 20개의 명령어를 분류하기 위해, 사용자 음성 입력의 형태소 분석 방식을 시도했습니다. (다들 친구인데 GITHUB에서 존댓말 쓰는거 조금 킹받는 포인트 감안)
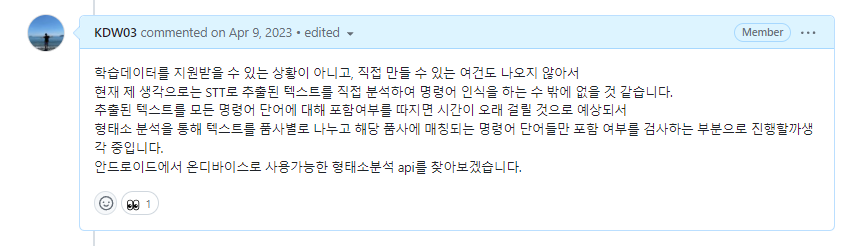
그러나 실제 현장에서 굴삭기 소음에 Android STT를 테스트해 봤을 때, 소음의 크기가 예상보다 매우 커서 STT를 통해 추출된 텍스트가 의도대로 나타나지 않는 것을 확인했습니다.
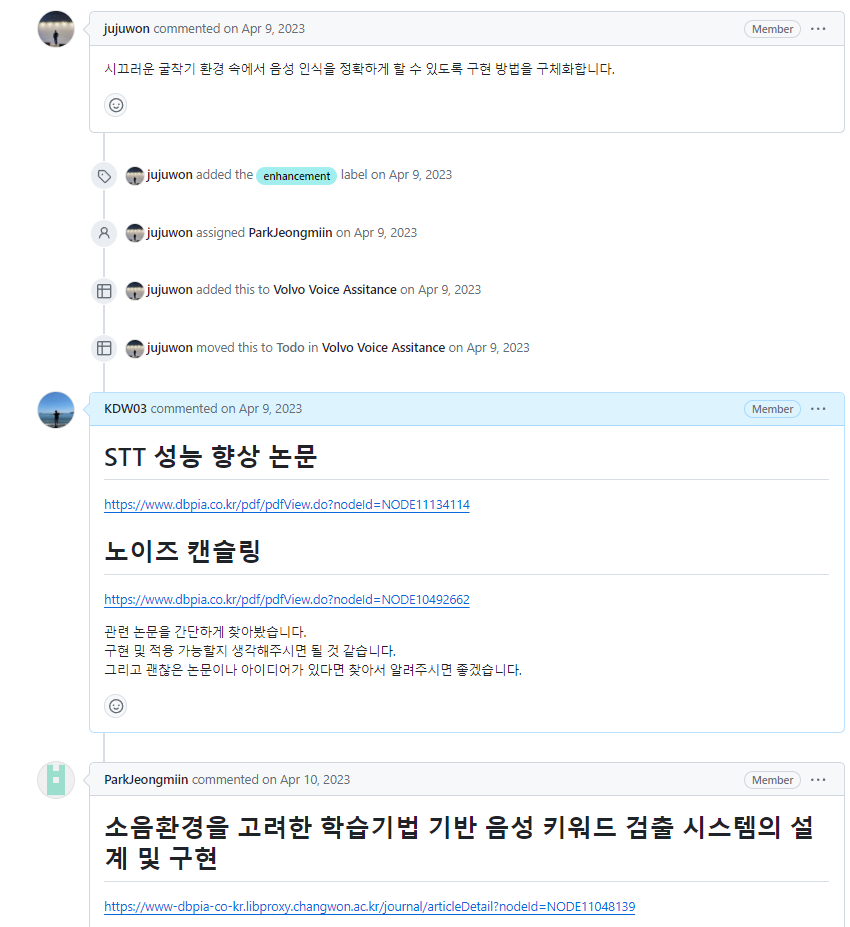
저희 팀은 소음 속 음성인식 정확도 개선 방법을 고민하였습니다. 여러 논문과 자료를 찾아보며 고민했지만 하드웨어가 아닌 오직 소프트웨어적으로, 제한된 시간 내에 이 소음 문제를 해결하는 것은 매우 어려운 문제였습니다.
그러던 중 연구실에서 AI세미나를 진행하며 이 문제를 다른 접근 방식으로 해결할 수 있을 것이라는 아이디어가 떠올랐습니다.
저는 다시 AI를 활용한 방법에 접근하였고 이를 통해 문제를 다른 접근 방식으로 해결할 수 있을 것이라는 아이디어가 떠올랐습니다. 저는 문제 해결을 위해 데이터 증강에 주목했습니다.
1.1 소음에 대응하는 데이터 증강
“현재 문제 상황을 고려했을 때 어떤 데이터를 학습시켜야 소음속에서도 잘 동작할까” 고민을 했고 소음속에서 나타나는 STT의 잘못된 결과들을 보았을 때
최종적으로 SR(특정 단어를 유의어로 교체하는 방식),(RI, RD)임의의 단어를 삽입(Insertion)하거나 삭제(Deletion)하는 방식,RS(문장 내 임의의 두 단어의 위치를 바꾸는 것)등의 텍스트 데이터 증강 기법을 사용하였습니다.
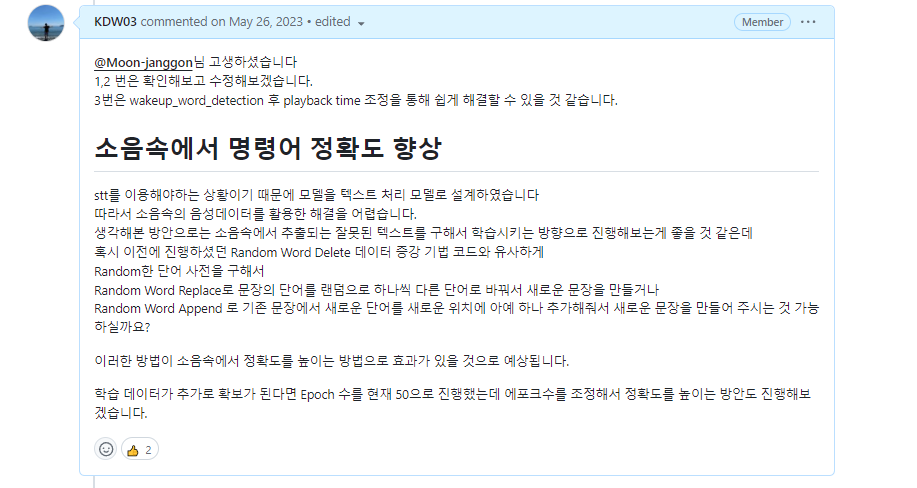
결과적으로 텍스트 데이터 증강 기법을 통해 초기 2000개의 데이터를 500만개 까지 늘어났습니다.
하지만 또다른 문제로 이렇게 증강한 큰 데이터로 학습을 진행할 때 제 컴퓨터로는 너무 느리다는 것이 였습니다. 다행히도 연구실에 사양이 좋은 컴퓨터가 있어서 그것으로 진행하려했지만 구현환경이 해당 컴퓨터에서는 제대로 구축이 되지않았습니다.

여러 방법을 시도해도 해결이 잘 되지 않았지만 그때 마침 제가 교내 전공 수업으로 DOCKER에 대해 배우고 있었습니다. 그래서 해당 컴퓨터에 DOCKER을 깔아 TENSORFLOW 이미지로 컨테이너를 설치해 성공적으로 학습환경을 구축해서 학습을 진행하였습니다.
2. WAKE-WORD-DETECTION 도입 결정
STT를 지속으로 작동시키면서 사용자의 음성 인식의 시작을 기다리는 것이 매우 리소스적으로 낭비가 심하고 자잘한 버그가 많다는 것이 였습니다.
다시 관련 논문들을 살펴보며 WAKE-WORD-DETECTION이라는 기술이 있다는 것을 발견하였습니다.
2.1 WAKE-WORD-DETECTION 과 STT 충돌 해결
그래서 관련 기술 중 온 디바이스 환경에서 작동이되는 오픈소스를 선택해 ANDROID에 내장시켜 결과적으로 해당 문제를 해결하였고 이 과정에 WAKE-WORD-DETECTION과 STT간의 충돌이 있는 이슈가 있었지만 playback time을 조정하는 방식으로 이 문제를 해결할 수 있었습니다.
결과적으로 90% 이상의 정확도로 소음속에서도 명령어를 구분할 수 있었습니다.
느낀점
굉장히 중간에 기술적인 문제 굉장히 많았습니다. 포기하지 않고 문제를 극복하는 자세와 다양한 방면으로 지식을 얻으면서 발상을 전환해가는게 중요하다는 것도 느꼈습니다.
나름 재밌고 기억에 가장 남는 프로젝트 중 하나였습니다..
보안상 많은 부분에 제약이 많아서 아쉬움이 많이 남는 프로젝트 중 하나이기도 합니다.
안드로이드 텐서플로우 라이트에 대해 궁금한 분은 제 이전 관련 글을 참고하시면 도움이 될 수도?..
