목표 및 방향
은 정확도의 안구 질환 진단 모바일 애플리케이션을 개발하여, 사용자가 직접 반려동물의 안구 사진을 분석하고 질환 유무를 신속하고 정확하게 판단할 수 있도록 한다. 이 앱은 안드로이드 플랫폼에서 동작한다. 이를 통해 보호자의 시간, 공간, 경제적 부담을 완화하고, 반려동물의 건강을 증진시킨다.
모델 선정
과적합과 계산 리소스의 문제를 해결하기 위해, 반려동물 안구 질환의 정밀한 조기 진단을 위해 EfficientNet과 ResNet 모델을 적용하였다. 이 두 모델은 작은 데이터셋에도 효과적이며, 복잡한 패턴을 가진 질환을 정확히 분류하는 데 높은 성능을 보였다.
과적합과 연산 복잡도 사이의 트레이드 오프를 고려하여 안구 질환 분류의 정확성을 높이기 위해 ResNet-50, EfficientNet-B4 모델을 선택
측정 지표
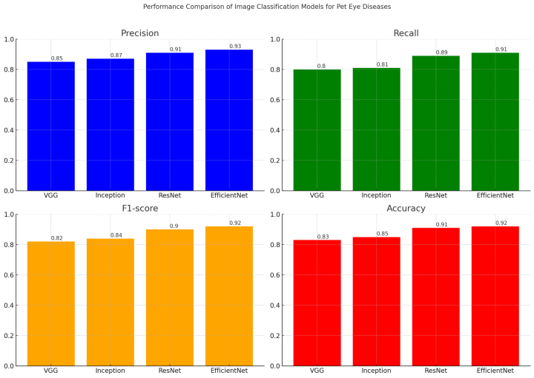
- 정확도(Accuracy)는 가장 기본적인 성능 지표
- 정밀도(Precision)는 모델이 특정 질병으로 진단했을 때, 그 진단이 얼마나 정확한지를 나타내는 지표이다. 예를 들어, 모델이 "백내장"이라고 진단했을 때 실제로 백내장인 경우의 비율을 알려줍니다. 이는 오진을 최소화하는 것이 중요할 때 중요한 지표로 작용
- 재현율(Recall)은 실제로 특정 질병을 가진 반려동물 중, 모델이 얼마나 많이 그 질병을 감지했는지를 나타내는 지표이다. 재현율이 높다면 실제 질병을 가진 동물을 놓치지 않고 거의 대부분을 감지해낼 수 있다는 것을 의미
- F1-Score는 정밀도와 재현율의 균형
데이터
데이터셋은 AIHUB에서 제공된 반려동물 안구질환 데이터
반려견 12종과 반려묘 6종의 안구질환 데이터를 사용하였다. 전체 데이터셋은 약 300,000장의 이미지로 구성
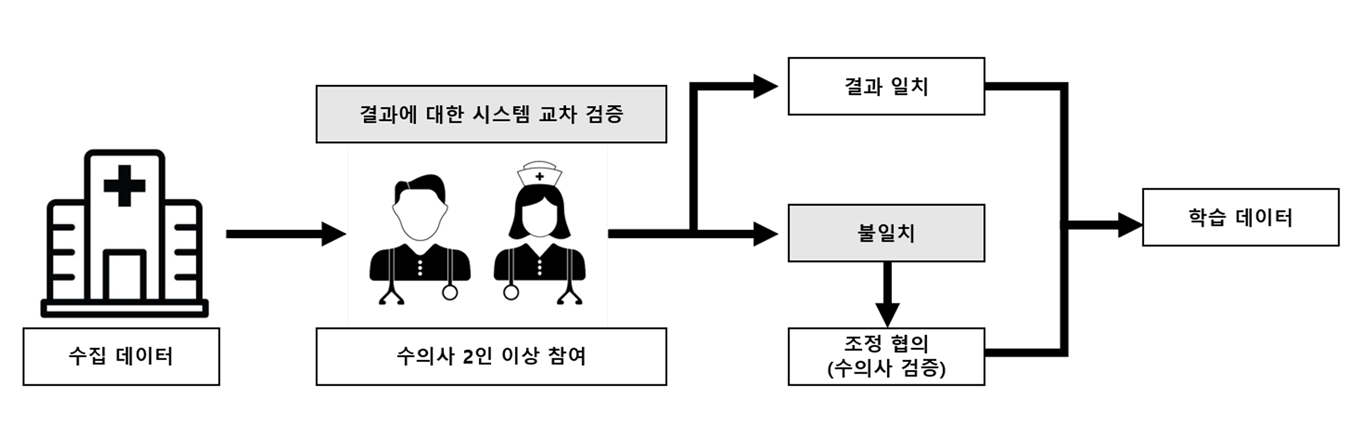
각 질환의 세부 라벨링 과정은 전문 수의사들의 1차 및 2차 검토를 통해 진행되었고, 이 과정은 데이터의 신뢰성을 확보하는 데 중요한 역할을 한다. 교차 라벨링 방법의 적용은 라벨링의 일관성과 정확도를 높이는 데 크게 기여
데이터 증강
- 각도 조절: 이미지를 10도, 20도 등 다양한 각도로 회전시켜 데이터를 확장하였다. 이는 반려동물의 움직임과 사용자의 촬영 각도에 따른 다양성을 반영하기 위함이다.
- 확대/축소: 이미지를 0.9배, 1.1배 등의 비율로 확대 및 축소하였다. 사용자가 다양한 거리에서 사진을 찍을 수 있으므로, 이러한 다양한 환경을 반영하기 위해 확대 및 축소를 진행하였다.
- 좌우 대칭: 이미지를 수평으로 뒤집어 좌우 대칭 데이터를 생성하였다. 이는 사진을 찍는 방향의 다양성을 반영하여, 모델이 이미지의 방향에 관계없이 안구 질환을 인식할 수 있도록 하기 위함이다.
- 무작위 노이즈 추가: 마지막으로 무작위 노이즈를 추가하여 실제 사용 시의 다양한 환경을 반영하였다. 스마트폰 촬영 시 발생할 수 있는 잡음이나 환경적 노이즈를 모방하기 위해 추가하였다.
데이터 분할
전체 데이터 중 70%는 학습, 15%는 검증, 15%는 테스트 데이터로 분할
분할은 Stratified Random Sampling 방법을 사용하여 질병 라벨 기반으로 균등하게 분할
최적화
SGD VS Adam
SGD는 로컬 최소값에서 벗어나는 능력이 우수하여 장기적 학습에 적합한 반면, Adam은 빠른 초기 수렴이 가능하지만 복잡한 데이터에서 로컬 최소값에 갇힐 위험
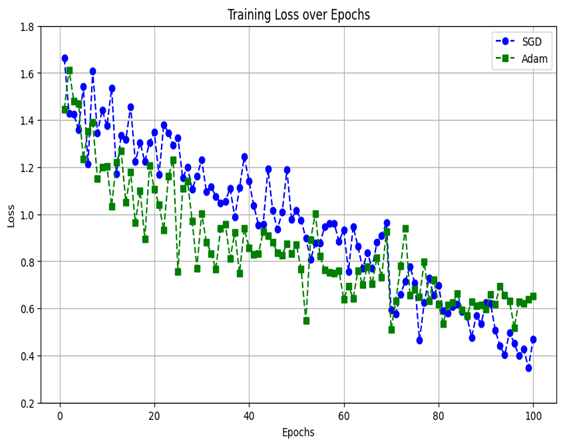
SGD가 복잡한 반려동물 안구 이미지 데이터셋에 대해 Adam보다 우수한 성능을 보여 SGD를 최적화 기법으로 선택
다양한 최적화 전략
데이터 증강, 배치 정규화, 드롭아웃, 그리고 이른 종료(Early Stopping)와 같은 최적화 전략을 적용하여 모델의 성능을 향상시키고 과대적합을 방지
