해당 글은
자연어 처리 바이블(임희석 저) 에서 참고하여 작성되었음을 알려 드립니다.목차
1. 질의응답의 배경과 단계
2. 질문처리단계
3. 문서처리단계
4. 정답처리단계
1. 질의응답의 배경과 단계
정의: 사용자가 필요한 정보를 자연어 질문으로 입력하였을 때, 질문에 부합하는 정답을 문서로부터 찾아서 제시하는 기술
구성 기술
- 자연어처리
- 정보추출
- 정보검색
분류
- 정보검색 질의응답 => 본 게시물에서 중점을 둘 부분
- 지식기반 질의응답
- 딥러닝 활용 질의응답 => 추후에 자세히 설명할 예정
정보 검색 기반 질의 응답의 단계
1) 질문처리단계 => 질문융형 분류와 정답 유형분류 진행
2) 문서처리단계(문서 검색) => 정답과 관련성이 높은 문서들을 탐색
3) 정답처리단계 => 정답후보추출, 정답순위화
2. 질문처리단계
질문이 무엇인지 이해하는 것이 핵심!
질문유형분류와 정답유형분류는 의문사를 이용한다는 점에서 강한 연관성을 갖는다.
- 질문 유형 분류
- 의문사를 기반으로 질문을 구분
- 정답 유형 분류
의문사는 질문의 정확한 정답유형을 결정짓지 못하지만, 중요한 제약정보로서 활용정답유형이란 사용자가 찾고자하는 정보가 무엇인지를 의미- 해당 과정에서는 의문사 정보와 개체명 태그, 형태소 분석 결과를 활용
- 질의 재생성
- 사용자의 질문에 가장 적당한 정답유형을 인식하는 것은 classification으로 귀결
- 그러나 질문은 단문이기 때문에 분류 문제를 해결하기에 단서가 부족(이를 보완하기 위해 질의 재생성 시행)
- 질문 내에 포함 된 주요 키워드, 문장 패턴들을 인식하여 질의를 생성한다. 생성된 질의는 문서를 검색하는 과정에서 이용
3. 문서처리단계
1) 불리언 모델
- 단어가 수집된 각 문서에서 출현 했는가의 여부를 Boolean으로 표시하는 것
- 특정 단어가 들어가 있는 문서를찾을 때 AND와 OR 구문으로 계산한다.
단점- 어떤 문서가 더욱 중요한지, 질의어와 더욱 일치하는지 순위를 매길 수 없음
- 결과 값이 너무 많아서 결과를 줄이기 위해 질의를 다듬어야 함.
- 전문적인 능력을 필요로 함
2) 벡터 공간 모델
-
각 문서에 나타나는 단어들에 대해 가중치를 측정
-
질의어와 문서의 유사도를 측정
-
각 문서의 순위를 나타낼 수 있다.
유사도 측정 방법
-
자카드 유사도
- 두 집합의 교집합과 합집합을 이용해 유사도를 구함
- 자카드 유사도는 0과 1사이
- 문장을 비교할 문서를 각각 , 라고 했을 때의 자카드 유사도
-
코사인 유사도
-
TF - IDF
TF: 단어가 문서에 나타난 횟수 => 단어가 문서에서 얼마나 중요한지 확인 가능
DF: 해당 단어가 문서에 나타난 수 => 적게 나타나야 해당 단어는 중요하다.
IDF: DF의 역수 값
TF-IDF: TF와 IDF값을 곱해 중요한 단어를 찾아주는 방법
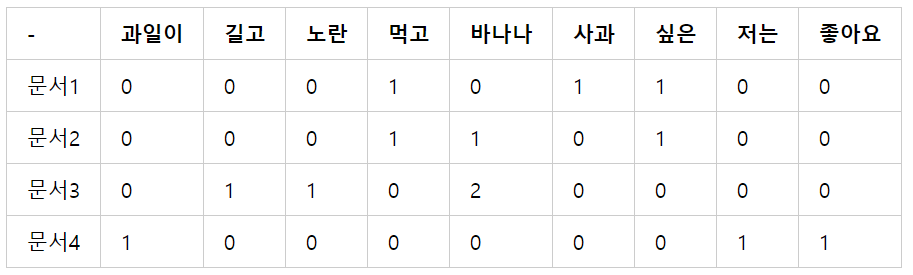
위 표에 따르면 바나나의 DF는 2, 사과의 DF는 1
-
4. 정답처리단계
1) 질문처리 단계에서 얻은 정답유형정보를 이용
2) 정답유형에 따른 개체명에 따라 얻은 관련문서나 문장을 탐색
3) 정답 유형과 같은 개체를 갖는 정답후보를 추출
4) 정답후보 순위화
나중에 다시 정리하면 좋은 내용들
- TF-IDF
- 코사인 유사도
