해당 글은
자연어 처리 바이블(임희석 저) 에서 참고하여 작성되었음을 알려 드립니다.해당 게시물은
규칙 기반 번역과통계 기반 번역을 중점적으로 다루는 게시물입니다.목차
1. 규칙 기반 기계번역
2. 통계 기반 기계번역
1. 규칙 기반 기계번역
정의 언어학적, 문법적인 규칙을 이용해 문장을 번역하는 것
- 단순히 단어를 번역하는 것이 아니라 통사적 혹은 의미론적 구조를 같이 분석하고자 함.
- 문장을 분석과 의미통합을 거쳐 여러 언어의 가장 근간이 되는 '인공통합언어'로 변환 후 원하는 언어로 번역하는 방법론을 제시
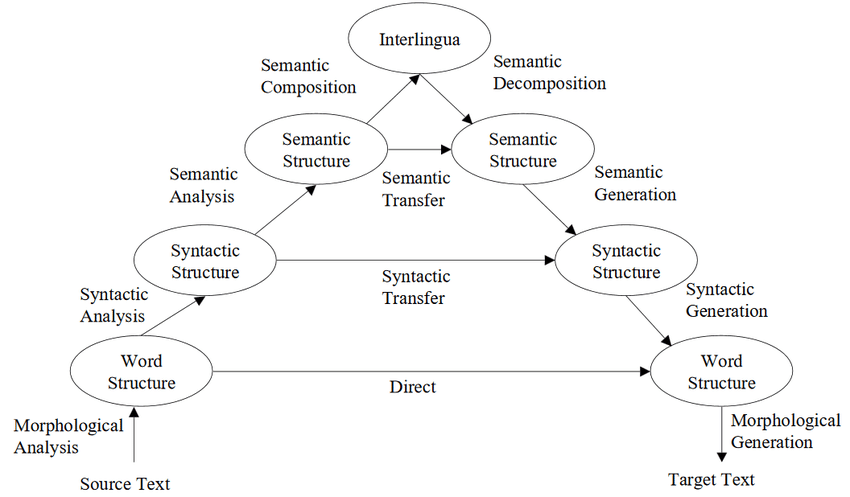
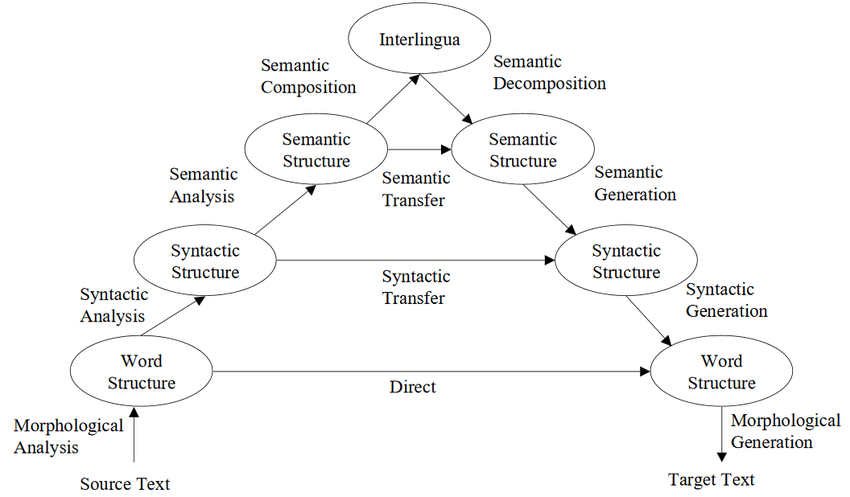
Vauquois Triangle 규칙 기반으로 문장을 번역하는 과정을 설명하는 도표
장점
- 번역된 문장의 문법이 꽤 정확하다.
단점
- 시스템을 만들기 위해 필요로하는 언어학적 지식의 양이 많다.
- 시간이 오래 걸릴 뿐만 아니라 복잡성에 의해 오류가 발생한다.
- 문장에서 규칙을 적용할 대상을 식별해야하는데, 이 단계의 정확도가 매우 낮았다.
2. 통계 기반 기계번역
정의 대량의 코퍼스를 바탕으로 두 언어 사이의 상관관계를 통계적으로 제시하는 기계번역의 한 방법
규칙 기반 기계번역과의 차이점
1. 규칙 기반 기계번역와 달리 학습할 코퍼스를 필요로 한다.
2. 모델의 존재 => 컴퓨터가 학습할 수 있도록 하는 알고리즘의 구성 형태
- 규칙기반과 다르게 여러가지 확률을 계산해, 그 정보를 내부적으로 보관하고 있다.
코퍼스의 특징
- 같은 내용을 의미하는 서로 다른 언어의 문장들이 쌍을 이뤄야 한다. 이를 병렬 코퍼스라고 한다.
- 문장 단위의 코퍼스만 있는 것은 아닌게 비슷한 주제를 다루고 있는 문장 (뉴스기사에서 가져온)들을 코퍼스로 사용하려는 시도가 있었다. 이를 비교 코퍼스라고 한다.
- 병렬 코퍼스에 비해 구축하는 것이 간단하지만, 정확도가 높지는 않았다.
1) 통계 기반 기계 번역의 수학적 접근
통계 기반 기계 번역은 수학적 원리들이 분명히 존재하고, 이를 설명하기 위한 사례를 영어 -> 프랑스어 번역으로 하려고 한다.
입력언어(Source)는 영어(E)이고, 출력 언어(target)은 불어(F)다.
-
조건부확률- 조건부확률을 통해 코퍼스 안에서 입력된 영어와 출력해야 하는 불어가 쌍을 이루고 있는 확률을 구하는 식
- 영어가 입력되었을 때 연결된 불어가 있는 경우를 찾는 방법이다.
- 코퍼스가 병렬 코퍼스라면 영어 문장이든 프랑스어 문장이든 총 개수는 동일하다.
- 하지만 해당 방법은 성공적인 기계 번역으로 이어지지 않는데, 우리가 세상의 모든 문장을 다 아는 것이 아니기 때문이다. => 입력된 영어문장이 코퍼스에 존재하지 않는다면 식을 이용해 확률을 구할 수 없다.
- 위의 문제를 해결하기 위해 문장단위로 보지 않고, 단어 단위로 보는 방법이 제시되었다. 그것을 보여주는게 아래의 식
- 아래 방법을 통해 확률값이 0이 나오는 것을 피할 수 있다.
- 조건부확률을 통해 코퍼스 안에서 입력된 영어와 출력해야 하는 불어가 쌍을 이루고 있는 확률을 구하는 식
-
번역의 질을 지표화하기-
위에 언급되어 있는 식을 이용하더라도 몇가지 문제가 있을 수 있다.
- 동음이의어나, 문장 위치에 따라 의미가 달라 질 수 있어 단어는 항상 한가지 의미로 번역되지 않는다는 점.
- 언어별로 단어의 변환(과거형, 의문형) 방법이 다르기 때문에 자연스럽지 않을 수 있다.
- 언어에 따라 어순이 다르기 때문에, 단어의 순서대로 번역해서는 자연스럽지 않은 번역이 나온다.
-
조건부확률에 베이즈 정리를 이용하면 위의 문제들을 해결하기는데 도움이 된다.
- 번역이 잘 되어 있는지 상태를 파악하는 기준이 될 수 있기 때문
- P(E)는 고정
-

프로그래밍 기록 + 공부 기록
공감하며 읽었습니다. 좋은 글 감사드립니다.