1. Retrieval
Accessing/indexing data in vector store
-
basic semantic similarity
-
Maximum Marginal Relevance(MMR)
MMR은 검색 결과의 다양성을 강화하는 방법 , 의미적 유사도를 기반으로 한 임베딩 공간에서는 가장 유사한 문서를 얻는 반면 이 과정에서 다양한 정보를 놓칠 수 있다.
아이디어- vector store를 쿼리하려 "fetch_k" => 가장 유사한 응답을 선택
- "fetch_k" 문서 세트에 대해 작업하여 질의와 관련성을 확보하고, 결과 간의 다양성을 확보
- "fetch_k" 응답들 중에서 k 개의 다양한 응답을 선택.
-
including Metadata
메타데이터를 이용해 특정 범위의 문서에서만 원하는 검색 결과를 도출하는 방법question = "what did they say about regression in the third lecture?" docs = vectordb.similarity_search( question, k=3, filter={"source":"docs/cs229_lectures/MachineLearning-Lecture03.pdf"} ) for d in docs: print(d.metadata)
LLM-aided retrieval, Self Query
Self Query를 이용하는 방법으로 쿼리 그 자체로 부터 메타데이터를 추론하고 싶을 때 사용된다.
SelfQueryRetriever를 이용하면되고, LLM을 이용하는 방법이다. 해당 방법으로 추출하는 것은 다음과 같다.
- 벡터 검색에 사용할 질의 문자열
- 전달할 메타 데이터 필터
이 방식은 검색 과정을 간소화하고, 자동화하여 사용자가 직접 필터를 설정할 필요없이 관련성 높은 결과를 얻을 수 있도록 돕는다.
from langchain.llms import OpenAI
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain.chains.query_constructor.base import AttributeInfo
metadata_field_info = [
AttributeInfo(
name="source",
description="The lecture the chunk is from, should be one of `docs/cs229_lectures/MachineLearning-Lecture01.pdf`, `docs/cs229_lectures/MachineLearning-Lecture02.pdf`, or `docs/cs229_lectures/MachineLearning-Lecture03.pdf`",
type="string",
),
AttributeInfo(
name="page",
description="The page from the lecture",
type="integer",
),
]
document_content_description = "Lecture notes"
llm = OpenAI(temperature=0)
retriever = SelfQueryRetriever.from_llm(
llm,
vectordb,
document_content_description,
metadata_field_info,
verbose=True
)
question = "what did they say about regression in the third lecture?"
docs = retriever.get_relevant_documents(question)Contextual Compression
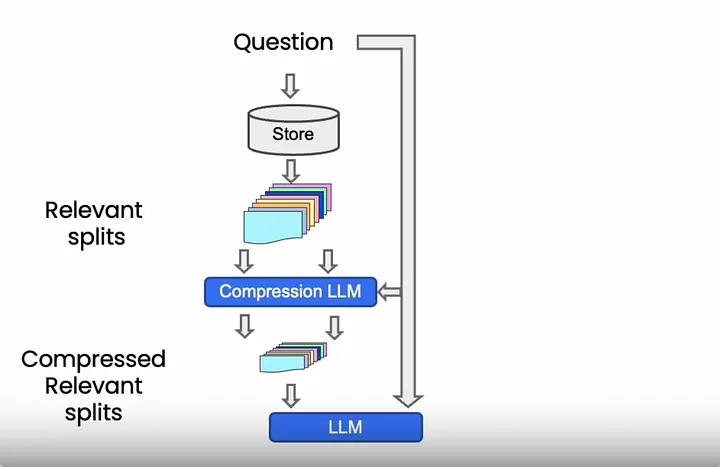
문서 압축이라고 부를 수 있다. 전체 문서를 애플리케이션을 통해 LLM으로 전달하는 것은 많은 비용을 수반한다. 또한 응답의 질 역시 떨어질 수 있다. 그래서 검색된 문단에서 가장 관련성 높은 부분만 추출하는 방법이다. 해당 접근 방식의 이점은 다음과 같다.
- 효율성 향상
- 응답 품질 개선
- 비용 절감
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
def pretty_print_docs(docs):
print(f"\n{'-' * 100}\n".join([f"Document {i+1}:\n\n" + d.page_content for i, d in enumerate(docs)]))
llm = OpenAI(temperature=0)
compressor = LLMChainExtractor.from_llm(llm)
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=vectordb.as_retriever()
)
question = "어떤 과목이 통계와 관련이 있어?"
compressed_docs = compression_retriever.get_relevant_documents(question)
pretty_print_docs(compressed_docs)
Document 1:
BIZ500 경영통계분석 (Management Statistical Analysis)
나의 경우에는 다음과 같은 결과가 나오고, 위의 예시 코드의 파이프라인은 일반적으로 다음과 같다.
2. Question Answering
RetrievalQA Chain
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
llm = ChatOpenAI(temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectordb.as_retriever()
)
# Pass question to the qa_chain
question = "어떤 과목이 통계랑 관련이 있나요?"
result = qa_chain({"query": question})
result["result"]RetrievalQA limitations
해당 Chain의 가장 큰 한계는 대화 이력을 보존하는 것에 실패하는 것이다.
이를 해결하기 위해서는 메모리 개념을 도입해야 한다. 챗봇을 만드는 경우 이전 질문이나 답변을 기억하는 능력이 필요하다.
또한 의미론적 검색은 특정한 케이스에서 실패할 수 있다. 이를 극복하기 위해 다양한 검색 알고리즘을 논의했으며, 질문에 대한 답변을 생성하기 위해 검색된 문서와 사용자 질문을 LLM에 전달하는 질문 답변 시스템을 탐구했다.
출처 https://medium.com/@onkarmishra/using-langchain-for-question-answering-on-own-data-3af0a82789ed
