paging
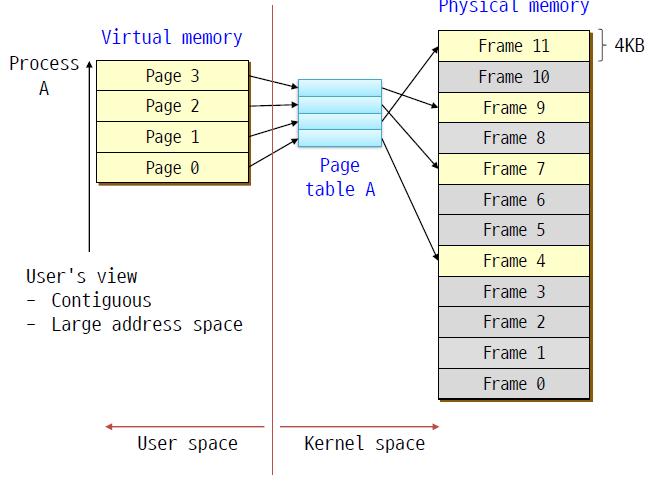
- 4kb(일반적으로) 단위 frame으로 쪼개서 피지컬 메모리를 쪼개서 관리한다. 프로세스도 마찬가지로 쪼개서(page라고 부른다.) 관리가 가능하다.
- 유저의 입장에서 연속적이고 매우 큰 주소 공간(VAS)처럼 보인다. 하지만 실제로 피지컬 주소 공간은 흩어져서 배치되도록 할 수 있다. 보통 32bit 컴퓨터는 4gb의 vm를 사용할 수 있다.
- virtual memory page의 개수만큼 page table을 OS가 준비한다. page table은 배열처럼 되어 있으며 각 인덱스는 피지컬 메모리의 frame을 가리킨다. 이때, 피지컬 메모리의 frame들은 흩어져서 배치된다. va에서 pa로의 맵핑 과정이 필요하며 이 과정은 프로그램에서 보이지 않는다. 즉, 사용자는 이 사실을 모르는 것이다.
- 피지컬 메모리는 frame이라고 불리는 고정된 사이즈의 블록으로 나뉜다. virtual(logical) 메모리는 page라고 불리는 같은 사이즈의 블록으로 나뉜다.
- page의 사이즈는 2의 배수 단위(512b~8kb)이고 보통 OS에서 4kb를 사용한다.
- n page가 필요하다면 프로그램을 돌리는데 n개의 free frame이 필요하다.
- OS는 연결리스트로 free frame을 관리한다.
- virtual을 physical 주소로 번역하는데 page table을 셋업해야 한다.
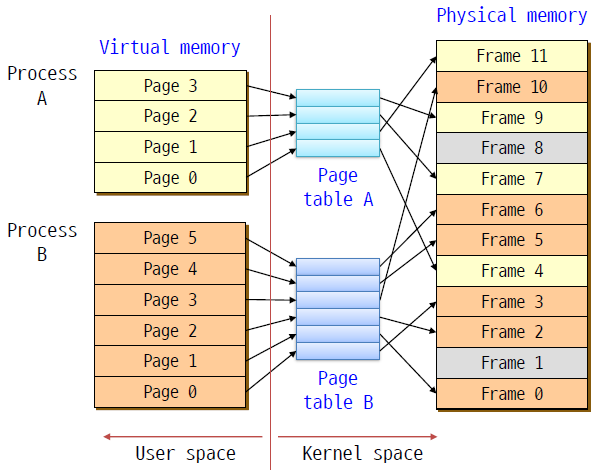
- process마다 따로 vm을 가진다. page table 또한 각각 가진다. 또한, 실제로 process들은 physical memory의 다른 frame number를 사용한다.
- program이 자신의 vas를 벗어난 것들을 절대로 reference할 수 없기 때문에 protection을 제공받는다. 가상 주소는 다른 프로세스들과 다른 physical 주소들에 맵핑된다.
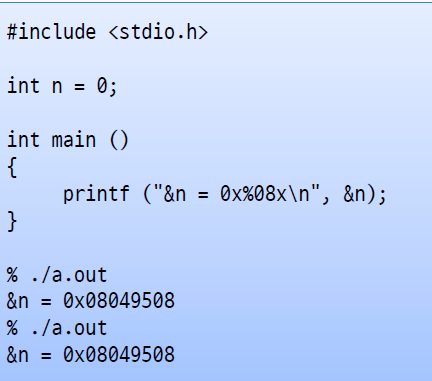
이 프로그램에서 access하는 메모리는 virtual address이다. 똑같은 프로그램을 다시 실행해도 같은 va가 출력되고 동시에 이 두 개를 실행했을 때도 마찬가지로 동일한 va를 출력한다. 하지만 서로 다른 프로세스이므로 실제 physical memory는 동일하지 않다.
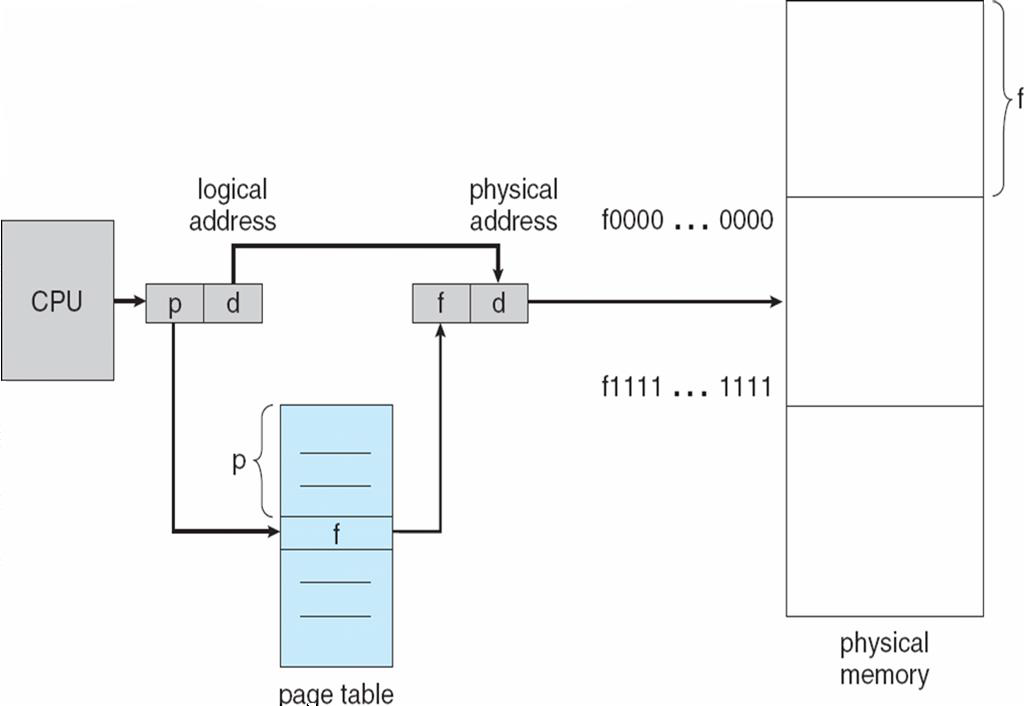
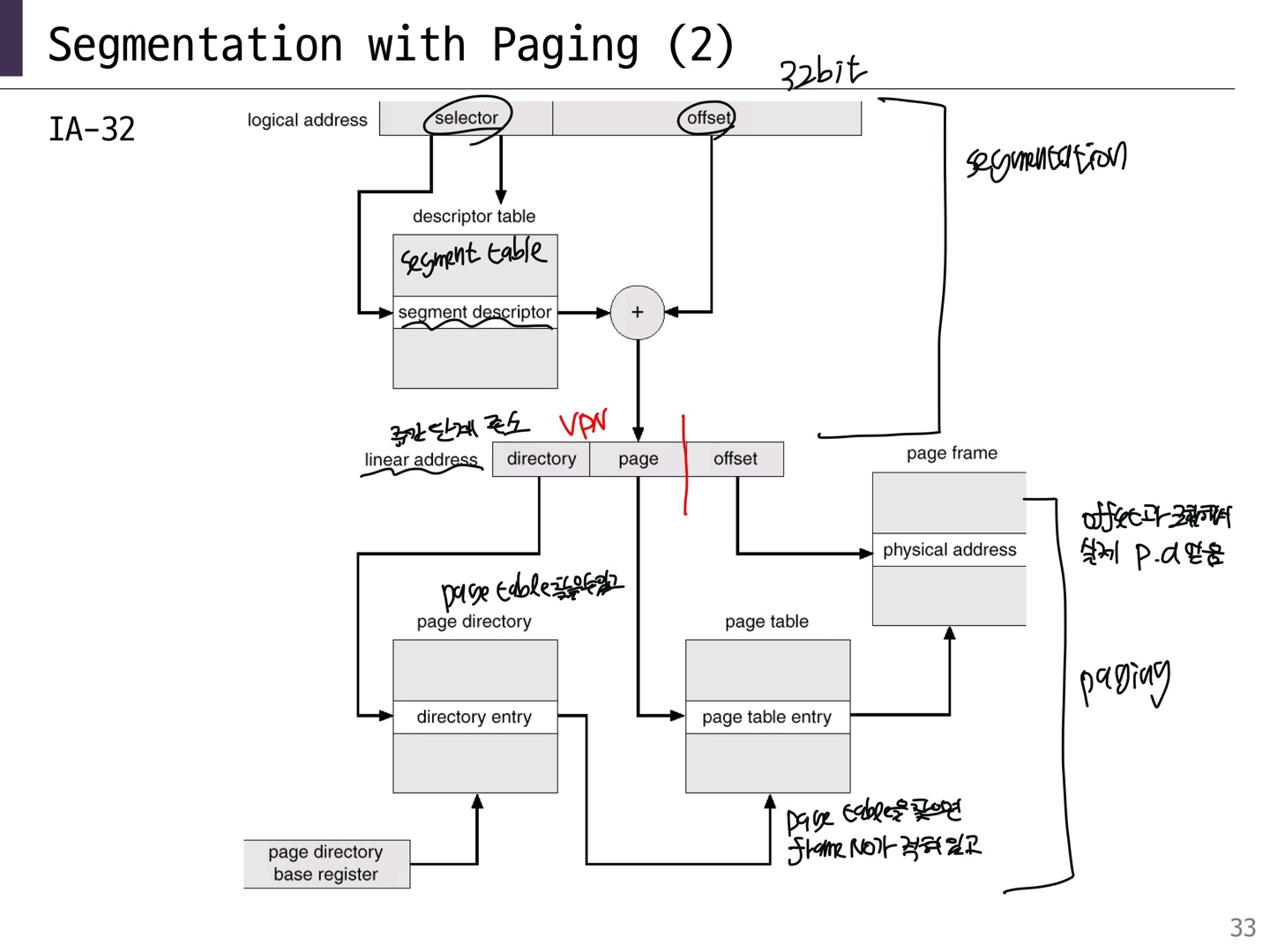
- 주소 번역: 가상 주소는 두 부분을 가진다.
- VPN(Virtual Page Number)::offset
- VPN은 PFN을 결정하는 page table의 index이고 page table은 PFN(Page Frame Number)를 결정한다.
- physical address는 PFN::offset이다.
page table
- 다시 한 번 더 말하자면 page table은 OS가 관리한다.
- VPN은 PFN으로 맵핑된다.
- vas에서 각 page마다 PTE(Page Table Entry, row 하나)를 가지고 있다. 즉, VPN당 하나의 PTE를 갖는다.
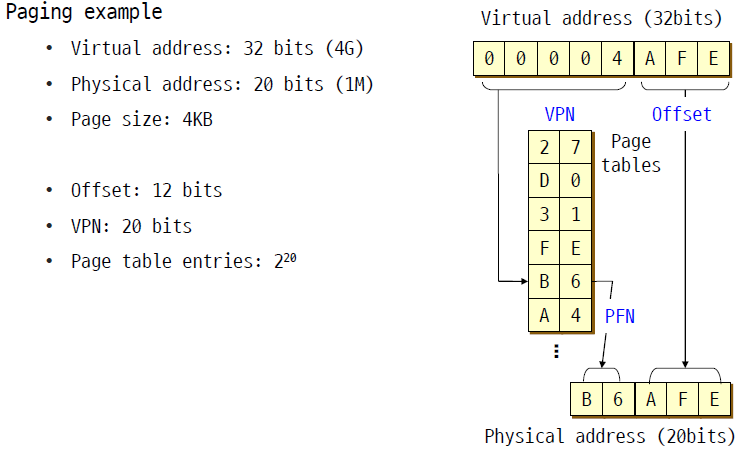
- 2^32= 4GB, 2^20=1M이고 va의 길이는 32bit이다. pa의 길이가 20bits이므로 PTE는 2^20개이다. page size는 4KB이다.
- offset이 12bits인 이유는 page size가 4KB이기 때문이다. 4KB를 모두 access하기 위해서는 2^12=4KB이므로 12bits가 필요하다. 또한, 여기서 VPN은 20bits이고 PFN은 8bits이다. frame의 개수는 2^8개이다.
vas는 유저가 볼 수 있고 pas는 커널이 볼 수 있다.
va가 pa보다 용량이 많을 수 있는 이유
va에서 안쓰는 메모리를 disk storage에 넣을 수 있다.

PFN이 20bits이면 2^20개만큼 frame의 개수를 가지고 있다.
1. V(Valid bit): 실제로 va(PTE)가 사용되고 있는지
2. R(Reference bit): 이 page가 최근에 access(참조)되었는지 즉, page에 대한 r/w가 일어났는지
3. M(Modify bit): page가 더러운지 아닌지 즉, disk에서 page로 내용을 가져왔는데 w가 일어나서 내용이 바뀌었을 때
4. Prot(Protection bits): page에서 r/w/e가 가능한지 표기
PFN은 물리적인 page를 결정한다.
장점:
1. physical memory를 할당하기 쉽다. 실제로 physical memory는 frame의 free list(연결리스트)로부터 할당된다.
2. No external fragmentation but internal은 생길 수 있다.
3. page out을 하기 쉽다. : valid bit만 바꾸면 page out할 수 있다.
4. 불법 접근으로부터 페이지를 보호하기 쉽다.
5. 페이지를 공유하기 쉽다.
단점:
1. internal fragmentation이 있다. 4KB로 잘라서 관리하므로 남는 공간이 발생할 수 있다. 하지만 그리 치명적인 단점이 아니다.
2. 메모리 참조 오버헤드가 발생한다.(성능 오버헤드): page table, memory에 access하는데 2번의 참조가 필요하다. TLB(hw support)의 지원을 받아 해결한다.
3. page table을 잡는데 요구되는 메모리가 클 수 있다.(공간 오버헤드)
-> vas에서 페이지 당 하나의 PTE가 필요하다.
-> 4KB 페이지와 32bit vas는 20비트의 VPN을 갖게 되고 이는 2^20개의 PTE를 갖는다. PTE 하나당 4바이트가 필요하면 32MB 페이지 테이블 용량이 필요하다. 여기서 여러 프로세스가 존재한다면 32*N만큼의 용량이 페이지 테이블에 소요된다.
-> 해결책으로 page the page tables, multi-level page tables, inverted page tables가 있다.
demand paging
- 오직 페이지가 필요할 때 디스크에서 메모리로 페이지를 가져오는 것
- I/O의 횟수를 적게, 메모리를 적게 쓰며 응답이 빠르며 더 많은 프로세스를 동시에 돌릴 수 있다.
- 따라서 OS를 메인 메모리를 캐쉬처럼 사용한다. 시스템에서 프로세스에 의해 할당되는 모든 데이터의 캐쉬이다. 물리적 메모리가 가득 찼을 때, 디스크에 있는 메모리와 교체한다.(eviction(디스크로 내려보낸다) and load(디스크에서 가져온다)
- evicted pages go to disk
-> 페이지가 dirty일 때 디스크에 write한다.(디스크와 메인메모리의 데이터가 다를 경우)
-> 디스크에서 특정한 swap file에 evict한다.
-> 메모리와 디스크 사이에서 페이지들의 움직임은 OS의해 실행된다.
-> 이 과정은 응용 프로그램이 모른다.
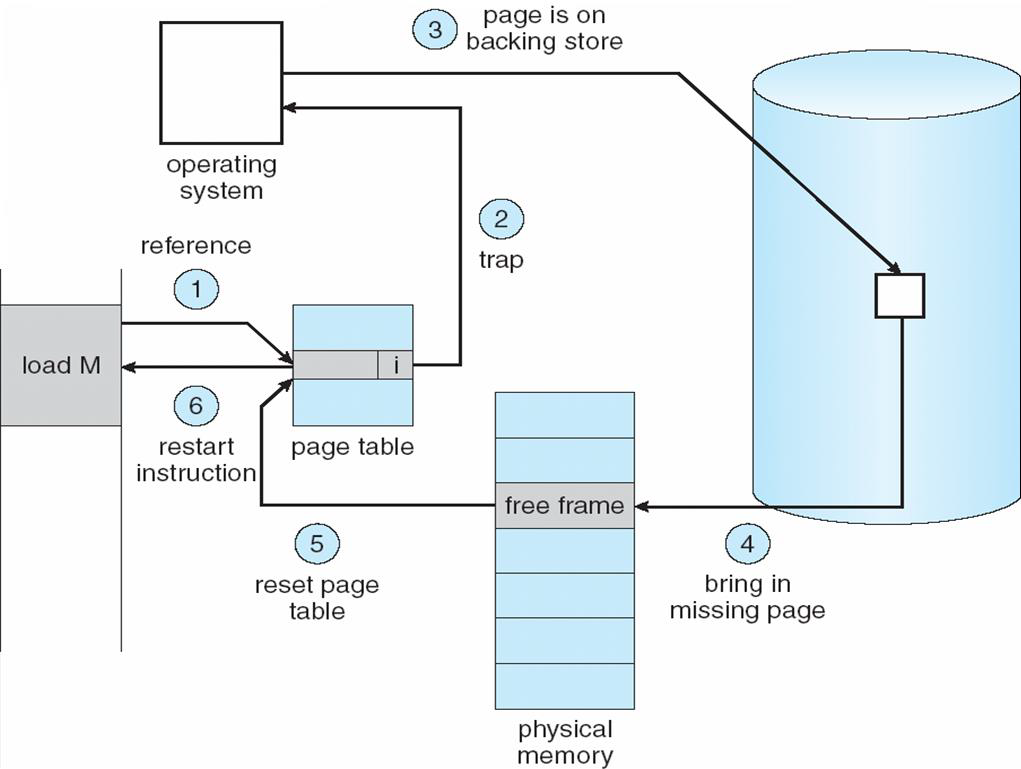
page faults
- evicted page(디스크에 있는)에서 va를 참조할 때
-> page가 evict되어 있을 때, OS는 PTE를 invalid한다.
-> swap file에서 페이지의 위치(PTE)를 저장한다.
-> page를 접근하면 exception(page fault)이 발생한다.
- page fault가 나면 OS는 page fault handler(OS 내부 함수)를 돌린다.
-> invalid PTE를 통해 swap file에서 원하는 페이지를 찾는다.
-> 핸들러는 그 페이지를 physical frame으로 읽어들인다.
-> PTE를 valid로 업데이트 한다.
-> 핸들러는 faulted process를 다시 시작한다.
- 페이지를 valid로 바꾸면 다른 페이지를 invalid로 바꿔야한다.
-> 반드시 어떤 것을 evict해야 한다.
-> 어느 것을 고를지 선택하는 것이 page replacement algorithm이다.
-> OS는 불가피하게 eviction을 일으키지 않기 위해 보통 free pages를 어느정도 유지하고 있다.
- locality
-> temporal locality: 최근에 참조된 위치가 곧 참조될 가능성이 있다.
-> spatial locality: 최근에 참조된 위치의 주위 위치가 곧 참조될 가능성이 있다.
- locality로 페이징이 일어날 가능성이 많지 않다.
-> 한 번 페이지하면 계속 페이지할 가능성이 높다.
-> locality는 많은 것에 의존한다.
-> 1) locality가 낮을 수도 있다.
-> 2) 어떤 것을 evict, load할지 결정해야 한다.
-> 3) physical memory가 너무 부족할 수도 있다.
-> 4) 어떤 패턴으로 access하는지에 따라 달라진다.
왜 demand paging인가?
처음에 프로세스가 시작할 때, 새로운 page table을 만들고 PTE valid bit는 0이다. 즉, 모든 페이지가 비어 있고 물리적 메모리에 맵핑된 페이지가 없다. 페이지를 요구할 때마다 page fault가 발생하고 디스크에 evict하고 load하고 반복한다.
이를 cold miss, cold page fault라고 한다.
필요한 코드와 데이터 페이지가 모두 있을 때, fault가 멈춘다.
또한, 프로세스에 의해 필요한 코드와 데이터만 load되어야 한다.
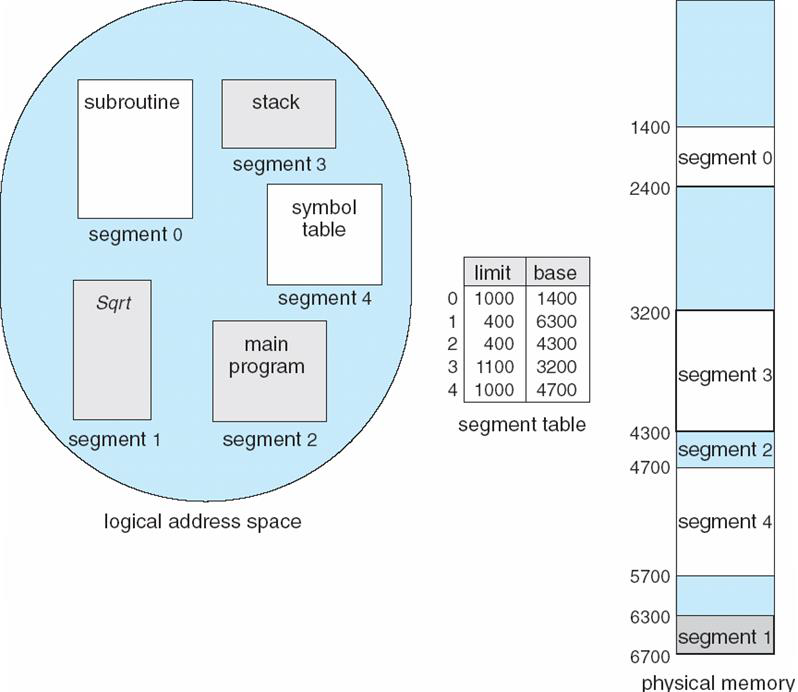
segmentation
- logical한 단위(코드, 스택, 힙 등)로 메모리를 잘라서 관리한다. paging은 무조건 4KB로 잘라서(frame또한) 관리한다.
- 유저 입장에서 메모리가 variable-sized segment의 집합처럼 보이며 그들의 순서를 정할 필요가 없다.
- virtual address: segment #::offset
- 각기 다른 segment는 서로 영향을 끼치지 않으면서 독립적으로 커졌다가 작아진다.
- variable-size partitions: 1 segment/process
- segmentation: many segment/process
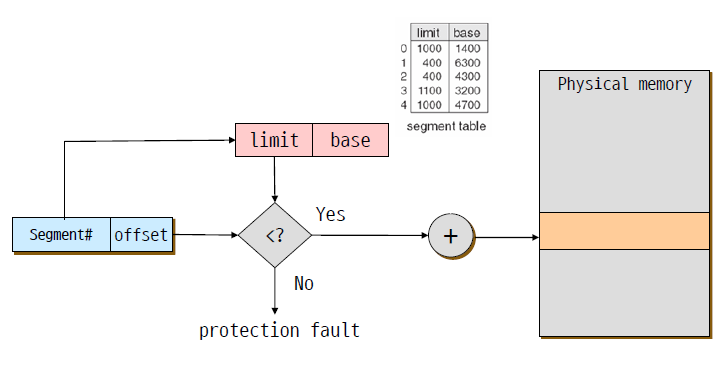
segment 하나 당 base/limit의 여러 짝들을 갖는다.
segment들은 segment #이라 이름 붙여진 번호로 관리되고 테이블 인덱스로 사용된다.
장점:
1. 늘어나고 줄어드는 데이터 구조의 관리가 쉬워진다.
2. segment를 보호하기 쉽다.
-> segment table에서 각 엔트리에 valid bit, protection bits이 연관된다. 페이징에서는 이런 문제가 발생하지만 segmentation은 생기지 않는다. code는 code 영역대로, stack은 stack영역대로
3. 공유도 쉬워진다.
-> segment level에서(segment 단위로) 공유가 일어난다.
단점:
1. segment를 넘어서 addressing을 해야 하는 경우가 생길 수 있다. pointer(indirect기법)로 다른 segment를 액세스하는 것은 어렵고 복잡하다. 또한, 같은 segment #을 갖고 있어야 가능하다.
2. segment table 크기도 크다.
-> 메인 메모리보다는 성능 향상을 위해서 hw cahe를 사용한다.
3. external fragmentation의 문제가 생긴다. 필요한 메모리가 조각으로 흩어져 있다.

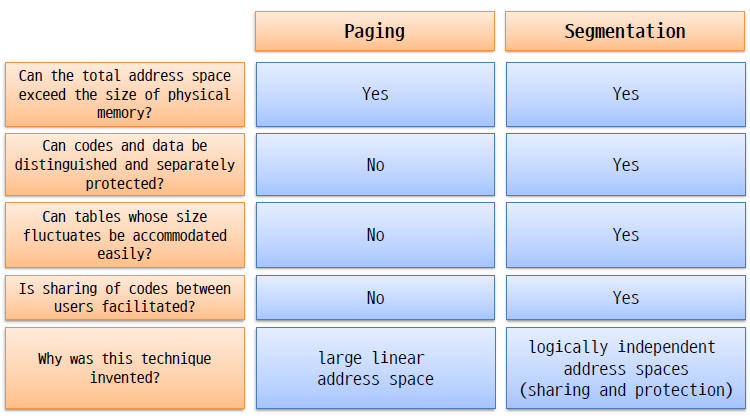
hybrid(현재 대부분 운영체제 방식)
paged segments
-> segmentation with paging(segment를 page로 나눈다.)
-> segments는 page size의 multiple이다.
-> page는 여러 사이즈로 관리될 수 있다.
1. segments를 논리적으로 관련된 유닛(코드, 스택, 힙)으로 관리한다.(segment는 사이즈가 다양하지만 보통 크기가 크다.)
2. page가 segment를 나누는데 사용된다.(똑같은 페이지 사이즈로 나뉜다.)
-> pm에서 segment가 쉽게 관리되도록 한다.
-> segment는 pageable해진다.(segment 안에 있는 page 단위로 disk에 올렸다가 내렸다가 이것을 가능하도록 해준다)(no externel fragmentation)