physical memory가 가득 찰 때
page replacement algorithms
page replacement
page fault가 일어났을 때, OS가 특정한 페이지를 디스크로부터 물리적 메모리로 불러들이고(load) 물리적 메모리에서 누구를 내보내야(evict)할지 고민.
evicting the best page
내보내는데 최적인 페이지를 고른다. page fault rate를 줄이는 것이 목표이고 이 목표에 해당하는 페이지(앞으로 절대 쓰이지 않는 페이지, never에 가장 가까운)를 쫓아내는 것이 최적이다.
Belady's proof: 최적의 page replacement
오랜 시간동안 쓰이지 않는 페이지를 교체하는 것
가장 낮은 page fault rate를 갖는다.
문제점
1. 미래를 알 수 없다.
2. 왜 Belady가 유용한지 기준점으로 사용해라.
-> 다른 알고리즘과 비교하여 최적인지 아닌지 비교해라.
FIFO(First In First Out)
- 개발하는데 명백하고 간단하다.
-> 그들이 page in되는 순서대로 페이지의 리스트를 유지한다.
-> 교체할 때, 가장 맨 처음에 들어온 페이지가 가장 먼저 나가도록 한다.
간단하지만 Belady's Anomaly라는 문제점이 있다.
-> 알고리즘이 많은 메모리가 주어졌을 때, fault rate가 줄어들지 않고 늘어난다.
LRU(Least Recently Used)
- LRU는 더 나은 교체 결정을 하기 위해 reference 정보를 사용한다.
-> 아이디어: 과거 패턴을 보면 미래를 추측할 수 있다.
-> 교체할 때, 과거에 가장 오랜 시간동안 사용되지 않은 페이지를 쫓아낸다(evict)
-> LRU는 과거를 보고 미래를 예측하며 Belady는 미래를 보길 원한다.
-> 문제점은 페이지가 언제 사용되었는지 보기 위해 모두 트래킹해야 하며 FIFO보다 복잡하고 FIFO처럼 연결리스트로 구현하려면 훨씬 더 많은 search가 필요함.
구현 방법
-> Counter implementation: timestamp를 놓는다.
-> Stack implementation: stack을 유지한다.
하지만 구현하는데 오버헤드가 너무 커서 근사치를 사용한다.
approximating LRU
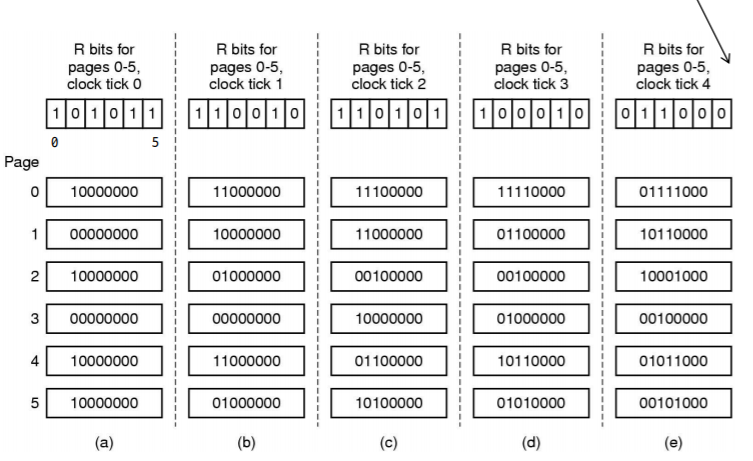
- 많은 LRU approximation들은 PTE reference(R) bit를 사용한다.
-> 페이지가 한 번이라도 액세스되면 R비트가 1로 세팅- counter-based approach
-> R이 0이면 counter를 증가(사용되지 않을 때)
-> R이 1이면 counter를 0으로 만든다.(사용되었을 때)
-> 수시로 0으로 만든다.
-> counter의 숫자가 높다 : 가장 오랬동안 사용하지 않았다. 만약 R비트를 제공하지 않는다면 이 알고리즘을 사용할 수 없다.
second chance(LRU의 변형)
- 최근에 참조되는 페이지에 second chance를 부여함으로써 FIFO구현
- 각 페이지/프레임을 큰 circle(clock)로 생각한다.
- clock이 사용되면 R비트가 0이면 사용되지 않았다라는 뜻이고 victim으로 만든다. R비트가 1이면 0으로 바꾸고 다음 페이지로 넘어간다.(한 번 더 기회를 준다.)
- Arm(시계 방향)은 굉장히 빨리 움직인다.
-> counter를 사용하지 않기 때문에 메모리가 절약된다.
-> 메모리가 크면 정보의 정확도가 떨어진다.
Not Recently Used(second chance의 진보형
- R, M bits 사용
-> 주기적으로 R 비트는 0으로 초기화시키고(최근데 사용되었는지 아닌지 알기 위함)
-> R, M비트로 class 숫자를 정한다.- 알고리즘
-> 클래스 숫자가 가장 낮은 것을 골라서 내보낸다.
-> 수정된 페이지를 메모리에 남기는 것이 낫다는 가정이 반영됨. 과거 매킨토시에서 쓰임
장점
-> 이해하기 쉽고 구현하기 쉽다.
-> 아주 최적이지는 않지만 충분한 성능을 제공한다.
LFU(Least Frequently Used)
- counting-based page replacement
- 일정 시간동안 가장 적은 횟수(count)로 access가 안된 것을 replace한다.
- count는 각 페이지마다 존재하고 액세스할 때마다 카운터에 R 비트를 추가한다. Aging기법으로 사용한다.(count가 R비트를 보고 오른쪽으로 shift하는 방식이다.)
MFU(Most Frequently Used)
- 가장 작은 카운트를 가진 페이지는 방금 올라온 페이지일 수도 있다는 가정
- heavy하게 사용되었다면 카운트가 높다면 더 이상 사용되지 않을 것이라는 가정
frame의 할당의 문제점
- 멀티프로세스 시스템 환경에서, 우리는 서로 경쟁하는 프로세스들끼리 어떻게 물리적인 메모리를 할당해줄 것인지에 대한 방법이 필요하다.
-> 어떤 프로세스의 피해자 페이지를 빼야하지?
-> 각 프로세스간에 얼마나 메모리를 줘야하지?
- Fixed space algorithms
-> 각 프로세스에게 이 프로세스가 사용할 수 있는 페이지를 제한한다.
-> 제한에 다다르면 그 프로세스 안에서 교체를 한다.
-> Local replacement: 몇 개의 프로세스는 잘될 수 있지만 다른 프로세스는 고통받을 수 있다.
- Variable space algorithms
-> 각 프로세스들이 사용하는 page set이 동적으로 늘어났다 줄어들었다를 반복
-> Global replacement: 어떤 프로세스는 다른 프로세스에게 영향을 줄 수 있다.(Linux) 대부분의 OS가 사용
Thrashing(heavy page fault)
- 프로세스를 많이 사용할수록 CPU사용량이 늘어난다. 그러다가 어느 순간 CPU사용량이 급격히 떨어질 때가 있다. 이러한 상황을 Thrashing이라고 한다.
- 대부분의 CPU 사용시간(프로그램이 돌아가는 시간)이 OS가 eviction, loading(page fault, page in)replacement하는데 대부분의 시간을 사용하기 때문이다. 간단히 말하면, 메모리 부족을 해결하는데 많은 시간을 소모하기 때문에 CPU가 제 할 일을 제대로 못하게 되는 상황이다.
-> 유용한 작업(행렬 계산 등)을 하지 못하고 I/O하는데 대부분의 시간을 사용한다.
-> 시스템이 overcommit된 상황
-> page fault를 줄이기 위해 어떤 것을 메모리에서 빼고 어떤 것을 메모리에 넣을 것인지 잘 안되는 상황
-> 메모리는 한정적인데 프로세스들이 메모리를 달라고 계속 요청해서 disk I/O와 이 page fault를 해결하기 위해 I/O작업만 계속 하다가 메모리의 내용을 가져다가 CPU가 계산을 해야하는데 그러지 못하는 상황이다.
해결방법
-> 프로세스의 모든 페이지를 모두 write out하여 빈 공간을 확보해준다.
-> 더 많은 메모리를 사면 된다. 아니면 process를 죽여야 한다.
Working Set Model
Working Set : 어떤 프로세스가 현재 필요로 하는 페이지들의 집합이다.
-> 이는 메모리 사용의 동적인 locality(캐쉬, 페이지 폴트에 영향을 미친다.)를 모델링하는데 굉장히 유용하다.
정의:
-> WS(t,w) = time interval(t, t-w)시간 동안 P가 참조된 페이지 P들의 집합
-> t: time, w: working set window size(페이지 참조에서 측정된다.)
-> 어떤 페이지가 last W 레퍼런스 동안에 참조되었으면 working set안에 있다고 말한다.
Working Set Size(WSS)
- working set안에 있는 페이지의 숫자 = interval(t, t-w)사이에 몇 개의 페이지가 참조되었는지
- WSS는 프로그램이 어떻게 동작하는지 locality가 얼마나 좋은지에 대해 달라진다.
- 만약 locality가 굉장히 안좋으면 more page가 레퍼런스된다.
- 그 시간 동안 WSS가 커진다. 만약 locality가 좋으면 작아진다.
- 직관적으로, WSS는 pm에 있는 것이 좋다. 그렇지 않으면 page fault가 일어나고 thrashing이 발생할 수 있다.
- WSS에 따라 몇 개의 프로세스(프로그램)을 동작할 수 있는지의 정도를 계산할 수 있다.
-> 각 프로세스의 WSS 파라미터를 associate하여 WSS를 판단하여 frame을 주거나 뺏거나 할 수 있다. 그래서 WSS가 여전히 메모리에 맞는다면 프로세스가 시작할 수 있도록 허용한다.
Working Set page replacement
- lask K의 레퍼런스 동안에 터치된 page들의 집합을 유지하는 방식이다. 즉, working set을 근사치한다.
-> 실제로 current virtual time을 만들어 이 시간으로부터 얼마나 지났는지 계산해보고 메모리가 access되었는지 판단- working set안에 들어있지 않은 페이지를 찾고 evict한다.
-> PTE에 'Time of last use'라는 필드를 만들고
-> 주기적으로 clock이 돌면서 R bit는 0으로 clear
-> 매 page fault가 발생했을 때 마다 page table은 evict하기에 적절한 타겟을 찾기 위해 스캐닝하는 과정을 거친다.
-> 만약 R = 1이면 timestamp를 current virtual time으로 세팅한다.(Tlast = Tcurrent)
-> R bit가 만약 0이면 그 (Tcurrent - Tlast)(마지막으로 액세스한 시간과 현재 시간을 비교하여) > t(time interval)이면 그 page를 evict한다.
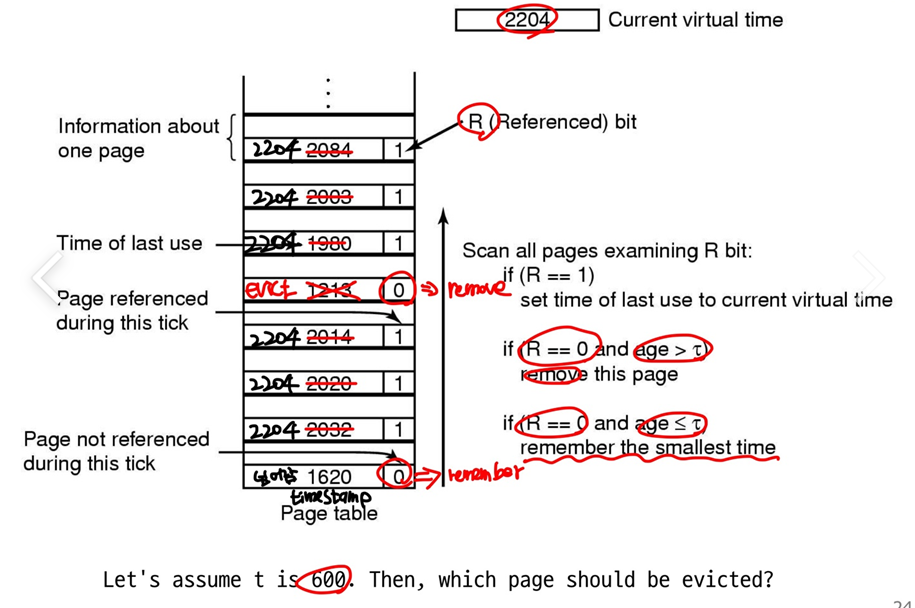
스캐닝을 얼마나 자주 하는지, t 시간을 얼마나 하는지에 따라 WS의 t,w를 정할 수 있으며 그 안에(WS) 들어있는지 판단하여 evict하는 방식이다.(LRU와 비슷한 방식이다. 오래된 것을 evict)
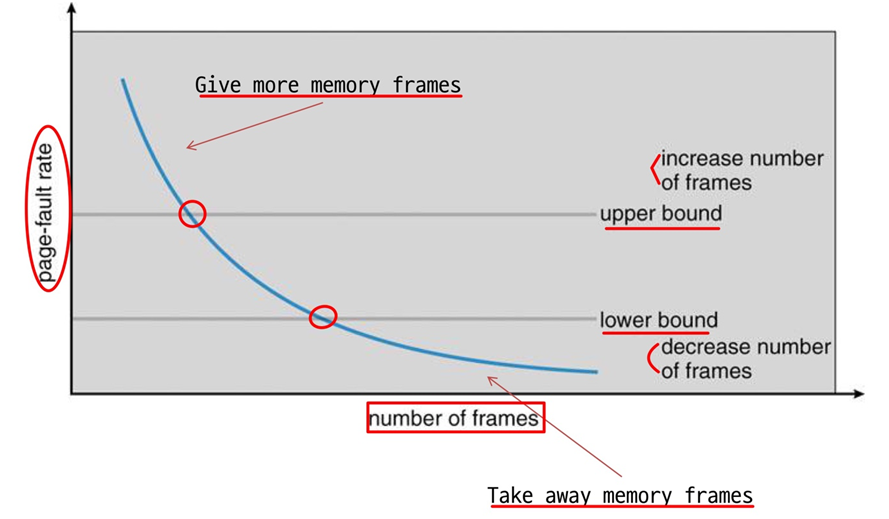
PFF(Page Fault Frequency)
- 각 프로세스의 page fault rate를 모니터한다.
- fault rate가 특정 값(high threshold)보다 높으면 메모리를 더 줘서 fault rate를 낮춘다. 그러나 항상 유효하다고 할 수 없다. 왜냐면 FIFO, Belady's anomally가 있기 때문이다. 메모리를 더 주거나 뺏는 것은 replacement를 어떤 알고리즘으로 하는지에 따라 달라진다.
- fault rate이 특정 값(low threshold)이 너무 낮으면 메모리를 뺏는다.
- PFF가 증가하면 free frame이 없을 수도 있다. 결국 thrashing상황이 올 수 있으므로 어떤 프로세스를 중지시킨다.
summary
VM 메커니즘
- physical, virtual addressing
- partitioning, paging, segmentation
- page table management, TLB
VM 정책
- page replacement algorithms
- memory alocation policies
VM은 hw와 OS 지원을 요구한다.
- MMU(Memory Manangement Unit) -> MMU에 따라 OS코드가 정해질 필요가 있다.
- TLB(Translation Lookaside Buffer)
- Page Tables -> MMU에 맞게 설계되어야 한다.
VM 최적화
- Demand Paging(space를 줄임) : page단위로 disk와 메인 메모리를 왔다갔다한다.
- page tables 관리(space를 줄임) : two level paging
- 효율적인 translation using TLB(time을 줄임)
- Page replacement policy(time을 줄임)
Advanced functionality
- Sharing momory
- Copy on write
- Mapped files
