1. page tables(메모리 공간 차지함)의 사이즈를 어떻게 줄일지?
2. 어떻게 address translation 시간을 단축할지??
page tables
- space overhead가 존재한다.(커널이 사용하는 메모리 공간에 메모리를 잡아야 한다.)
-> 32비트 주소 공간을 쓰고 page당 4kb를 쓴다고 하면 프로세스 당 대략 4mb의 page tables사이즈를 잡아야한다.- 따라서 이 오버헤드를 어떻게 줄일까?
-> 실제로 사용되는 메모리(주소 공간)만 맵핑하는 것이다.
-> 전체를 메모리로 유지하지 않고 그 중 일부만 메모리에 유지한다. 프로세스가 항상 4G의 메모리 주소 공간을 사용하지는 않기 때문이다.- 어떻게 사용되는 메모리만 맵핑할까?
-> page table structure가 동적으로 늘어났다가 줄어들었다가 해야한다.
-> use another level of indirection(다른 structure를 쓰기도 한다.)(Two-level, hierarchial, hashed, etc.
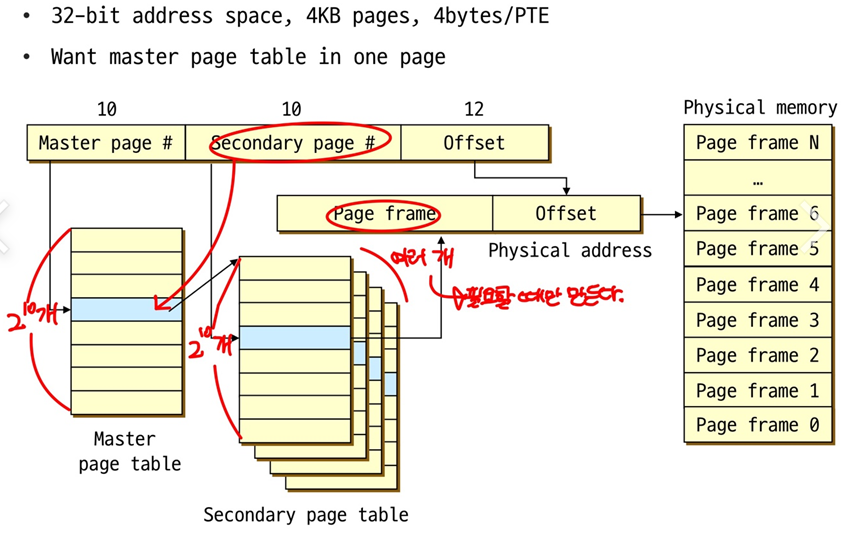
Two-level Page Tables(전체 사이즈를 줄이기 위함.)
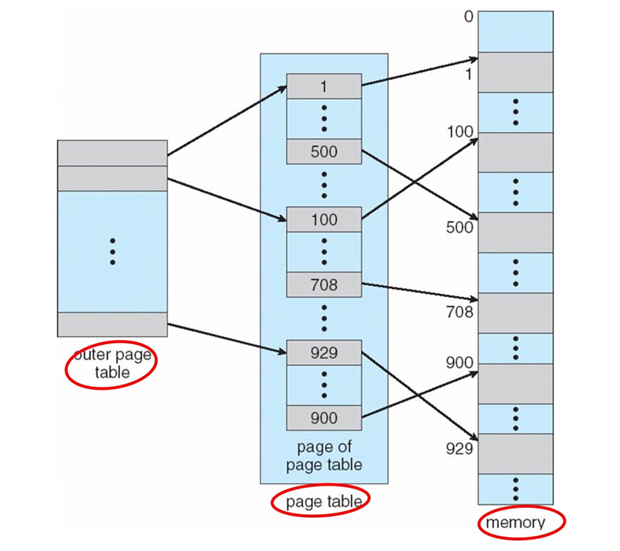
- virtual address를 3개의 parts로 쪼갠다
-> Master page #, Secondary page #, Offset- Master page table
-> Master page # -> Secondary page #- Secondary page table
-> Secondary page # -> page frame #
이렇게 하면 PT size가 줄어들 수 있을까?
-> Secondary page table은 필요할 때만 만들게 된다. 만약 Secondary page table(size가 훨씬 작음)이 하나만 있으면 될 때, Master page table 하나와 Secondary page table하나만 있으면 된다.
Hashed Page Tables
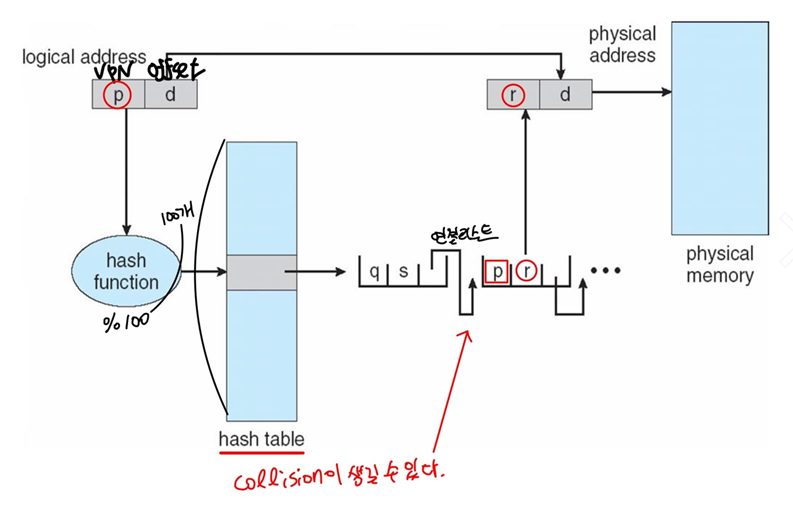
- hash function을 어떻게 정의하는지에 따라서 전체적인 Page Tables의 사이즈를 조절할 수 있다.(줄일 수 있다.), Virtual page number로 hashing을 하여 hashed page tables를 만든다.
- 각 hash entry들은 linked list를 가져야 한다. 충돌이 생기면 해결할 수 있기 위한 방법. but 충돌이 발생하면 찾아야 한다는 문제점이 있다. 따라서 access하는 시간은 길어질 수 있지만 PT size를 줄일 수 있다.
- 각 element들은 Virtual page number(VPN), The value of the mapped page frame, A pointer to the next element in the linked list를 가져야 한다.
Clusterd page tables(Hashed page table에서 변화)
PT size를 줄이기 위한 방법
각 entry는 연속적인 page tables의 블록에 대한 mapping info를 가진다.
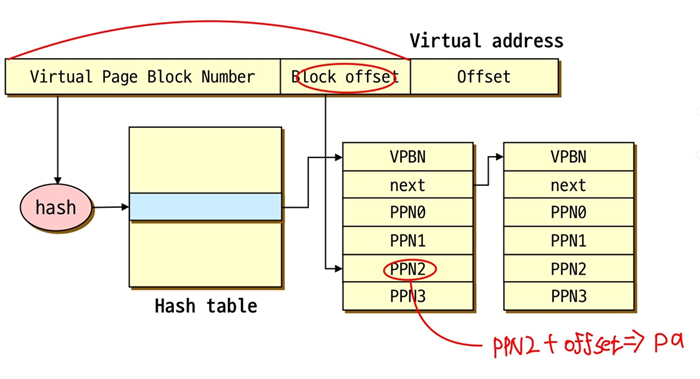
Inverted Page Tables
PT size를 줄이기 위한 방법
1. 앞에서 나온 hashed page tables 방법들은 virtual memory를 기준으로 hashed page table을 만들었지만 이 방법은 physical memory를 기준으로 hashed page table을 만든다.
2. pid를 만드는 이유는 pm을 기준으로 시스템 상에 page table 하나만 만들기 위함이다. 어떤 프로세스가 p라는 va를 access할 수 있고 또 다른 프로세스도 p라는 va를 access할 수 있다. 따라서 pid와 p의 값을 같이 저장한다.
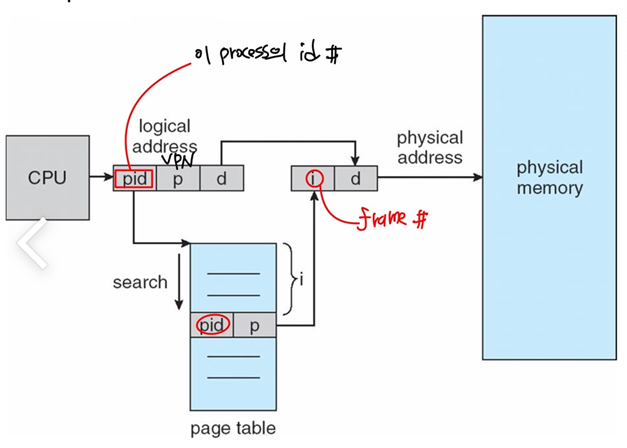
- 메인 메모리의 각 실제 page에 대해 하나의 entry만 가진다. pm이 2^20이면 inverted page table도 2^20이다. 단, 모든 프로세스에서 딱 하나의 inverted page table이 존재한다.
- but 각 entry가 포함하고 있어야 하는 것이 달라지게 되는데 실제 메모리 위치에 저장된 페이지의 virtual address + 각 페이지를 포함하고 있는 프로세스에 대한 정보(pid)를 포함해야 한다.(PID를 관리해야 한다. 오버헤드 발생)
- 이 방식으로 pt를 저장하는 메모리가 줄어들게 된다.
- 문제는 search를 해야한다. (pid, p)가 포함된 index를 찾아야 한다. 굉장히 큰 오버헤드 발생
- search를 줄이기 위해 hash table과 섞어서 사용할 수 있다.
Paging Page Tables
page table도 커널에 들어있는 DS(자료구조) 메모리가 잡힌 것이라서 page table을 가지고 있는 page를 disk로 내려보낼 수 있다.
1. page tables이 어디에 저장되었는가? 고민
(1) physical memory로 page table을 관리한다면 위치를 찾아보기 쉽고 traslation도 필요없다. 어차피 OS만 page table을 관리하기 때문에 virtual page도 관리할 필요가 없다.
-> 그러나, VAS가 유지되는 동안 page table을 계속 관리해야 한다.
(2) Virtual memory(OS virtual address space) : OS가 관리하는 VAS에 page table을 할당하고 관리한다.
-> 그러면 잘 안쓰는 page table은 page out해서 disk로 보낸다.
-> 문제는 addressing page table은 translation을 거쳐야 한다.
-> two-level page table로 만들었을 때, secondary page table은 내려보낼 수 있지만 outer page table을 내려보냈을 때 문제가 발생한다. 따라서 outer page table을 내려보내지 않는 조치(wiring)가 필요하다. 내려보내면 문제가 발생한다.
이로써 paging page tables 기법을 사용할 수 있게 되고, 전체 OS address space 역시 잘 paging할 수 있게 된다.
중요한 부분에 대해서는 wiring해야 한다.(운영체제가 쓰는 코드 혹은 데이터, interrupt나 exception을 쓰는 핸들러)
more faster address translation에 대한 고민
TLB(HW)
- va를 pa로 바꿔줘야하는데 이 작업을 조금 더 빠르게 하고자 한다. 왜냐하면 page table을 거친다는 이야기는 비용이 두 배가 된다는 것이다. 즉, page table을 찾고 나서 그 데이터를 access할 수 있기 때문이다. 한 번에 갈 수 있는 방법을 찾는 것이다.
- two-level page table은 비용이 세 배가 된다. master, secondary, data 이것도 secondary page table이 physical memory에 존재한다는 가정하에 그렇다. 만약 paging out돼서 disk에 내려가 있다면 오버헤드는 점점 더 커진다.
- 그래서 이 과정을 조금 더 빠르게 할 수 없을까?
-> 목적 : va로부터 데이터를 가져오는 일을 physical address를 이용해서 즉, translation없이 한 번에 빨리 처리하기 위함이다.
-> 해결방법으로 TLB(Translation Lookaside Buffer, Memory Management Unit에 의해 관리되는 hw)라는 cache를 사용하는 것이다. 하드웨어적인 TLB를 사용해서 page table을 잠깐 캐쉬해놓겠다는 아이디어이다.
TLB는 hw로 구현되었다.
> Page Table 전체의 일부를 캐슁하고 있는 구조이다.
-> machine cycle 한 번만에 page table에 있는 frame #를 알아낼 수 있다. 훨씬 더 빨리 access할 수 있다. TLB에서 PTE에서 갖고 있는 내용을 거의 그대로 볼 수 있다. TLB에 액세스하면 page #를 찾고 바로 frame #를 찾을 수 있다.
- TLB는 성능을 위해 fully associative cache로 되어 있다.(모든 엔트리를 parallel하게 한 번에 찾아볼 수 있어야 한다. 가능한 빠르게 찾아볼 수 있도록 한다.)
- cache이므로 tags(VPN), values(PTE, entries from page tables)를 가지고 이를 통해 진짜로 가지고 있는 page table인지 판단한다.
- PTE+offset 조합으로 TLB를 가지고 있는 MMU가 직접적으로 physical address를 계산할 수 있도록 하는 구조를 가지게 된다.
TLB는 locality를 갖고 있기 때문에 효과적이다.
page table을 액세스하는 것은 locality가 매우 높기 때문에 조그만 cache를 가지고 있어도 hit될 확률이 높다.
-> 실제 프로세스들은 소량의 PTE(16~48개)를 가지고 있다. 2^20에 비하면 굉장히 작은량이다. Hit rate가 높을 수록 굉장히 좋고 중요하다. Hit rate이 얼마인지에 따라 전체 시스템의 성능에 크게 미찬다.
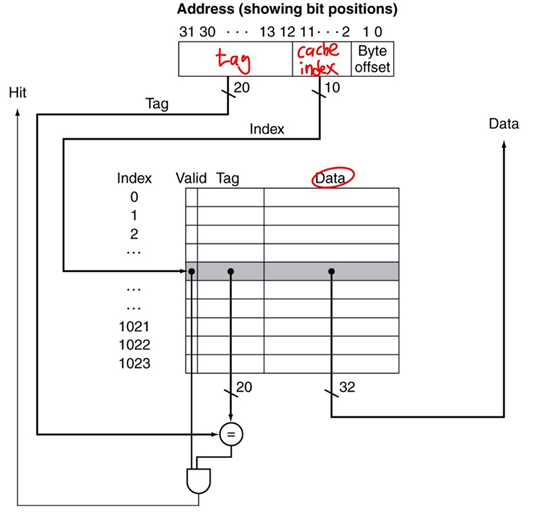
cache에는 Direct Mapped Cache, Set Associative Cache, Fully Associative Cache가 있다.
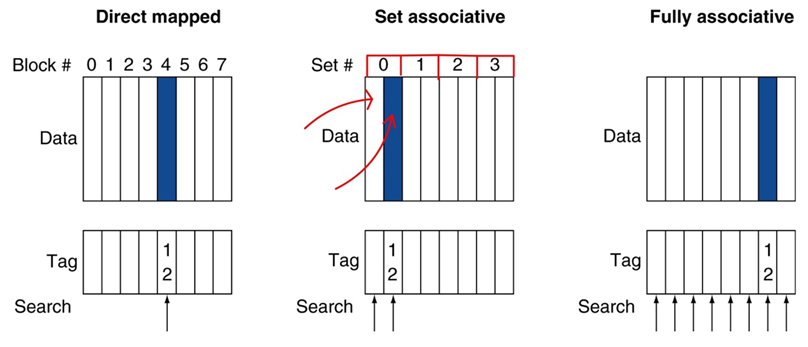
Direct Mapped Cache
address에 의해 location이 정해진다. 메모리에 있는 address는 cache에서 정해진 한 자리에만 넣을 수 있다.(충돌이 생길 수 있다.) 따라서 여러 메모리 주소가 경쟁한다. 장점은 심플하다는 것이고 단점은 충돌이 생긴다는 것이다.
Set Associative Cache
정해진 set에 address를 넣을 수 있다. 단점은 내가 원하는 x라는 address를 찾기 위해 두군데를 찾아봐야 한다.(search의 비용이 증가한다.)
Fullay Associative Cache
메모리에 있는 데이터는 어느위치에도 들어갈 수 있지만 대신 search비용이 더 증가한다. 회로도 복잡해지고 cache의 비용도 증가한다.
Cache associativtity가 증가할수록 보통 miss-rate는 낮아진다. 히트율은 높아지고 대신 cache를 만드는 비용은 증가한다.
Fast Translation Using a TLB
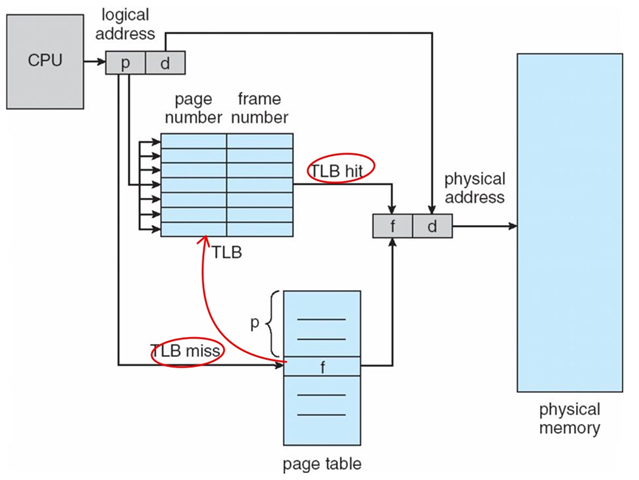
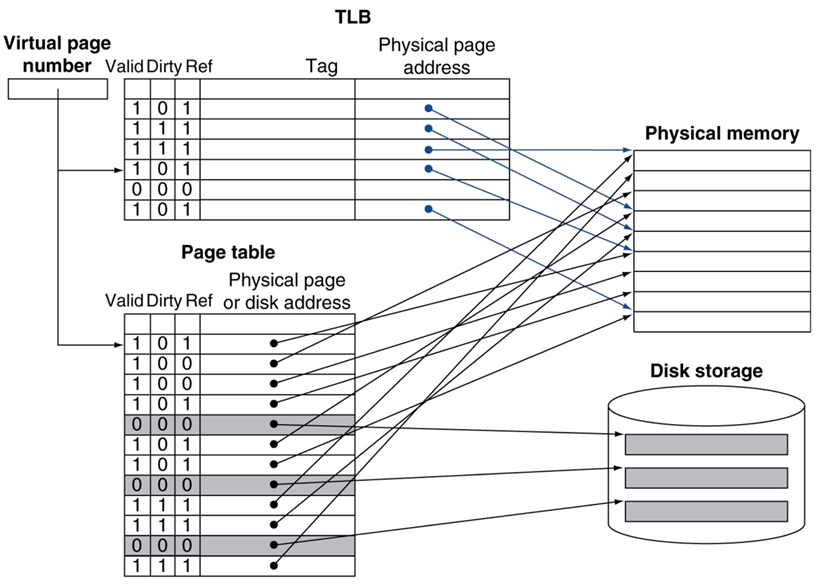
VPN이 있을 때, 제일 먼저 같은 HW(CPU 내부에 존재)내에 있는 TLB를 찾아본다. Physical memory와 page table은 main memory에 있다.
1. 운좋게 TLB에서 내가 원하는 frame #을 찾으면 바로 physical memory에 액세스할 수 있다.
2. 운이 안좋으면 page table에서 찾아보게 되고 frame #을 무조건 찾을 수 있다. 관건은 PTE를 TLB어딘가로 집어 넣게 되고 따라서 누군가가 올라가면 누군가는 빠져야 한다.
3. 더 운이 나쁘게 disk에 있다면 복잡한 일이 발생한다. disk에 있는 page를 physical memory에 올리고 page table의 내용을 바꾸고 PTE의 내용(R, V비트)을 바꾸고 TLB에 올린다.
address translation은 대부분 TLB에 의해 hit가 일어난다.
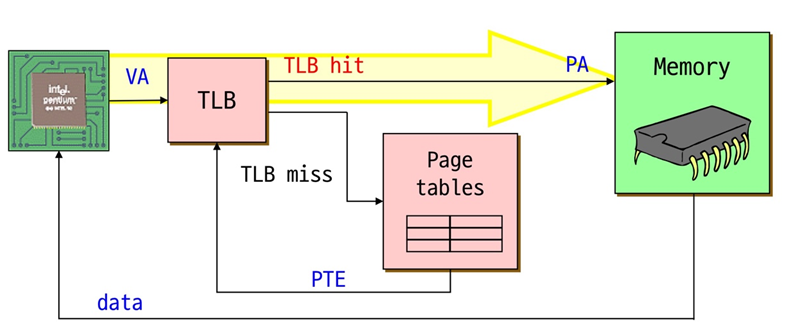
대략 99.9% 이상 hit가 일어난다. 1% 정도 미스, page table에 액세스하면 또, 액세스할 확률이 높고 그 주변이 액세스할 확률이 높으므로 TLB에 한 번 올라오면 hit날 확률이 높다.
만약 miss되었을 때,
- MMU(HW)(대부분 사용)
-> HW가 page table이 어디 있는지 알고 있고 직접적으로 액세스한다. 그러려면 page table구조와 hw가 정의한 구조가 일치해야 한다.- Software loaded TLB(OS)
-> TLB miss fault를 OS가 처리할 수 있도록 하였다.(HW가 지원하지 않을 때) OS가 알아서 PTE를 찾고 TLB에 load한다.
-> 그러나 과정이 굉장히 빨라야 하며 하지만 HW보다 OS가 하는 것이 느리다.
-> 또한, CPU ISA가 TLB조작에 대한 instruction을 지원해줘야 가능한 일이다.
-> OS가 flexible하게 PTE의 내용을 변경할 수 있다.
TLB 관리
- OS는 TLB와 page tables의 내용이 일치한다는 것을 보장할 수 있어야 한다.
- process가 context switch할 때, TLB를 flush하고 reload하도록 만들어졌다.
-> TLB는 CPU 내에 단 하나 존재하고 page tables은 process마다 가지고 있다. 따라서 context switch할 때, TLB에 있는 entries를 invalidate해야 한다. 즉, 다시 process를 액세스할 때, process의 page table의 내용을 다시 TLB로 가져와야 한다. 그러한 오버헤드가 발생한다.- 만약 이 과정이 싫다면 PID를 TLB entry에 저장해야 하고 이에 따른 오버헤드도 발생한다. 실제로는 하지 않는다.
- TLB가 miss났을 때, 새로운 PTE가 로딩되어야한다. TLB에 cach되어 있던 PTE는 빠져나가야(evict) 한다.
-> victim PTE를 고르는 것은 TLB replacement policy라고 불리며 누구를 빼고 올릴것인지 고민하는 것이다.
-> 이를 위한 알고리즘(LRU..)이 있다. 하지만 대부분 HW로 구현해야 하며 가능하면 simple한 방식을 사용한다.
Memory Reference
대부분 TLB hit가 99%이상 일어난다.
MMU에 있는 TLB에서 read를 하기 시작하고 TLB가 실제로 page number를 찾기 위해서 lookup한다. page number를 찾게 되면 PTE를 알 수 있게 되고
TLB는 PTE protection이 read를 허용하는지 check한다.
PTE는 physical frame이 잡는 page를 특정한다.
MMU는 physical frame #와 offset을 조합해서 physical address를 알아낸다.
MMU는 physical address에 가서 값을 가져오고 CPU에 리턴한다.
TLB 미스를 모두 핸들링한 후, valid PTE를 TLB가 가지고 있는다. 다음부터 TLB hit case처럼 동일하게 동작한다.
TLB miss가 recursive fault가 된다면
- page table lookup(by OS or HW)을 했는데 recursive page fault가 일어날 수 있다. 왜냐하면 page table이 paging out되어 있기 때문이다.
- OS내에 vas에서 page table을 관리하는 경우에 page table이 담겨 있는 physical memory자체가 paging out돼서 disk에 내려가 있을 수 있다.
- page fault handler가 disk에서 찾아서 physical momory로 page table을 laod한다. PTE를 다시 TLB에 업데이트한다.
- TLB가 PTE를 가지면 다시 translation을 시작한다.
- 대부분의 case는 PTE가 valid page를 액세스할 수 있다.
- 그렇지 않은 경우로 TLB fault가 다시 한 번 일어날 수 있다. PTE protection bit가 설정되어 있을 경우이다.
page faults
PF can be two cases
1. Read/Write/Execute(protection fault) : operation이 허용되지 않을 때
2. Invalid : virtual page가 할당되어있지 않거나 physical memory에 없어 page out된 상태
TLB가 OS에 trap을 건다.
1. Read/Write/Execute : OS가 문제 있는 것이라고 알려준다.
2. Invalid(Not allocated) : OS가 프로세스에게 fault를 보내준다.
3. Invalid(Not in physical memory, disk에 있는 경우) : OS가 page fault handler를 불러서 frame을 할당해주고 디스크에서 읽어서 physical memory에 업데이트하고 PTE를 수정한다.
