Boosting Zero-shot Learning via Contrastive Optimization of Attribute Representations 제2부 method
Introduction
Visiual recognition flourishes in the presence of deep neural networks (DNNs) [1]–[3].
flourishes 번창하다
시각적 인식은 심층 신경망(DNN)의 존재 하에서 번창한다[1]–[3].
Great success has been achieved with the availability of large amount of data and efficient machine learning techniques.
availability 가용성, 유용성
많은 양의 데이터와 효율적인 기계 학습 기술의 가용성으로 큰 성공을 거두었다.
The learned models are good experts to recognize visual classes that they were trained with, nonetheless, often fail to generalize on unseen classes with few or no training samples.
학습된 모델은 훈련된 시각적 클래스를 인식하는 훌륭한 전문가이지만, 훈련 샘플이 거의 또는 전혀 없는 보이지 않는 클래스를 일반화하는 데 종종 실패합니다.
To tackle this, several learning paradigms such as few-shot learning [4]–[6], zeroshot learning [7]–[9], self-supervised learning [10], [11] are introduced given different data/label availability during training and testing.
tackle 해결하다
이를 해결하기 위해 퓨샷 학습[4]–[6], 제로샷 학습[7]–[9], 자체 지도 학습[10], [11]과 같은 몇 가지 학습 패러다임이 훈련과 테스트 중에 서로 다른 데이터/라벨 가용성에 대해 도입된다.
This paper focuses on zero-shot learning (ZSL) where models are learned with sufficient data of seen classes and deployed to recognize unseen classes.
이 문서는 본 클래스의 충분한 데이터로 모델을 학습하고 보이지 않는 클래스를 인식하도록 배포하는 ZSL(제로샷 학습)에 중점을 둡니다.
An extended setting to ZSL is referred to as the generalized zero-shot learning (GZSL) where learned models are required to recognize both seen and unseen classes at testing stage.
ZSL에 대한 확장된 설정을 GZSL(일반화 제로샷 학습)이라고 하며, 여기서 학습된 모델은 테스트 단계에서 보이는 클래스와 보이지 않는 클래스를 모두 인식해야 합니다.
GZSL is closer to the recognition problem we face in the real world.
GZSL은 우리가 현실 세계에서 직면하는 인식 문제에 더 가깝습니다.
Below, unless specified, we use ZSL to refer to both settings.
아래에서는 지정하지 않는 한 ZSL을 사용하여 두 설정을 모두 참조합니다.
Despite that no training samples are provided for unseen classes in ZSL, the semantic information is available both sides to relate seen and unseen classes.
ZSL에서 보이지 않는 클래스에 대한 훈련 샘플이 제공되지 않음에도 불구하고 의미론적 정보는 보이는 클래스와 보이지 않는 클래스를 연결하기 위해 양쪽에서 모두 사용할 수 있습니다.
The essential idea is to transfer knowledge from seen classes to unseen classes which can be through either the visual-to-semantic mapping [12]– [14] or reversely the semantic-to-visual mapping [15]–[17].
through either 둘중 하나를 통해
필수적인 아이디어는 시각 - 의미 론적 매핑 [12]- [14] 또는 역으로 의미 론적 매핑 [15]-[17]을 통해 볼 수있는 클래스에서 보이지 않는 클래스로 지식을 전달하는 것입니다.
Commonly used semantic information includes human-defined attributes of classes [18] and machine-generated word vectors of classes [19].
일반적으로 사용되는 의미 정보에는 클래스의 인간 정의 속성[18]과 기계 생성 클래스의 단어 벡터[19]가 포함됩니다.
A number of representative methods in ZSL make use of generative models to synthesize visual features for unseen classes based on their class semantics [20]–[22].
synthesize 합성하다
ZSL의 많은 대표적인 방법은 생성 모델을 사용하여 클래스 의미론[20]–[22]을 기반으로 보이지 않는 클래스에 대한 시각적 특징을 합성한다.
Generative models can be hard to optimize as there exists a substantial gap between virtual features and features from real images.
생성 모델은 가상 특징과 실제 이미지의 특징 사이에 상당한 격차가 있기 때문에 최적화하기 어려울 수 있습니다.
To bypass the use of generative models, other works tend to directly learn an embedding function associating visual features with corresponding semantic features [12], [13], [23]–[25].
bypass 우회시키다, align 정렬하다
생성 모델의 사용을 우회하기 위해 다른 작업에서는 시각적 특징을 해당 의미적 특징과 연관시키는 임베딩 기능을 직접 학습하는 경향이 있습니다[12], [13], [23]–[25].
Because of the enriched representations of visual objects, these methods have reported state of the art results.
시각적 개체의 풍부한 표현으로 인해 이러한 방법은 최첨단 결과를 보고했습니다.
Despite their success, they still face challenges: attribute features are extracted within each individual image; due to the intra-attribute variance, one attribute might appear in form of multiple scattered features in the embedding space (see Fig. 1).
그들의 성공에도 불구하고, 그들은 여전히 도전에 직면 해 있습니다 : 속성 기능은 각 개별 이미지 내에서 추출됩니다. 속성 내 분산으로 인해 하나의 속성이 포함 공간에 여러 흩어져 있는 피쳐의 형태로 나타날 수 있습니다(그림 1 참조).
This weakens the feature representativeness, hence impairs the classification.
impair 손상시키다, 악화시키다
이것은 특징의 대표성을 약화시켜 분류를 손상시킨다.
To tackle it, we propose to boost zero-shot learning via contrastive optimization between attribute prototypes across images and attribute-level features within images.
이를 해결하기 위해 이미지 전반의 속성 프로토타입과 이미지 내 속성 수준 기능 간의 대조 최적화를 통해 제로샷 학습을 향상할 것을 제안합니다.
As a result, the knowledge of attributes can be robustly learned and transferred from seen classes to unseen class in ZSL.
결과적으로 속성에 대한 지식은 ZSL의 보이는 클래스에서 보이지 않는 클래스로 강력하게 학습되고 이전될 수 있습니다.
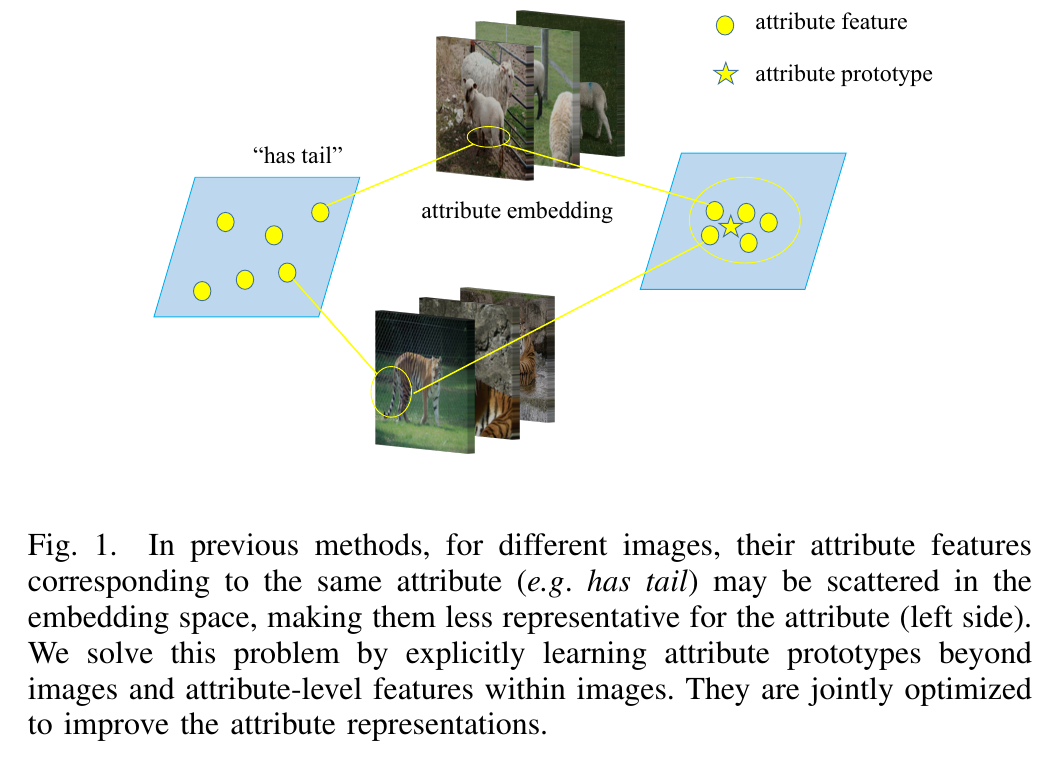
In previous methods, for different images, their attribute features corresponding to the same attribute (e.g. has tail) may be scattered in the embedding space, making them less representative for the attribute (left side).
이전 방법에서는 다른 이미지에 대해 동일한 속성(예: 꼬리가 있음)에 해당하는 속성 특징이 임베딩 공간에 흩어져 속성(왼쪽)을 덜 대표할 수 있습니다.
We solve this problem by explicitly learning attribute prototypes beyond images and attribute-level features within images.
이미지 너머의 속성 프로토타입과 이미지 내의 속성 수준 기능을 명시적으로 학습하여 이 문제를 해결합니다.
They are jointly optimized to improve the attribute representations.
속성 표현을 개선하기 위해 공동으로 최적화됩니다.
