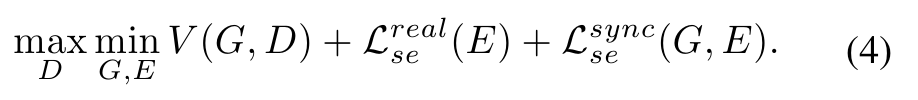Contrastive Embedding for Generalized Zero-Shot Learning 제 4부
3. Contrastive Embedding for GZSL
In this section, we first define the Generalized Zero-Shot Learning (GZSL) problem, before introducing the proposed hybrid GZSL framework and the contrastive embedding in it.
이 섹션에서는 제안된 하이브리드 GZSL 프레임워크와 이에 대한 대조 임베딩을 도입하기 전에 먼저 GZSL(Generalized Zero-Shot Learning) 문제를 정의합니다.
3.1 Problem deifintion
In ZSL, we have two disjoint sets of classes: S seen classes in and U unseen classes in , where we have .
disjoint 분리된
ZSL에는 두 개의 분리된 클래스 세트가 있습니다. 의 S 보이는 클래스와 의 U 보이지 않는 클래스, 여기서 입니다.
Suppose that N labeled instances from seen classes are provided for training:, where denotes the instance and is the corresponding seen class label.
denote 나타내다
본 클래스 에서 N개의 레이블이 지정된 인스턴스가 학습을 위해 제공된다고 가정합니다. , 여기서 는 인스턴스를 나타내고 는 해당 보이는 클래스 레이블입니다.
The test set contains M unlabeled instances.
테스트 세트 에는 레이블이 지정되지 않은 M개의 인스턴스가 있습니다.
In conventional ZSL, the instances in come from unseen classes only.
기존 ZSL에서 의 인스턴스는 보이지 않는 클래스에서만 가져옵니다.
Under the more challenging Generalized Zero-Shot Learning (GZSL) setting, the instances in come from both seen and unseen classes.
come from 출신이다, 가져오다
보다 도전적인 GZSL(Generalized Zero-Shot Learning) 설정에서 의 인스턴스는 보이는 클래스와 보이지 않는 클래스 모두에서 가져옵니다.
At the same time, the class-level semantic descriptors of both seen and unseen classes are also provided , where the first S semantic descriptors correspond to seen classes in and the last U semantic descriptors correspond to unseen classes in
descriptors 설명자
동시에 보이는 클래스와 보이지 않는 클래스의 클래스 수준 의미 설명자도 , 여기서 첫 번째 S 의미 설명자는 에서 본 클래스에 해당하고 마지막 U 의미 설명자는 에서 보이지 않는 클래스에 해당합니다.
We can infer the semantic descriptor for labeled instance x from its class label y.
클래스 레이블 y에서 레이블이 지정된 인스턴스 x에 대한 의미 설명자 를 추론할 수 있습니다.
3.2 A Hybrid GZSL Framework
Semantic embedding (SE) in conventional ZSL aims to learn an embedding function E that maps a visual feature x into the semantic descriptor space denoted as .
기존 ZSL의 SE(Semantic Embedding)는 시각적 특징 x를 로 표시된 의미 설명자 공간에 매핑하는 포함 기능 E를 학습하는 것을 목표로 합니다.
The commonly-used semantic embedding methods rely on a structured loss function proposed in [2, 18].
일반적으로 사용되는 의미적 임베딩 방법은 [2, 18]에서 제안한 구조화된 손실 함수에 의존합니다.
The structured loss requires the embedding of being closer to the semantic descriptor of its ground-truth class than the descriptors of other classes, according to the dot-product similarity in the semantic descriptor space.
구조화된 손실은 의미 설명자 공간의 내적 유사성에 따라 다른 클래스의 설명자보다 실측 클래스의 의미론적 설명자 에 더 가까운 의 임베딩을 필요로 합니다.
Concretely, the structured loss is formulated as below:
Concretely 구체적으로, 명시적으로
구체적으로, 구조적 손실은 다음과 같이 공식화된다.:
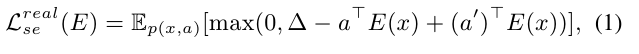
where is the empirical distribution of the real training samples of seen classes, is a randomly-selected semantic descriptor of other classes, and is a margin parameter to make E more robust.
distribution 분포
여기서 는 보이는 클래스의 실제 훈련 샘플의 경험적 분포이고, 는 다른 클래스의 무작위로 선택된 의미 설명자이며, 은 E를 더 견고하게 만들기 위한 여유 매개 변수이다.
Semantic embedding methods are less effective in GZSL due to the severe bias towards seen classes.
severe 심각한 bias 편향
시맨틱 임베딩 방법은 보이는 클래스에 대한 심각한 편향으로 인해 GZSL에서 덜 효과적입니다.
Recently, many feature generation methods [70, 38, 50, 28, 5] have been proposed to synthesize the missing training samples for unseen classes.
최근에는 보이지 않는 클래스에 대한 누락된 훈련 샘플을 합성하기 위해 많은 특징 생성 방법[70, 38, 50, 28, 5]이 제안되었습니다.
Feature generation methods learn a conditional generator network to produce the samples conditioned on a Gaussian noise and a semantic descriptor .
특징 생성 방법은 조건부 생성기 네트워크 를 학습하여 샘플 가우시안 잡음 및 의미 설명자 에 따라 조정됩니다.
In the meanwhile, a discriminator network D is learned together with G to discriminate a real pair from a synthetic pair .
한편, 판별자 네트워크 D는 G와 함께 학습되어 실제 쌍 와 합성 쌍 를 구별합니다.
The feature generator G tries to fool the discriminator D by producing indistinguishable synthetic features.
indistinguishable 구분이 안되는, 구별할 수 없는 fool 속이다
특징 생성기 G는 구별할 수 없는 합성 특징을 생성함으로써 판별기 D를 속이려고 한다.
The feature generation methods hope to match the synthetic feature distribution with the real feature distribution in the original feature space.
특징 생성 방법은 합성 특징 분포를 원래 특징 공간의 실제 특징 분포와 일치시키기를 희망합니다.
The feature generator network G and the discriminator network D can be learned by optimizing the following adversarial objective:
특징 생성기 네트워크 G와 판별기 네트워크 D는 다음과 같은 적대적 목표를 최적화하여 학습할 수 있습니다.
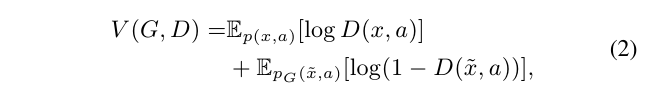
where is the joint distribution of a synthetic feature and its corresponding semantic descriptor.
여기서 는 합성 기능과 해당 의미 설명자의 공동 분포입니다.
The feature generation methods learn to synthesize the visual features in the original feature space.
특징 생성 방법은 원래 특징 공간에서 시각적 특징을 합성하는 방법을 배웁니다.
However, in the original feature space, the visual features are usually not well-structured and thus are suboptimal for GZSL classification.
그러나 원래 기능 공간에서 시각적 기능은 일반적으로 잘 구조화되지 않으므로 GZSL 분류에 적합하지 않습니다.
In this paper, we propose a hybrid GZSL framework, integrating the embedding model and the feature generation model.
본 논문에서는 임베딩 모델과 특징 생성 모델을 통합한 하이브리드 GZSL 프레임워크를 제안한다.
In our hybrid GZSL framework, we map both the real features and the synthetic features into an embedding space, where we perform the final GZSL classification.
하이브리드 GZSL 프레임워크에서 실제 기능과 합성 기능을 모두 임베딩 공간에 매핑하여 최종 GZSL 분류를 수행합니다.
3In its simplest form, we just choose the semantic descriptor space as the embedding space and combine the learning objective of semantic embedding defined in Eq.1 and the objective of feature generation defined in Eq.2.
가장 간단한 형태로, 우리는 임베딩 공간으로 시맨틱 디스크립터 공간을 선택하고 Eq.1에 정의된 Semantic Embedding의 학습 목표와 Eq.2에 정의된 기능 생성 목표를 결합합니다.
To map the synthesized features into the embedding space as well, we introduce the following embedding loss for the synthetic features:
합성 특징을 임베딩 공간에도 매핑하기 위해 합성 특징에 대해 다음과 같은 임베딩 손실을 도입합니다.
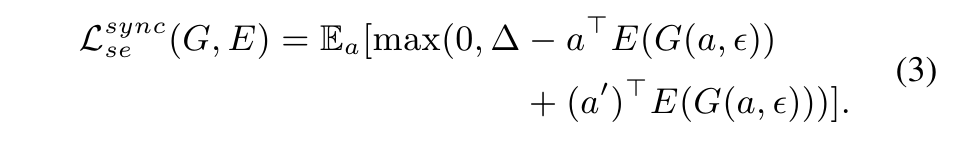
Notably, we formulate only using the semantic descriptors of seen classes.
특히, 우리는 본 클래스의 시맨틱 디스크립터만을 사용하여 를 공식화합니다.
Therefore, the total loss of our basic hybrid GZSL approach takes the form of
따라서 기본 하이브리드 GZSL 접근 방식의 총 손실은 다음과 같은 형태를 취합니다.