Contrastive Embedding for Generalized Zero-Shot Learning 제4-2부
3.3 Contrastive Embedding
Our basic hybrid GZSL framework is based on the traditional semantic embedding model, where only the class-wise supervision is exploited.
우리의 기본 하이브리드 GZSL 프레임워크는 클래스별 감독만 활용되는 전통적인 의미 임베딩 모델을 기반으로 한다.
In this section, we present a new contrastive embedding (CE) model for our hybrid GZSL framework.
이 섹션에서는 하이브리드 GZSL 프레임워크를 위한 새로운 CE(Contrastive Embedding) 모델을 제시합니다.
The contrastive embedding consists of the instance-level contrastive embedding based on the instance-wise supervision and the class-level contrastive embedding based on the class-wise supervision.
대조 임베딩은 인스턴스 단위 감독에 기반한 인스턴스 수준 대조 임베딩과 클래스 단위 감독에 기반한 클래스 수준 대조 임베딩으로 구성됩니다.
Instance-level contrastive embedding
In the embedding space, the embedding of a visual sample is denoted as .
임베딩 공간에서 시각적 샘플 의 임베딩은 로 표시됩니다.
For each data point embedded from either a real or synthetic seen feature, we set up a classification subproblem to distinguish the unique one positive example from total K negative examples .
unique 고유한 subproblem 하위 문제
실제 또는 합성된 기능에서 포함된 각 데이터 포인트 에 대해 분류 하위 문제를 설정하여 고유한 긍정적 예시 를 총 K개의 부정적인 예시 {h− 1 , .. . ,h -K}.
The positive example being randomly selected has the same class label with , while the class labels of the negative examples are different from ’s class label.
무작위로 선택되는 긍정적인 예제 는 와 동일한 클래스 레이블을 갖는 반면 부정적인 예제의 클래스 레이블은 의 클래스 레이블과 다릅니다.
Here, we follow the strategy in [12] to add a non-linear projection head H in the embedding space: .
여기에서 [12]의 전략을 따라 임베딩 공간에 비선형 투영 헤드 H를 추가합니다. .
And we perform the -way classification on to learn the embedding .
그리고 임베딩 를 학습하기 위해 에 대해 -way 방향 분류를 수행합니다.
Concretely, the cross-entropy loss of this (K + 1)-way classification problem is calculated as follows:
구체적으로, 이 (K + 1) 방향 분류 문제의 교차 엔트로피 손실은 다음과 같이 계산됩니다.
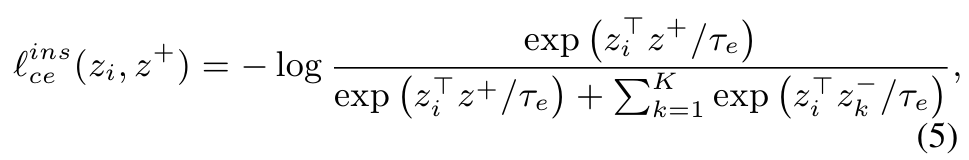
where > 0 is the temperature parameter for the instance-level contrastive embedding and K is the number of negative examples.
여기서 > 0은 인스턴스 수준 대조 임베딩에 대한 온도 매개변수이고 K는 음수 예의 수입니다.
Intuitively, a large K will make the problem in Eq.5 more difficult.
Intuitively 직관적으로
직관적으로 큰 K는 식 5의 문제를 더 어렵게 만듭니다.
The large number of negative examples encourages the embedding function E to capture the strong discriminative information and structures shared by the samples, real and synthetic, from the same class in the embedding space.
encourage 격려하다, 권장하다
많은 수의 부정적인 예제는 임베딩 함수 E가 임베딩 공간에서 동일한 클래스의 실제 및 합성 샘플에 의해 공유되는 강력한 차별적 정보와 구조를 캡처하도록 장려한다.
To learn the embedding function E, the non-linear projection H and the feature generator network G, we calculate the loss function for the instance-level contrastive embedding as the expected loss computed over the randomly selected pairs and for both the real and synthetic examples, where but they belong to the same seen class.
임베딩 함수 E, 비선형 투영 H 및 피처 생성기 네트워크 G를 배우기 위해, 우리는 인스턴스 수준 대비 임베딩에 대한 손실 함수를 실제 및 합성 예 모두에 대해 무작위로 선택된 쌍 와 에 대해 계산된 예상 손실로 계산한다. 여기서 는 동일한 보이는 클래스에 속한다.
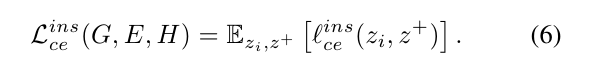
Class-level contrastive embedding
Analogously, we can formulate a class-level contrastive embedding.
Analogously 비슷하게, 유사하게
유사하게, 우리는 클래스 수준 대조 임베딩을 공식화할 수 있습니다.
Since we do not limit our embedding space to be the semantic descriptor space, we cannot compute the dot-product similarity between an embedded data point and a semantic descriptor directly.
임베딩 공간을 시맨틱 디스크립터 공간으로 제한하지 않기 때문에 임베디드 데이터 포인트와 시맨틱 디스크립터 사이의 내적 유사성을 직접 계산할 수 없습니다.
Thus, we learn a comparator network F(h, a) that measures the relevance score between an embedding h and a semantic descriptor a.
relevance 관련성
따라서 임베딩 h와 의미 설명자 a 사이의 관련성 점수를 측정하는 비교기 네트워크 F(h, a)를 학습합니다.
With the help of the comparator network F, we formulate the class-level contrastive embedding loss for a randomly selected point h_i in the embedding space as an S-way classification subproblem.
비교기 네트워크 F의 도움으로 임베딩 공간에서 무작위로 선택된 점 h_i에 대한 클래스 수준 대조 임베딩 손실을 S-way 분류 하위 문제로 공식화합니다.
The goal of this subproblem is to select the only one correct semantic descriptor from total S semantic descriptors of seen classes.
이 하위 문제의 목표는 본 클래스의 전체 S 의미 설명자에서 올바른 의미 설명자 하나만 선택하는 것입니다.
In this problem, the only positive semantic descriptor is the one corresponding to ’s class, while the remaining S − 1 semantic descriptors from the other classes are treated as the negative semantic descriptors.
remaining 남아있는
이 문제에서 유일한 양의 의미 기술자는 h_i의 클래스에 해당하는 것이고, 나머지 S - 1개의 다른 클래스의 의미 기술자는 음의 의미 기술자로 취급된다.
Similarly, we can calculate the cross-entropy loss of this S-way classification problem as below:
마찬가지로 이 S-way 분류 문제의 교차 엔트로피 손실을 다음과 같이 계산할 수 있습니다:
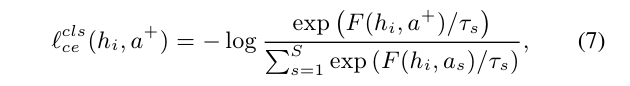
where > 0 is the temperature parameter for the classlevel contrastive embedding and S is the number of seen classes.
여기서 > 0은 클래스 수준 대조 임베딩에 대한 온도 매개변수이고 S는 본 클래스의 수입니다.
The class-level contrastive embedding relies on the class-wise supervision to strengthen the discriminative ability of the samples in the new embedding space.
클래스 수준 대조 임베딩은 새 임베딩 공간에서 샘플의 판별 능력을 강화하기 위해 클래스별 감독에 의존합니다.
We define the following loss function for the class-level contrastive embedding:
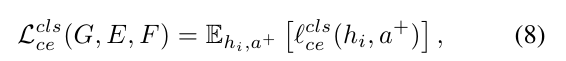
which is the expected loss over the samples, either real or synthetic, in the new embedding space, and their corresponding semantic descriptor, i.e. the positive descriptor.
expected 예상되는 synthetic 합성의
이는 새로운 임베딩 공간에서 실제 또는 합성 샘플에 대한 예상 손실과 해당 의미론적 설명자, 즉 긍정적 설명자입니다.
