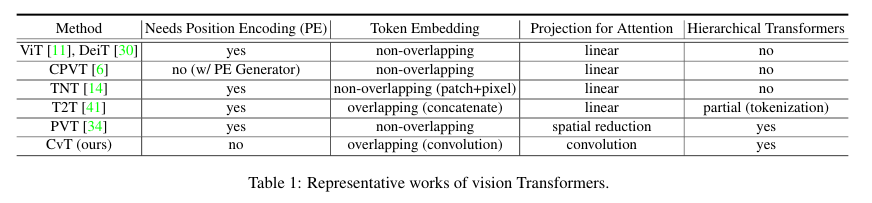
1. Introduction
Transformers [31, 10] have recently dominated a wide range of tasks in natural language processing (NLP) [32].
트랜스포머[31, 10]는 최근 자연어 처리(NLP)[32]에서 광범위한 작업을 지배했습니다.
The Vision Transformer (ViT) [11] is the first computer vision model to rely exclusively on the Transformer architecture to obtain competitive image classification performance at large scale.
competitive 경쟁력 있는
비전 트랜스포머(ViT)[11]는 대규모로 경쟁력 있는 이미지 분류 성능을 얻기 위해 트랜스포머 아키텍처에 전적으로 의존하는 최초의 컴퓨터 비전 모델이다.
The ViT design adapts Transformer architectures [10] from language understanding with minimal modifications.
adapt 적용하다, 적응하다
ViT 디자인은 최소한의 수정으로 언어 이해에서 Transformer 아키텍처[10]를 적용합니다.
First, images are split into discrete nonoverlapping patches (e.g. 16x16).
nonoverlapping 겹치치않는
먼저, 이미지가 겹치지 않는 개별 패치로 분할됩니다(예: 16 × 16).
Then, these patches are treated as tokens (analogous to tokens in NLP), summed with a special positional encoding to represent coarse spatial information, and input into repeated standard Transformer layers to model global relations for classification.
treat 처리하다, 다루다 sum 합산되다 analogous 유사한 coarse 거친
그런 다음, 이러한 패치는 토큰(NLP의 토큰과 유사)으로 처리되고, 거친 공간 정보를 나타내기 위해 특수 위치 인코딩으로 합산되고, 분류를 위해 전역 관계를 모델링하기 위해 반복되는 표준 Transformer 레이어에 입력됩니다.
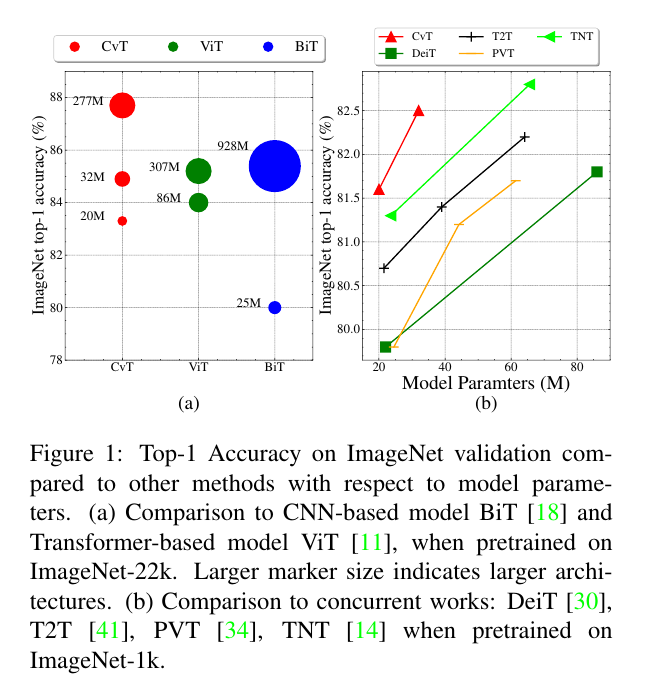
with respect to ~에 관하여
Despite the success of vision Transformers at large scale, the performance is still below similarly sized convolutional neural network (CNN) counterparts (e.g., ResNets [15]) when trained on smaller amounts of data.
below 낮은 counterparts 상대
대규모 비전 트랜스포머의 성공에도 불구하고 더 적은 양의 데이터에 대해 훈련할 때 성능은 여전히 비슷한 크기의 CNN(Convolutional Neural Network) 대응물(예: ResNets[15])보다 낮습니다.
One possible reason may be that ViT lacks certain desirable properties inherently built into the CNN architecture that make CNNs uniquely suited to solve vision tasks.
inherently 내재하는, 본질적으로 uniquely 독특한 certain 특정
한 가지 가능한 이유는 ViT가 CNN 아키텍처에 본질적으로 내장된 특정 바람직한 속성이 부족하기 때문일 수 있다.((built into the CNN architecture) that CNN이 비전 작업을 해결하는 데 고유하게 적합)
For example, images have a strong 2D local structure: spatially neighboring pixels are usually highly correlated.
neighboring pixels 인접 픽셀 correlated 상관관계
예를 들어, 이미지는 강력한 2D 로컬 구조를 가지고 있습니다. 공간적으로 인접한 픽셀은 일반적으로 높은 상관 관계가 있습니다.
The CNN archi-tecture forces the capture of this local structure by using local receptive fields, shared weights, and spatial subsampling [20], and thus also achieves some degree of shift, scale, and distortion invariance.
invariance 불변성 distortion 왜곡 some degree 어느 정도 subsampling 하위 샘플링``receptive 수용 force 사용하다
CNN 아키텍처는 로컬 수용 필드, 공유 가중치 및 공간 서브샘플링[20]을 사용하여 이 로컬 구조를 강제로 캡처하므로 어느 정도의 이동, 규모 및 왜곡 불변성을 달성합니다.
In addition, the hierarchical structure of convolutional kernels learns visual patterns that take into account local spatial context at varying levels of complexity, from simple low-level edges and textures to higher order semantic patterns.
take into account 고려하다
또한, 컨볼루션 커널의 계층 구조는 단순한 낮은 수준의 에지 및 질감에서 고차 의미 패턴에 이르기까지 다양한 수준의 복잡도에서 로컬 공간 컨텍스트를 고려하는 시각적 패턴을 학습한다.
In this paper, we hypothesize that convolutions can be strategically introduced to the ViT structure to improve performance and robustness, while concurrently maintaining a high degree of computational and memory efficiency.
hypothesize 가설을 세우다 concurrently ~와 함께 robustness 강건함 strategically 전략적으로
본 논문에서는 높은 수준의 계산 및 메모리 효율성을 동시에 유지하면서 성능과 견고성을 향상시키기 위해 ViT 구조에 컨볼루션을 전략적으로 도입할 수 있다고 가정한다.
To verify our hypothesises, we present a new architecture, called the Convolutional vision Transformer (CvT), which incorporates convolutions into the Transformer that is inherently efficient, both in terms of floating point operations (FLOPs) and parameters.
incorporates 포함하다 in terms of ~의 측면에서, 관점에서 vertify 검증하다
우리의 가설을 검증하기 위해 우리는 컨볼루션 비전 트랜스포머(CvT)라고 하는 새로운 아키텍처를 제시합니다. 이 아키텍처는 컨볼루션을 FLOP(부동 소수점 연산) 및 매개변수 측면에서 본질적으로 효율적인 트랜스포머에 통합합니다.
The CvT design introduces convolutions to two core sections of the ViT architecture.
CvT 설계는 ViT 아키텍처의 두 가지 핵심 섹션에 컨볼루션을 도입합니다.
First, we partition the Transformers into multiple stages that form a hierarchical structure of Transformers.
partition 나누다
먼저 Transformer를 여러 단계로 분할하여 Transformer의 계층 구조를 형성합니다.
The beginning of each stage consists of a convolutional token embedding that performs an overlapping convolution operation with stride on a 2D-reshaped token map (i.e., reshaping flattened token sequences back to the spatial grid), followed by layer normalization.
overlaping 중첩, 겹치는 bakc 뒤로, 다시, 예전의 followed by 뒤이어. ~로 이어지는, 다음
각 단계의 시작은 2D로 재구성된 토큰 맵에서 스트라이드로 중첩 컨볼루션 작업을 수행하는 컨볼루션 토큰 임베딩(즉, 평평한 토큰 시퀀스를 공간 그리드로 다시 재구성하는 것)과 계층 정규화를 차례로 수행하는 컨볼루션 토큰 임베딩으로 구성된다.
This allows the model to not only capture local information, but also progressively decrease the sequence length while simultaneously increasing the dimension of token features across stages, achieving spatial downsampling while concurrently increasing the number of feature maps, as is performed in CNNs [20].
progressively 점진적으로 simultaneously 동시에 stages 단계 concurrently 동시에, 함께
이를 통해 모델은 로컬 정보를 캡처할 수 있을 뿐만 아니라 시퀀스 길이를 점진적으로 줄이는 동시에 여러 단계에서 토큰 기능의 차원을 증가시켜 공간 다운샘플링을 달성하는 동시에 CNN에서 수행되는 것처럼 기능 맵의 수를 늘릴 수 있습니다[20].
Second, the linear projection prior to every self-attention block in the Transformer module is replaced with our proposed convolutional projection, which employs a s × s depth-wise separable convolution [5] operation on an 2D-reshaped token map.
emplot 쓰다, 이용하다, 사용하다 separable 분리될 수 있는
둘째, 트랜스포머 모듈의 모든 자기 주의 블록 이전의 선형 투영은 2D 재구성된 토큰 맵에서 s × s 깊이별 분리 가능한 컨볼루션[5] 연산을 사용하는 제안된 컨볼루션 프로젝션으로 대체됩니다.
This allows the model to further capture local spatial context and reduce semantic ambiguity in the attention mechanism.
allow 가능하게 하다, 허락하다, 허용하다 ambiguity 애매모호한 semantic 의미론적
이를 통해 모델은 지역 공간 컨텍스트를 추가로 캡처하고 주의 메커니즘에서 의미론적 모호성을 줄일 수 있습니다.
It also permits management of computational complexity, as the stride of convolution can be used to subsample the key and value matrices to improve efficiency by 4× or more, with minimal degradation of performance.
degradation 저하 degradation of performance 성능 저하 permit 허용하다, 가능하게 하다
또한 컨볼루션의 stride을 사용하여 키 및 값 행렬을 서브샘플링하여 성능 저하를 최소화하면서 효율성을 4× 이상 향상시킬 수 있으므로 계산 복잡성을 관리할 수 있습니다.
In summary, our proposed Convolutional vision Trans-former (CvT) employs all the benefits of CNNs: local receptive fields, shared weights, and spatial subsampling, while keeping all the advantages of Transformers: dynamic attention, global context fusion, and better generalization.
요약하면, 우리가 제안한 컨볼루션 비전 트랜스포머(CvT)는 로컬 수용 필드, 공유 가중치 및 공간 하위 샘플링과 같은 CNN의 모든 이점을 사용하는 동시에 동적 주의, 글로벌 컨텍스트 융합 및 더 나은 일반화라는 트랜스포머의 모든 장점을 유지한다.
Our results demonstrate that this approach attains state-of-art performance when CvT is pre-trained with ImageNet-1k, while being lightweight and efficient: CvT improves the performance compared to CNN-based models (e.g. ResNet) and prior Transformer-based models (e.g. ViT, DeiT) while utilizing fewer FLOPS and parameters.
우리의 결과는 이 접근 방식이 가볍고 효율적인 동시에 ImageNet-1k로 사전 교육될 때 최첨단 성능을 달성한다는 것을 보여준다. CvT는 FLOPS와 매개 변수를 덜 활용하면서 CNN 기반 모델(예: ResNet) 및 이전 트랜스포머 기반 모델(예: ViT, DeIT)에 비해 성능을 향상시킨다.
In addition, CvT achieves state-of-the-art performance when evaluated at alrger scale pretriaining(e.g. on the public ImageNet-22k dataset).
또한 CvT는 대규모 사전 교육(예: 공개 ImageNet-22k 데이터 세트)에서 평가할 때 최첨단 성능을 달성합니다.
Finally, we demonstrate that in this new design, we can drop the positional embedding for tokens without any degradation to model performance.
마지막으로, 우리는 이 새로운 디자인에서 모델 성능 저하 없이 토큰에 대한 위치 임베딩을 삭제할 수 있음을 보여줍니다.
This not only simplifies the architecture design, but also makes it readily capable of accommodating variable resolutions of input images that is critical to many vision tasks.
accommodating 수용하는, 협조하는
이는 아키텍처 설계를 단순화할 뿐만 아니라 많은 비전 작업에 중요한 입력 이미지의 다양한 해상도를 쉽게 수용할 수 있도록 합니다.