3. Vision transformer: overview
In this section, we briefly recall preliminaries associated with the vision transformer [15, 52], and further discuss positional encoding and resolution.
recall : 상기하다 preliminary : 예비의 further : 좀 더 (자세히)
이 섹션에서는 비전 트랜스포머[15, 52]와 관련된 예비 사항을 간략히 상기하고 위치 인코딩 및 해상도에 대해 자세히 논의한다.
Multi-head Self Attention layers(MSA)
The attention mechanism is based on a trainable associative memory with (key, value) vector paris.
associative : 연합의, 연관의
주의 메커니즘은 (키, 값) 벡터 쌍이 있는 훈련 가능한 연관 메모리를 기반으로 합니다.
A query vector is matched against a set of key vector (packed together into a matirx using ineer products.
matche : 일치하다 against: ~에 대해, ~에 반대하여
쿼리 벡터 는 내적을 사용하여 키 벡터 세트(행렬 로 함께 묶음)에 대해 일치됩니다.
These ineer products are then scaled and normalized with a softmax fuction to obtain weights.
그런 다음 이 내적을 스케일링하고 softmax 함수로 정규화하여 k 가중치를 얻습니다.
The output of the attention is the weighted sum of a set of value vectors (packed in to
주의의 출력은 k 값 벡터 세트의 가중치 합입니다( 로 압축됨).
For a sequence of query vectors (packed int ), it produces an output matrix ( of size ):
packed : 압축하다
N 쿼리 벡터 시퀀스( 로 압축)에 대해 출력 행렬(크기 N × d)을 생성합니다.
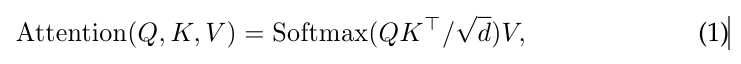
where the function is applied over each row of the input matirx and the term provides appropriate normalization.
여기서 Softmax 함수는 입력 행렬의 각 행에 적용되고 항은 적절한 정규화를 제공합니다.
In [52], a Self-attention layer is proposed.
Query, key and values matrices are themselves computed from a sequence of input vectors (packed into ):
쿼리, 키 및 값 행렬은 N개의 입력 벡터 시퀀스에서 자체적으로 계산됩니다(로 압축됨).
, , , using linear transformations , , with the constraint , meaning that the attention is in between all the input vectors.
, , , 제약 조건 과 함께 선형 변환 , , 를 사용하여 주의가 모든 입력 벡터 사이에 있음을 의미합니다.
Finally, Multi-head self-attention layer(MSA) is defined by considering attention "heads', i.e. self-attention functions applied to the input.
마지막으로, 다중 헤드 자가 주의 계층(MSA)은 주의 "헤드", 즉 개의 자가 주의 기능이 입력에 적용되는 것을 고려하여 정의됩니다.
Each head provides a sequence of size N × d.
These h sequences are rearranged into a N × dh sequence that is reprojected by a linear layer into N × D.
reprojected : 재 투영되다
이러한 h 시퀀스는 선형 레이어에 의해 N × D로 재투영되는 N × dh 시퀀스로 재배열됩니다.
Transformer block for images.
To get a full transformer block as in [52], we add a Feed-Forward Network(FFN) on top of the MSA layer.
[52]에서와 같이 완전한 변환기 블록을 얻으려면 MSA 계층 위에 Feed-Forward Network(FFN)를 추가합니다.
This FFN is composed of two linear layers separated by a GeLU activation.
The first linear layer expands the dimension form D to 4D, and the second layer reduces the dimension from 4D back to D.
첫 번째 선형 레이어는 차원을 D에서 4D로 확장하고 두 번째 레이어는 차원을 4D에서 D로 축소합니다.
Both MSA and FFN are operationg as residual operators thank to skip-connections, and with a layer normalization.
MSA와 FFN은 모두 스킵 연결과 계층 정규화 덕분에 잔여 연산자로 작동합니다[3].
In order to get a transformer to process images, our work builds upon the ViT model [15].
process 처리하다
변환기가 이미지를 처리하도록 하기 위해 우리의 작업은 ViT 모델을 기반으로 합니다[15].
It is a simple and elegant architecture that processes input images as if they were a sequence of input tokens.
elegant : 우아한 as if : (마치) ~처럼
입력 이미지를 입력 토큰의 시퀀스인 것처럼 처리하는 간단하고 우아한 아키텍처입니다.
The fixed-size input RGB image is decomposed into a batch of N patches of a fixed size of 16 × 16 pixels (N = 14 × 14).
고정 크기 입력 RGB 이미지는 16 × 16 픽셀(N = 14 × 14)의 고정 크기 N 패치 배치로 분해됩니다.
Each patch is projected with a linear layer that conserves its overall dimension 3 × 16 × 16 = 768..
각 패치는 전체 차원을 3 × 16 × 16 = 768로 유지하는 선형 레이어로 투영됩니다.
The transformer block described above is invariant to the order of the patch embeddings, and thus does not consider their relative position.
invariant : 불변, 변함없는 abobe 위에
위에서 설명한 변환기 블록은 패치 임베딩의 순서에 불변하므로 상대적 위치를 고려하지 않습니다.
The positional information is incorporated as fixed[52] or trainable [18] positional embeddings.
위치 정보는 고정된 [52] 또는 학습 가능한 [18] 위치 임베딩으로 통합됩니다.
They are added before the first transformer block to the patch tokens, which are then fed to the stack of transformer blocks.
첫 번째 트랜스포머 블록 앞에 패치 토큰이 추가되고, 이 토큰은 트랜스포머 블록의 스택에 공급됩니다.
The class token
The class token is a trainable vector, appended to the patch tokens before the first layer, that goes through the transformer layers, and is then projected with a linear layer to predict the class.
append : 첨부, 추가(V) go through : 통과하다 ,겪다 prjocet with : ~로 투영되다
클래스 토큰은 훈련 가능한 벡터이며, 첫 번째 레이어 앞에 패치 토큰에 추가되며, 트랜스포머 레이어를 통과한 다음 선형 레이어로 투영되어 클래스를 예측한다.
This class token is inherited from NLP, and departs from the typical pooling layers used in computer vision to predict the class.
depart from 출발하다
이 클래스 토큰은 NLP[14]로부터 상속되며, 클래스를 예측하기 위해 컴퓨터 비전에 사용되는 일반적인 풀링 레이어에서 출발한다.
The transformer thus process batches of (N+1) X tokens of dimension D, of which only the class vector is used to predict the output.
따라서 변압기는 D차원의 (N + 1) 토큰의 배치를 처리하며, 그 중 클래스 벡터만 출력을 예측하는 데 사용된다.
This architecture forces the self-attention to spread information between the patch tokens and the class token:
이 아키텍처는 패치 토큰과 클래스 토큰 사이에 정보를 분산시키기 위해 자기 주의를 강제합니다.
at training time the supervision signal comes only from the class embedding, while the patch tokens are the model's only variable input.
훈련 시간에 감독 신호는 클래스 임베딩에서만 오는 반면, 패치 토큰은 모델의 유일한 변수 입력입니다.
Fixted the positional encoding across resolutions.
across : ~에 걸쳐 , 전체에 걸친
해상도 전반에 걸쳐 위치 인코딩을 수정합니다.
Touvron et al.[50] show that it is desirable to use a lower training resolution and fine-tune the network at the larger resolution.
desireable 바람직하다
Touvron et al. [50]은 더 낮은 훈련 해상도를 사용하고 더 큰 해상도에서 네트워크를 미세 조정하는 것이 바람직함을 보여줍니다.
When increasing the resolution of an input image, we keep the patch size the same, therefore the number N of input patches does change.
입력 이미지의 해상도를 높일 때 패치 크기를 동일하게 유지하므로 입력 패치의 수 N이 변경됩니다.
Due to the architecture of transformer blocks and the class token, the model and classifier do not need to be modified to process more tokens.
Due to ~ 때문에, ~로 인해
변환기 블록 및 클래스 토큰의 아키텍처로 인해 더 많은 토큰을 처리하기 위해 모델 및 분류기를 수정할 필요가 없습니다.
In contrast, one needs to adapt the positional embeddings, because there are N of them, one for each patch.
대조적으로, 각 패치마다 하나씩 N이 있기 때문에 위치 임베딩을 조정해야합니다.
Dosovitskiy et al.[15] interpolate the positional encoding when changin the resolution and demonstrate that this methd works with the subsequent fine-tuning stage.
interpolate : 보건하다 demonstrate : 입증하다
Dosovitskiy et al. [15] 해상도를 변경할 때 위치 인코딩을 보간하고 이 방법이 후속 미세 조정 단계에서 작동함을 보여줍니다.
