4. Distillation through attention
attention을 통한 증류
In this section we assume we have access to a strong image classifier as a teacher model.
이 섹션에서는 교사 모델로서 강력한 이미지 분류기에 액세스할 수 있다고 가정한다.
It could be a convet, or a mixture of classifie.
We address the question of how to learn a transformer by expㅣoiting this teacher.
exploiting : 이용하다, 착취하다
우리는 이 교사를 이용하여 변압기를 배우는 방법에 대한 질문을 다룹니다.
As we will see in Section 5 by comparing the trade-off between accuracy and image throughput, it can be beneficial to replace a convolutional neural network by a transformer.
throughput 처리량
정확도와 이미지 처리량 간의 균형을 비교하여 섹션 5에서 볼 수 있듯이 컨볼루션 신경망을 변환기로 교체하는 것이 유리할 수 있습니다.
This section covers two axes of distillation: hard distillation versus soft distillation, and classical distillation versus the distillation token.
axes : 축
이 섹션에서는 두 가지 증류 축, 즉 경질 증류 대 연질 증류, 고전 증류 대 증류 토큰을 다룹니다.
Soft distillation
Soft distillation [24, 54] minimizes the Kullback-Leibler divergence between the softmax of the teacher and the softmax of the student model.
Soft distillation[24, 54]은 교사의 softmax와 학생 모델의 softmax 사이의 Kullback-Leibler 발산을 최소화합니다.
Let be the logits of the teacher model, the logits of the student model.
를 교사 모델의 로짓이라고 하고 학생 모델의 로짓이라고 합니다.
We denote by τ the temperature for the distillation, λ the coefficient balancing the Kullback–Leibler divergence loss (KL) and the cross-entropy () on ground truth labels y, and ψ the softmax function.
denote : 나타내다, 보여주다
우리는 증류를 위한 온도를 τ로 표시하고, λ는 정답 레이블 y에 대한 Kullback-Leibler 발산 손실(KL)과 교차 엔트로피()의 균형을 맞추는 계수 및 ψ softmax 함수로 표시합니다.
The distillation objective is:
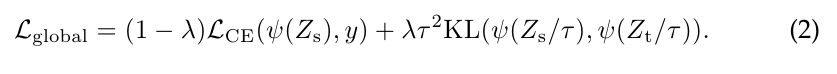
Hard-label dsitillation.
Hard-label distillation. We introduce a variant of distillation where we take the hard decision of the teacher as a true label.
variant : 변형
하드 라벨 증류. 우리는 교사의 어려운 결정을 진정한 라벨로 삼는 증류의 변형을 소개합니다.
Let be the hard decision of the teacher, the objective associated with this hard-label distillation is:
objective : 목적 associated with : ~와 연관된
를 교사의 어려운 결정이라고 하면 이 하드 라벨 증류와 관련된 목적은 다음과 같습니다.
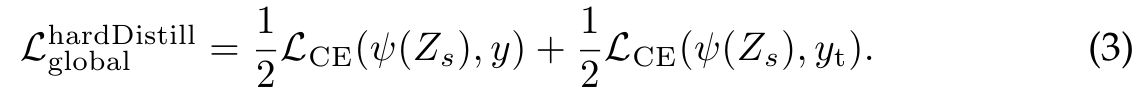
For a given image, the hard label associated with the teacher may change depending on the specific data augmentation.
주어진 이미지에 대해 교사와 관련된 하드 레이블은 특정 데이터 증강에 따라 변경될 수 있습니다.
We will see that this choice is better than the traditional one, while beiing parameter-free and conceptually simpler: The teacher prediction plays the same role as the true label y.
while ~ing : ~보다, conceptually : 개념적
우리는이 선택이 매개 변수가없고 개념적으로 더 간단하면서도 전통적인 선택보다 낫다는 것을 알게 될 것입니다 : 교사 예측 는 실제 레이블 y와 동일한 역할을합니다.
Note also that the hard labels can also be converted into soft labels with label smoothing [47], where the true label is considered to have a probability of 1 − ε, and the remaining ε is shared across the remaining classes.
converted into : ~로 변환하다 reamining 남는, 남아있는
또한 하드 레이블은 레이블 평활(smoothing)[47]을 사용하여 소프트 레이블로 변환될 수도 있습니다. 여기서 실제 레이블은 1 - ε의 확률을 갖는 것으로 간주되고 나머지 ε은 나머지 클래스에서 공유됩니다.
We fix this parameter to ε = 0.1 in our all experiments that use true labels.
실제 레이블을 사용하는 모든 실험에서 이 매개변수를 ε = 0.1로 수정합니다.
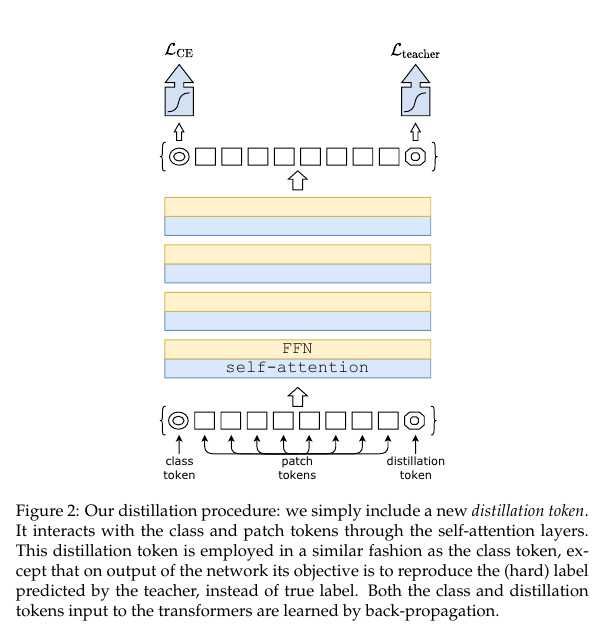
Figure 2:
Our distillation procedure: we simply include a new distillation token.
우리의 증류 절차: 단순히 새로운 증류 토큰을 포함합니다.
It interacts with the class and patch tokens through the self-attention layers.
셀프 어텐션 레이어를 통해 클래스 및 패치 토큰과 상호 작용합니다.
This distillation token is employed in a similar fashion as the class token, except that on output of the network its objective is to reproduce the (hard) label predicted by the teacher, instead of true label.
employed: 이용하다
이 증류 토큰은 클래스 토큰과 비슷한 방식으로 사용되지만 네트워크의 출력에서 목표는 실제 레이블 대신 교사가 예측 한 (하드) 레이블을 재현하는 것입니다.
Both the class and distillation tokens input to the transformers are learned by back-propagation.
변압기에 입력되는 클래스와 증류 토큰 모두 역전파를 통해 학습됩니다.
Distillation token
We now focus on our proposal, which is illustrated in Figure 2.
We add a new token, the distillation token, to the initial embeddings (patches and class token).
초기 임베딩(패치 및 클래스 토큰)에 새로운 토큰인 distillation 토큰을 추가합니다.
Our distillation token is used similary as the class token: it interacts with other embeddings through self-attention, and is output by the network aftuer the last layer.
우리의 증류 토큰은 클래스 토큰으로 유사하게 사용됩니다 : 자기 관심을 통해 다른 임베딩과 상호 작용하며 마지막 레이어 이후의 네트워크에 의해 출력됩니다.
Its target objective is given by the distillation component of the loss.
그것의 target 목표는 손실의 증류 성분에 의해 주어진다.
The distillation embedding allows our model to learn from the output of the teacher, as in a regular distillation, while remaining complementary to the class embedding.
allow : 하게하다 while + 명사 : ~하면서 remain 유지하다 complementary: 보완하다
distillation embedding을 통해 우리 모델은 클래스 임베딩을 보완하면서 정규 증류에서와 같이 교사의 출력에서 학습할 수 있습니다.
Interestingly, we observe that the learned class and distillation tokens converge towards different vectors: the average cosine similarity between these tokens equal to 0.06.
converge : 수렴하다 toward : 향하여
흥미롭게도 우리는 학습된 클래스와 증류 토큰이 서로 다른 벡터로 수렴하는 것을 관찰했습니다. 이 토큰 간의 평균 코사인 유사성은 0.06입니다.
As the class and distillation embeddings are computed at each layer, they gradually become more similar through the network, all the way through the last layer at which thier similarity in high(cos=0.93), but still lower than 1.
클래스 및 증류 임베딩이 각 계층에서 계산됨에 따라 네트워크를 통해 점차적으로 유사도가 높지만(cos=0.93) 유사도가 1보다 낮은 마지막 계층을 통해 점점 더 유사해집니다.
This is expected since as they aim at producing targets that are similar but not identical.
identical 유사하
유사하지만 동일하지 않은 목표물을 생산하는 것을 목표로 하기 때문에 이는 예상되는 일입니다.
