5. Experiements.
This section presents a few analytical experiments and results.
present 제시하다
이 섹션에서는 몇 가지 분석 실험과 결과를 제시합니다.
We first discuss our distillation strategy.
Then we comparatively analyze the efficiency and accuracy of convnets and vision transformers.
comparatively 비교적
그런 다음 컨브넷과 비전 트랜스포머의 효율성과 정확도를 비교 분석합니다.
5.1 Transformer models
As mentioned earlier, our architecture design is identical to the one proposed by Dosovitskiy et al. [15] with no convolutions.
As mentioned earlier 앞서 언급 했듯이
앞서 언급했듯이 우리의 아키텍처 디자인은 Dosovitskiy et al.에서 제안한 것과 동일합니다. [15] 회선이 없습니다.
Our only differences are the training strategies, and the distillation token.
우리의 유일한 차이점은 훈련 전략과 증류 토큰입니다.
Also we do not use a MLP head for the pre-training but only a linear classifier.
또한 우리는 사전 훈련을 위해 MLP 헤드를 사용하지 않고 선형 분류기만 사용합니다.
To avoid any confusion, we refer to the results obtained in the prior work by ViT, and prefix ours by DeiT.
혼란을 피하기 위해, 우리는 ViT의 이전 작업에서 얻은 결과를 참조하고 DeiT에 의해 접두사를 붙입니다.
If not specified, DeiT refers to our referent model DeiT-B, which has the same architecture as ViT-B.
specified 명시된
지정하지 않으면 DeiT는 ViT-B와 동일한 아키텍처를 가진 참조 모델 DeiT-B를 나타냅니다.
When we fine-tune DeiT at a larger resolution, we append the resulting operating resolution at the end, e.g, DeiT-B↑384.
DeiT를 더 큰 해상도로 미세 조정할 때 끝에 결과 작동 해상도(예: DeiT-B↑384)가 추가됩니다.
Last, when using our distillation procedure, we identify it with an alembic sign as DeiT⚗.
alembic alembic, (옛날의 증류기)
마지막으로, 우리의 증류 절차를 사용할 때 DeiT⚗라는 표식 기호로 식별합니다.
The parameters of ViT-B (and therefore of DeiT-B) are fixed as D = 768, h = 12 and d = D/h = 64.
ViT-B (따라서 DeiT-B)의 매개 변수는 D = 768, h = 12 및 d = D / h = 64로 고정됩니다.
We introduce two smaller models, namely DeiT-S and Deit-Ti, for which we change the number of heads, keeping d fixed.
우리는 두 개의 더 작은 모델, 즉 DeiT-S와 DeiT-Ti를 소개합니다. 이 모델은 d를 고정한 상태에서 헤드 수를 변경합니다.
Table 1 summarizes the models that we consider in our paper.
표 1은 우리가 논문에서 고려하는 모델을 요약한 것입니다.

Variants of our DeiT architecture.
DeiT 아키텍처의 변형.
The larger model, DeiT-B, has the same architecture as the ViT-B[15].
더 큰 모델인 DeiT-B는 ViT-B와 동일한 아키텍처를 가지고 있습니다[15].
The only parameters that vary across models are the embedding dimension and the number of heads, and we keep the dimension per head constant (equal to 64).
vary 달라지다constant 일정하게
모델에 따라 달라지는 유일한 매개 변수는 임베딩 치수와 헤드 수이며, 헤드당 치수를 일정하게 유지합니다(64와 같음)
Smaller models have a lower parameter count, and a faster throughput.
count 총계
모델이 작을수록 매개 변수 수가 적고 처리량이 더 빠릅니다.
The throughput is measured for images at resolution 224×224.
처리량은 해상도 224×224에서 이미지에 대해 측정됩니다.
5.2 Distillation
Our distillation method produces a vision transformer that becomes on par with the best convnets in terms of the trade-off between accuracy and throughput, see Table 5.
on par with 동등하게
우리의 증류 방법은 정확도와 처리량 간의 균형 측면에서 최고의 convnet과 동등해지는 비전 변압기를 생성합니다(표 5 참조
Interestingly, the distilled model outperforms its teacher in terms of the trade-off between accuracy and throughput.
outperform 뛰어나다 능가하다
흥미롭게도, 증류된 모델은 정확도와 처리량 간의 균형 측면에서 교사를 능가합니다.
Our best model on ImageNet-1k is 85.2% top-1 accuracy outperforms the best Vit-B model pretrained on JFT-300M at resolution 384(84.15%).
ImageNet-1k의 최고의 모델은 85.2%의 top-1 정확도가 384(84.15%)의 해상도에서 JFT-300M에서 사전 훈련된 최고의 Vit-B 모델보다 성능이 뛰어납니다.
For reference, the current state of the art of 88.55% achieved with extra training data was obtained by the ViTH model (600M parameters) trained on JFT-300M at resolution 512.
참고로, 추가 훈련 데이터로 달성한 88.55%의 현재 기술 상태는 해상도 512에서 JFT-300M에서 훈련된 ViTH 모델(600M 매개변수)에 의해 획득되었습니다.
Hereafter we provide several analysis and observations.
Heraafter 그 이후
이후 몇 가지 분석 및 관찰을 제공합니다.
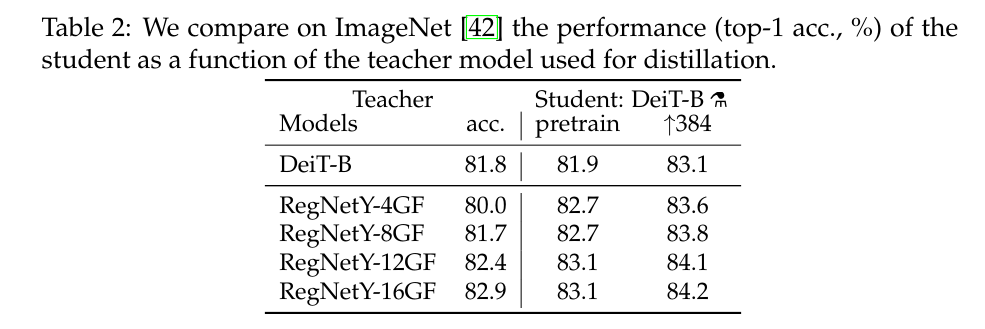
Convets teachers.
We have observed that using a convnet teacher gives better performance than using a transformer
우리는 convnet 교사를 사용하는 것이 변환기를 사용하는 것보다 더 나은 성능을 제공한다는 것을 관찰했습니다.
Table 2 compares distillation results with different teacher architectures.
표 2는 다양한 교사 아키텍처와 증류 결과를 비교합니다.
The fact that the convnet is a better teacher is probably due to the inductive bias inherited by the transformers through distillation, as explained in Abnar et al. [1].
inherited 유전되는 inductive 귀납의, 유도의
Convnet이 더 나은 교사라는 사실은 Abnar et al. [1]에서 설명한 바와 같이, 아마도 증류를 통해 변압기에 의해 유전되는 유도 편향 때문일 것이다.
In all of our subsequent distillation experiments the default teacher is a RegNetY-16GF [40] (84M parameters) that we trained with the same data and same data-augmentation as DeiT.
이후의 모든 증류 실험에서 기본 교사는 DeiT와 동일한 데이터 및 동일한 데이터 증강으로 훈련한 RegNetY-16GF [40](84M 매개 변수)이다.
This teacher reaches 82.9% top-1 accuracy on ImageNet.
이 선생님은 ImageNet에서 82.9%의 상위 1위 정확도에 도달한다.
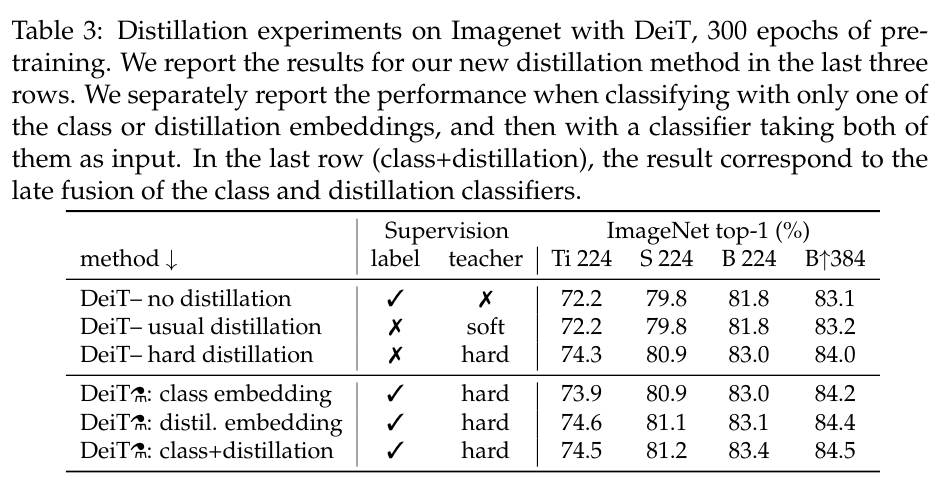
Distillation experiments on Imagenet with DeiT, 300 epochs of pretraining.
DeiT를 사용한 Imagenet의 증류 실험, 사전 훈련 300 에포크.
We report the results for our new distillation method in the last three rows.
우리는 마지막 세 행에 새로운 증류 방법에 대한 결과를 보고합니다.
We separately report the performance when classifying with only one of the class or distillation embeddings, and then with a classifier taking both of them as input.
클래스 또는 증류 임베딩 중 하나만 사용하여 분류할 때 성능을 별도로 보고한 다음 두 분류자가 둘 다 입력으로 사용합니다.
In the last row (class+distillation), the result correspond to the late fusion of the class and distillation classifiers.
correspond 해당하다
마지막 행(class+distillation)에서 결과는 클래스와 증류 분류기의 마지막 융합에 해당합니다.
Comparison of distillation methods.
We compare the performance of different distillation strategies in Table 3.
표 3에서 다양한 증류 전략의 성능을 비교합니다.
Hard distillation significantly outperforms soft distillation for transformers, even when using only a class token:
hard 증류는 클래스 토큰 만 사용하더라도 변압기의 소프트 증류보다 훨씬 우수합니다:
hard distillation reaches 83.0% at resolution 224×224, compared to the soft distillation accuracy of 81.8%.
hard 증류는 분해능 224×224에서 83.0 %에 도달하며 부드러운 증류 정확도는 81.8 %입니다.
Our distillation strategy from Section 4 further improves the performance, showing that the two tokens provide complementary information useful for classification:
섹션 4의 증류 전략은 성능을 더욱 향상시켜 두 토큰이 분류에 유용한 보완적인 정보를 제공한다는 것을 보여줍니다.
the classifier on the two tokens is significantly better than the independent class and distillation classifiers, which by themselves already outperform the distillation baseline.
두 토큰의 분류기는 독립적 인 클래스 및 증류 분류기보다 훨씬 우수하며, 그 자체로 이미 증류 기준선을 능가합니다.
The distillation token gives slightly better results than the class token.
증류 토큰은 클래스 토큰보다 약간 더 나은 결과를 제공합니다.
It is also more correlated to the convnets prediction.
또한 convnet 예측과 더 관련이 있습니다.
This difference in performance is probably due to the fact that it benefits more from the inductive bias of convets.
이러한 성능 차이는 아마도 컨넷의 귀납적 편향으로부터 더 많은 이익을 얻는다는 사실 때문일 것입니다.
We give more detials and an analysis in the next paragraph.
The distillation toekn has an undeniable advantage for the initial training.
undeniable 부인할 수 없는
증류 토큰은 초기 훈련에 대해 부인할 수 없는 이점이 있다.
Agreement with the teacher & inductive bias?
As discuseed above, the architecture of the teacher has an important impact.
위에서 논의한 바와 같이 교사의 구조는 중요한 영향을 미칩니다.
Does it inherit existing inductive bias that would facilitate the training?
inherit 상속받다, 이어받다 facilitate 용이하게 하다. existing 기존의
훈련을 용이하게 하는 기존의 귀납적 편향을 상속합니까?
While we believe it difficult to formally answer this question, we analyze in Table 4 the decision agreement between the convnet teacher, our image transformer DeiT learned from labels only, and our transformer DeiT⚗.
이 질문에 정식으로 답하기 어렵다고 생각하지만 표 4에서 convnet 교사, 레이블에서만 학습한 이미지 변환기 DeiT 및 변환기 DeiT⚗ 간의 결정 일치를 분석합니다.
Our distilled model is more correlated to the convnet than with a transformer learned from scratch.
from scratch 처음부터 배운
우리의 증류 모델은 처음부터 배운 변압기보다 컨트랙트와 더 관련이 있습니다.
As to be expected, the classifier associated with the distillation embedding is closer to the convnet that the one associated with the class embedding, and conversely the one associated with the class embedding is more similar to DeiT learned without distillation.
conversely 반대로
예상대로, 증류 임베딩과 관련된 분류기는 클래스 임베딩과 관련된 분류기보다 convnet에 더 가깝고, 반대로 클래스 임베딩과 관련된 분류기는 증류 없이 학습된 DeiT와 더 유사합니다.
Unsurprisingly, the joint class+distil classifier offers a middle ground.
당연히, 공동 클래스 + distil 분류기는 중간 지점을 제공합니다.
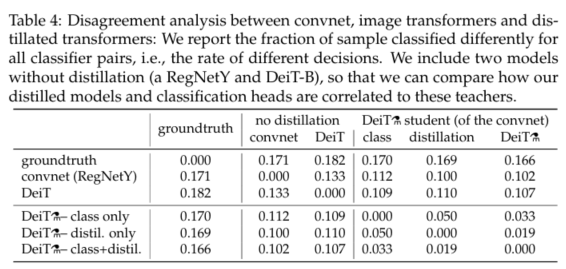
Disagreement analysis between convet, image transformers and distillated transformers:
convnet, 이미지 변환기 및 증류된 변환기 간의 불일치 분석:
We report the faraction of smaple classified differently for all classifier pairs, i.e., the rate of different decision.
fraction 부분, 일부
우리는 모든 분류기 쌍에 대해 다르게 분류된 샘플의 비율, 즉 다른 결정의 비율을 보고한다.
We include two models without distillation (a RegNetY and DeiT-B), so that we can compare how our distilled models and classification heads are correlated to these teachers.
correlate to 상관관계가 있다
증류가 없는 두 가지 모델(RegNetY 및 DeiT-B)을 포함하여 증류된 모델과 분류 헤드가 이러한 교사와 어떻게 상관되는지 비교할 수 있습니다.
Number of epochs.
Increasing the number of epochs significantly imporves the performacne of training with distillation, see Figure 3.
Epoch 수를 늘리면 증류를 사용한 훈련 성능이 크게 향상됩니다(그림 3 참조).
With 300 epochs, our distilled network DeiT-B⚗ is already better than DeiT-B
But while for the latter the performance saturates with longer schedules, our distilled network clearly benefits from a longer training time.
saturates 포화시키다
그러나 후자의 경우 더 긴 일정으로 성능이 포화되는 반면, 우리의 증류된 네트워크는 더 긴 훈련 시간으로부터 분명히 이점을 얻습니다.
