
1. Overview

GPT-4 등의 LLM을 활용하여 Knowledge-Distillation의 목적으로 생성한 Machine-Generated Instruction Following Data를 활용하여, LLM을 Instruction Tuning한 결과, "ChatGPT, GPT-4, Llama, Alpaca, Vicuna" 등의 Zero-Shot Capability가 대폭 상승하였지만, 'LLM Decoder'를 'Visual Encoder'와 결합하는 Multi-Modal 분야에서는 해당 기법이 적극적으로 활용되지 않았다 (23.04 기준)
이에, 해당 논문의 저자들은 'Language only' 'GPT-4'를 활용하여, Multimodal (Language, Image) Instruction-Following Data를 생성 및 'Llama 기반의 Vicuna LLM decoder'를 Fine Tuning하였고, 이에 Larage Langauage and Vision Assistance로서 End-to-End로 학습된 LLaVA 모델을 제안하였다.
저자들은 LLM 분야에서 성공적으로 적용되어 온 Instruction Tuning을 VLM (Vision Language Model)로 확장함으로써, Multimodal-Instruction-Following Capability를 증진한 것을 Main Contribution으로 얘기한다. 해당 논문의 제목 "Visual Instruction Tuning"을 통해서도, 저자들의 의도를 파악할 수 있다.
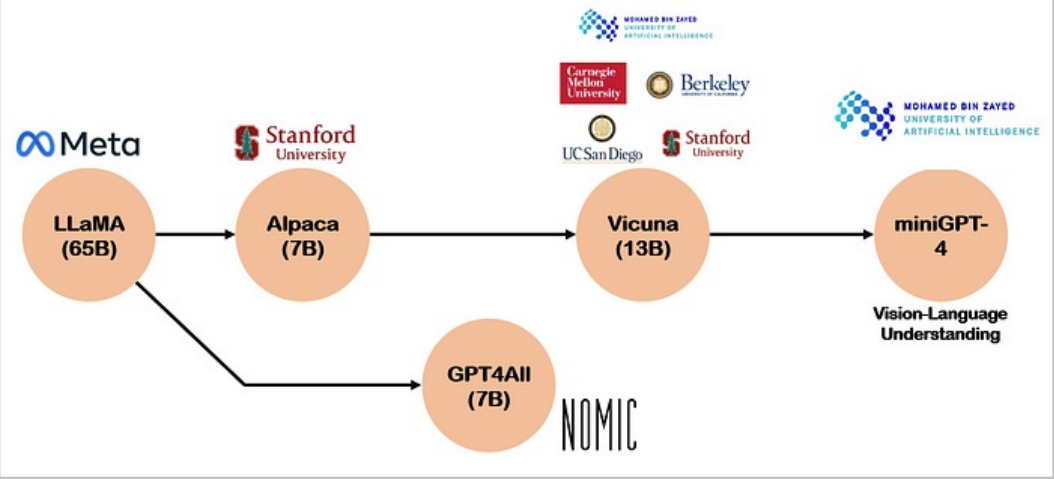
LLaVA-1.5, LLAVA-CoT, VILA, NVILA 등 Opensource VLM 들의 발전을 위한 초석을 이루고 있는 LLaVA는 다음과 같은 Contribution을 지닌다.
"Large Multimodal Model (LMM)"
LLaVA는 Open Source Model만을 활용하여 파이프라인을 구축한 이후, LLaVA 모델 또한 Open source로 공개하였다. Visual Input을 받기 위해 CLIP의 ViT (Vision Transformer) Image Encoder를 활용하였고, Image Embedding과 Query Embedding을 기반으로 Output Text Token을 생성하고자 Vicuna Language Decoder를 활용하였다. 또한 같은 차원의 벡터일지라도, 내포된 의미가 다른 Visual Embedding과 Text Embedding 간의 Alignment를 이루고자, Single Linear Layer로 구성된 Linear Projecetion Matrix 를 활용하였다.
"Multi-Modal Instruction-Following-Data"
Instruction Tuning을 Multi-Modal 분야에 성공적으로 적용한 것은, LLaVA 연구가 처음이었기에, 해당 저자들은 ChatGPT/GPT-4 등의 Text Only Model을 활용하여, Multi-modal Instruction Following Data를 생성하고자 하였고, 이에 기존 "Image-Caption" Pair를 적절한 "Instruction Following Format"으로 변환하는 효과적인 파이프라인을 제시하였다. 또한, Multi-Modal Instruction following capability를 측정하기 위한 "LLaVA-Bench" 벤치마크를 생성한 것을 Contribution으로 이야기 하고 있다.
"Open Source"
LLaVA: https://llava-vl.github.io/
Multi-modal instruction following data, codebase, model checkpoints 등이 모두 Open-Source로 공개되어 있다. 이후 출시된 VILA, NVILA 등의 최신 VLM 또한 LLaVA의 Codebase를 기반으로 구축되었다.
2. Related Works
2.1. Instruction Tuning
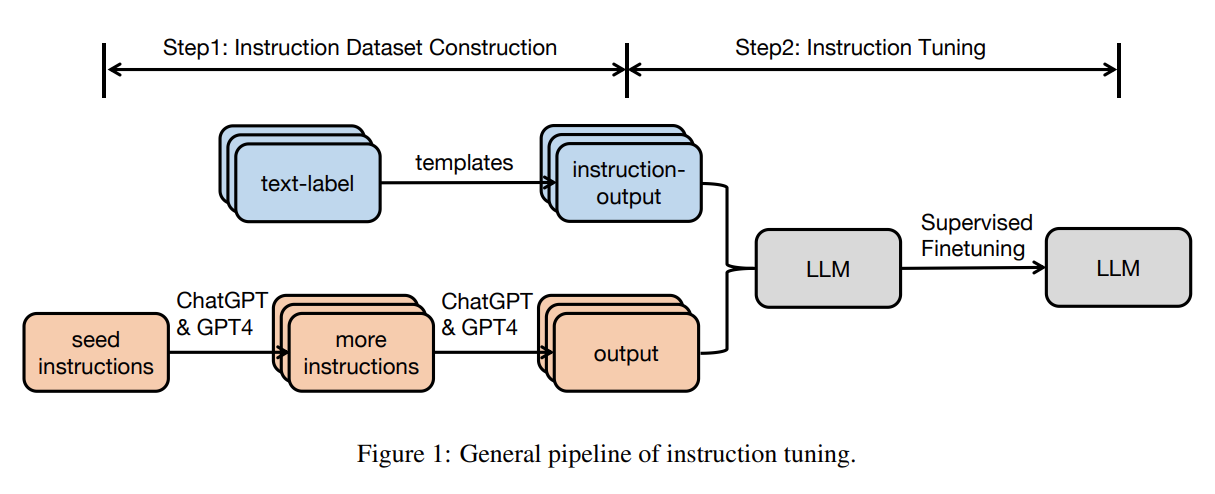
InstructGPT, ChatGPT, FLAN-T5, FLAN-PaLM 등의 LLM이 Instruction-Following Text only Dataset을 통한 Instruction-Tuning의 효과성을 Zero 혹은 Few-shot Generalization Capability를 통해 증명하였다.
기존 BLIP2, KOSMOS-1 등의 LMM이 Task-Transfer 성능을 보여주긴 하였지만, Vision-Language Instriction Data를 통해 전체 아키텍처를 명시적으로 튜닝하지는 않았기에, Language-Only Task에 비해서, Multi-modal Task에서의 모델 성능은 다소 부족한 편이다. 이에, 해당 저자들은 Vision-Language Instruction Tuning을 새롭게 적용하였다고 얘기한다.
2.2. Multimodal Instruction-Following Agents
Computer Vision 에서의 Instruction-Following Agents는 크게 2가지로 구분된다.
(i) End-to-End trained Models
특정한 세부목적을 위해 별도로 학습된 모델을 이야기한다.
- "Vision Language Navigation Task"를 위해, Natural Language Instruction을 기반으로 Visual Environment에서 Sequence of Actions을 취하는 Agents
- "Image editing Task"를 위해, Input Image와 Written Instruction을 입력으로 받는 InstructPix2Pix.
(ii) A System that coordinates various models (i) via LangChain
Multiple Tasks를 해결하고자하는 Visual-ChatGPT, X-GPT, MM-REACT 등의 Multi-modal Model이 이에 해당한다.
LLaVA의 경우, Multiple Multimodal tasks를 (ii) 해결하고자 전체 파이프라인을 End-to-End로 (i) 학습시키는 General Multimodal Agent에 해당한다.
3. Methodologies
3.1. GPT-assisted Visual Instruction Data Generation
COCO 혹은 LAION 과 같이, Multi-modal image-text pair dataset은 그 수가 충분하지만, Multi-modal "Instruction-Following" Dataset은 생성 과정에 시간과 인력이 많이 요구되기에, LLaVA 논문이 출시되는 시점에 (23.04) 제한적이었다.

이에, 저자들은 GPT-4를 활용하여 widly existing image-text pair dataset을 기반으로, Multi-Modal Instruction Folloiwng data를 생성하였다.
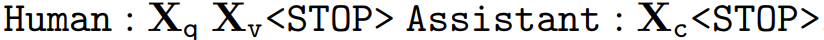
Image 와 associated Caption 에 대해서, Instruction Following Version으로의 Simple Expansion은 위와 같이, "Describe the image Concisely"라는 을 기존 Image-Text Pair Dataset에 추가하는 방식이다.
이 때 는 다음 목록으로부터 무작위로 추출될 수 있다.

이 경우, Public Image-Caption pair dataset으로부터 Instruction Following Version을 손 쉽게 구축할 수 있지만, 정해진 Instruction과 Caption 으로 인해, In-Depth Reasoning과 Diversity가 부족하다.
이에 저자들은, Image-Caption Pair Dataset으로부터 복잡한 Instriction Following Dataset을 구축하고자, Text-Only GPT-4를 활용하였다.
이떄, Text-Only GPT-4 모델에 Visual Image를 Input으로 넣어주고자 두 종류의 Symbolic Representation을 활용하였다.

(i) Visual Scene을 Various Perspective로부터 묘사하는 Detailed Caption
→ Enhanced from the original COCO caption
(ii) Visual Scene 안의 객체들을 Localize 하는 Bounding Boxes
→ COCO 등의 데이터셋으로부터 가져온 Bounding Box를 Text Format으로 변환
이를 통해, Image와 Query를 LLM이 모두 Text 형태로서 이해할 수 있게 되었기에, LLM을 통해 Language Instruction Following Dataset을 생성하게 된다.
또한, 생성된 Langauge Instruction Following Dataset에서 Text 형태의 Symbolic Representation을 다시 Visual Image로 대체함으로써, Multi-Modal Instruction Folloiwng Dataset을 구축하게 된다.
이때 생성되는 Dataset은 다시 3가지 카테고리로 구분되어, Multi-Modal Model의 Zero / Few Shot Capability를 증진하는데 활용된다.

(i) Conversation
Visual Scene 상에서의 '객체 수', '객체 타입', '객체 행동', '객체 위치', '객체 간의 상대적 위치' 등 명확한 답변이 있는 질문들만을 기반으로, 대화 기반의 Instruction Following Dataset을 구축하였다.
(ii) Detailed description
앞선 Symbolic Representation을 기반으로, LLM을 통해 최대한 자세하게 Description Answer를 생성하였고, 상응하는 Query를 앞선 Query List로부터 Random Sampling하였다.
(iii) Complex reasoning
Conversation과 Description을 기반으로, Rigorous Logic에 기반한 Step-by-step in-depth reasnoning을 수행하는 Text Response 또한 생성하였다.
이 때, Query와 Symbolic Representation을 기반으로 GPT-4를 통해 3가지 경우에 대해 (Converstaion, description, reasoning) 응답을 생성하기에 앞서, 몇가지 모범 답안을 Manually design한 이후, GPT-4의 In-context-learning을 위한 Seed Examples로 활용하였다.

전체 데이터 생성 과정에서 해당 Context-Design이 유일한 Human annotation에 해당하기에, 적은 시간과 인력을 기반으로 158K unique language-image instruction following sample을 생성할 수 있었다. 세부적으로는 58k Conversations, 23K Detailed Description, 77K Complex Reasoning으로 구성된다.
3.2. Visual Instruction Tuning
3.2.1. LLaVA Architecture
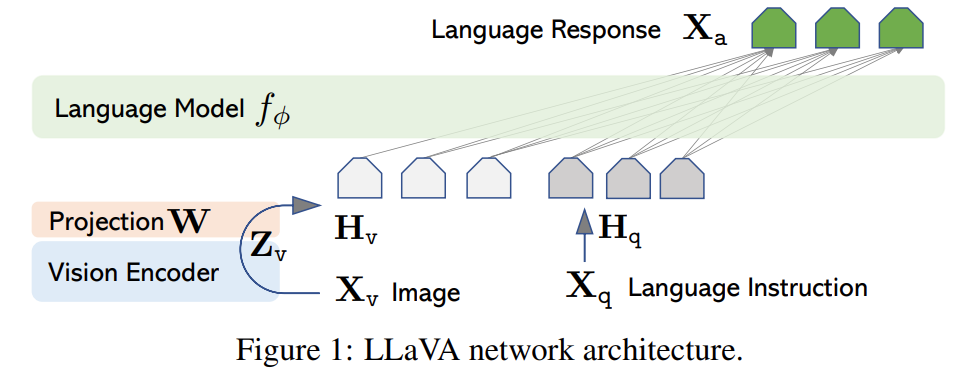
23.04 기준 Publicly available checkpoints 중 Instructiton Following Capability가 가장 좋은 "Vicuna"를 Language Model 로 활용하였다. ϕ는 LLM parameter를 의미한다.
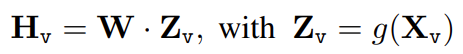
Input Image 를 Image Feature 로 Embedding함에 있어, Vision Encoder 로서 CLIP Vision Encoder "ViT-L/14"를 활용하였다. 이떄 ViT의 마지막 Transformer Layer의전후 Grid Feature가 Image Feature 로 활둉되었다.
이후 Image Feature 를 Word Embedding Space로 변환하는 과정에서 Simple Linenar Layer (Matrix) 를 활용하였다. Trainable projection matrix 를 통해 Image Embedding 을 Language Embedding token 로 변환함으로써, Vicuna Language decoder에서의 word Embedding과 차원을 맞춰주었다. .
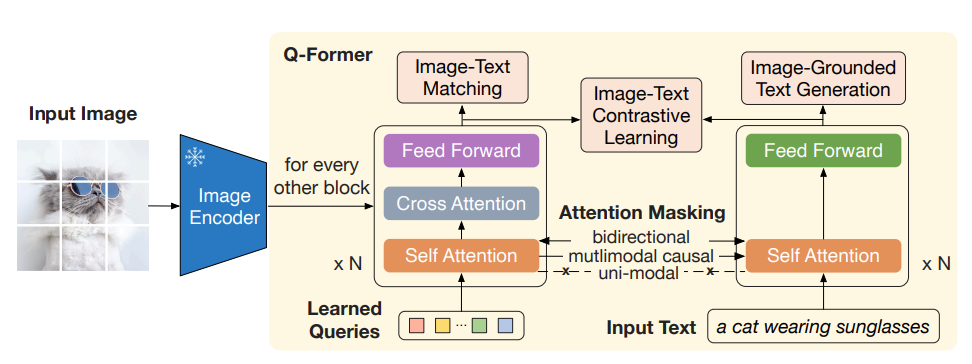
- 이후 리뷰할 LLaVA 1.5에서는 Linear Projection Matrix 를 Two linear layer와 Single non-linear layer 로 구성된 MLP Connector로 확장하였고, BLIP2에서는 Vision-Language Connector로서 Q-Former를 활용하기도 하였다. Vision과 Language 두 Modality를 간단한 Projection Matrix만으로 연결할 수 있음을 보여준 좋은 예시인 것 같다.
더욱 정교한 방식으로 visual embedding과 language embedding을 연결하는 접근법으로는 Flamingo의 gated-cross-attention과 BLIP-2의 Q-former 등이 있다.
3.2.2. Training
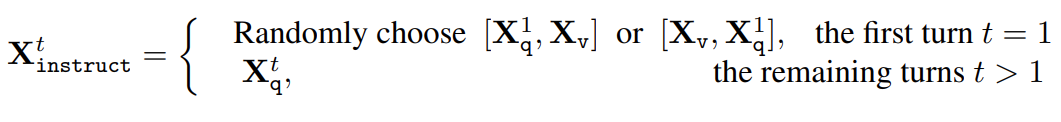
각 Input Image 에 대해서 GPT-4를 통해 multi-turn conversation data ((), (), ())를 생성한 이후, 앞서 살펴본 LLaVA 아키텍처의 학습을 위해, 위 이미지와 같이 Input Image와 (Original Image로서 Symbolic Representation이 아님) 를 다시 결합함으로써, Visual Instruction을 완성하게 된다. 여기서 T는 multi-turn conversation의 toal number of turns를 나타낸다.

위 사진과 같이, 앞서 생성한 각 시점에서의 Instruction을 GPT-4를 통해 생성해두었던 Answer와 다시 결합함으로써, Instruction Following Dataset이 완성되기에,
이를 기반으로 LLaVA Architecture에 대한 Instruction Tuning을 진행하게 되고,
이 때, LLM의 학습과 같이 Auto-Regressive-Training-Objective 를 활용하게 된다.
즉, GPT-4를 통해 Knowledge-Distillation의 방식으로 생성된 정답 Response를 기반으로, Sequence 길이 의 Generated Response의 Probability를 계산한다.
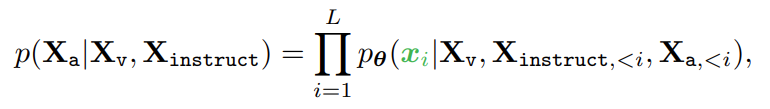
여기서 는 전체 LLaVA 아키텍처의 Trainable Parameter (CLIP Vision Encoder ViT, Vicuna Text Decoder, Linear Projection Matrix ) 에 해당하며, 와 는 Current Prediction Token 이전의 모든 Conversation Turn에서의 Instruction과 Answer 토큰에 해당한다.
위 Auto-Regressive Objective에 기반한 LLaVA 아키텍처의 Instruction-Tuning은 두 단계로 구성된다.
Stage 1: Pre-Training for Feature Alignment
첫 번째 단계는, Visual Embedding과 Language Embedding 간에 Feature Alignment를 진행하기 위한 Pre-Training 단계이며, 이를 위해 CC 3M Dataset으로부터 595K Image-Caption Pairs를 추출하였다.
이 때, Training efficiency와 Concept Coverage 간의 균형을 위해, 각 단어의 Frequency를 기반으로 LLaVA 모델의 지식 학습에 기여할 수 있는 Pairs를 우선적으로 추출하였다.
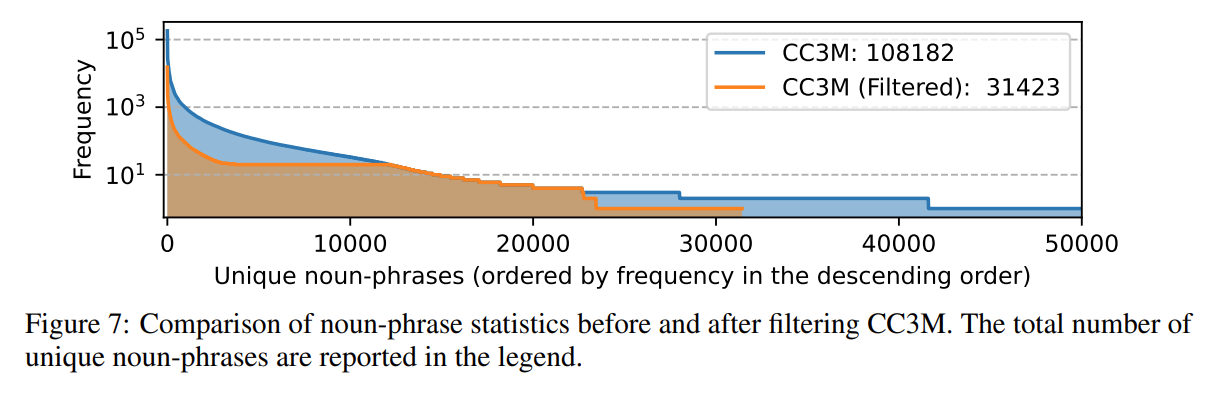
이에 위 이미지와 같이, 3M Original Dataset에 비해 적은 595K Filtered Dataset만으로도 비슷한 Concept Coverage를 달성하였음을 이야기한다.
해당 Filtered 595K Dataset은 앞서 살펴본 Instruction Following Dataset으로의 Simple Expanstion을 거쳐, Feature-Alignment Pre-Training에 활용되었다.
은 역시, 앞서 살펴본 Query List로부터 Random Sampling되었으며, ground truth 는 original CC3M caption에 해당한다.
위의 Simple expansion을 거친 Instruction Following Dataset에 기반하여 Feature Alignment를 위한 Pre-Training을 진행함에 있어,
CLIP ViT Visual Encoder와 Vicuna Language Decoder의 Weight는 고정하고,
Image → Text Projection Matrix 만을 Trainable Parameter 로 설정하였다.
이후, 앞서 살펴본 Objective의 Likelihood를 Maximize하는 방식으로, LLaVA 아키텍처를 Pre-Training 함으로써, Visual, Language Modality 간의 Alignment를 이루고자 하였다.
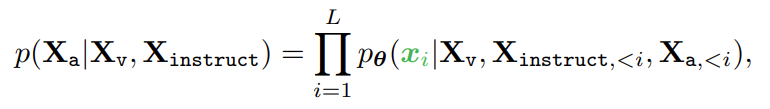
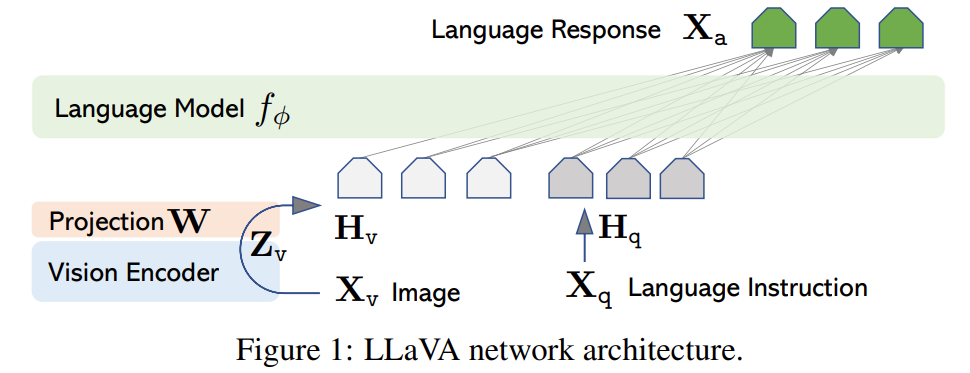
해당 방식으로, Image Feature 와 Word (Query) Embedding ,간에 Alignment를 이룸으로써, 이후 Fine Tuning 혹은 Inference 과정에서 LLM Decoder가 Multi-modal Embedding을 이해할 수 있게 되었음을 이야기한다.
** LLaVA 1.5, NVILA, BLIP2 등의 연구에서는 MLP connector 혹은 Cross-Attention 기반의 Q-Former를 활용함으로써, Vision과 Text 두 Modality 간의 더욱 정교한 Alignment를 달성하고자 하였다.
This stage can be understood as training a compatible visual tokenizer for the frozen LLM
Stage 2: Fine-Tuning End-to-End
3.1 절에서 살펴본 Multi-modal Instruction Following Dataset으로 전체 LLaVA를 Instruction Tuning함에 있어, CLIP Visual Encoder ViT의 가중치는 항상 고정하였고, Linear projection layer 와 Vicuna LLM decoder의 가중치만을 학습하였다.
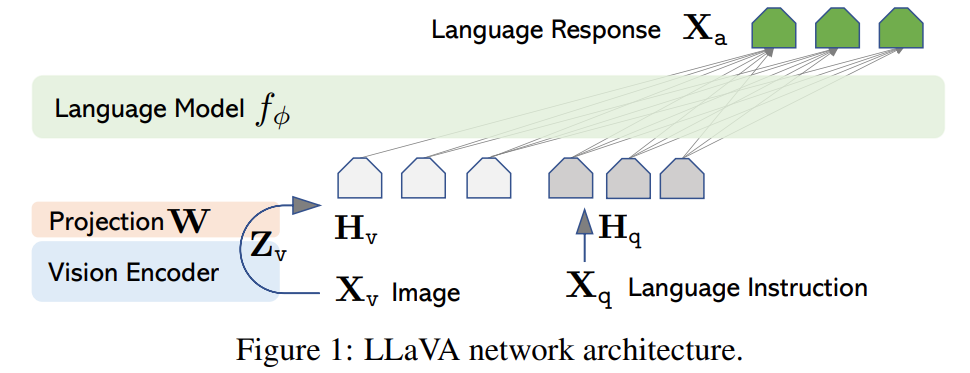
i.e., the trainable parameters are
이에 Multi-Modal Instruction Tuning을 거친 LLaVA 아키텍처가
- Multi-turn Conversation Format (Multimodal Chatbot)
- Complex Reasoning Format (Science QA)
등의 Multi-modal Instruction을 적절히 이행하는 것을 목표로 Fine-Tuning을 진행하였다.
4. Experiments
We train all models with 8× A100s, following Vicuna’s hyperparameters.
We pre-train our model on the filtered CC-595K subset for 1 epoch with a learning rate of 2e-3 and a batch size of 128, (Projection Layer Alignment)
and fine-tune on the proposed LLaVA-Instruct-158K dataset for 3 epochs, with a learning rate of 2e-5 and a batch size of 32. (Projection Layer , Decoder LLM)
4.1. Multimodal Chatbot

BLIP2, OpenFlamingo, GPT4 등의 기존 VLM보다 더욱 정교한 Visual Instruction Following을 수행함을 보여준다. 허나, 더욱 정확한 결과 비교를 위해서는, 직접 Zero / Few Shot 으로 Inference를 진행해봐야 할 것 같다.
Indoor, Outdoor Scenes, Memes, Paintings, Sketches 등의 Diverse set of 24 Images with 60 detailed questions로 구성된 "LLaVA-Bench (In-the-wild)" 벤치마크를 자체적으로 제작하여, OpenFlamingo, BLIP-2 와 성능 비교를 수행한 결과는 다음과 같다.

4.2. ScienceQA dataset
ScienceQA contains 21k multimodal multiple choice questions with rich domain diversity across 3 subjects, 26 topics, 127 categories, and 379 skills.
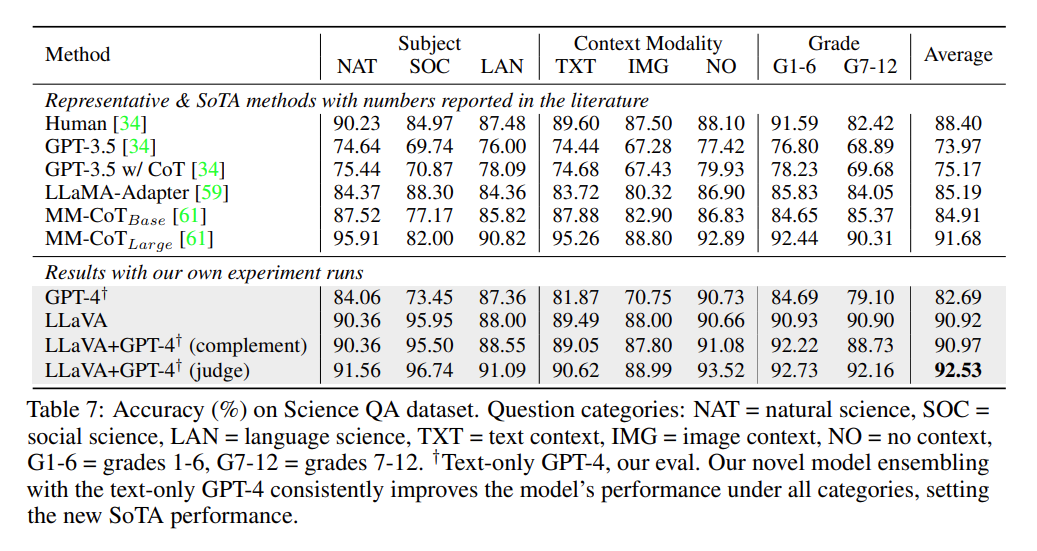
Science QA 벤치마크에 대해 LLaVA가 좋은 Reasoning Capability를 보여줌을 확인할 수 있고, Text Only GPT-4를 기반으로 Model Ensembling을 적용하였을 때, 더욱 향상된 Reasoning Capability를 달성함을 보여준다.
4.3. Ablations
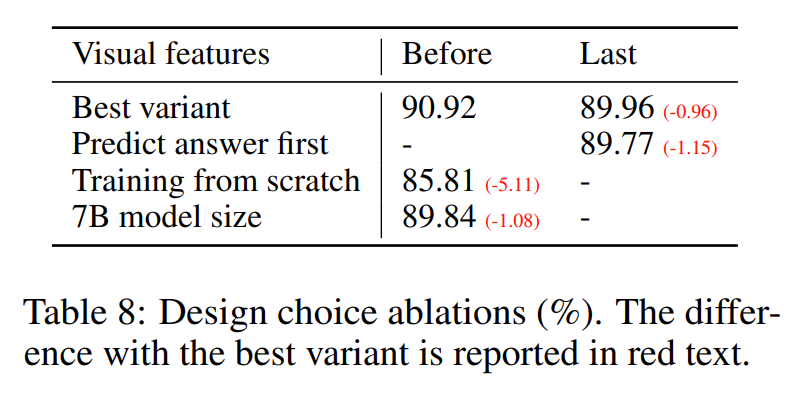
1. CLIP Image Encoder의 Last layer Feature의 경우, 더욱 Global하고 Abstract 한 Feature에 집중하다보니, Image의 Specific detail을 이해할 수 있는 Localized property에 더욱 집중하는 before the last layer보다 Multi-modal Instruction following capability가 떨어질 수 있다고 설명한다.
→ Further Scaling Input Image Resolution in LLaVA-1.5.
- Chain-Of-Thought
CoT-like-reasoning-first strategy가 더욱 원활한 Convergence로 이어졌지만, final perfomance에는 적은 영향을 미침을 확인하였다.
→ But, LLaVA CoT's Structured, Systematic Approach의 경우, CoT Reasoning을 통해 Adaptive한 성능 향상을 달상하였다.
- Pre-Training
Project Matrix 에 대한 Feature Alignment Pre-Training을 생략한 결과, 5.11%의 Accuracy drop이 나타났고, 이를 통해 두 Modality 간의 Feature Alignment의 중요성을 확인할 수 있다.
→ Further Scaling Vision-Text connector in LLaVA-1.5 (MLP)
- Model Size
Vicuna 7B Model을 활용하였을 때, Original 13B model에 비해 1.08%의 Accuracy drop이 나타났고, 이를 통해 Model Scale의 중요성을 확인할 수 있다.
→ Further Scaling model size in LLaVA-1.5
5. Limitations
-
Lack of large knowledge coverage (Weak in Information Retrieval)
→ ‘Scaling the model size’ in LLaVA-1.5 -
Lack of processing high resolution images
→ ‘Scaling input Resolution’ in LLaVA-1.5 -
LLaVA perceives the image as a “bag of patches”, failing to grasp the complex semantics within the image.
(ex. it responds with yes when asked if strawberry-flavored yogurt is present, even though the fridge contains only yogurt and strawberries)
→ ‘Scaling input Resolution’ in LLaVA-1.5
As LLaVA is built upon LLaMA, Vicuna, and CLIP,
it inherits some of the issues associated with LLMs and vision encoders.
- Hallucination (that aren’t grounded in facts or input data)
→ ‘Scaling the model size while balancing with Dataset scaling’
→ ‘Scaling Input Resolution’ in LLaVA-1.5
→ ‘Enhancing Logical Reasoning Capability’ in LLaVA-CoT - Biases
→ ‘Enhancing Logical Reasoning Capability’ in LLaVA-CoT
6. Interesting Findings
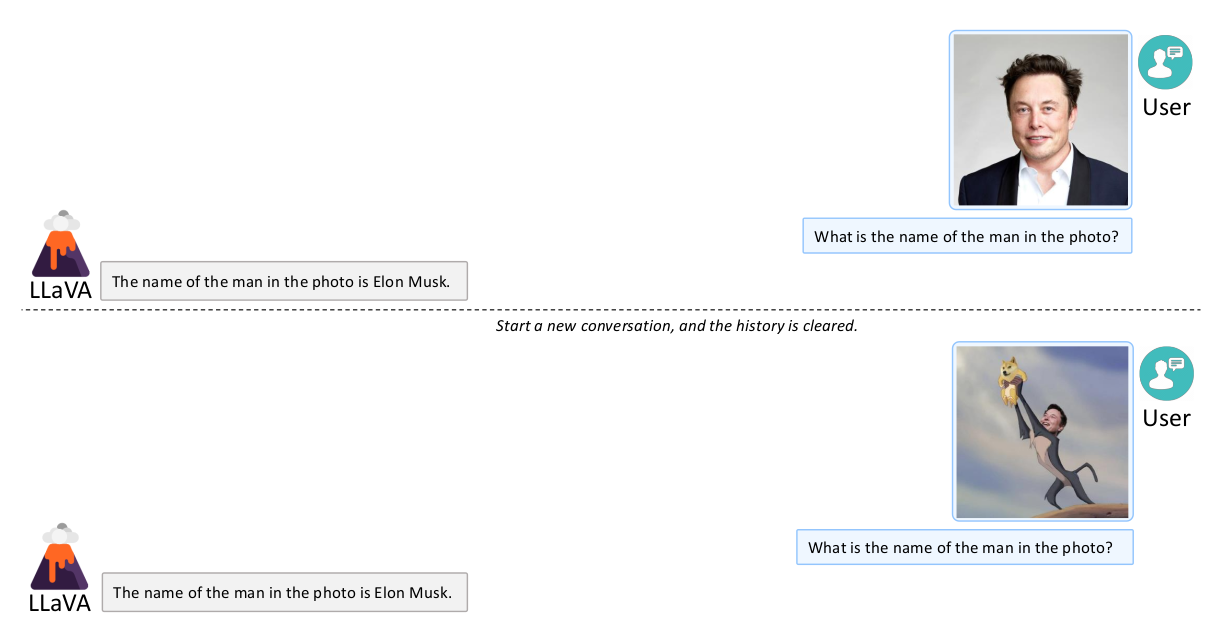

- LLaVA is able to understand visual contents that are not covered in the training.
- LLaVA also demonstrates impressive OCR (optical character recognition) ability which is rarely covered in our training data.
→ CLIP, Vicuna ‘s Pre-trained knowledge utilization.
→ May be Further Utilized by scaling the model size and dataset (LLaVA-1.5)
7. Conclusion
LLaVA-1.5, LLAVA-CoT, VILA, NVILA 등 Opensource VLM 들의 발전을 위한 초석을 이루고 있는 LLaVA는 다음과 같은 Contribution을 지닌다.
Open Source "Large Multimodal Model (LMM)"
LLaVA Source: https://llava-vl.github.io/
LLaVA는 Open Source Model만을 활용하여 파이프라인을 구축한 이후, LLaVA 모델 또한 Open source로 공개하였다.
Visual Input을 받기 위해 CLIP의 ViT (Vision Transformer) Image Encoder를 활용하였고, Image Embedding과 Query Embedding을 기반으로 Output Text Token을 생성하고자 Vicuna Language Decoder를 활용하였다.
또한 같은 차원의 벡터일지라도, 내포된 의미가 다른 Visual Embedding과 Text Embedding 간의 Alignment를 이루고자, Single Linear Layer로 구성된 Linear Projecetion Matrix 를 활용하였다.
"Multi-Modal Instruction-Following-Data"
Instruction Tuning을 Multi-Modal 분야에 성공적으로 적용한 것은, LLaVA 연구가 처음이었기에, 해당 저자들은 ChatGPT/GPT-4 등의 Text Only Model을 활용하여, Multi-modal Instruction Following Data를 생성하고자 하였고, 이에 기존 "Image-Caption" Pair를 적절한 "Instruction Following Format"으로 변환하는 효과적인 파이프라인을 제시하였다.
