논문 리뷰
1.[논문 리뷰] LLaVA: Visual Instruction Tuning

LLaVA: Visual-Instruction-Tuning
2025년 1월 28일
2.[논문 리뷰] LLaVA-1.5: Improved Baselines with Visual Instruction Tuning

[논문 리뷰] LLaVA-1.5: Improved Baselines with Visual Instruction Tuning
2025년 1월 30일
3.[논문 리뷰] LLaVA-CoT: Let Vision Language Models Reason Step-by-Step

[논문 리뷰] LLaVA-CoT: Let Vision Language Models Reason Step-by-Step
2025년 1월 31일
4.[논문 리뷰] VILA: On Pre-training for Visual Language Models
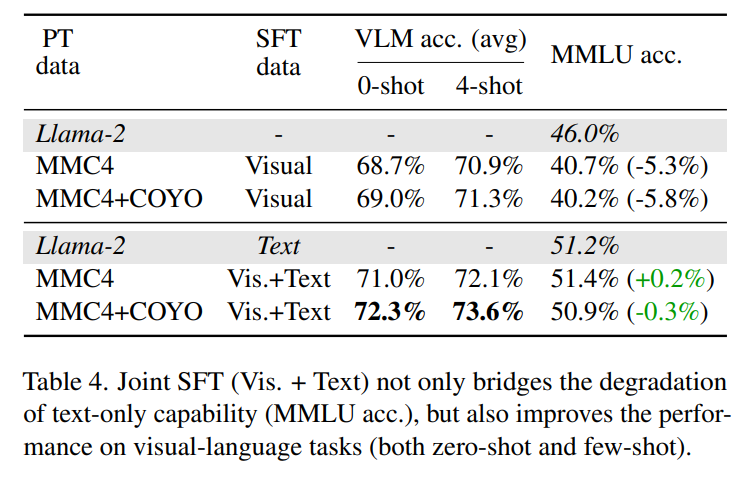
[논문 리뷰] VILA: On Pre-training for Visual Language Models
2025년 2월 2일
5.[논문 리뷰] NVILA: Efficient Frontier Visual Language Models

[논문 리뷰] NVILA: Efficient Frontier Visual Language Models
2025년 1월 7일
6.[논문 리뷰] MUIRBENCH: A Comprehensive Benchmark for Robust Multi-image Understanding

[논문 리뷰] MUIRBENCH: A Comprehensive Benchmark for Robust Multi-image Understanding
2025년 2월 11일
7.[논문 리뷰] DriveLM: Driving with Graph Visual Question Answering
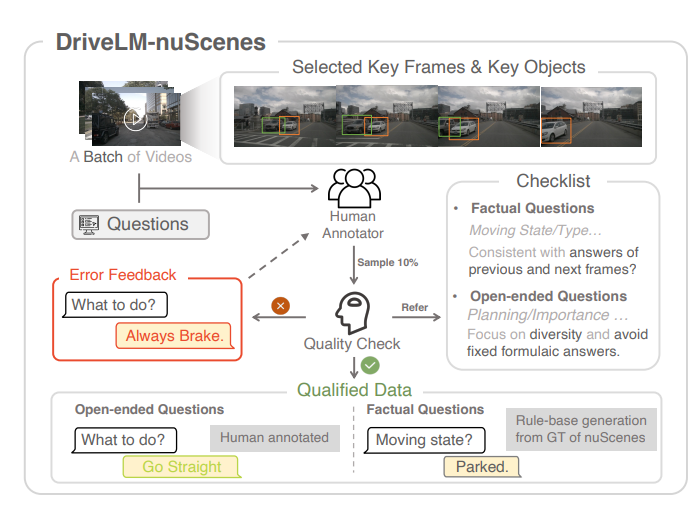
[논문 리뷰] DriveLM: Driving with Graph Visual Question Answering
2025년 2월 19일
8.[논문 리뷰] Sparse4D 시리즈
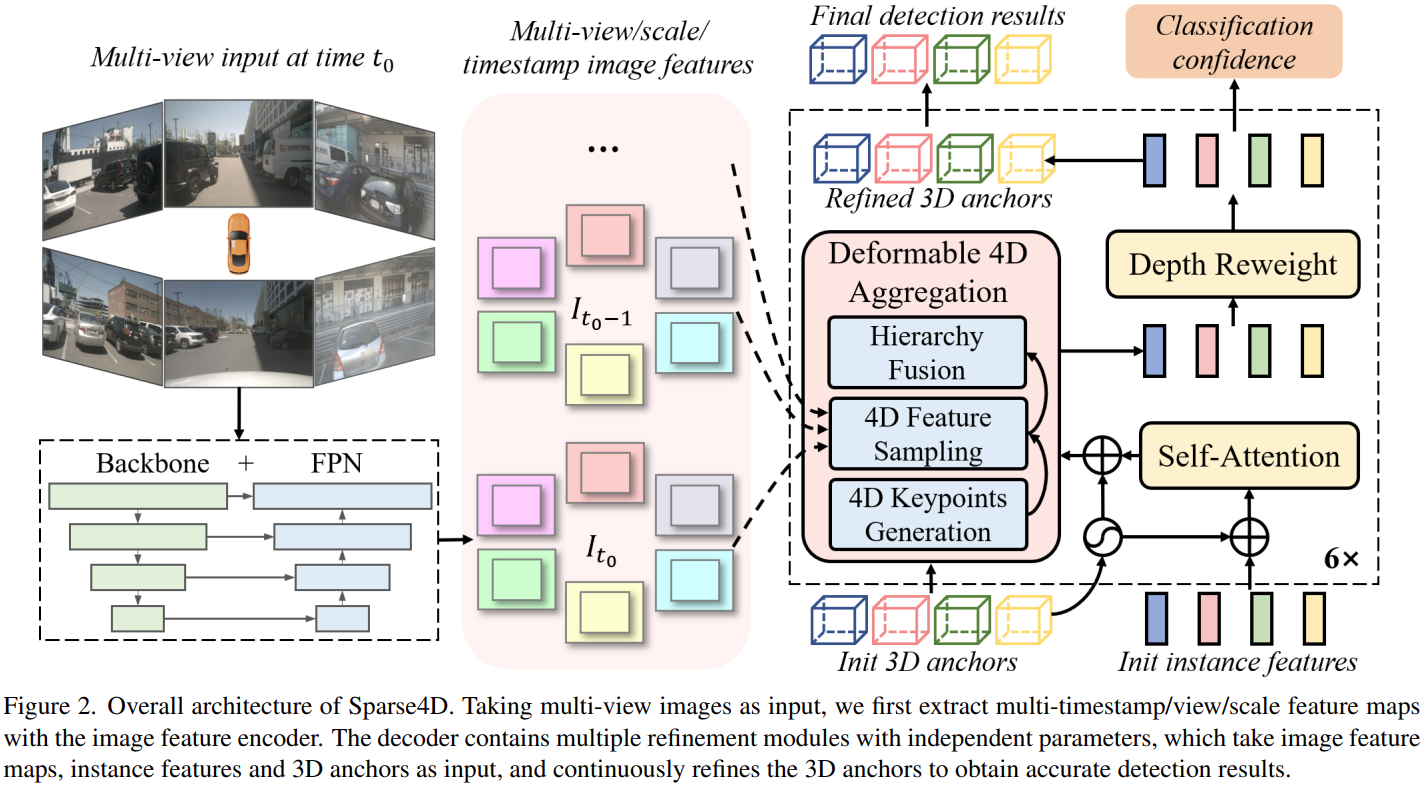
[논문 리뷰] Sparse4D 시리즈
2025년 3월 10일