🏃♂️ 넘블 챌린지 참가
우연히 '나만의 지역 기반 커뮤니티 서비스 만들기'의 챌린지를 진행하고 있는 광고를 보았다. 기본 와이어프레임을 제공해주고 돈을 내면 자신의 수준에 맞는 프론트엔드, 디자이너, 백엔드 팀원들을 빌딩해주며 6주 동안 배포까지 프로젝트를 진행하는 챌린지였다. 프로젝트 경험이 필요했던 나에게는 너무나 매력적인 챌린지였고 고민없이 참가하였다. 하지만 당시에는 생각못한 나는 3학년 2학기를 다니고 있었고 21학점 7전공을 수강 중 이었다. 또 졸업 필수 요건인 '코딩부트캠프'를 수료하기 위해선 코딩테스트 연습도 꾸준히 해야했고 또 다른 졸업 필수 요건인 '인턴'을 하기 위해 학기 중에 꾸준히 이력서, 포트폴리오, 자기소개서를 써야했다. 교수님들은 이를 당연히 아실리가 없고 미친듯이 과제를 내주셨고 나는 이미 진행 중인 프로젝트가 있었다. 정리하자면, 6주 사이에
- 코딩부트캠프 (필수졸업요건) - 코딩테스트 연습 필수
- 인턴 (필수졸업요건) - 이력서, 포트폴리오, 자기소개서 작성 필수
- 21학점 7전공 - 미친 과제량
- 진행중인 다른 프로젝트 - 12월 베타서비스 배포 예정
- 3학년 2학기 중간고사
- 넘블 프로젝트,,,
이 모든 것을 다 했어야했고 너무나 힘든 6주였다. 다른 분들도 돈을 지불하고 챌린지에 참여하는 것이기에 부담감이 너무 컸다. API를 제시간에 못만들어드리고 오류투성이였지만 다행히 다들 너무 친절하셔서 뭐라고는 안하셨다. 어쨌든 이렇게 나는 넘블 챌린지에 참여하였다.
🤔 주제 선정

넘블 측에서 기본 와이어프레임을 제공했지만 세부 주제는 우리가 짜야한다. 그래서 처음 1주간은 주제 회의를 하였고 프론트엔드 호민님이 생각하신 '이웃 공동 구매 서비스'로 결정했다. 나처럼 자취하는 1인 가구를 타겟으로 한 서비스인데 혼자 배달시켜 먹기엔 배달비도 너무 비싸고 요리를 하자니 초기 재료 양과 비용이 너무 많고 비싸서 요리를 하기 쉽지 않다. 이런 사람들을 위한 비슷한 지역의 마트를 선정해 함께 쇼핑을 하고 재료를 소분하는 '소분소분' 서비스를 기획했다.

주제를 선정했다고 끝이 아니라 기획 구체화를 위해 위 사진에 보이는 것처럼 아이디어 구체화, 플로우 차트, 서비스 이름, 비즈니스 모델 구축, 타 서비스 차별점, 한계점 및 기대효과 등을 회의했는데 한번의 회의로는 부족해서 2번 나눠서 했다. 그럼에도 회의 시간이 기본 2시간씩 넘어가서 너무 힘들었던 기억밖에 없다 ㅠ
📊 DB 설계 및 서버 배포

그 다음 백엔드 파트는 바로 DB 설계 작업부터 들어갔다. 물론 처음부터 MySQL Workbench에서 ERD 형식으로 짜는 방법도 있었지만 백엔드 회의 결과 아직 정확한 화면 view도 안나왔고 기능도 변동 가능성이 컸기에 대략적으로만 1차 DB를 설계하고 Agile하게 수정하기로 했다.

그 다음 서버를 배포했다. 아무래도 프론트분들이 백엔드 환경 설정을 하고 로컬에서 테스트하기도 번거롭고 배포까지가 최종 목표이니 처음부터 배포를 하기로 결정했다. 이번이 2번째 배포이지만 AWS를 만질 때는 항상 겁나고 귀찮고 어렵다.. 잘못 설정하면 엄청난 돈이 나가고 AWS는 불친절하다는 느낌을 많이 받기 때문이다. Github 백엔드 레포의 main 브랜치를 Github Action을 통해 AWS의 Code Deploy하는 형식인데 여기서 항상 문제는 gitignore된 파일이다. s3, mysql 같은 개인정보를 포함하고 있는 properties 파일은 gitignore 설정을 해주는데 이는 GitHub에 안올라가기 때문에 서버에도 안올라간다는 점이다. 이게 귀찮다고 저번에 안해줬다가 목업 데이터를 해킹당한 경험이 있어서 그 이후로는 무조건 gitignore 처리를 해준다. 간혹 gitignore 처리를 해줘도 push하면 GitHub에 올라가는 경우도 있는데 이럴 땐
git rm -r --cached ~ [properties 파일 위치]를 해주면 캐시가 비워지고 gitignore가 잘 작동되는 걸 볼 수 있다. 그리고 이를 서버에 배포할 때는
nohup java -jar -Dspring.config.location=classpath:/,/home/ubuntu/app/src/main/resources/application-mysql.properties,/home/ubuntu/app/src/main/resources/application-s3.properties -Duser.timezone=Asia/Seoul $JAR_NAME >> $REPOSITORY/nohup.out 2>&1 &우선 application-s3.properties, application-mysql.properties 같은 민감한 파일들을 vim 명령어로 작성해주고 위의 코드를 입력하면 jar 실행 파일을 실행시킬 때 위의 경로에 찾아가 알아서 include 해준다고 한다. 이렇게 어찌저찌 서버 배포까지 끝이 났다.
🔨 API 구현

우선 백엔드는
- Spring Boot/ Java
- Gradle
- Spring Data JPA
- MySQL
- RDS, EC2, S3
등의 기술스택을 사용했고 REST API 적용했다. 프론트엔드 개발자분들과의 소통을 위해 API 문서는 노션에다 작성했다. Swagger라는 툴도 추천을 받았는데 이는 다음에 꼭 써봐야겠다.
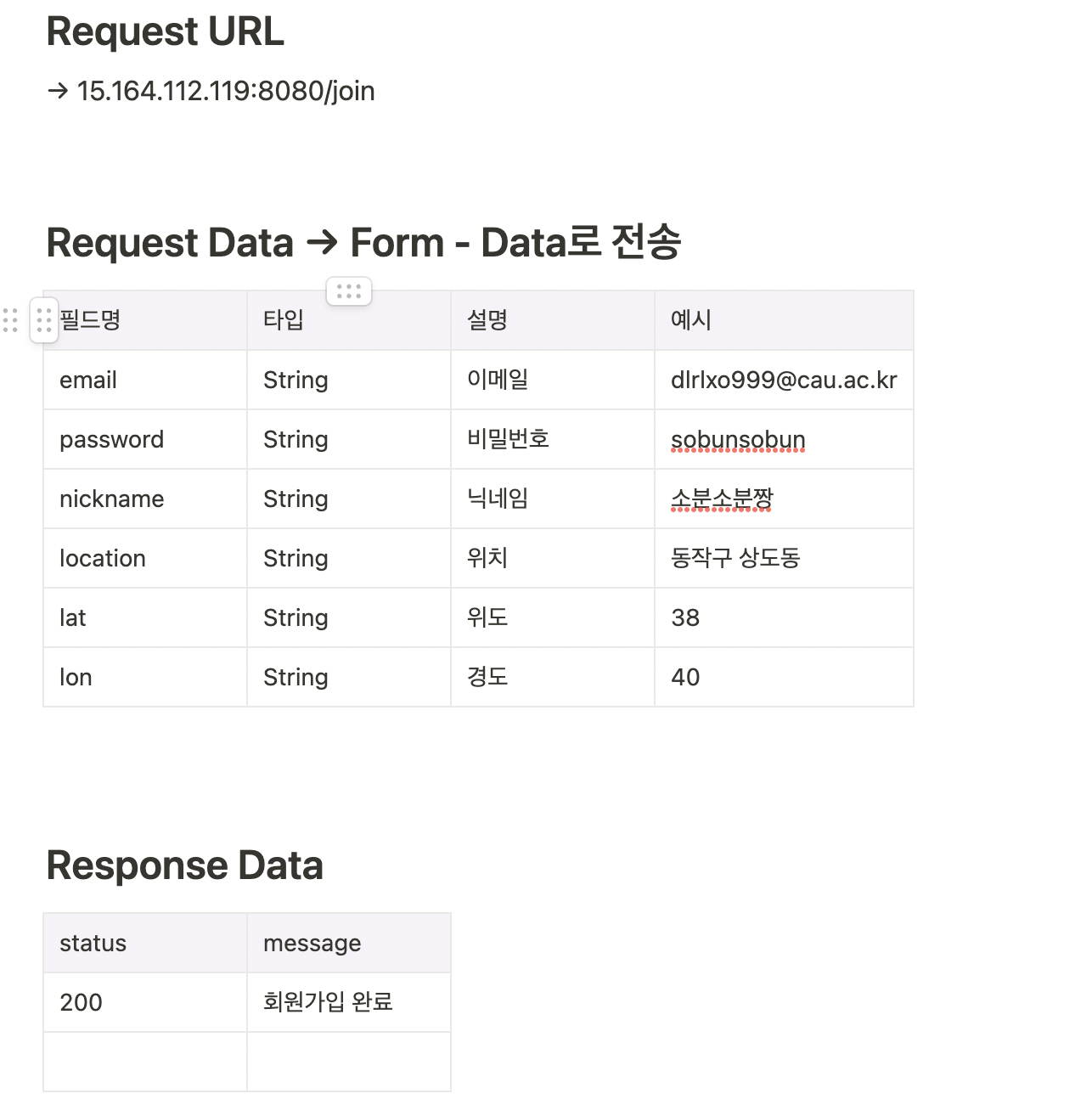
API 문서에는 Request URL, Request Data, Response Data 등 구체적으로 작성해 프론트-백엔드 소통에 어려움이 없게 했다. 위 사진에는 없지만 포스트맨 사진도 밑에 첨부해주며 프론트엔드 개발자분들이 조금 더 이해하기 쉽게 하기위해 노력했다. 약 25개의 API를 구현했는데 이를 3주 조금 넘는 시간에 다 구현했다. 어려운 API는 거의 없었으나 실력이 너무 부족해서 오래걸린 것 같다 ㅠ 이제부터는 내가 API를 구현하면서 어려웠던 점을 정리해보도록 하겠다.
😭 1. CORS 설정
우선 CORS 설정이다. 분명 API는 잘짠거 같은데 프론트에서 통신이 안된다고 한다. 프론트분께 여쭤보니

이렇게 에러가 뜨고 CORS 관련 오류인 것 같다라고 하셨다. CORS가 뭔지 몰랐고 그제서야 찾아봤다. CORS(Cross-Origin Resource Sharing)는 React와 Spring Boot가 서로 사용하는 포트(3000 <-> 8080)가 다르기에 CORS 세팅을 꼭 해줘야 데이터 교환이 가능하다는 것이다. 보통 백엔드단에서 세팅을 해주는게 편하고 많이들 한다기에 찾아보니 Controller마다 Cross Origin을 세팅해주는 방법보단 @EnableWebMvc 어노테이션을 사용해 WebConfigurer를 상속받아 CORS 응답을 한번에 처리하는 방법이 좋다고 한다.
@Configuration
@EnableWebMvc
public class WebMvcConfig implements WebMvcConfigurer {
@Override
public void addCorsMappings(CorsRegistry registry){
registry.addMapping("/**")
.allowedOriginPatterns("*")
.allowedHeaders("*")
.allowedOrigins("http://localhost:3000")
.allowCredentials(true)
.allowedMethods("OPTIONS", "GET", "POST", "PUT", "DELETE", "PATCH")
.maxAge(3000);
}
}이렇게 해줌으로써 CORS 설정을 완료하였다. 이때 *로 처리해주는 거는 그렇게 좋지 않은 방식이라고 하던데 꼭 더 공부해서 코드 리팩토링을 진행할 예정이다.
😭 2. Refresh Token
이번 로그인은 Spring Securityt + Jwt 방식으로 구현했다. 이때 백엔드단에서 로그인을 완료하면 Access Token을 반환하는데

초반에는 이 Access Token의 만료 시간이 30분이었다. 이 때문에 프론트 개발자분들이 통신 테스트를 하다 Access Token의 만료 시간이 지나 갑자기 403 Forbidden이 뜨는 경우가 허다했고 불편함을 호소하셨다. 이를 해결하기 위해 우선 Access Token의 만료기간을 20일로 대폭 늘렸는데 찾아보니 이는 좋지 않은 방식이라고 한다. Access Token은 그 자체로 User PK 등 인증 정보를 모두 가지고 있어서 탈취되면 매우 위험한 상황이 발생할 수 있다고 한다. 또 Access Token은 서버에 저장되지 않으므로(stateless) token이 탈취되면 서버에서는 막을 방법이 없어 보통 Access Token은 만료 기간을 짧게 설정하는 것이 좋다고 한다. 이를 해결하기 위해 보통 Refresh Token을 많이들 사용하는데 Refresh Token은 Access Token을 재발급받을 수 있는 token이다. 이 token은 서버에 저장되기 때문에(stateful) refresh token이 해커에 의해 탈취당했다고 판단되었을 때 서버에서 Refresh Token을 삭제함으로써 강제 로그아웃을 시킬 수 있다고 한다. 이렇게 Access Token과 Refresh Token을 둘 다 사용함으로써 보안과 비용을 지키는 방식을 사용해야 한다.
하지만 Refresh Token을 사용하기 위해선 Redis라는 저장소를 사용해야하고 AWS Redis 저장소를 사용하다가 돈을 날린 경험과 시간이 부족하다는 판단하에 이는 사용하지 않기로 결정했다 ㅠ 지금 우리 프로젝트는 Access Token만을 사용하고 있는 상황이다. 이도 나중에 꼭 해결해야할 문제이다.
😭 3. Pagination
이번 프로젝트를 진행하며 가장 어려웠던 부분이 페이징 처리였다. 프로젝트 특성 상 모든 게시물을 보여줘야했고 게시물의 양이 많아 지면 서버에서 보내야하는 데이터의 양도 많아지고 처리 시간에 있어 비효율적이게 됨을 깨달았다. 따라서 서버에서는 한 페이지에 사용자들이 보기 적당할 양의 데이터를 보내줘야함을 알았고 관련 페이징 기술을 배워야했다.
우선 위의 블로그를 작성하신 분 아니었으면 나는 아마 못했을 것이다.. 너무나 친절하게 작성해주셔서 덕분에 구현할 수 있었다(감사합니다). Spring Data JPA에서 제공하는 JpaRepository 인터페이스가 PagingAndSortingRepository를 확장하고 있기에 페이징 및 정렬을 간편하게 처리할 수 있음을 배웠고
Page<Post> findAllByCategoryAndLocationAndStatusAndIsFullOrderByCreatedTimeDesc(String category, String location, Integer status, Boolean isFull, Pageable pageable);이렇게 카테고리, 위치, 유저 상태, 게시물 마감상태에 따라 파싱하고 이를 시간 순서대로 정렬함으로써 구현할 수 있었다.
{
"content": [
{
"title": "amo",
"category": "DELIVERY",
"deadline": 1663243762507,
"numberPeople": 9,
"currentNumberPeople": 4,
"viewCount": 65,
"nickname": "123",
},
{
"title": "dpu",
"category": "EXHIBITION",
"deadline": 1660593585499,
"numberPeople": 4,
"currentNumberPeople": 3,
"viewCount": 40,
"nickname": "123",
},
...
],
"pageable": {
"sort": {
"empty": true,
"sorted": false,
"unsorted": true
},
"offset": 0,
"pageNumber": 0,
"pageSize": 5,
"paged": true,
"unpaged": false
},
"last": false,
"totalElements": 99,
"totalPages": 20,
"size": 5,
"number": 0,
"sort": {
"empty": true,
"sorted": false,
"unsorted": true
},
"first": true,
"numberOfElements": 99,
"empty": false
}Pageable를 사용하면 이렇게 나오는데 (우리 프로젝트 자료 아님!!, 위에 블로그 분꺼 가져온 것!) 여기서 content는 뽑고자 하는 객체 내용, pageable은 총 데이터 갯수, 이게 마지막 페이지인지 등 페이징 처리에 필요한 내용을 담고 있다. 나는 호민님과 회의 끝에 Post 객체 + 해당 페이지가 마지막 페이지인지 아닌지 알려주는 isLast(boolean) 값만 넘겨주기로 결정했다. 이 API를 공부하고 구현하는데만 거의 일주일이 걸렸던 것 같다. 이렇게 어려웠지만 겨우겨우 페이징 API를 구현할 수 있었다.
🥇 배포 결과물 (1등)
짧은 시간에 많은 양의 API를 만들어내고 평소 몰랐던 개념을 배울 수 있어 나 자신이 성장할 수 있어서 너무 좋은 기회였다. 좋은 분들과 프로젝트를 함께 할 수 있어서 너무 행복했고 API 진행상황이 느려 프론트엔드 개발자분들에게 민폐를 끼친점이 너무나 죄송한 프로젝트였다.
🤔 찐 회고
사실 작년 11월~12월에 수행했던 프로젝트를 지금에서야 회고록을 쓰는 이유 (사실 예전에 써놓은거 + 지금 내용 덧붙이기)는 지금 쓸 내용 때문이다. 우리팀은 1등을 한 보상으로 현직자분들의 피드백을 받았는데 난 그 당시 잘 와닿지도 않고 중요시하지 않았다. 지금에서야 너무나 소중한 피드백임을 깨닫고 하나하나 분석해보려 한다!

아쉬웠던 점을 위주로 봐보자
- 테스트코드가 작성되어있지 않습니다.
맞다.. 테스트코드가 하나도 없었다. 부끄러운 얘기지만 저 당시까지만 해도 테스트코드의 중요성을 몰랐다. 하지만 인턴생활을 하고 있는 요즘, 테스트코드가 얼마나 중요한지 몸소 깨닫고 있고 지금 진행 중인 프로젝트에도 어떻게든 테스트코드를 넣으려한다. 테스트코드 그 자체가 문서가 될 수도 있기 때문에 TDD 개발 방식을 생활화해야한다!
- 에러가 제대로 catch, handle 되지 않은 부분이 있습니다. (뒷내용 생략)
- Nullish, Optional 값이 코드베이스에 전파되고 있습니다.
맞다... 이 내용은 정말 내가 부족했던 것인데, 나는 내가 세팅해놓은 DB에서 테스트해보고 '아 문제가 없네' 라 생각하고 예외처리를 생각을 안해줬었다. 아니 몰랐었다. 하지만 이때 이후 공부를 하면서 예외처리가 얼마나 중요한지 배웠고 정말 절대 틀리지 않을 것 같은 parameter, pathvariable 등 모든 예외처리를 해줘야함을 배웠다. 여기서 말하는 예외처리 말고도 '아 클라이언트가 값을 틀리게 보낼 일이 없겠지' 하고 안일하게 생각했던 나를 반성한다 ㅠ 백엔드 단에서는 모든 경우의 수를 생각해 예외처리를 해야 서비스가 안전하다! 꼭 명심하자
- 테이블 구조에 아쉬움이 있습니다. (댓글 관련)
댓글 관련 테이블은 DB를 설계할 때 부터 불안했다. 그 당시 우리팀은 댓글의 대댓글까지만 허용하기로 했고 더 깊은 대댓글은 생각을 안하기로 했었다. 시간도 부족했고 그냥 우리가 생각한 대로만 굴러가는 DB를 설계했었다. 개발의 확장성을 생각했으면 절대 나와서는 안되는 선택이었다.
