
길을 걷다보면 흔히 고양이를 마주치는데, 문득 이 친구들이 무슨 품종일까 궁금해졌습니다.
그래서 반려동물 품종 분류를 위한 기초 모델을 개발해보고자 생각했습니다. 향후 감정 인식 및 행동 분석으로의 확장 가능성을 염두해 두고, 실제 데이터 수집부터 학습까지의 전체 프로세스 경험을 해보고자 주제를 선정했습니다.
1. 데이터셋 및 전처리
먼저 고양이 품종이 얼마나 많은지 확인하기 위해 검색을 진행했습니다.
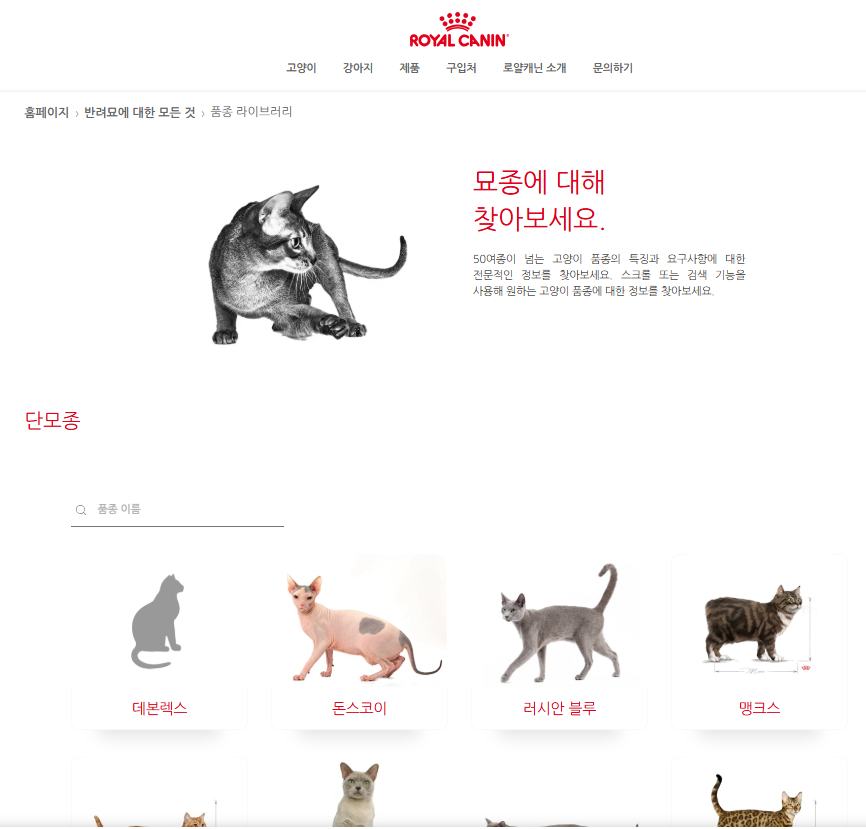
로얄 캐닌이라는 사료 회사에서 정의한 58개의 품종을 텍스트로 변환하여 웹 스크래핑을 통해 이미지 데이터셋을 수집하는 방향으로 구상했습니다.
1.1 웹 스크래핑
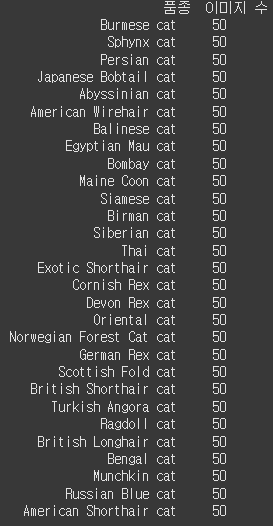
29가지 품종에 대해 50장씩 총 1450장을 수집.
1.2 데이터 분석

벌써부터 중복된 이미지 및 그림도 보입니다.
1.3 데이터 정제
하지만 58개의 클래스는 상당히 많고 품종중에 외견이 비슷한 품종도 있기 때문에 모델의 성능을 증가시키고 학습및 라벨링 시간을 단축하기 위해 품종의 수를 23개로 줄였습니다.
선정 기준은 다음과 같습니다.
1. 외형적 특징의 구분 가능성 (특징 추출이 쉬움)
2. 데이터 획득 용이성 (데이터 양과 관련) 비선호 품종의 경우 이미지 자체가 적기 때문
3. 유전적 근접성 (특징 추출이 쉬움)
주요 특징별 품종 그룹화
1. 동양계
- Siamese / Balinese / Thai
→ "Siamese Type" 으로 통합
2. 미국계
- American Shorthair / American Wirehair
→ "American Type" 로 통합
3. 영국계
- British Shorthair / British Shorthair
→ "British Type" 로 통합
4. Rex 그룹
- Devon Rex / Cornish Rex / German Rex
→ "Rex Type" 로 통합
나머지 품종은 독립 클래스로 유지할 뚜렷한 특징이 있어서 남겨두었습니다.
마지막으로 중복 이미지 / AI 생성 / 그림 이미지를 제거했습니다.
1.4 데이터 라벨링 및 증강
데이터 라벨링은 Roboflow에서 진행했고, 잘리는 부분이 없도록 객체를 최대한 포함하여 포괄적으로 라벨링 했습니다.
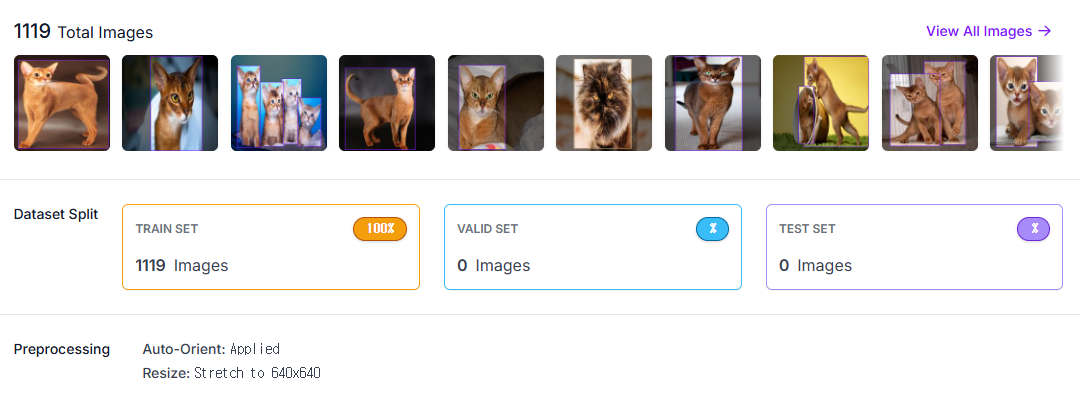
150장 정도 가량을 직접 라벨링 후 Roboflow의 AI assist 기능을 사용해서 자동으로 boxing 했습니다.

2. 모델 선정 및 이유
- YOLOv8에 비해 더 적은 컴퓨팅 자원을 소모함 (추후 엣지 디바이스 보드 활용 고려)
- YOLOv8에 비해 소형객체 탐지에 탁월함
- YOLOv8에 비해 작은 세부사항과 단서를 찾아내는데 유리(털 색상이나 패턴 분류에 강함)
- 혼잡한 상황에서 더욱 뛰어난 모습을 보임 (고양이는 빠르니까...)
아래 표는 상대적인 비교입니다
| 특성 | YOLOv8 | YOLOv11 |
|---|---|---|
| 객체 크기별 성능 | 대형 객체 감지 우수 | 소형 객체 감지 우수 |
| 처리 속도 | 실시간 처리 속도 빠름 | 상대적으로 느림 |
| 컴퓨팅 자원 | 많은 자원 필요 | 적은 자원으로도 운영 가능 |
| 패턴 인식 | 일반적인 성능 | 우수한 성능 |
3. 학습
- 객체를 최대로 포함하여 라벨링.
- train valid test 클래스 간 불균형.
- Roboflow에서 제공하는 데이터 증강 사용.
3.1 모델(YOLO11n, 512^2)
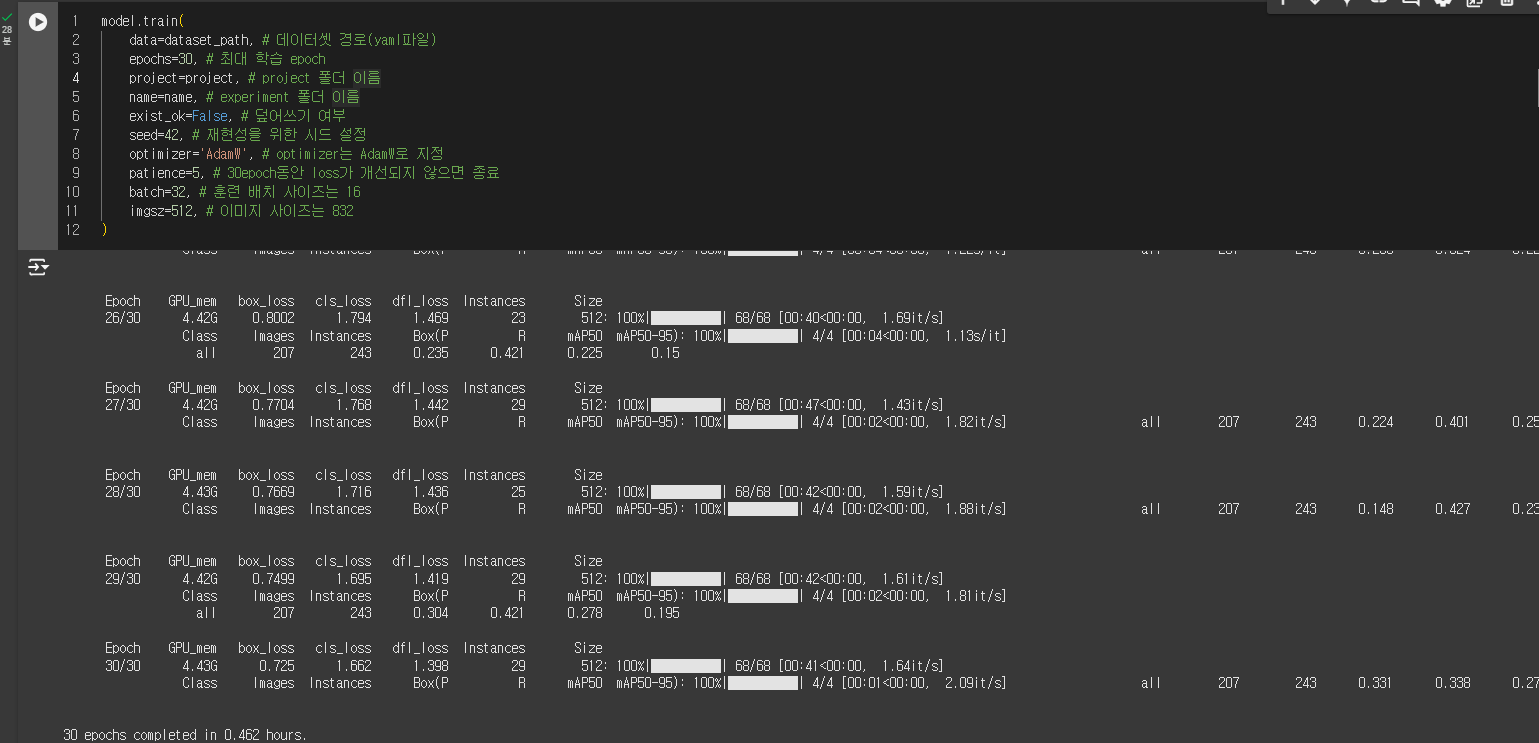 28분 소요됨.
28분 소요됨.
loss값 시각화
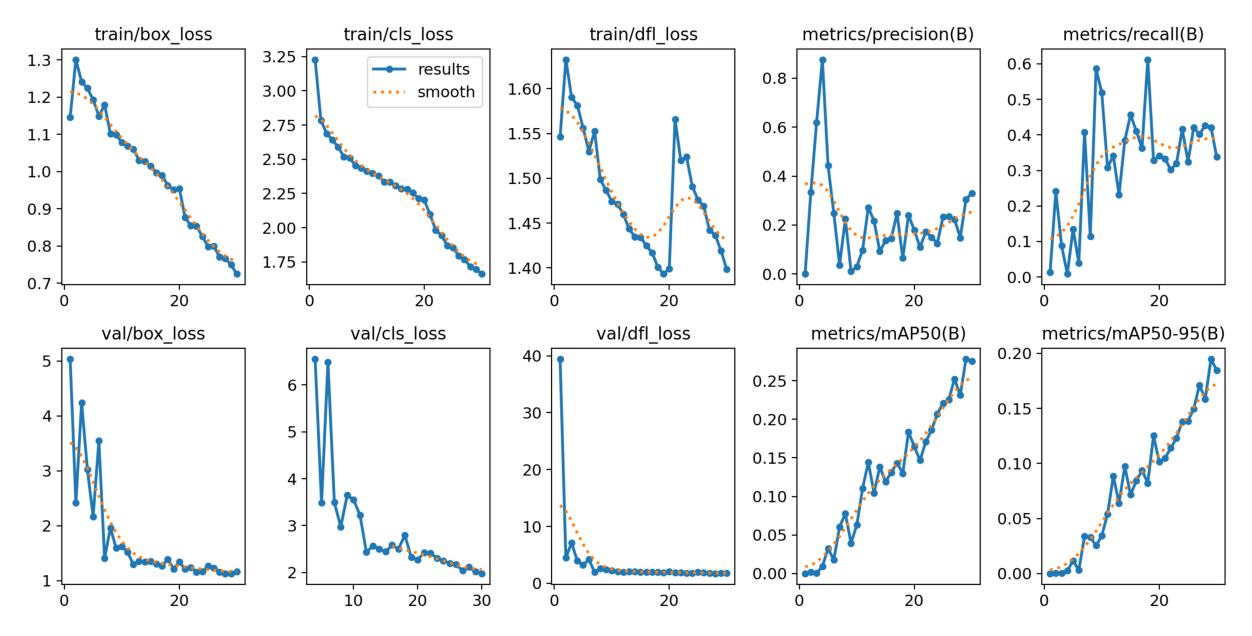
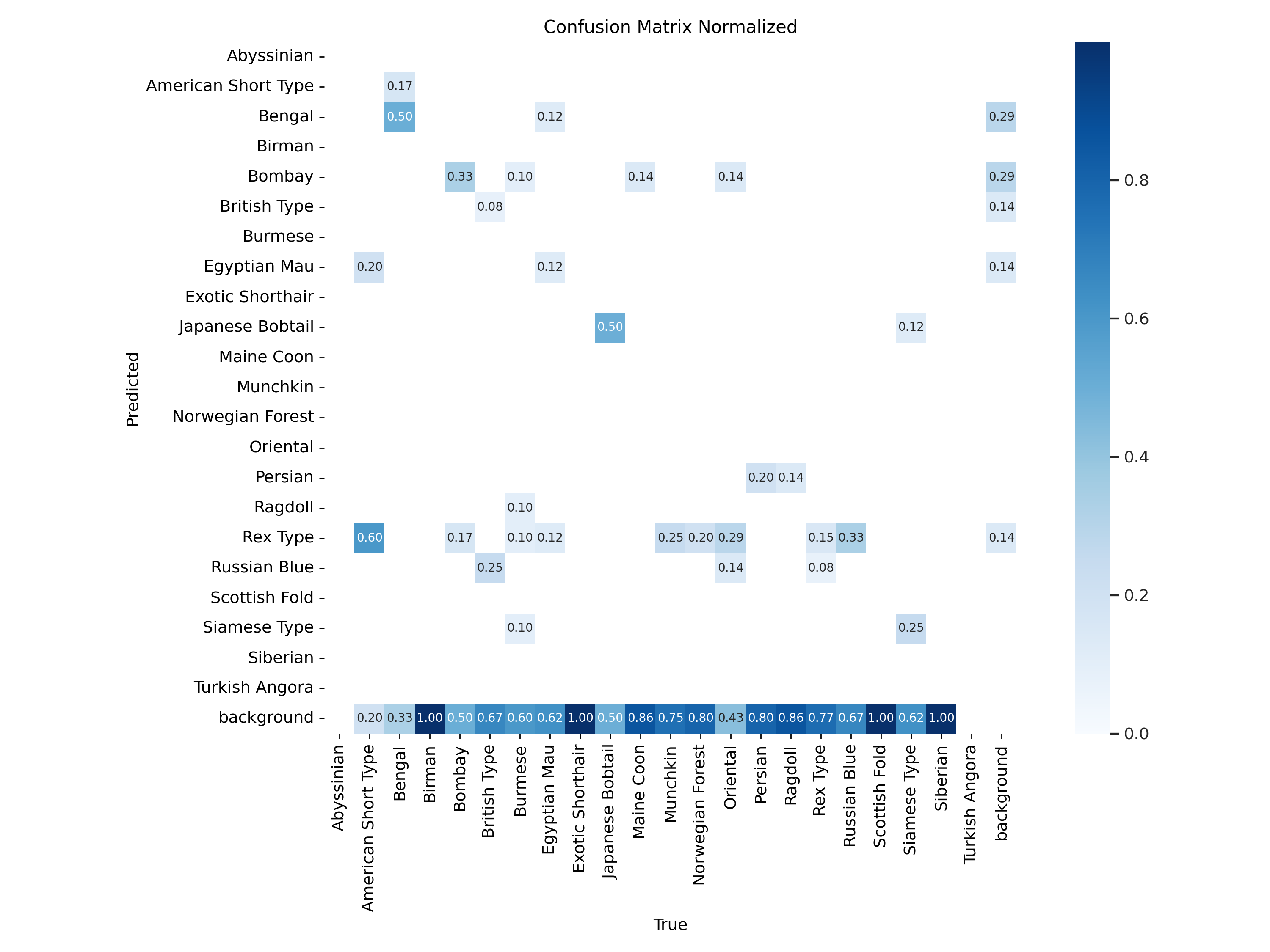
혼동행렬(정규화 빠짐)
3.2 모델(YOLO11s, 640^2)
 26분 소요됨.
26분 소요됨.
loss값 시각화
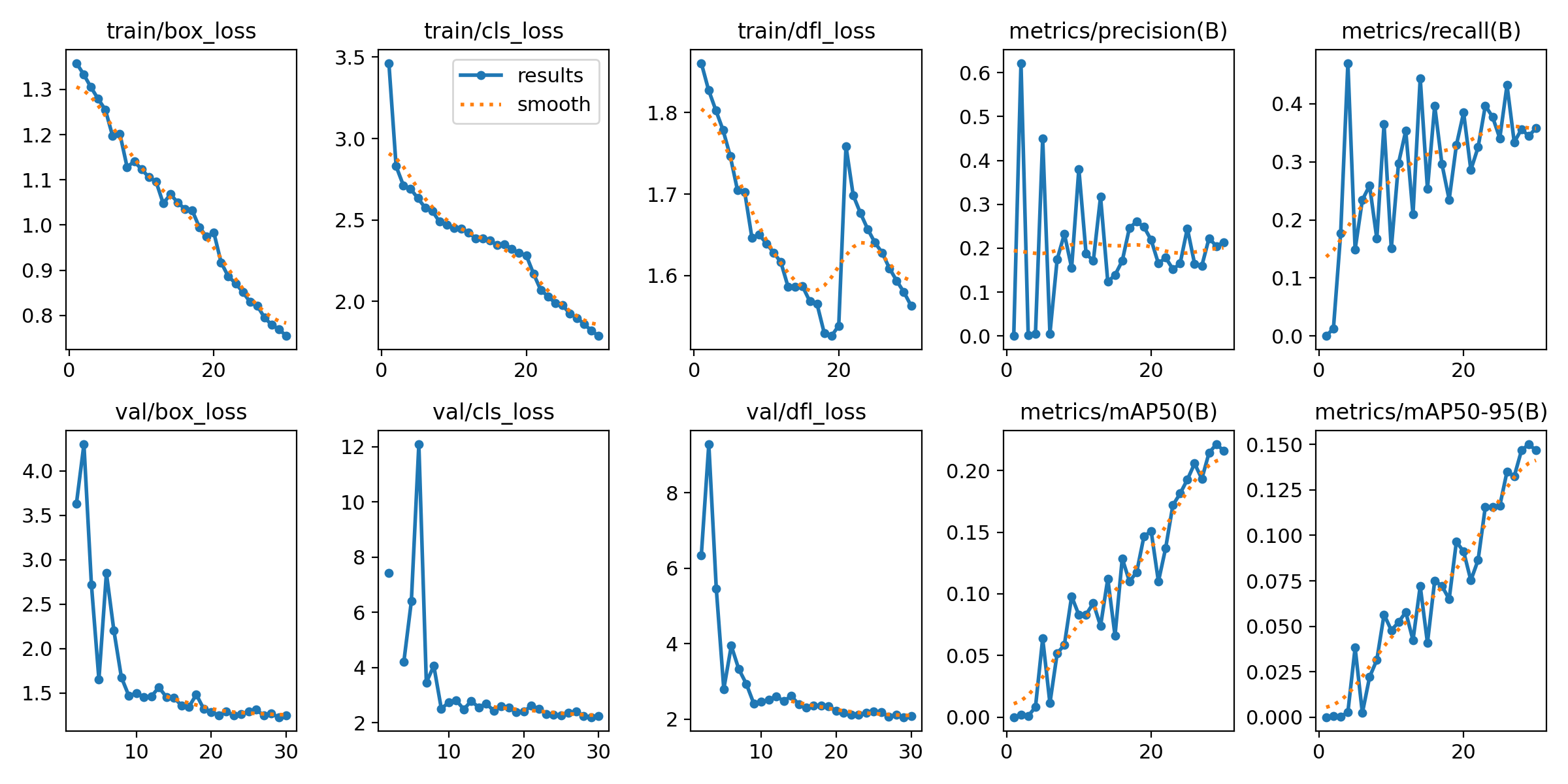
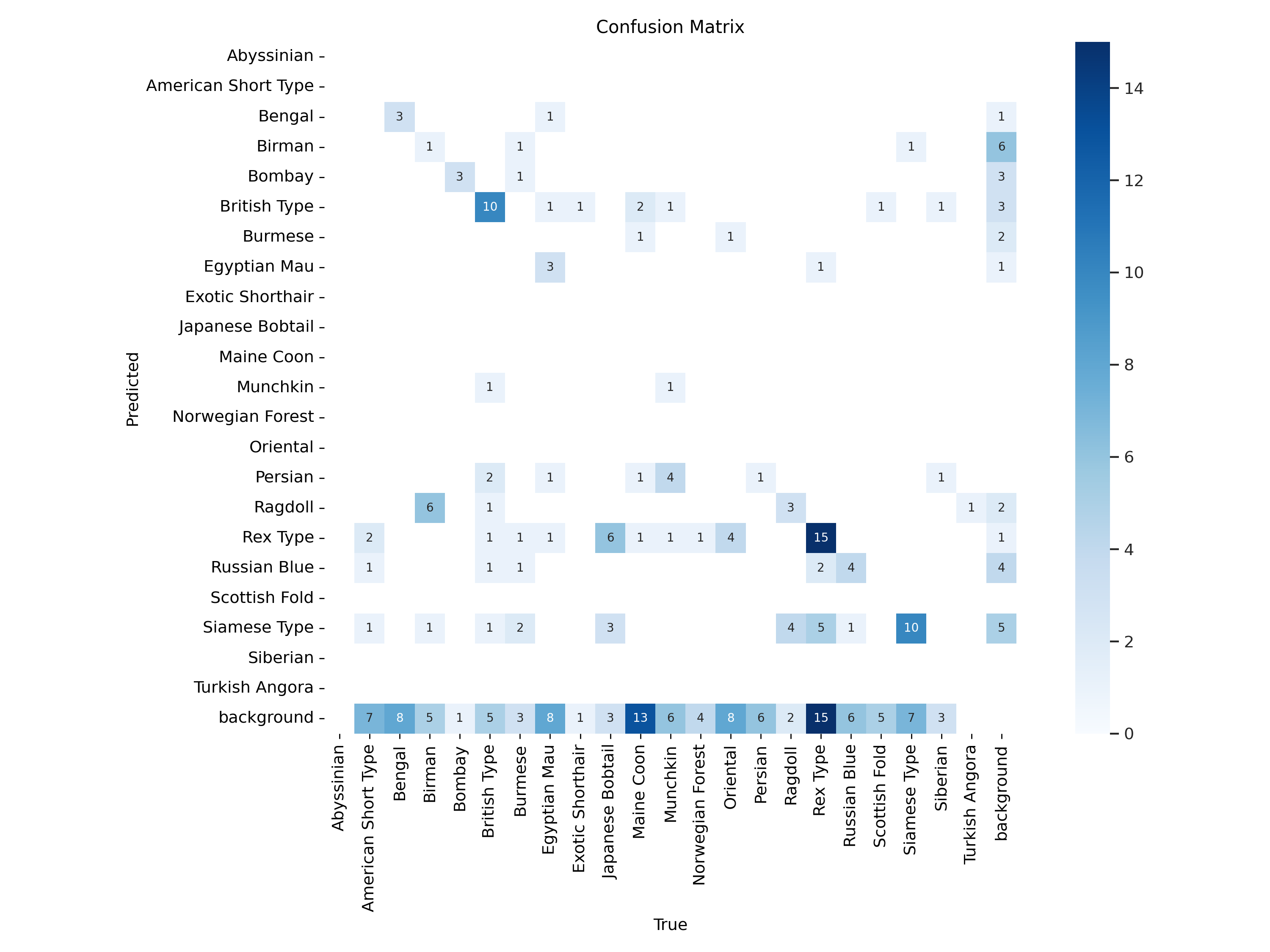
혼동행렬
4. 문제점 분석 및 해결방안
이미지 스크래핑 부분
BS 사용했을때 썸네일만 가져오는 로직때문에 화질이 열화되는 문제가 발생해서 selenium으로 바꿨지만 20장 까지는 잘 저장해도 그 이후 밑으로 스크롤하면서 리프레쉬 되어 parsing 부분이 바뀌는 문제 때문에 실패했습니다. 최종적으로는 bing image downloader 라이브러리를 사용했습니다.
데이터셋 만드는 부분
혼동행렬을 보니 말이안되는 수치라 test data의 클래스를 확인해봤더니
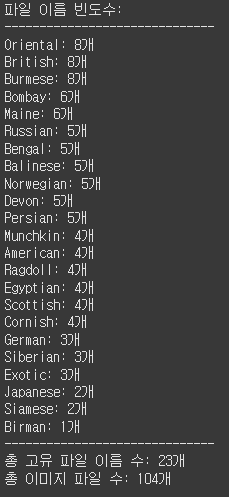
다소 제멋대로 들어가있어서, 클래스가 많을 경우 분포를 잘 맞춰야 한다고 생각했습니다.
학습 부분
epoch 30기준. 그래프를 보면 정확도가 증가하는데 시간 자원이 한정되어 잠시 보류했습니다.
데이터 부분
품종이 꼬리, 다리에 특징이 있는 경우가 많은데, 앉아있거나 누워있거나 얼굴만 있는 이미지가 대다수였습니다. 그래서 모델이 오로지 털 색깔이나 패턴에 의존해서 추측하는 경향을 보였습니다. (봄베이, 뱅갈 타입이 반증) 객체와 배경과 분리되어야 모델이 맥락을 파악할 수 있지만, 고양이의 경우 보통 실내&영역 동물이기때문에 배경없는 객체 근접사진이 절대다수 였습니다.
---------------------------------
수정한 버전
아쉬운 부분들이 많아서 다시 여러 부분을 수정했습니다.
품종 그룹화 부분 수정
주요 특징별 품종 다시 그룹화
1. 동양계 (유지)
- Siamese / Balinese / Thai
→ "Siamese Type" 으로 통합
2. 도메스틱 타입 (수정)
- American Shorthair / American Wirehair / Japanese Bobtail
→ "Domestic Type" 로 통합
이유 : 품종간 특징이 비슷해 보이기 때문
3. 영국계 (제거)
- British Longhair / British Shorthair
→ "British Type" 로 통합
이유 : 품종간 특징이 뚜렷해 보이기 때문
4. Rex 그룹 (유지)
- Devon Rex / Cornish Rex / German Rex
→ "Rex Type" 로 통합
외형적 특징이 뚜렷한 품종들을 최대한 개별 클래스로 만드는 방향으로 설정하고, 반대로 특징이 비슷하다면 과감하게 합치는 방향으로 수정했습니다.
Roboflow 라벨링부분 수정

모델이 배경을 인식하도록 하기위해 라벨링 일관성을 해치지 않는선에서 객체를 잘라서 라벨링 했습니다. (ex. 꼬리 제외, 귀 제외)
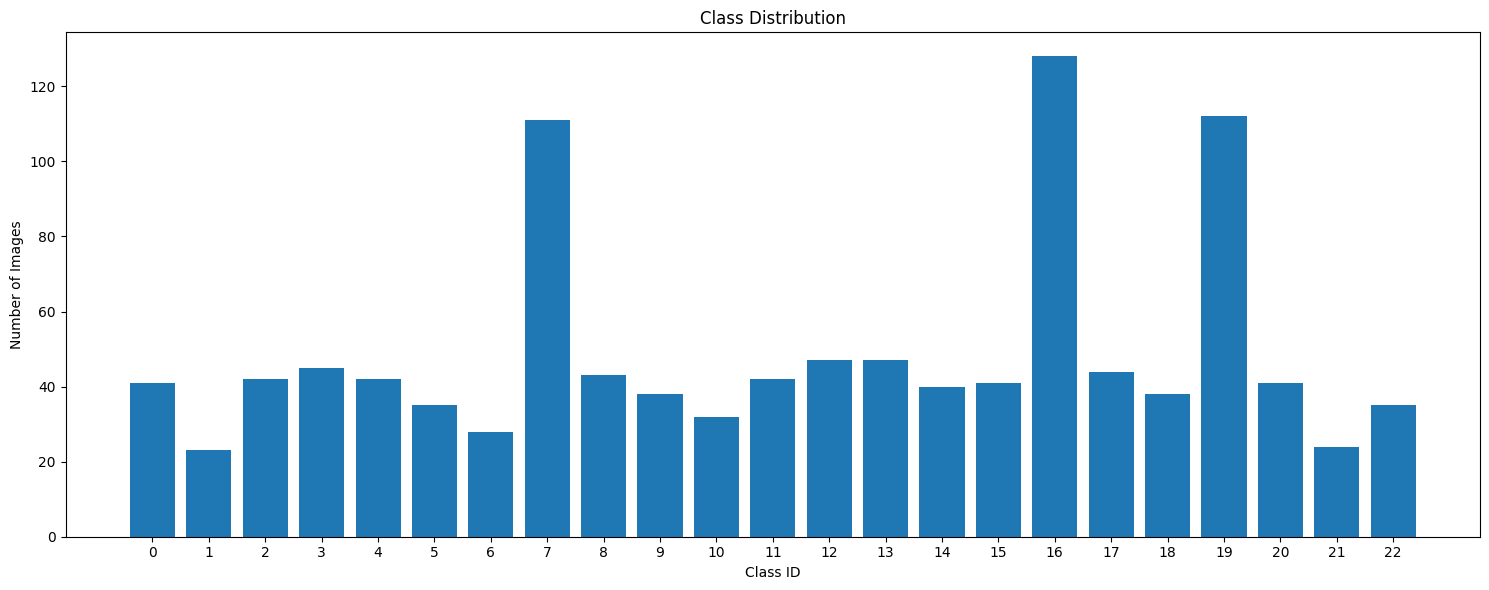
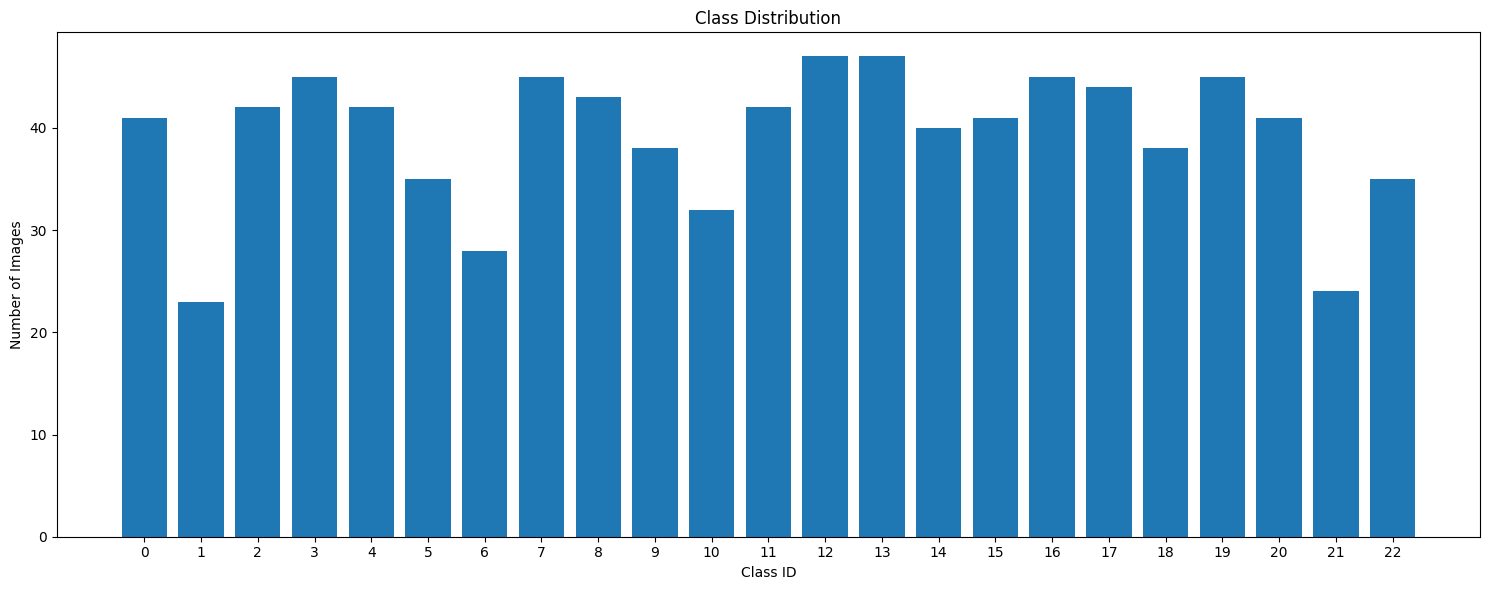
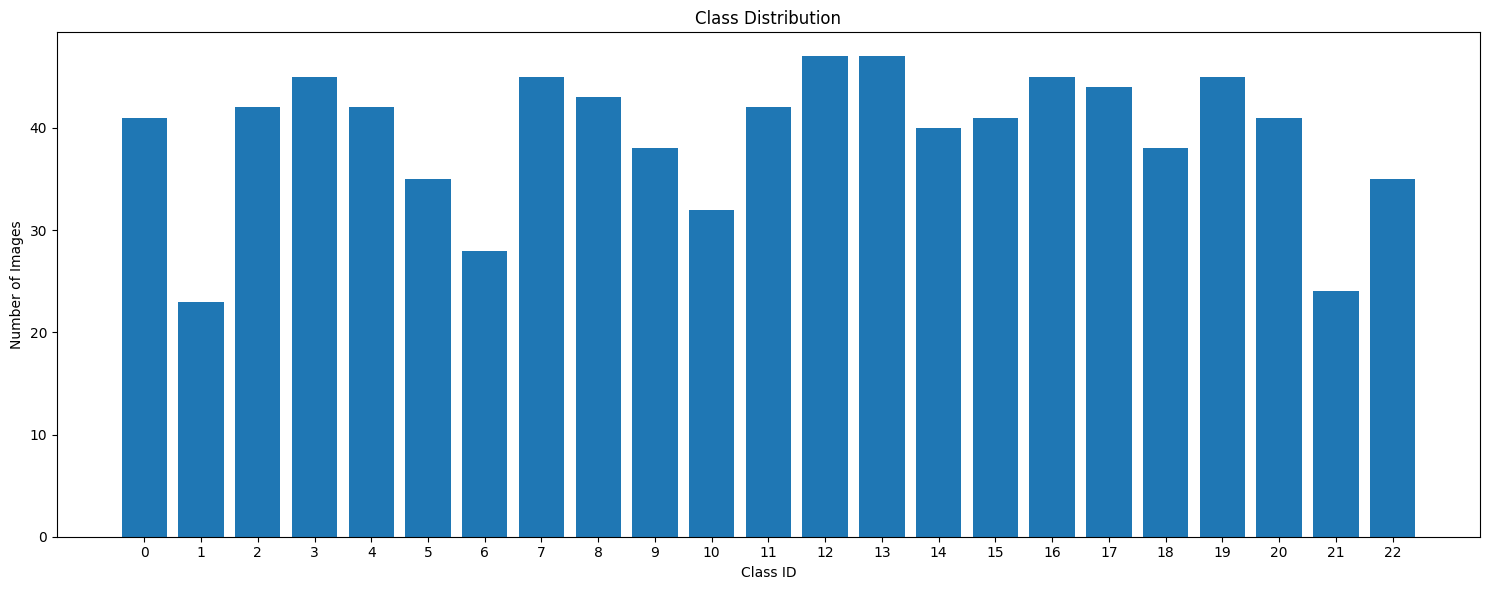
데이터셋 간 클래스 불균형 문제 수정
다운 샘플링
 |  |
|---|
업샘플링
 |  |
|---|
훈련데이터 최종 이미지 개수
1119 -> 1071
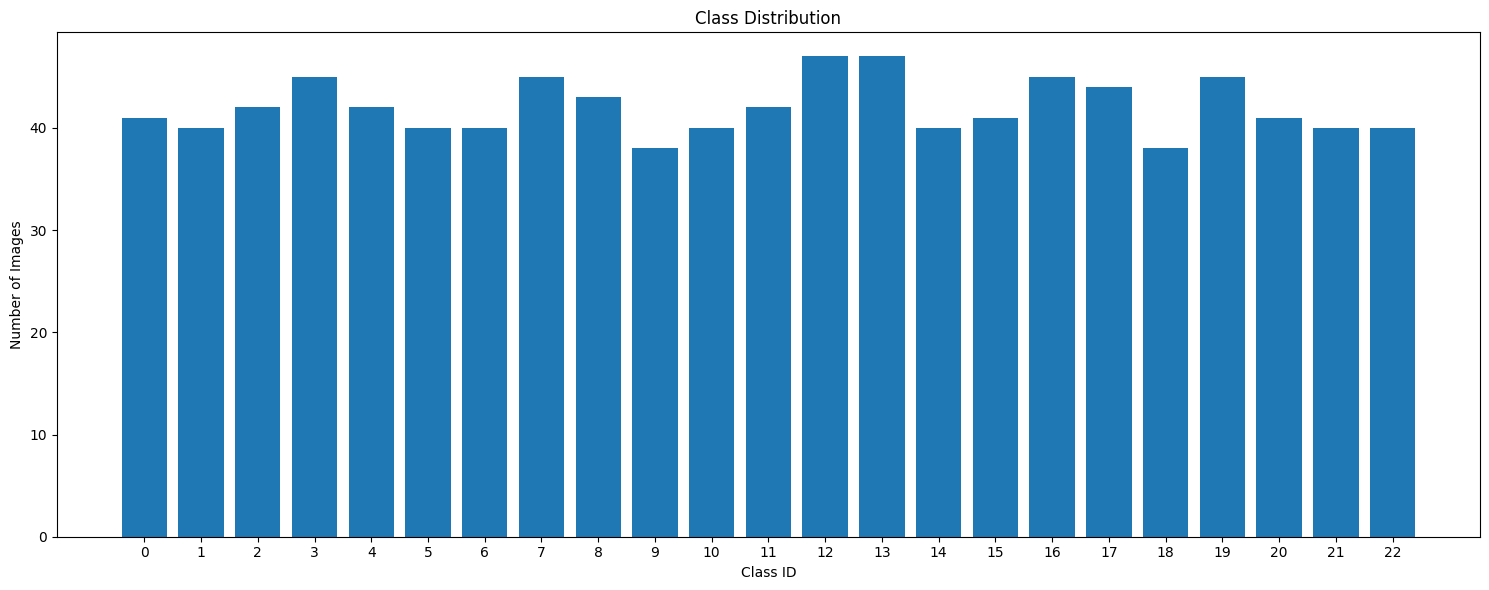
업&다운 샘플링으로 클래스 별로 이미지 개수를 40~50장에 맞췄습니다.

train / valid / test 비율 부분 수정
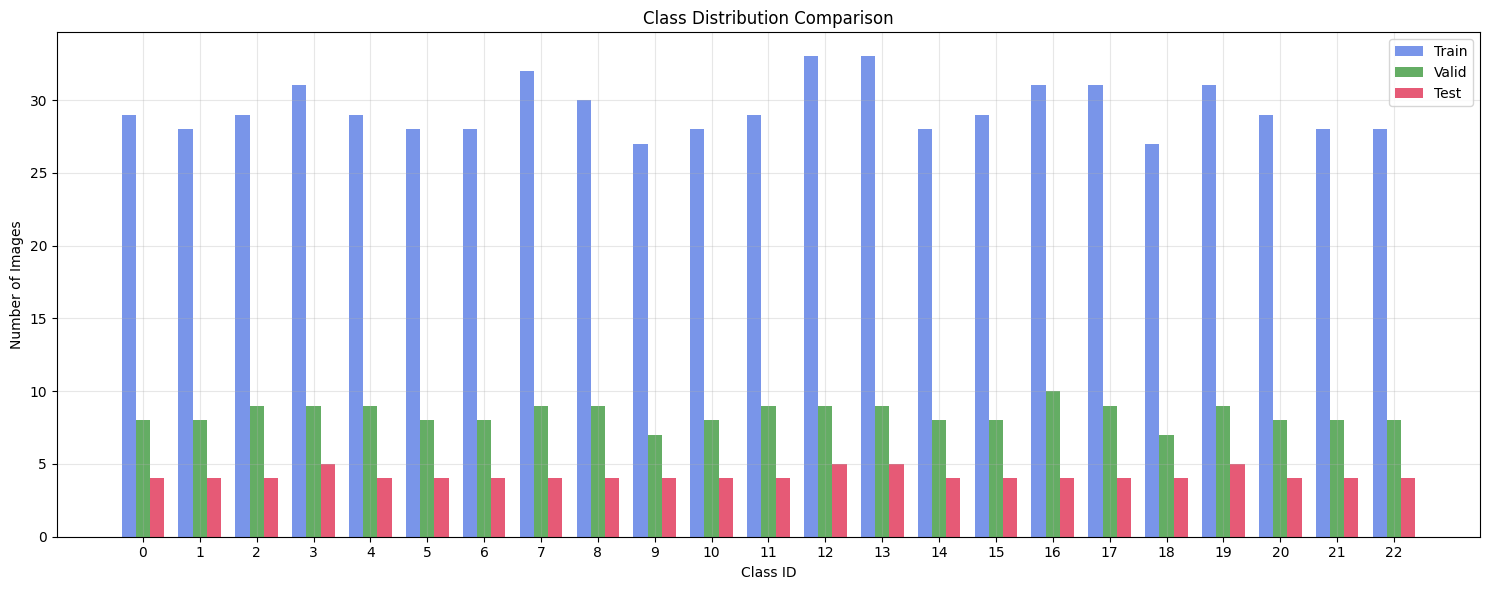
클래스간 비율 분포를 동일하게 했습니다.
데이터 증강부분 수정
 | 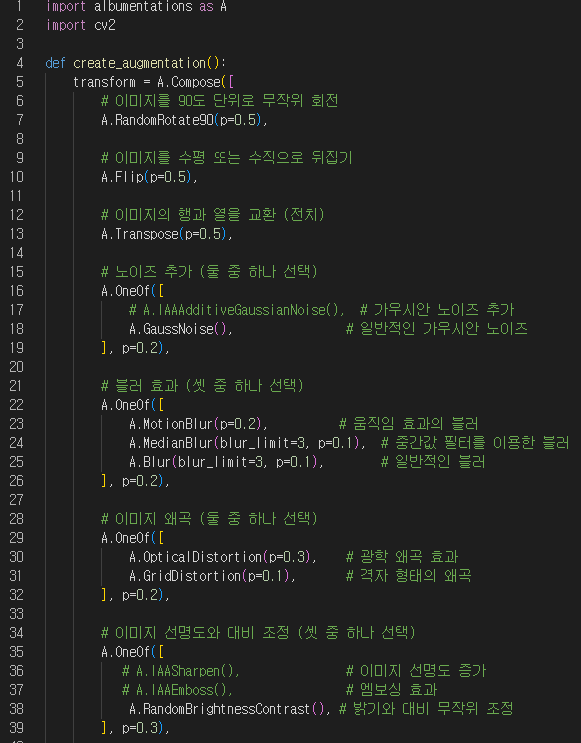 |
|---|
데이터 증강을 Roboflow가 아닌 Albumentation 라이브러리를 사용했고, label 파일의 좌표도 같이 변환했습니다.
모델 버전 수정

기존 모델의 예측은 객체자체를 인식하지 못하는 문제가 있었습니다. YOLOv11 모델이 너무 국소적인 패턴 파악에 매몰되어 있는것 같았습니다. 그래서 YOLOv8을 사용해서 패턴 파악보다는 전체적인 객체를 인식하도록 의도적으로 성능을 감소시켜 보았습니다. 물론 극적인 변화까지는 생각하지는 않았지만 그래도 약간의 기대를 가지고 학습시킨 결과, 역시 버전별 성능은 크게 관계가 없고 대동소이 했습니다.
 |  |
|---|
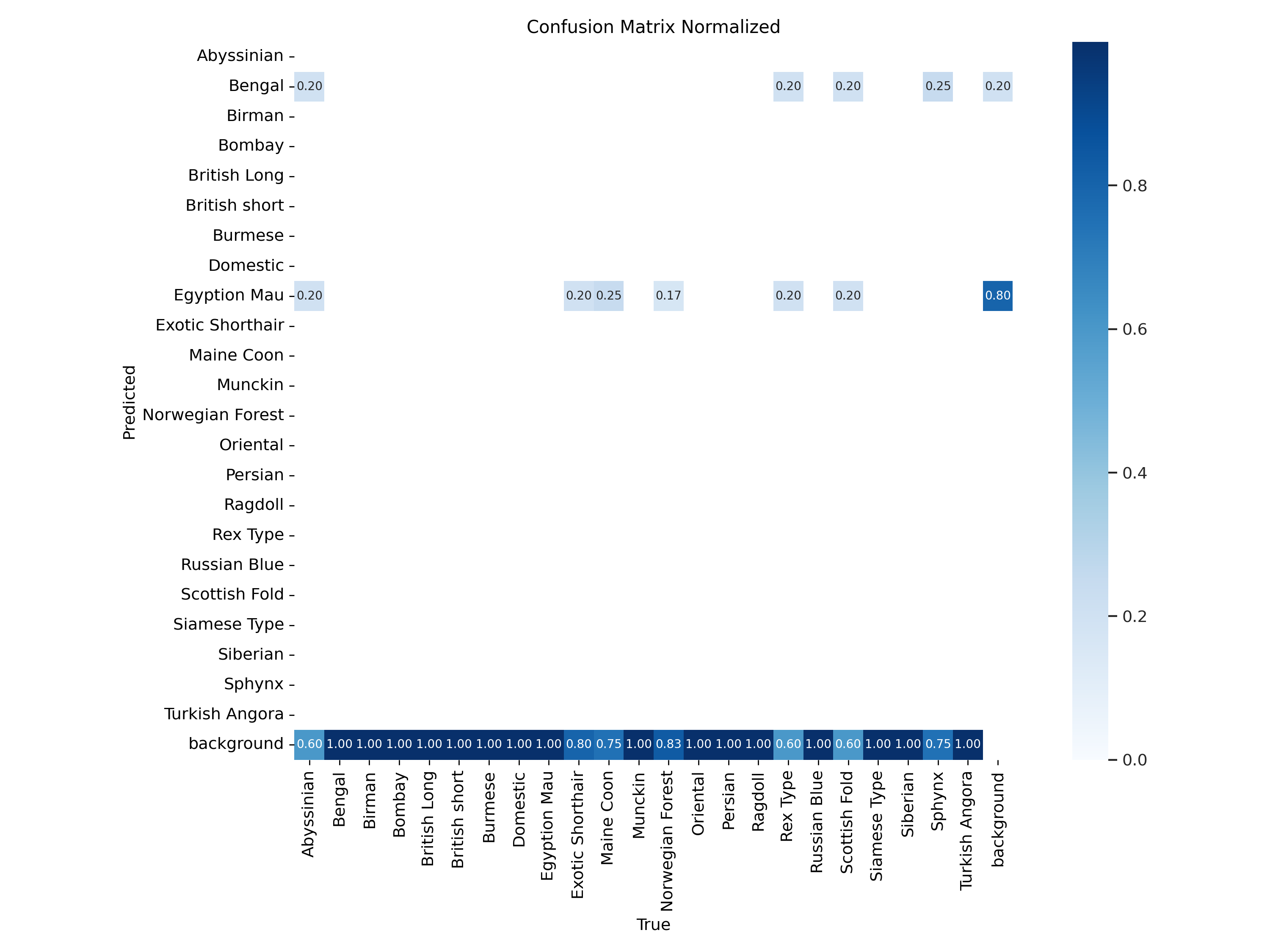
항상 뱅갈 품종과 이집트 고양이 품종의 정확도가 상대적으로 높게 나왔던것을 보아하니, 모델이 특정한 패턴을 위주로 학습했다는 것을 알게 되었습니다.
모델 학습부분 수정

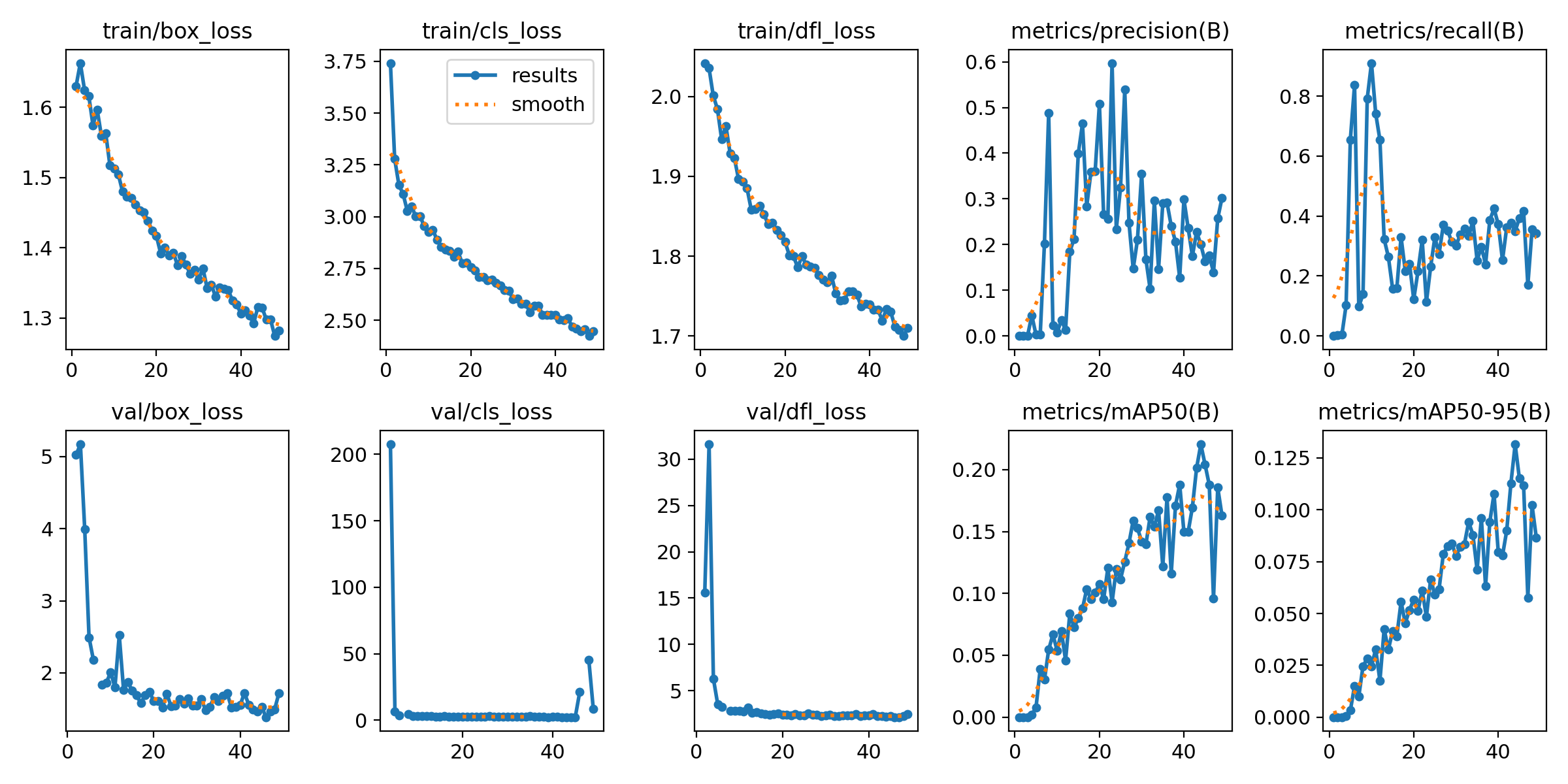
epoch를 100으로 설정했지만 50 부근에서 Early stopping이 작동했습니다.
수정 결과
loss 값 시각화
정규화된 혼동행렬
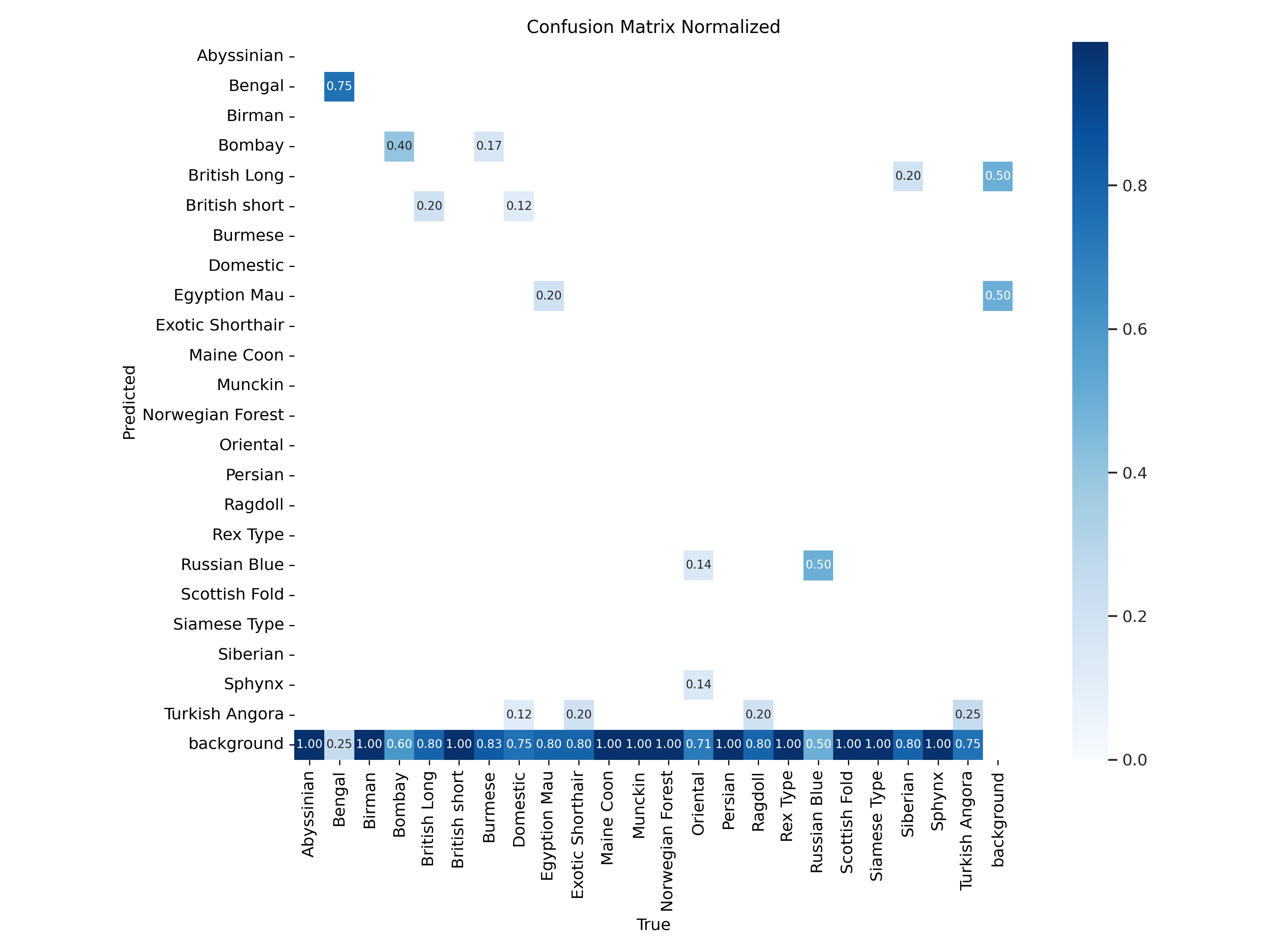
한계 및 결론
한계
전부 검은색인 봄베이 품종과, 특유의 레오파드 무늬가 있는 뱅갈 품종등이 그나마 높은 정확도를 보였습니다. 모델이 오로지 털 색깔이나 패턴에 의존해서 추측하는 경향을 보였습니다. 강아지와 달리 고양이의 경우 보통 실내 동물이기 때문에 배경이 거의 없는 근접 이미지가 많았던 것이 모델 정확도가 낮은 이유라고 생각합니다.
결론
좋지 않은 결과로 인해 프로젝트 주제 선정에 의문을 가졌으나, 이는 오히려 모델의 한계점을 파악하고 개선 방향을 도출할 수 있는 의미 있는 기회였다고 생각합니다. 모델이 패턴 특징에만 의존한다는 점을 발견했고, 이를 바탕으로 다양한 각도와 조건의 데이터 확보 필요성을 확인했습니다. 이러한 경험을 토대로 향후 더 정확한 객체인식 모델을 개발하고자 합니다.
