
1. 개요 및 문제 분석
1.1 개요
딥페이크(Deepfake) 기술의 발전으로 인한 가짜 얼굴 이미지 생성이 증가하고 있고, 이러한 가짜 이미지를 탐지하는 것이 사회적으로 중요한 문제로 대두되고 있습니다.
1.2 문제 분석
실제 사람의 얼굴 이미지와 AI로 생성된 가짜 얼굴 이미지를 구분하는 이진 분류 문제로 접근했고,
pytorch, ResNet18 모델을 기반으로 전이학습을 적용하여 문제를 해결하고자 했습니다.
또한 모든 전처리, 학습과정은 colab pro 환경에서 진행했습니다.
2. 데이터셋 분석
데이터셋은 kaggle의 Real and Fake Face Detection 데이터를 사용했습니다.
특이사항으로는 GAN 기반이 아니라 포토샵 기반의 합성 이미지입니다.
2.1 데이터셋 분석

데이터셋은 test와 training 두개로 분류했습니다.

하위 파일은 fake와 real로 다시 나누었습니다. (후에 파일명으로 label 예정)
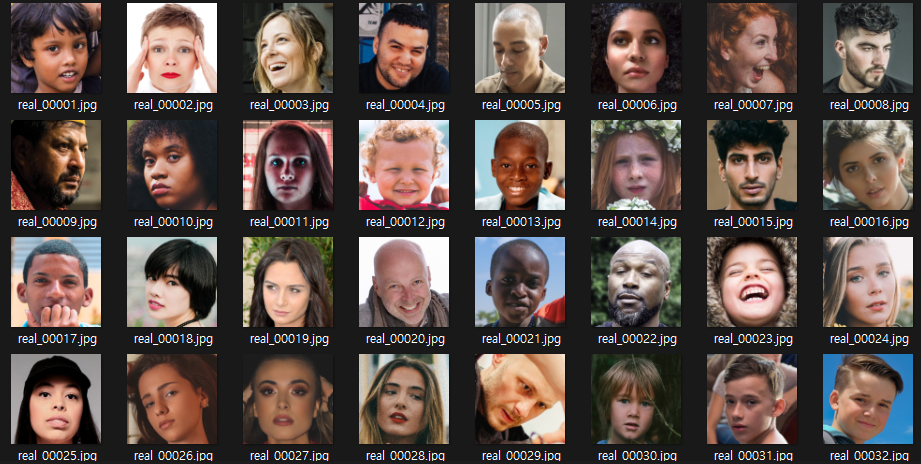 real image 구성.
real image 구성.
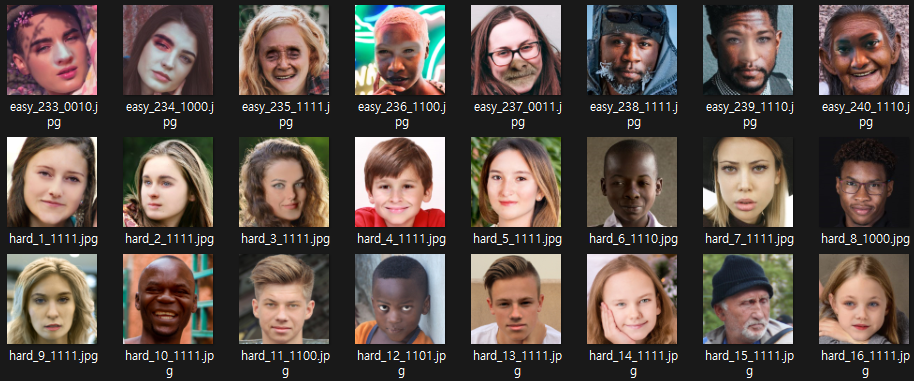

fake imgae는 easy / mid / hard 의 세가지 분류가 있습니다. (easy는 합성된 이상한 이미지, hard는 실제 사람과 분간이 힘든정도)
(train) real image = 779
(train) fake image = 658개 (0.47 : 0.35 : 0.47) 도합 1,437개 이미지.
(test) real image = 302
(test) fake image = 302 (only mid) 도합 604개 이미지.
3. 구현 과정
데이터 준비 부분
구글 드라이브에 데이터 마운트
glob로 파일경로를 기준으로 dataframe 생성하고 학습데이터 및 테스트데이터로 저장
validation을 위해 학습데이터셋을 8:2 분할
train 원시 데이터는 변수로 따로 저장
딥러닝 모델 구조 부분
사용자 정의 데이터 로딩
데이터 정규화 & 표준화 시행
- 픽셀값을 0~1사이로 조정하여 기울기 문제 해결 및 학습 속도↑
- 모델 일반화 능력
채널 정규화 시행
- RGB 채널의 평균과 표준편차를 0~1 사이의 값으로 조정.
Data Augmentation 시행
- 이미지를 resize후 randomcrop 진행
- 좌우반전 / 10º 회전 / 밝기 대비 채도 색조 랜덤 조정
Pre-trained 모델(ResNet18) 사용
- 마지막 완전연결층 출력을 2로 수정 (real/fake 이진분류를 위함)
- 손실함수는 기본적으로 다중클래스 분류에 유리한 CrossEntropy 사용
- Adam 옵티마이저 사용
- 학습률 1e-5
시각화 부분
Confusion Matrix로 예측대비 맞춘 비율 시각화
Train loss와 Validation loss 값 그래프로 시각화
사용자가 직접 이미지를 넣어볼 수 있도록 하는 함수 추가
3.1 데이터 준비
3.1.1 구글 드라이브 마운트
필요 라이브러리를 import 하고, colab에 구글 드라이브를 연결
Google Colab에서 데이터 관리 및 최적 활용 전략
드라이브 설정
- 코랩에서 데이터에 접근하는 방법에는 크게 두 가지가 있습니다.
- 구글 드라이브 연동 : 자신의 Google Drive를 코랩에 연결하여 드라이브 안의 데이터에 접근합니다.
- 코랩의 세션 드라이브 업로드 : 코랩의 임시 저장 공간에 데이터를 업로드하여 사용합니다.
- 각각의 방법은 장단점을 가지고 있습니다.
- 구글 드라이브 연동의 장점은 드라이브에 데이터가 미리 준비되어 있으면 즉시 사용할 수 있다는 것이며, 데이터가 지속적으로 보존됩니다. 단점은 이미지 데이터와 같이 용량이 큰 데이터를 다룰 때, 로딩 속도가 매우 느리다는 단점이 있습니다.
- 코랩의 세션 드라이브에 업로드하는 방법의 장점은 드라이브 연동에 비해 로딩 속도를 매우 빠르게 사용할 수 있다는 것입니다. 하지만 이 방법의 단점은 코랩 런타임이 초기화될 때마다 데이터가 사라지고, 다른 ipynb에서 접근이 안된다는 단점이 존재합니다.
- 따라서 이미지 데이터와 같이 대용량의 학습 데이터는 학습 직전에 임시 경로에 업로드하여 사용하고, 그 외 필요한 파일들은 구글 드라이브에서 직접 불러오는 것이 좋습니다. 또한 학습된 모델 파일처럼 저장이 필요한 자료는 보존을 위해 반드시 구글 드라이브에 저장합니다. 이렇게 하면 데이터 사용의 효율성과 접근성을 극대화할 수 있습니다.
3.1.2 학습을 위한 DataFrame 생성
glob 메서드로 training / test 파일 경로를 df로 만들고, 파일명으로 labeling 진행했습니다.
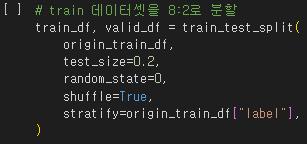
train_data는 train : valid = 8 : 2로 분리하고 원시 데이터를 남기기 위해 따로 origin 변수로 저장했습니다.
3.2 딥러닝 모델 구조 설명
3.2.1 CustomDataset 로딩
class CustomDataset(Dataset):
def __init__(self, dataframe, transform=None):
self.dataframe = dataframe
self.transform = transform
def __len__(self):
return len(self.dataframe)
def __getitem__(self, idx):
img_name = self.dataframe.iloc[idx, 0]
img = Image.open(img_name).convert('RGB')
label = 0 if self.dataframe.iloc[idx, 1] == 'real' else 1
if self.transform:
img = self.transform(img)
return img, label
if self.transform:
img = self.transform(img)
return img, label3.2.2 데이터 정규화 & 표준화
def compute_overall_mean_std(dfs):
all_pixels = {0: [], 1: [], 2: []}
for df in dfs:
for index, row in df.iterrows():
img_path = row['path']
img = Image.open(img_path)
img_np = np.array(img)
for i in range(3): # RGB 채널
channel_pixels = img_np[:, :, i].ravel().tolist() # 각 채널의 모든 픽셀 값을 수집
all_pixels[i].extend(channel_pixels)
means = [np.mean(all_pixels[i]) for i in range(3)]
stds = [np.std(all_pixels[i]) for i in range(3)]
return means, stds
# 미리 계산해둔 값 사용
channel_means = [193.67807472479592, 111.60517909723688, 118.44033090803525]
channel_stds = [63.00208387441839, 87.1299016633704, 71.00312754293988]
print("Overall Data: Mean -", channel_means, "Std -", channel_stds)각 데이터프레임의 이미지를 반복해서 NumPy 배열로 변환
3.2.3 채널 정규화 및 Data Augmentation
# 채널 평균 및 표준편차를 0~1 사이의 값으로 정규화
normalized_channel_means = [x / 255 for x in channel_means]
normalized_channel_stds = [x / 255 for x in channel_stds]
# 배치 사이즈 설정
batch_size = 32
# 학습용 데이터 증강 변환 정의
train_transform = transforms.Compose([
transforms.Resize((256, 256)), # 약간 큰 크기로 리사이즈
transforms.RandomCrop((224, 224)), # 랜덤 크롭
transforms.RandomHorizontalFlip(), # 랜덤 수평 뒤집기
transforms.RandomRotation(10), # 랜덤 회전 (-10도에서 10도 사이)
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1), # 색상 변조
transforms.ToTensor(),
transforms.Normalize(mean=normalized_channel_means, std=normalized_channel_stds),
])
# 검증 및 테스트용 변환 정의
eval_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=normalized_channel_means, std=normalized_channel_stds),
])
# 데이터셋 로딩
train_dataset = CustomDataset(dataframe=train_df, transform=train_transform)
valid_dataset = CustomDataset(dataframe=valid_df, transform=eval_transform)
test_dataset = CustomDataset(dataframe=tdf, transform=eval_transform)
# 데이터 로더 설정
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=4)
valid_loader = DataLoader(valid_dataset, batch_size=batch_size, shuffle=False, num_workers=4)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=4)3.2.4 Pre-trained Model(ResNet18) 사용
# 사전 학습된 ResNet18 모델 불러오기
model = models.resnet18(weights=models.ResNet18_Weights.DEFAULT)
# 모델의 마지막 완전 연결 계층(fc)을 사용자 정의 계층으로 대체
model.fc = nn.Sequential(
nn.Linear(model.fc.in_features, 2), # 이진분류
)
# 교차 엔트로피 손실 함수 초기화
criterion = nn.CrossEntropyLoss()
# 이진 교차 엔트로피 손실 함수 초기화
# criterion = nn.BCEWithLogitsLoss()
# 최적화 알고리즘으로 Adam 사용
optimizer = torch.optim.Adam(model.parameters(), lr=1e-5, weight_decay=1e-5)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)이진분류(real/fake) 분류를 위해 완전연결층 출력을 2로 설정했습니다.
손실함수는 기본적으로 다중클래스 분류에 유리한 CrossEntropy를 사용했습니다.
추가로 이진분류에 특화된 BCEWithLogitsLoss 함수도 따로 학습해 보았습니다.
3.3 Hyper Parameter 설정
모든 Parmeter는 동일하게 설정
epochs = 50
batch_size = 32
learning_rate = 1e-5
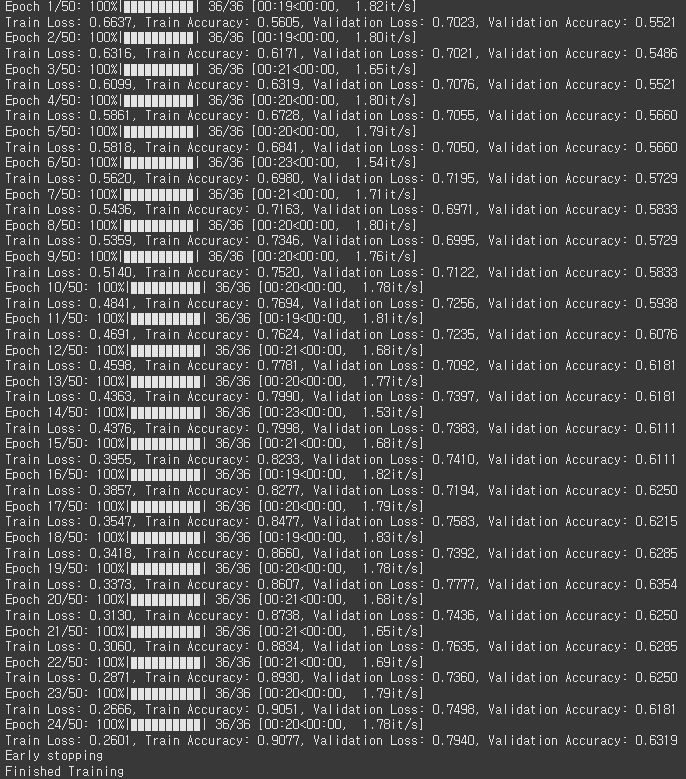
4. 학습
# 전체 훈련 횟수 설정
num_epochs = 50
# 최고 검증 정확도 초기화
best_val_acc = 0.0
# 얼리 스타핑을 위한 조건 설정 (성능 향상이 없을 때 몇 에포크까지 기다릴지)
patience = 5
# 연속적으로 성능 향상이 없는 에포크 수를 추적
no_improve = 0
# 훈련 및 검증 손실을 추적하기 위한 리스트
train_losses = []
valid_losses = []
# 정해진 훈련 횟수만큼 반복
for epoch in range(num_epochs):
model.train() # 모델을 훈련 모드로 설정
running_loss = 0.0
correct_train = 0
total_train = 0
# 훈련 데이터 로더를 통해 배치를 반복
for inputs, labels in tqdm(train_loader, desc=f"Epoch {epoch+1}/{num_epochs}", dynamic_ncols=True):
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad() # 이전 반복에서 계산된 그래디언트를 초기화
outputs = model(inputs) # 모델에 입력을 전달하여 출력을 계산
# BCEWithLogitsLoss는 0, 1 레이블을 예상하지만,
# 모델은 2개의 출력 뉴런을 가지므로, 이를 0 또는 1로 변환해야 합니다.
# 가장 높은 확률을 가진 클래스 인덱스를 선택합니다.
_, predicted = torch.max(outputs.data, 1)
# loss = criterion(outputs, labels) # 손실 함수를 사용하여 손실 계산
loss = criterion(outputs[:, 1], labels.float()) # 이진 분류를 위한 수정
loss.backward() # 손실에 대한 그래디언트를 계산
optimizer.step() # 옵티마이저를 사용하여 모델의 가중치를 업데이트
running_loss += loss.item() # 총 손실을 누적
# _, predicted = torch.max(outputs.data, 1) # 예측 결과 계산 # 이 부분은 위로 이동되었습니다.
total_train += labels.size(0) # 전체 레이블 수 업데이트
correct_train += (predicted == labels).sum().item() # 정확한 예측 수 업데이트
# 에포크별 훈련 정확도 및 손실 계산
train_acc = correct_train / total_train
train_loss = running_loss / len(train_loader)
# Validate
model.eval()
running_val_loss = 0.0
correct_val = 0
total_val = 0
with torch.no_grad():
for inputs, labels in valid_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
# Get the raw output for the positive class (index 1)
# This makes sure outputs and labels have the same shape
loss = criterion(outputs[:, 1], labels.float()) # Select the output for the positive class (index 1) and convert to float
running_val_loss += loss.item()
# For accuracy calculation, you still need predictions based on both outputs
_, predicted = torch.max(outputs.data, 1)
total_val += labels.size(0)
correct_val += (predicted == labels).sum().item()
val_acc = correct_val / total_val
val_loss = running_val_loss / len(valid_loader)
# 손실 기록
train_losses.append(train_loss)
valid_losses.append(val_loss)
print(f'Train Loss: {train_loss:.4f}, Train Accuracy: {train_acc:.4f}, '
f'Validation Loss: {val_loss:.4f}, Validation Accuracy: {val_acc:.4f}')
# 최고 검증 정확도를 갱신하고 모델 저장
if val_acc > best_val_acc:
best_val_acc = val_acc
torch.save(model.state_dict(), 'best_model_after.pth')
no_improve = 0
else:
no_improve += 1 # 성능 향상이 없으면 no_improve 카운터 증가
if no_improve >= patience: # 설정한 얼리 스타핑 patience에 도달하면 학습을 중단합니다.
print("Early stopping")
break
print('Finished Training')BCEWithLogitsLoss를 사용해서 레이블을 변환한 부분을 제외하면 일반 CrossEntropy 학습과정과 동일합니다.
5. 학습 결과 및 시각화
5.1 CrossEntropy / Data Augmentation X
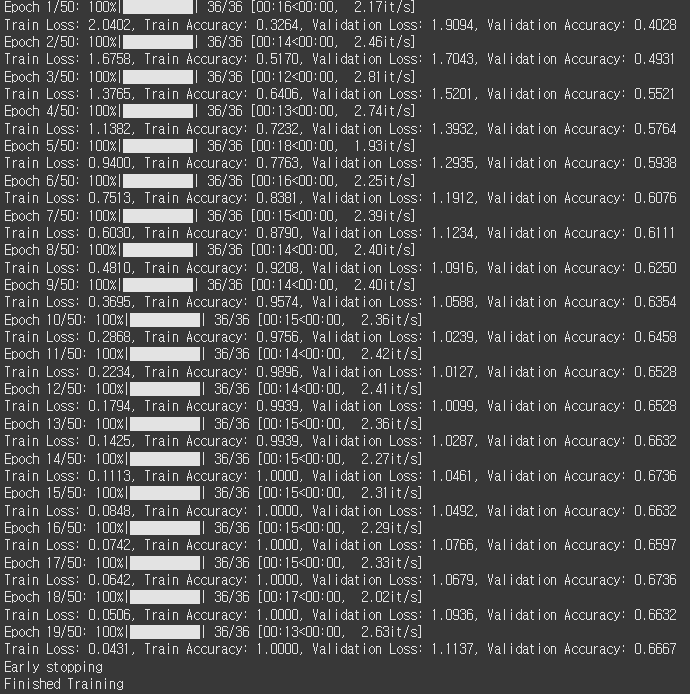
과적합 문제가 나타났습니다.
5.2 CrossEntropy / Data Augmentation O
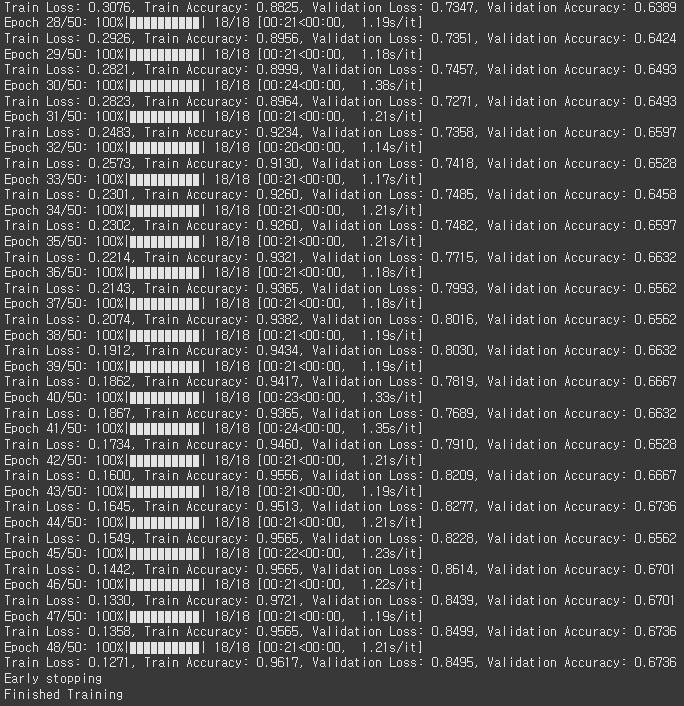
Data Augmentation 과정을 추가하니 Train/Valid loss값이 감소하고 정확도도 소폭 상승했습니다.
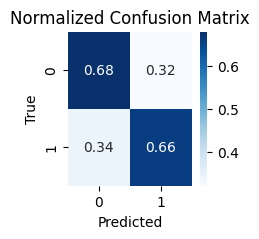
정확도는 66 ~ 68% 정도가 나왔습니다.
0 = real
1 = fake
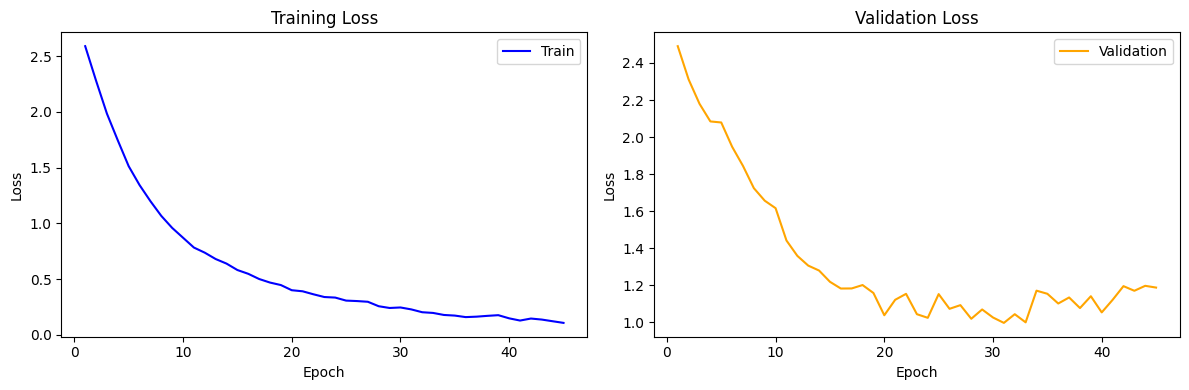
확실히 Validation쪽이 문제가 심해 보입니다.
5.2 BCEWithLogits / Data Augmentation O
이진 분류에 특화된 손실함수를 사용했는데 결과는 이전보다 더 나쁘게 나왔습니다.
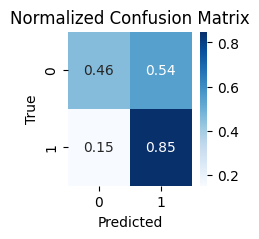
사실상 OX문제를 한줄로 밀어버린 수준...
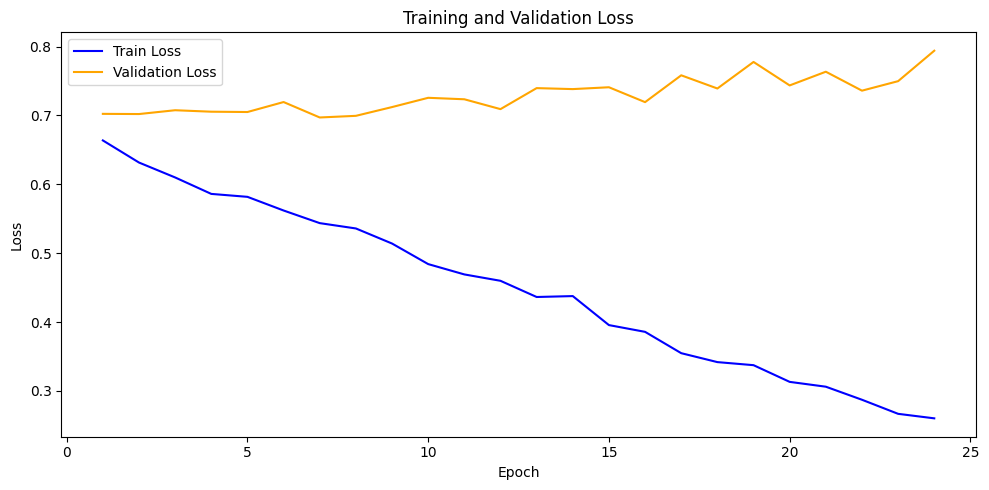
한 그래프에 범례를 통일해서 넣으면 한눈에 보기 좋다는걸 까먹고 여기서 추가했습니다.
사실, 결과는 안봐도 예측이 되는 수준이였습니다.
6. 입력받고 예측
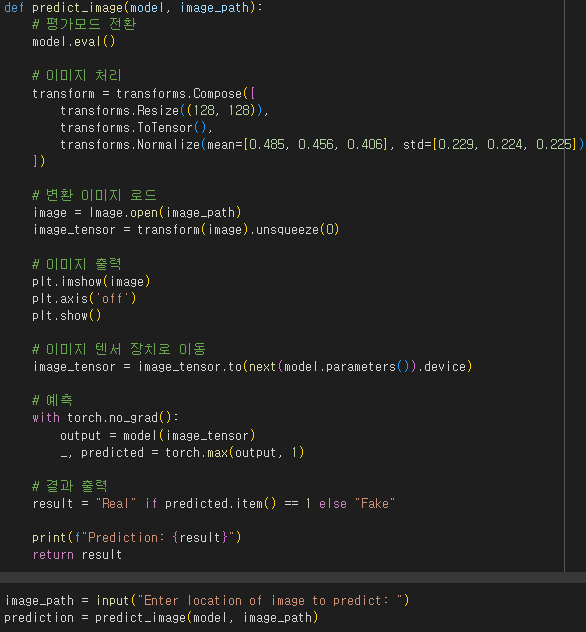
위 코드를 사용해서 직접 사진을 입력해서 모델별로 확인해보았습니다
6.1 CrossEntropy / Data Augmentation X
 카리나님 기사 사진을 넣어 보았습니다.
카리나님 기사 사진을 넣어 보았습니다. 맞추긴 했네요
6.2 CrossEntropy / Data Augmentation O
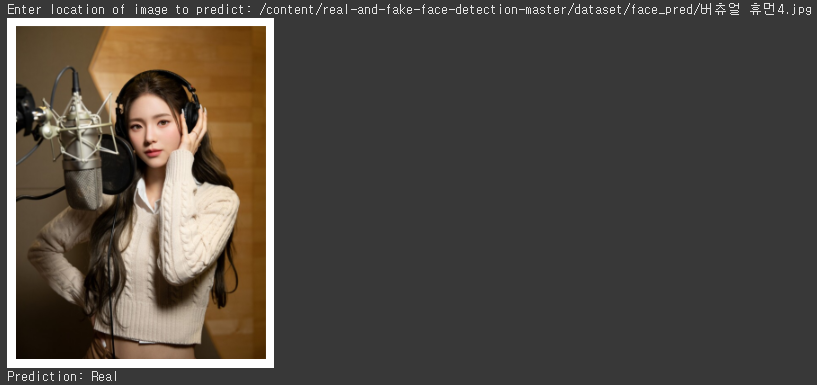 버추얼 휴먼 사진을 넣어 보았습니다.
버추얼 휴먼 사진을 넣어 보았습니다.
6.3 BCEWithLogits / Data Augmentation O
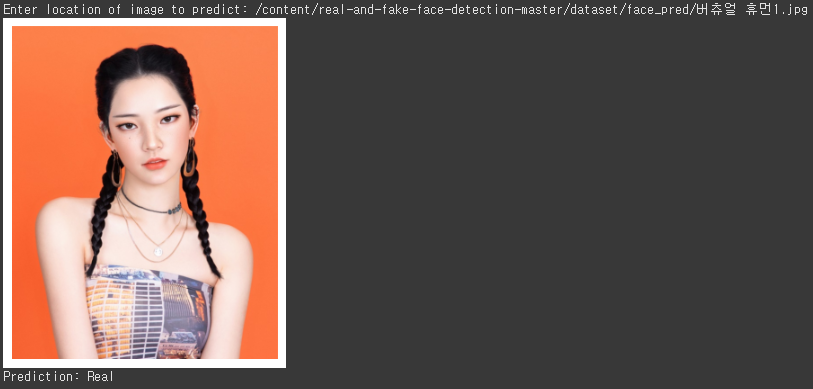 똑같이 버추얼 휴먼 사진을 넣어 보았습니다.
똑같이 버추얼 휴먼 사진을 넣어 보았습니다.
7. 결론
- pytorch와 Pre-trained 모델을 사용해서 정확도 67%로 조작된 사진을 구별하는 Face Detecter를 구현했다.
- Data Augmentation과 전이학습을 통해 모델의 성능을 향상시켰다.
7.2 한계
- 데이터셋 이미지 부족
- 판별의 어려움
 |  |  |
|---|
hard는 사람도 구분이 힘들다.
7.3 요약
본 프로젝트에서는 ResNet18을 기반으로 한 딥러닝 모델을 통해 fake/real 얼굴 이미지를 분류하는 시스템을 구현했습니다. 데이터 증강, 전이학습 등 다양한 기법을 적용했으나, 과적합 문제가 여전히 존재합니다. 향후 프로젝트에서는 더 개선된 정규화 기법 적용, 데이터셋 확장, 모델 구조 최적화 등을 통해 이러한 문제점을 개선하겠습니다.
참고문헌
https://tutorials.pytorch.kr/beginner/basics/data_tutorial.html (파이토치)
https://dacon.io/en/forum/405988 (전이학습)
https://hnsuk.tistory.com/31 (ResNet18)
https://roytravel.tistory.com/149 (정확도 97% 방법)
