-
Canvas-to-Image: Compositional Image Generation with Multimodal Controls
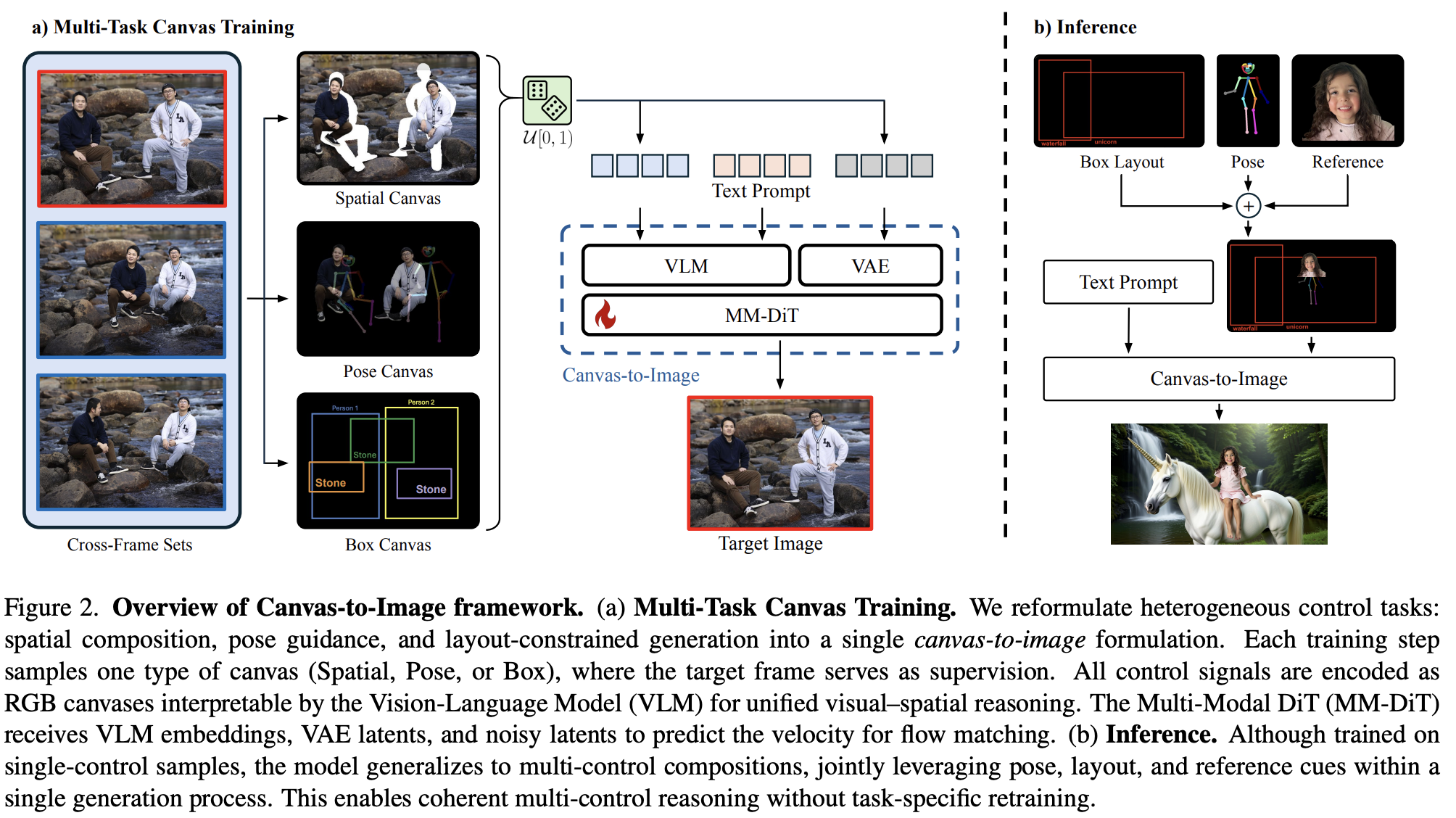
큰 구조는 각 canvas에 대해 (Spatial, Pose, Box) supervision으로 학습하여 inference에서 canvas만 주면 이미지를 생성하도록 한다. 어떻게 보면 아이디어는 간단할 지 모르나 결과물이 놀랍다. Multi-task training이 쉽지 않을 것 같다. 이 논문을 훝으며 MM-DiT가 이미지를 되게 잘뽑네 하는 생각을 했다.
-
Video Generation Models Are Good Latent Reward Models
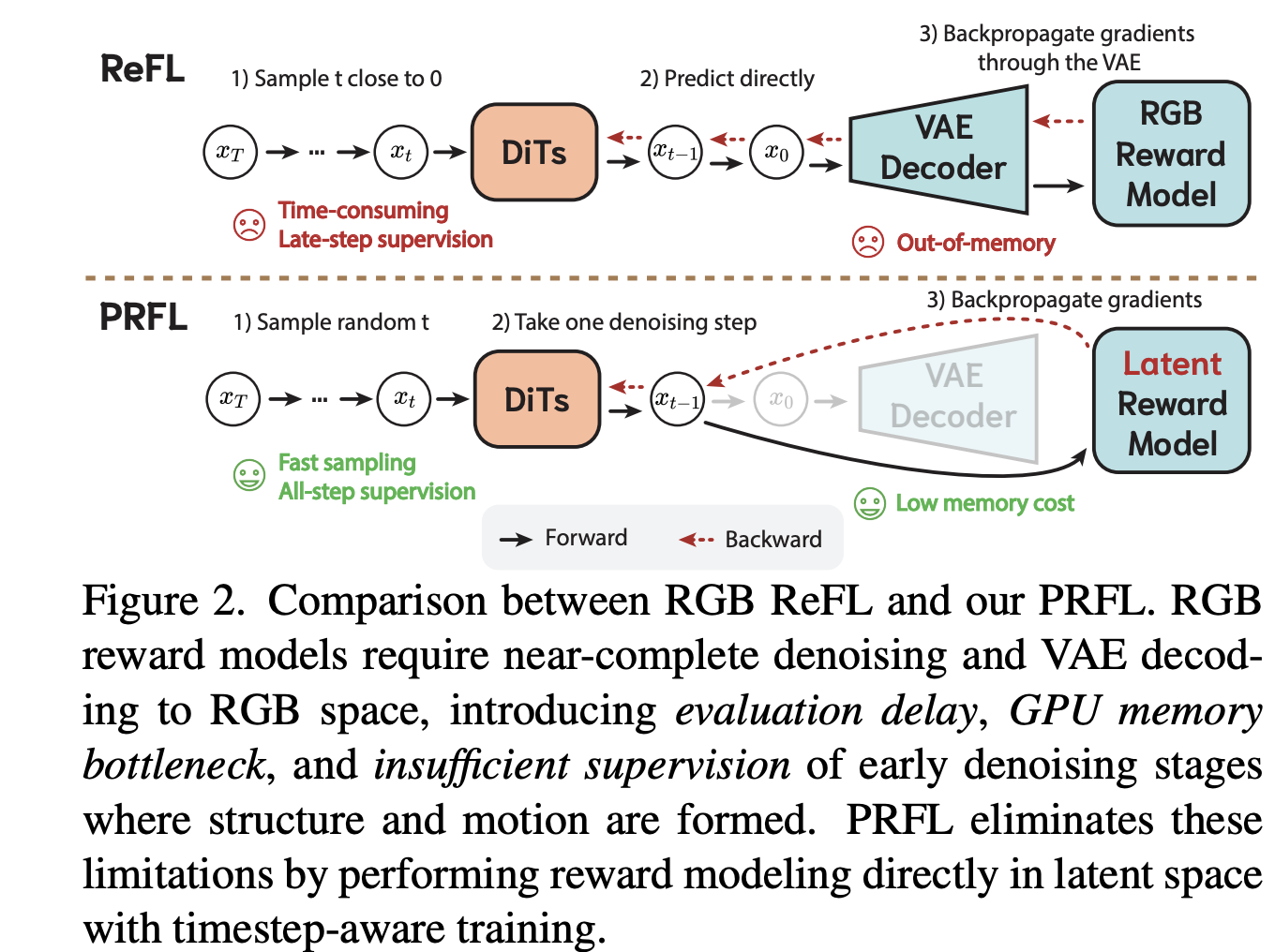
기존의 ReFL은 리워드를(RLHF) 완성된 이미지를 보고 주기 때문에 디퓨전 후반에만 관여할 수 있었다. 해당 모델은 latent 단계에서 이를 주어 정확도를 높이는 전략을 취한다고 한다. 일단 리워드를 기존에 주는 방법은 다음과 같다.

바로 생성된 결과물에 을 VAE 디코더에 넣어 확인하는 것이다. 이에 반해 latent 단계에서 주는 것은 전반적인 수식은 동일하나 x의 입력이 달라진다.
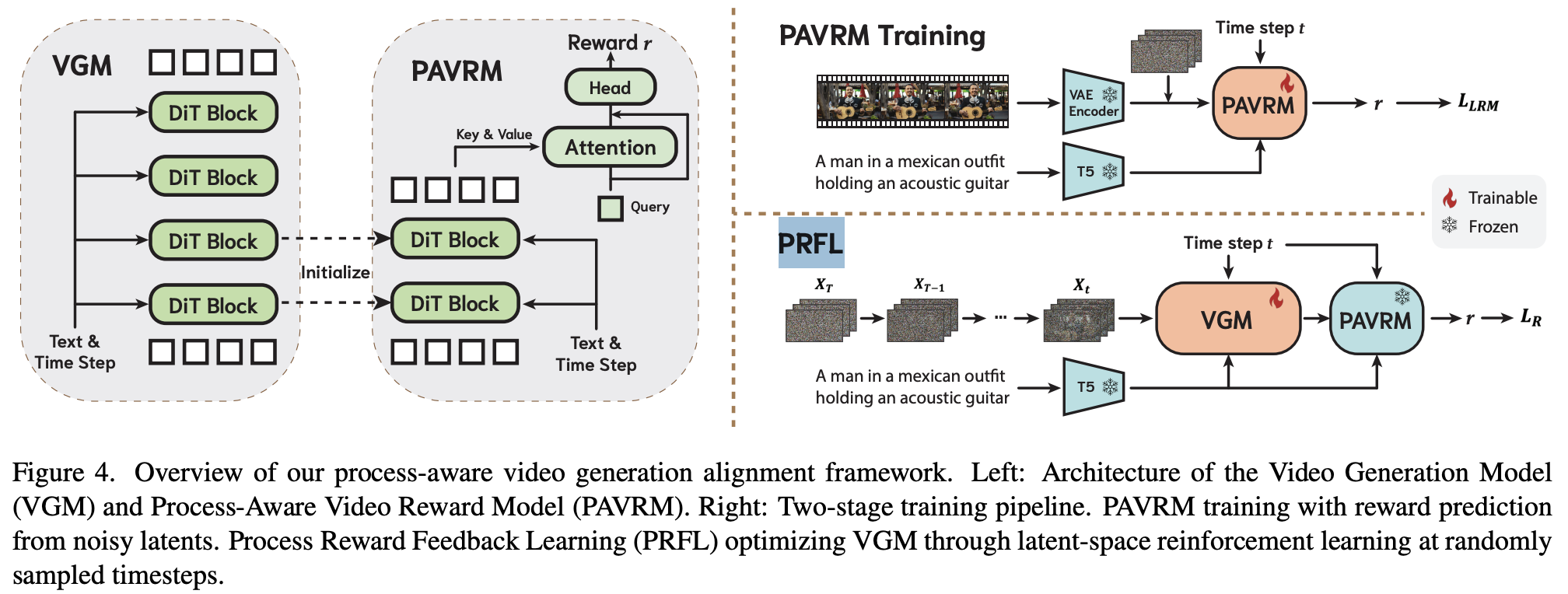
이처럼 latent vecter를 가지고 리워드를 주는 것이다.


공부