Daily report
1.[daily report] 24-02-23

OpenAI is making its own search engine to complete Googleopenai에서 검색엔진을 만든다고 한다. 구글에 대항할 걸 준비한다는데 구글입장에서는 자식한테 뒷통수 맞은 기분이 아닐까..video/ 3DFlashTex: Fast
2.[daily report] 24-02-26
GPT extention LinkedIn, X 같은 개인 social profiles와 연동 되는 것 같다. GeneOH Diffusion: Towards Generalizable Hand-Object Interaction Denoising via Denoising D
3.[Daily report] 24-02-27
Paper MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases MobileNet이 나온게 엊그제 같은데 이젠 LLM도 Mobile로 나온다.
4.[Daily report] 24-02-28
Google Chatbot’s A.I. Images Put People of Color in Nazi-Era Uniforms 구글이 Bard를 Gemini로 변경하고 나서 Chatbot이 이미지까지 처리하게 되었는데 여러 가지 이슈가 있구나 싶다. 이 기사도 그 중
5.[Daily report] 24-02-29

Nvidia Is a Must-Buy. Or Is It? 기사 중간에 나와있는 The Global Race for Computer Chips 표가 잘 정리되어 있어 흥미롭다.https://www.nytimes.com/2024/02/28/technology/o
6.[Daily report] 24-03-04
OpenAI claims New York Times ‘hacked’ ChatGPT to build copyright lawsuit OpenAI와 NewYork Times 간의 저작권 공방이 계속 이어진다. OpenAI가 넘어야 할 저작권 문제가 아직 많이 남은 것 같
7.[Daily report] 24-03-06
issue Paper ✔ Trajectory Consistency Distillation latent의 정확도를 지키기 위해 distillation 방식으로 학습한다. consistency를 지키기 위한 방법. Hugging face 등으로 모델을 공개하고 있는 점
8.[Daily report] 24-03-07
Ex-Google Engineer Charged With Stealing A.I. Secrets for Chinese Firm 지적재산권을 소중히.. 데이터 관리를 열심히.. 왜냐면 뺏기면 슬프니꼐..RT-Sketch: Goal-Conditioned Imitatio
9.[Daily report] 24-03-08
Enhancing Vision-Language Pre-training with Rich Supervisions CVPR2024 accept논문. Vision LLM은 확실한 화두이다. ✔ Backtracing: Retrieving the Cause of the Que
10.[Daily report] 24-03-11
✨Pix2Gif: Motion-Guided Diffusion for GIF Generation MS에서 한 비디오 생성 연구. 비디오 도메인은 아직 모르는 부분이 꽤 있다. ✨StableDrag: Stable Dragging for Point-based Image E
11.[Daily report] 24-03-13
paper ✨Multistep Consistency Models 모델 자체에 대한 논문이 오랜만에 등장. Diffusion model에도 근본있는 논문들이 있는데 그 계보를 따른다. An Image is Worth 1/2 Tokens After Layer 2: Plu
12.[Daily report] 24-03-19
paper ✔Language models scale reliably with over-training and on downstream tasks LLM알못이 봐도 탑티어 논문이다.. ✔Gemma: Open Models Based on Gemini Research an
13.[Daily report] 24-03-21
✨AnimateDiff-Lightning: Cross-Model Diffusion Distillation 비디오 논문. 굉장히 짜임있는 느낌FouriScale: A Frequency Perspective on Training-Free High-Resolution Im
14.[Daily report] 24-03-25
ReNoise: Real Image Inversion Through Iterative Noising inversion과 editing에 대한 논문Efficient Video Diffusion Models via Content-Frame Motion-Latent De
15.[Daily paper] 24-03-26
StreamingT2V: Consistent, Dynamic, and Extendable Long Video Generation from Text Picsart AI에서 쓴 T2V 모델 paper. streaming이 가능하다고 한다.Champ: Controllabl
16.[Daily paper] 24-03-27
DreamLIP: Language-Image Pre-training with Long Captions VLLM(vision LLM)보단 MLLM(multi-modality LLM)이라고 이야기 한다. contrastive learning 방식으로 detail desc
17.[Daily report] 24-03-29
DreamPolisher: Towards High-Quality Text-to-3D Generation via Geometric DiffusionImproving Text-to-Image Consistency via Automatic Prompt Optimization
18.[Daily report] 24-04-01
Amazon scrambles for its place in the AI race Amazon이 Antropic에 지원한다고 한다. MS-OpenAI 구도에 대항하기 위함일까?NYC will test AI gun detectors on the subway 뉴욕시에서
19.[Daily report] 24-04-04
Bigger is not Always Better: Scaling Properties of Latent Diffusion Models diffusion기반 모델이 클수록 성능이 좋아진 것은 맞지만 모든 경우에 적용되는 이야기는 아니라는 것Measuring Style
20.[Daily report] 24-04-05
ReALM: Reference Resolution As Language Modeling Apple에서도 LLM 모델이 나왔다. Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Predi
21.[Daily report] 24-04-08
Introducing Command R+: A Scalable LLM Built for Business cohere에서 command R의 상위 command R+가 공개했다. command R 시리즈는 RAG를 기반으로한 채팅에 중점 되어있는 LLM이다. 기존 R과
22.[Daily report] 24-04-12
https://viggle.ai/ video2video, text2video를 서비스하는 사이트. 디스코드로 베타 버전을 서비스 중이다. 결과가 놀라움 Paper InternLM-XComposer2-4KHD: A Pioneering Large Vision-Langua
23.[Daily report] 24-04-16
COCONut: Crafting the Future of Segmentation Datasets with Exquisite Annotations in the Era of ✨Big Data✨ COCO 업그레이드로 COCONut. CVPR2024에 올라왔다.Dataset
24.[Daily report] 24-04-17
✨Ctrl-Adapter: An Efficient and Versatile Framework for Adapting Diverse Controls to Any Diffusion Model ControlNet의 변형 버전. 일종의 변형된 모델 구조에 다시 adapter
25.[Daily report] 24-04-19
https://aiindex.stanford.edu/report/?utmsource=Nomad+Academy&utmcampaign=ab4e4c9c7f-EMAILCAMPAIGN20240419&utmmedium=email&utmterm=04313d957c9-ab4e4c9c
26.[Daily report] 24-04-22
LLaMA3 말해뭐해 라마3이 나왔으니 무조건 확인해줘야한다. 70B에선 모든 모델 중에 최고성능이라고 한다. 내가 주목하는 것은 7B나 8B성능이다. 사실상 모델 자체를 활용하기에 70, 400B를 쓸 수 있는 곳은 그리 많지 않을 것이다. EdgeFusion: O
27.[Daily report] 24-04-23
✔Groma: Localized Visual Tokenization for Grounding Multimodal Large Language Models MLLM에 대한 논문. tokenizer로 각 박스를 만들고(원하는 영역을 자유롭게 지정) 해당 위치의 이미지를 텍
28.[Daily report] 24-04-25
✨Align Your Steps: Optimizing Sampling Schedules in Diffusion Models diffusion model에서 sampling은 중요하다. 어떤 scheduler로 sampling하냐에 따라 결과 이미지에 차이가 있기 때문
29.[Daily report] 24-04-29
NeRF-XL: Scaling NeRFs with Multiple GPUs NVIDIA에서 나온 NeRF-XL. 제목에서도 볼 수 있듯이 multiple GPU가 핵심이다. ✔ConsistentID: Portrait Generation with Multimodal F
30.[Daily report] 24-04-30
VIDU 칭화대와 공동 연구로 비디오 생성 서비스가 출시되었다. 앵글 전환, 자연스러운 consistency 유지 등 이미지 퀄리티가 좋다. vidu 팀에서 주장하기로는 Sora에 대항할 수 있다고 말한다. 60초 길이로 생성할 수 있으며 모델 구조에 U-ViT가 사
31.[Daily report] 24-05-01
Stylus: Automatic Adapter Selection for Diffusion Models stable diffusion 이후로 뒤에 붙는 adapter가 많이 나왔다. 해당 모델은 상황에 맞게 어떤 adapter를 선택할지 결정해준다. DressCode:
32.[Daily report] 24-05-02
MicroDreamer: Zero-shot 3D Generation in ∼20 Seconds by Score-based Iterative Reconstruction 20초 안에 text/ image로부터 3D를 만들어 준다. 코드 있음Visual Fact Check
33.[Daily report] 24-05-07
☑Paint by Inpaint: Learning to Add Image Objects by Removing Them First editing 논문. 코드는 공개되지 않았다. Automatic Creative Selection with Cross-Modal Match
34.[Daily report] 24-05-09
☑ You Only Cache Once: Decoder-Decoder Architectures for Language Models YOLO 대신에 YOCO 폼미쳤다. decoder-decoder 구조로 되어 있는 LLM이다. self-decoder와 cross-dec
35.[Daily report] 24-05-16
✨Compositional Text-to-Image Generation with Dense Blob Representations ICML2024인 NVIDIA 논문. blob representation을 이용해 각 객체를 제어하는 방식을 사용한다. 예상 외의 것을 생
36.[Daily report] 24-05-23

CUDA 공식 start locally에 새로운 버전(12.4)이 올라왔네요. 완전 안정화된 것은 아니더라도 새 버전으로 교체되고 있나봅니다.✔Reducing Transformer Key-Value Cache Size with Cross-Layer Attention
37.[Daily report] ✨24-05-28
I2VEdit: First-Frame-Guided Video Editing via Image-to-Video Diffusion ModelsImproved Distribution Matching Distillation for Fast Image SynthesisSeman
38.[Daily report] 24-05-31
Matryoshka Multimodal Models 같은 이미지에 대해 단계별로 풍성한 텍스트 description을 생성하는 코드. 일전에 마트료시카라는 이름의 paper를 한 번 봤었는데 관련이 있는 paper인지는 잘 모르겠다. MS research에서 했다.
39.[Daily report] 24-06-05
MOFA-Video: Controllable Image Animation via Generative Motion Field Adaptions in Frozen Image-to-Video Diffusion Model
40.[Daily report] 24-06-07
CamCo: Camera-Controllable 3D-Consistent Image-to-Video Generation NVIDIAI4VGen: Image as Stepping Stone for Text-to-Video Generation Alibaba Guidi
41.[Daily report] 24-06-10
pOps: Photo-Inspired Diffusion Operators editing논문. 흥미로운 것은 edit 방향을 이미지 프롬프트로 준다. 저자 정보가 공개되지 않았다. Step-aware Preference Optimization: Aligning Pref
42.[Daily report] 24-06-11
GenAI Arena: An Open Evaluation Platform for Generative Models 같은 프롬프트를 주고 다르게 생성한 두 모델을 비교하는 플랫폼을 소개한다. voting 시스템 도입으로 사용자들의 선호를 파악하기도 한다. 여기 사이트에서
43.✨[Daily report] 24-06-13
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation VQGAN에서부터 이어지는 LLM 이미지 생성 계보들의 발전의 현주소인가 생각했다. 모델명은 LlamaGen. Margin-aware
44.[Daily report] 24-06-18
An Empirical Study of Mamba-based Language Models NVIDIA에서 나온 논문. Mamba, Mamba2, Hybrid 모델을 서로 비교했다. 직접 다 읽지 못했지만 arXiv Daily말로는 Hybrid 모델은 트포머 성능을 거
45.[Daily report] 24-06-21
Autoregressive Image Generation without Vector Quantization autoregressive 방식의 image generation은 대게 vector-quantized tokens가 필요한데 해당 paper는 각 token별로
46.[Daily report] 24-06-24
Claude 3.5 Frontier intelligence : Claude 3.5 Sonnet은 graduate-level reasoning (GPQA), undergraduate-level knowledge (MMLU), and coding proficiency (H
47.[Daily report] 24-07-03
Aligning Teacher with Student Preferences for Tailored Training Data Generation 확실히 내 요즘 관심사와 세간의 관심사들 중 하나는 knowledge distilation이다. 해당 모델은 Teacher-
48.[Daily report] 24-07-10
MJ-BENCH: Is Your Multimodal Reward Model Really a Good Judge? 텍스트와 이미지간의 상관성, 이미지 자체의 품질, 때론 이미지 간의 상관성까지 평가해야하는데 Multi-modal 모델을 평가하는 것은 결코 쉬운 일이 아
49.[Daily report] 24-07-26
PyTorch 2.4 Release Blog pytorch 2.4가 release되었습니다. Beta에 보면 python 3.12를 기점으로 두고 이전 버전으로는 3.8~3.11을 지원한다고 하네요. 저도 환경설정할 때 기본 python 버전을 3.8이나 3.11을
50.[Daily report] 24-08-05
SAM 2: Segment Anything in Images and Videos OpenAI의 그 SAM이 2가 나왔다. 기존버전에 비해 비디오에서는 3배 정확도, 이미지는 6배 속도 향상이 있다고 한다. 이제 완전히 object detect/seg. 분야는 SAM이
51.[Daily report] 24-08-06
POA: Pre-training Once for Models of All Sizes foundation model을 사용할 때 고려해야할 점 중 하나는 크기이다. 이미지 생성을 해본 사람은 알겠지만 여러 모델을 섞다보면 tensor가 맞지 않아서 오류가 생기는 경우가
52.[Daily report] 24-08-13
Sketch2Scene: Automatic Generation of Interactive 3D Game Scenes from User's Casual Sketches SDXL에 LoRA로 finetuning한 전형적인 방식. 방법론 적으로 크게 놀라운 것이 없지만 이
53.[Daily report] 24-08-15
ControlNeXt: Powerful and Efficient Control for Image and Video Generation ControlNet으로 비디오도 제어할 수 있다. 굉장히 scene간의 consistency가 잘 지켜지는 것이 보인다. LoRA를
54.[Daily report] 24-08-21
TraDiffusion: Trajectory-Based Training-Free Image Generation diffusion 모델로 이미지를 생성할 때 조건을 제어하는 방법은 두 가지가 있다. 하나는 adapter 등을 추가하는 것이고 다른 하나는 latent v
55.[Daily report] 24-08-22
Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model 예전부터 이런 모델이 나왔으면 좋겠다 싶었는데 나왔다. Transformer + diffusion이 한번에 하나의 모델이
56.[Daily report] 24-09-03
CURLoRA: Stable LLM Continual Fine-Tuning and Catastrophic Forgetting Mitigation LoRA의 파생 모델. (CUR matrix decomposition)https://en.wikipedia.org
57.[Daily report] 24-09-20
GRIN: GRadient-INformed MoE Microsoft에서 새로운 MoE 모델을 내놓았다. 기존의 MoE는 각 expert를 학습할 때 딥러닝 방식을 사용하는게 일반적인데 해당 모델은 autoregressive language model을 사용한다고 한다
58.[Daily report] 24-10-16
Cavia: Camera-controllable Multi-view Video Diffusion with View-Integrated Attention 비디오에서 카메라 view를 조정하는 논문. 내가 보기엔 CameraCtrl의 결과랑 비교해서 엄청 유의미한 발전을
59.[Daily report] 24-10-17
What Matters in Transformers? Not All Attention is Needed 기존의 LLM에 대한 구조적 문제점을 제기하고 Block drop 방식을 실험으로 보여준다. Block drop은 일종의 drop out 기법으로, transfor
60.[Daily report] 24-10-22
MagicTailor: Component-Controllable Personalization in Text-to-Image Diffusion Models 이미지의 component별로 control 할 수 있는 모델. 내가 선택한 component들로 하나의 이미지를
61.[Daily report] 25-08-06
Hybrid Global-Local Representation with Augmented Spatial Guidance for Zero-Shot Referring Image Segmentation
62.[Daily report] 25-08-18
D2F: Diffusion LLMs Can Do Faster-Than-AR Inference via Discrete Diffusion Forcing기존 LLM보다 처리속도를 줄인 모델. 정리를 잘해놓았다. 기존 LLM이 연산 시간이 오래 걸리는 이유는 크게 2가지로 첫
63.[Daily report] 25-08-20
SSRL: SELF-SEARCH REINFORCEMENT LEARNING 칭화대, 상하이AI랩, 런던대 등 다수의 저자진이 연구했다. 스스로 검색을 통해 (Bing, wikipidia, google 등) policy 모델을 업데이트 한다는 방법을 제시한 연구이다.(퍼
64.[Daily report] 25-10-20
WithAnyone: Towards Controllable and ID-Consistent Image Generation모델 자체엔 엄청 특이하거나 특별하게 느껴지는 새로운 구조는 없다. 다만 데이터셋 수집 방법이나, 이걸 진짜 다? 싶을 정도로 짜임새가 좋다. 뭔가
65.[Daily report] 25-11-03

★ThinkMorph:Emergent Properties in Multimodal Interleaved Chain-of-Thought Reasoning 텍스트와 이미지의 chain of thought을 합쳐서 보는 것이 아닌 상호 보완적으로 보는 것이 핵심. Ques
66.[Daily report] 25-11-12
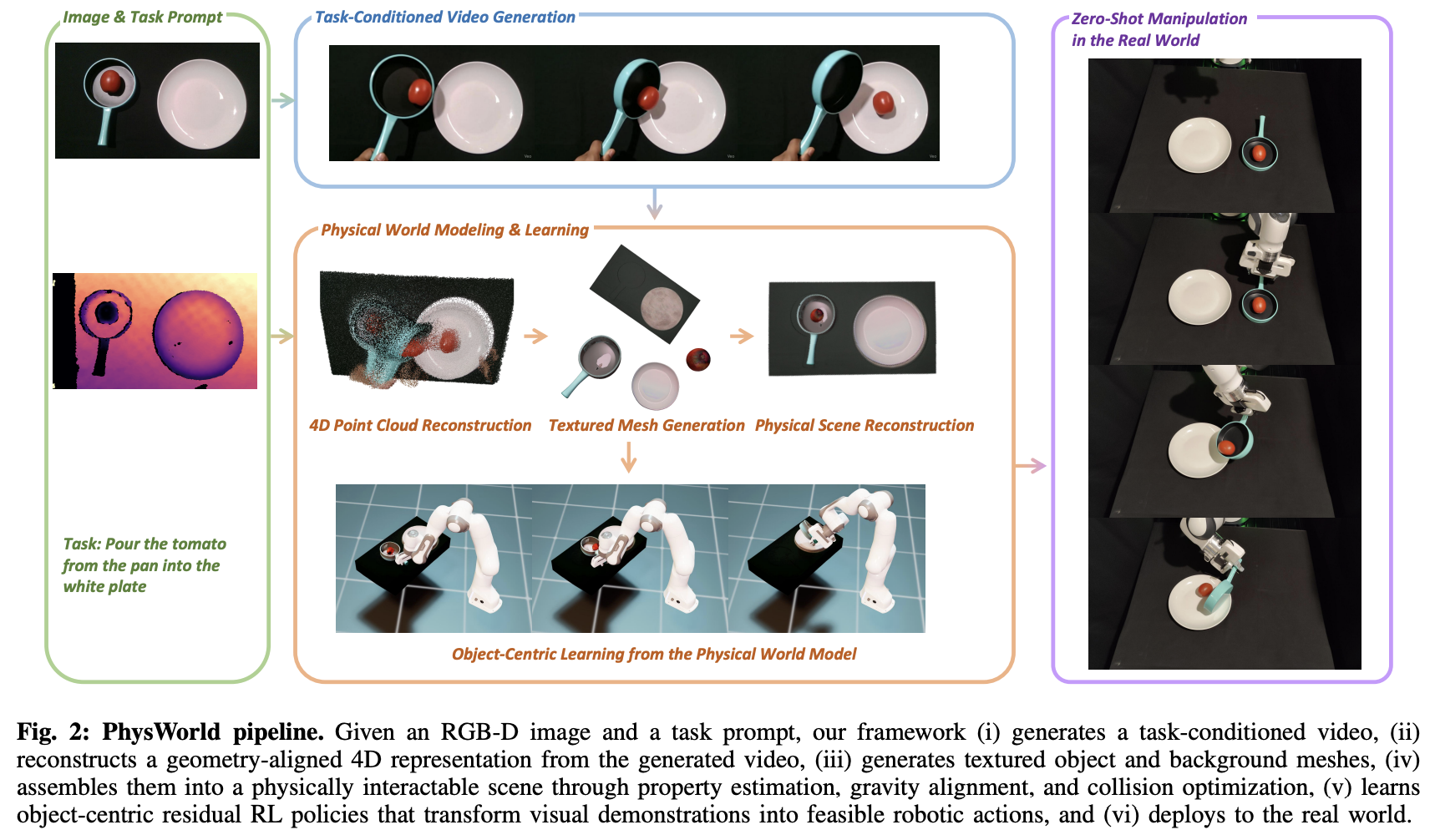
Robot Learning from a Physical World Model 비디오를 따라 zero-shot으로 로봇의 움직임을 만드는 연구. 기존의 비디오 관련 로봇 연구는 많은 데이터가 필요하거나 사람의 개입이 필수적이었는데 이를 최소화하여 zero-shot으로
67.[Daily report] 25-11-14
Time-to-Move: Training-Free Motion Controlled Video Generation via Dual-Clock Denoising Nvidia 논문. 결과물을 보고 육성으로 "미친 거 아니야?"라고 했다. 왜냐면 training free라고
68.[Daily report] 25-12-02
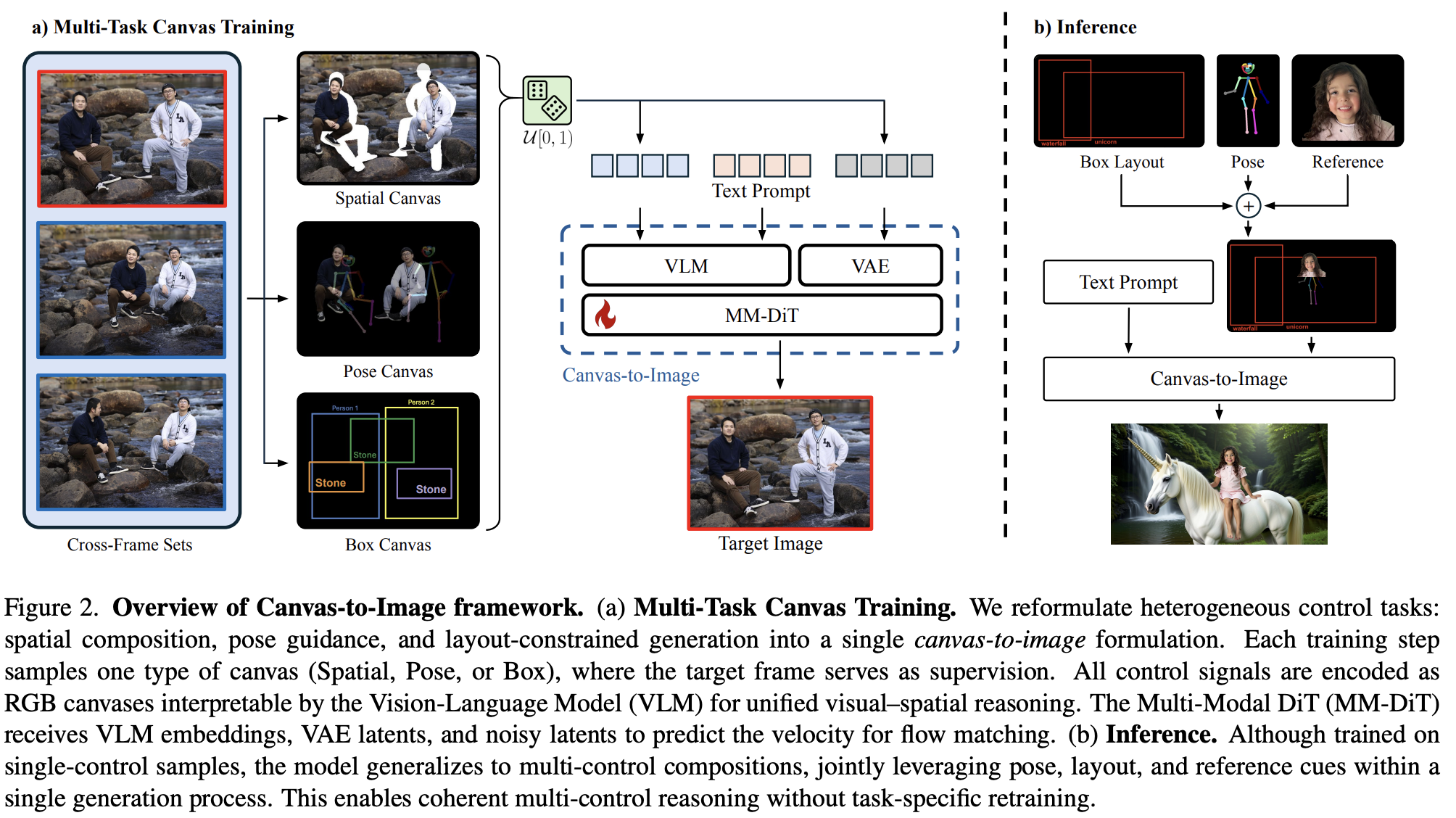
Canvas-to-Image: Compositional Image Generation with Multimodal Controls 큰 구조는 각 canvas에 대해 (Spatial, Pose, Box) supervision으로 학습하여 inference에서 can
69.[Daily report] 26-05-26
LongLive-2.0: An NVFP4 Parallel Infrastructure for Long Video Generation 이 논문이 언급하고 있는 주요점은 크게 3가지로 나눌 수 있다. NVFP4 연산 4비트로 데이터가 표현되기 때문에 기존의