[친절한 SQL 튜닝]1.3 I/O 메커니즘 - Single Block I/O, Multi Block I/O, Table Full Scan, Index Range Scan
친절한 SQL 튜닝
목록 보기
6/13

Single Block I/O vs Multi Block I/O
- I/O Call : 디스크에 데이터를 읽거나 쓰기 위해 발생한 호출 - 물리적 I/O 수행
- 캐시에서 찾지 못한 블록은 I/O Call을 통해 디스크에서 DB버퍼캐시로 적재한 뒤 읽는다.
Single Block I/O
- I/O Call을 할 때, 한 번에 한 블록씩 요청해 메모리에 적재하는 방식
Multi Block I/O
- I/O Call을 할 때, 한 번에 여러 블록씩 요청에 메모리에 적재하는 방식
- 캐시에서 찾지 못한 특정 블록을 디스크 상에서
해당 블록과 인접한 블록들을 한꺼번에 읽어 캐시에 미리 적재하는 기능- ‘인접한 블록’은 같은 익스텐트에 속한 블록을 의미
- 즉, Multiblock I/O로 데이터 블록을 읽더라도 익스텐트의 경계를 넘어 읽어오진 못한다!
(Multiblock I/O 중간에 Single Block I/O가 나타나는 이유다)
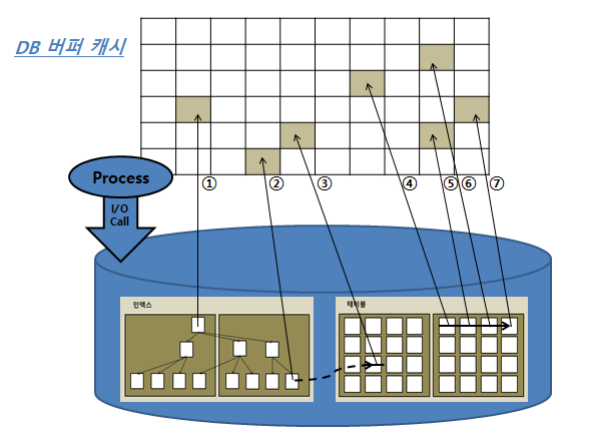
1,2,3는 Single Block I/O,4,5,6,7은 Multiblock I/O- 인덱스는 소량 데이터를 읽을 때 주로 사용하므로,
인덱스를 이용할 때는 인덱스와 테이블 블록 모두 Single Block I/O 방식을 사용한다. - 많은 데이터 블록을 읽을 때는 Multi Block I/O 방식을 사용하며,
인덱스를 이용하지 않고 테이블 전체를 스캔할 때(Full Scan) 이 방식을 사용한다.
I/O Call과 프로세스의 상태, Multiblock I/O 단위
- I/O Call을 요청한 프로세스는 대기 큐에서 잠을 잔다 - Wait 상태
그런데 바쁘게 일해야 할 프로세스가 자주 잠을 자면 손해가 이만 저만 아니다! - 읽어야 할 데이터 블록은 많은데, 한번에 읽어오는 데이터 블록의 단위가 작다면
프로세스는 그만큼 자주 잠을 자게된다. - 따라서 읽어야 할 데이터 블록이 많은 대용량 테이블을 Full Scan할 때,
Multiblock I/O 단위를 크게 설정하면 성능을 향상시킬 수 있다. - 즉, 기왕 잠을 자려면 한번에 많은 양을 요청하고 잠자는 횟수를 줄여 성능을 향상시킨다.
Table Full Scan vs Index Range Scan
- 테이블에 저장된 데이터를 읽는 방법은 두 가지다. - Table Full Scan, Index Range Scan
- 앞서 살펴본 Single Block I/O와 Multiblock I/O 방식을 이해하면
Table Full Scan의 경우Multiblock I/O방식으로 데이터 블록을 요청하고
Index Range Scan의 경우Single Block I/O방식으로 데이터 블록을 요청하는 것이
더 효율적이고 적절하다는 것을 알 수 있다.
Table Full Scan
- 테이블(에 속한 블록) 전체를 스캔해 데이터를 읽는 방식
Index Range Scan
- 인덱스를 이용해 데이터를 읽는 방식
- 인덱스에서 ‘일정량’을 스캔하면서 얻은
ROWID로 테이블 레코드를 찾아가는 방식
✨ ROWID : DBA + 블록 내 로우 번호, 테이블 레코드가 디스크 상에 어디 저장됐는지 가리키는 위치 정보
🫧 인덱스에 대한 오해와 진실
- 인덱스는 데이터를 빠르게 찾기 위해 사용하는 특별한 자료구조이다.
- 그럼 어떤 데이터이든 무조건 인덱스를 사용해 데이터를 읽는게 좋을까? ❌
- 모든 레코드를 액세스할 때, Index Range Scan보다 Full Scan이 훨씬 효율적일 수 있다!
Table Full Scan은 피해야 한다는 많은 개발자의 인식과 달리
인덱스가 SQL 성능을 떨어뜨리는 경우도 상당히 많다.
-
Table Full Scan: 시퀀셜 액세스, Multiblock I/O
즉, 한 번의 수면으로 인접한 수십~수백개 블록을 한꺼번에 I/O하는 메커니즘 -
Index Range Scan: 랜덤 액세스, Single Block I/O
캐시에서 블록을 못찾으면, 레코드 하나를 읽기 위해 매번 잡을 자는 I/O 메커니즘
| 구분 | Table Full Scan | Index Range Scan |
|---|---|---|
| 장점 | 많은 양의 데이터 처리에 빠름 병렬 처리 적합 | 소량의 데이터 빠르게 접근 불필요한 블록 읽기 없음 |
| 단점 | 모든 블록 읽음 → 부담 클 수 있음 필요 없는 데이터도 읽음 | 많은 건수를 처리하면 I/O 폭증 반복 블록 접근 시 느림 |
| 유리한 경우 | 조건이 없어 전 건 조회 WHERE 조건이 선택도 낮음 (대부분 해당) 함수 조건, 인덱스 무효 병렬 쿼리 | WHERE 조건이 잘 인덱스 타는 경우 데이터 소량 조회 정렬, 조인 키 조건에 적합한 인덱스 존재 |
| 불리한 경우 | 행 소수만 조회할 때 비효율적 큰 테이블인데 조건이 명확한 경우 | 대량 조회 시 비효율 (많은 논리적 I/O) 캐시 경합 가능성 ↑ |
예시를 통해 좀 더 이해해보자면
- 테이블에 100만개의 레코드가 있다고 가정
- 한 블록에 평균 500개의 레코드가 저장
- 그럼 이 테이블은 약 2000개의 블록으로 구성됨
이때,
📍 Table Full Scan
- 모든 레코드를 가져오기 위해 블록 2000개를 딱 1번씩만 읽으면 끝!
📍 Index Range Scan(인덱스로 모든 레코드 접근)
- 인덱스에서 레코드 위치를 하나하나 찾아서
해당 블록으로 가 1개의 레코드만 읽고 다음 인덱스로 이동 - 다음에 읽은 레코드가 이전 블록과 동일한 블록에 속한다면?
같은 블록을 여러 번 반복에서 읽게 됨
정리하자면,
- Table Full Scan은 대량 데이터 조회에 유리
- Index Range Scan은 소량 데이터 조회에 유리

"개발자는 해결사이자 발견자이다✨" - Michael C. Feathers