
논리적 I/O vs 물리적 I/O
DB 버퍼캐시
- 결론적으로 디스크 I/O가 SQL 성능을 결정한다.
- 따라서 SQL을 수행하는 과정에서 데이터 블록을 액세스할 때,
자주 읽는 블록을 매번 디스크에서 읽는 것은 비효율적이다. - 데이터 캐싱 메커니즘 필요 이유

Library Cache: SQL, 실행계획, DB 저장형 함수/프로시저 캐싱 - 코드 캐시DB Buffer Cache: 데이터를 캐싱 - 데이터 캐시- DB 버퍼 캐시의 목적: 디스크에서 어렵게 읽은 데이터 블록을 캐싱해 해당 블록에 대한 I/O Call을 감소
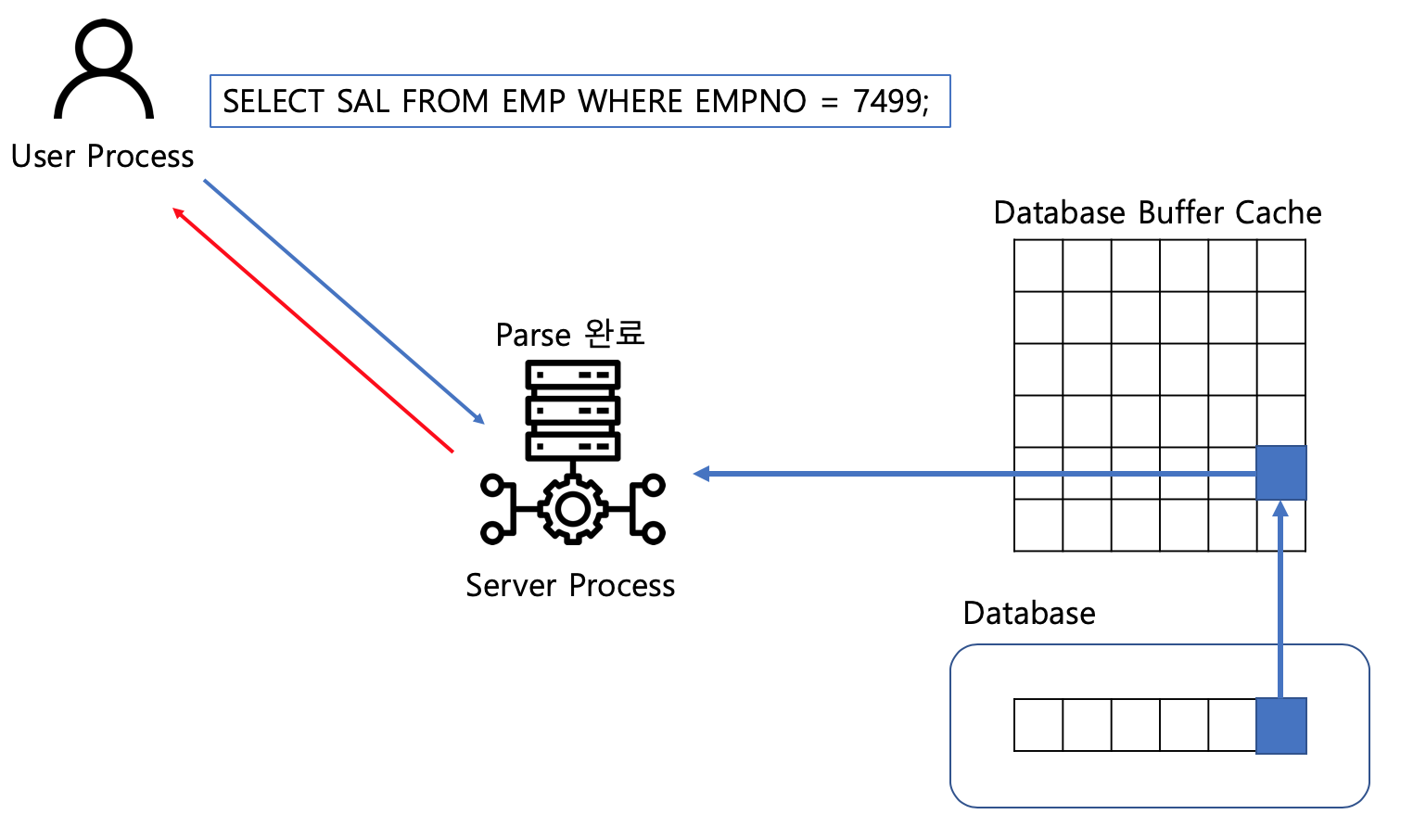
- 버퍼캐시는 서버 프로세스와 데이터파일 중간에 존재해,
모든 데이터 블록에 액세스 할 때 반드시 버퍼 캐시를 경유한다 - ❗Direct Path I/O는 예외 - 캐시 미스인 경우 디스크에서 데이터 블록을 읽어 버퍼 캐시에 적재하고,
버퍼 캐시는 공유 메모리 영역이므로 같은 블록을 읽는 다른 프로세스에게도 이득이다!
✨ Direct Path I/O : 데이터 액세스 시 DB 캐시를 거치지 않고 곧바로 데이터 블록을 읽고 쓸 수 있는 기능
논리적 I/O
- SQL을 처리하는 과정에 발생한 총 블록 I/O, 메모리 I/O가 곧 논리적 I/O, 전기적 신호
- 논리적 I/O 횟수는 일반적으로 DB 버퍼캐시에서 블록을 읽은 횟수와 일치
- 메모리(DB 버퍼캐시)에 읽는 블록을 읽는 작업
물리적 I/O
- 디스크에서 발생한 총 블록 I/O, 액세스 암(Arm)을 통한 물리적 작용 발생(❗느리다)
- DB 버퍼캐시에서 블록을 찾지 못해 디스크에서 읽은 블록 I/O
- 디스크에서 블록을 읽어와 메모리(DB 버퍼캐시)에 올리는 작업
- 물리적 I/O의 경우 디스크 경합이 심한 경우에는 훨씬 더 느려진다.
✨ 디스크 경합: 여러 프로세스나 세션이 동시에 같은 디스크 장치나 파일에 접근하는 경우 발생
🍀 물리적 I/O의 횟수와 캐싱 :
- 데이터 입력이나 삭제가 없어도 물리적 I/O는 SQL을 실행할 때마다 다르다.
(같은 SQL이라도 캐시 상태에 따라 다르게 동작한다.) - SQL을 연속적으로 실행하면 DB 버퍼캐시에서 해당 테이블 블록의 점유율이 높아지기 때문이다.
(버퍼캐시에 캐싱될 수록 물리적 I/O가 줄어든다.) - 버퍼캐시는 공간 부족 시 삭제되고 다른 블록으로 채워지므로, 한참 뒤에 실행하면 물리적 I/O가 늘어난다.
🍀 물리적 I/O는 논리적I/O와 포함관계다 :
- SQL 처리 도중 읽어야 할 블록을 버퍼캐시에서 찾지 못할 때만 디스크를 액세스하므로
논리적 블록 I/O 중 일부를 물리적으로 I/O한다.
버퍼 캐시 히트율(BCHR)과 SQL 튜닝 - 논리적 I/O 줄이기
- 버퍼 캐시 히트율(
BCHR)은 찾는 데이터가 캐시에 있을 확율을 의미한다. - 즉,
BCHR은 읽은 전체 블록 중 물리적 I/O를 수반하지 않고 메모리에서 찾은 비율을 나타낸다.
BCHR = (캐시에서 곧바로 찾은 블록 수 / 총 읽은 블록 수) * 100
= ((논리적 I/O - 물리적 I/O) / 논리적 I/O) * 100
= (1 - (물리적 I/O) / (논리적 I/O)) * 100버퍼 캐시 히트율 공식에서 알 수 있는 SQL 튜닝 원리
BCHR 공식에서 우리는 중요한 성능 원리를 발견할 수 있다.
물리적 I/O가 성능을 결정하지만, 실제 SQL 성능을 향상하려면
물리적 I/O가 아닌 논리적 I/O를 줄여야 한다는 사실이다.
물리적 I/O = 논리적 I/O * (100% - BCHR)- 논리적 I/O는 일정하므로 물리적 I/O는
BCHR에 의해 결정된다. - 즉,
BCHR이 높을수록(캐시 히트가 많을 수록) 물리적 I/O는 줄어들고
BCHR이 낮을수록(캐시 미스가 많을 수록) 물리적 I/O는 늘어난다.
논리적 I/O가 왜 성능에 영향을 주는데?
- 논리적 I/O도 메모리 리소스를 소모한다.
- 블록 1개를 읽는 것도 Latch를 걸고, 탐색하고, 필터링하고 ..
읽어야 할 블록이 n개면 n번 반복해야 한다.
- Multi Block 논리적 I/O = 더 많은 버퍼 탐색 + 처리 시간 증가
- Full Scan은 연속된 블록을 읽지만,
실제로는 정렬, JOIN, 필터링까지 들어가면 CPU와 메모리를 엄청나게 소모한다.
- SQL 튜닝없이 논리적 I/O가 많으면 병목이 쌓인다.
- 캐시가 꽉 차면 다른 세션 캐시를 밀어냄 →
BCHR낮아짐 → 물리적 I/O 증가로 이어진다.
성능 향상을 위해 결국은 논리적 I/O를 줄여야 한다고?
📍 1. Full Scan
SELECT * FROM ORDERS WHERE TO_CHAR(order_date, 'YYYYMM') = '202304';📍 2. Index Range Scan
SELECT * FROM ORDERS WHERE order_date
BETWEEN TO_DATE('2023-04-01') AND TO_DATE('2023-04-30')1 의 경우, Full Scan으로 논리적 I/O가 수천 ~ 수만번 발생할 수 있지만
2 의 경우, Index Range Scan으로 논리적 I/O가 수십번만 발생한다.
둘 다 캐시에서 처리되서 물리적 I/O는 0번(디스크 액세스❌)일 수 있으나
1 번 쿼리는 불필요한 블록을 많이 읽고, 반복된 논리적 I/O를 많이 수행해
실제 응답 속도는 수십 배 차이날 수 있다.
즉, 논리적 I/O를 줄여 실제 성능도 향상된 사례로 볼 수 있다.
좀 더 자세히 설명해줘 GPT야 ..!
쿼리를 다시 보자
📍 1. Full Scan
SELECT * FROM ORDERS WHERE TO_CHAR(order_date, 'YYYYMM') = '202304';1번 쿼리의 경우TO_CHAR(order_date, 'YYYYMM')로 인해 인덱스가 무효화된다.- 왜? Oracle의 경우, 함수 조건이 있는 컬럼엔 인덱스를 사용하지 못하기 때문이다.
(이 경우 인덱스가 있어도 무시하고ORDERS테이블 전체를 스캔한다.)- 즉, 컬럼에 연산이나 함수가 걸려 있으면 기존 인덱스를 사용하지 못한다.
TO_CHAR(order_date, ‘YYYYMM’)는order_date컬럼에TO_CHAR()함수가 적용- Oracle 옵티마이저는 함수가 적용된 컬럼은 인덱스에 있는 원본 값과 비교할 수 없기 때문에,
함수가 적용된 컬럼에는 인덱스를 사용하지 않는다 - Full Scan으로 실행된다.
- 결과적으로 :
- 테이블 블록 전체를 순차적으로 읽으면서 논리적 I/O가 수천~수만건 발생 가능
- 캐시 히트율이 높아도, 메모리에서 반복적으로 읽는 비용이 큼
- ✨ 블록은 연속적으로 캐시되지만,
쿼리가 조건에 따라 동일 블록의 특정 행만 골라야 한다면
해당 블록을 여러 번 참조하게 됨 - 논리적 I/O 계속 발생
- ✨ 블록은 연속적으로 캐시되지만,
- CPU 사용, 버퍼 탐색 비용, Latch 횟수, Context Switch 등 모두 증가
- 다른 세션과 버퍼 캐시 경합 발생 가능성
여기서 알 수 있는 사실 - 인덱스를 사용하기 위해서는 컬럼을 가공해서는 안된다!
- 위에서 말했다싶이 컬럼이 있는 그대로 쓰이지 않고 가공되어 있으면, 일반 인덱스는 사용할 수 없다.
- 따라서 함수 기반 인덱스(Function-Based Index)를 생성하거나,
SQL 조건문에서 함수를 제거하고 컬럼 원형을 그대로 사용해야 한다.
📍 2. Index Range Scan
SELECT * FROM ORDERS WHERE order_date
BETWEEN TO_DATE('2023-04-01') AND TO_DATE('2023-04-30')2번 쿼리의 경우 조건문에서 함수를 제거하고 컬럼 원형을 그대로 사용한 예시이다.BETWEEN구문은 인덱스를 그대로 활용 가능하다.- 예를 들어,
order_date에 인덱스가 있다면 해당 범위에 해당하는 인덱스 리프 블록만 순회하고
각 인덱스 엔트리가 가리키는ROWID를 따라가서 필요한 데이터만 읽는다.
정리하자면,
| 항목 | 설명 |
|---|---|
| 캐시 히트 | 디스크 I/O는 없음 → 성능에 유리 |
| 논리적 I/O | 메모리 블록을 읽는 횟수, 같은 블록도 여러 번 읽게 되면 횟수는 누적됨 |
| 반복 I/O | 쿼리 조건이나 인덱스 탐색 로직에 따라 같은 블록을 계속 참조하게 되면 발생 |
🚀 SQL 튜닝의 핵심
- SQL을 튜닝해 총 읽는 블록 개수를 줄인다.
- 즉, 핵심은 필요한 블록만 최소한으로 읽게 하는 것이다.
- 이는 논리적 I/O를 줄임으로써 물리적 I/O를 줄이는 것을 의미한다.

"개발자는 해결사이자 발견자이다✨" - Michael C. Feathers