1️⃣ 프로젝트 요약
LangChain, OpenAI ChatGPT, 그리고 Streamlit을 활용하여 문서 기반 질의응답 챗봇을 만들어보았다.
사용자는 PDF, DOCX, TXT 문서를 업로드하고 자연어로 질문하면,
해당 문서를 기반으로 LLM이 답변을 생성해주는 구조이다.
2️⃣ 사용 기술 스택
- LangChain: 문서 로딩, 분할, 임베딩 및 RAG 구성
- OpenAI ChatGPT: 답변 생성 (GPT-4o-mini 사용)
- Streamlit: 웹 UI 구현
3️⃣ 주요 구현 요소
3.1 문서 처리 및 임베딩 생성
UnstructuredFileLoader로 다양한 문서 형식(PDF, DOCX, TXT) 지원RecursiveCharacterTextSplitter:chunk_size=1000,chunk_overlap=200text-embedding-3-small모델로 임베딩 생성CacheBackedEmbeddings로 중복 임베딩 방지 및 속도 개선
3.2 벡터 DB 및 검색기
- FAISS로 벡터 저장 및 검색
- MMR (Maximum Marginal Relevance) 검색: 관련성 + 다양성 모두 고려
- BM25Retriever: 키워드 기반 검색 추가
- EnsembleRetriever: 벡터 + 키워드 기반 앙상블
3.3 프롬프트 설계 및 LLM 연결
- 시스템 프롬프트:
- 문서 기반 답변
- "모르면 모른다" 안내
- 문서 분석 전문가 페르소나
- LangChain
Runnable로 체인 구성 ChatCallbackHandler로 LLM의 실시간 응답 스트리밍 구현
3.4 사용자 인터페이스 (Streamlit)
- 파일 업로드 UI (사이드바)
- 대화형 채팅창 구현
- 세션 기반 채팅 기록 저장
- 문서 임베딩 및 처리 결과 캐싱
4️⃣ 테스트 및 결과 분석
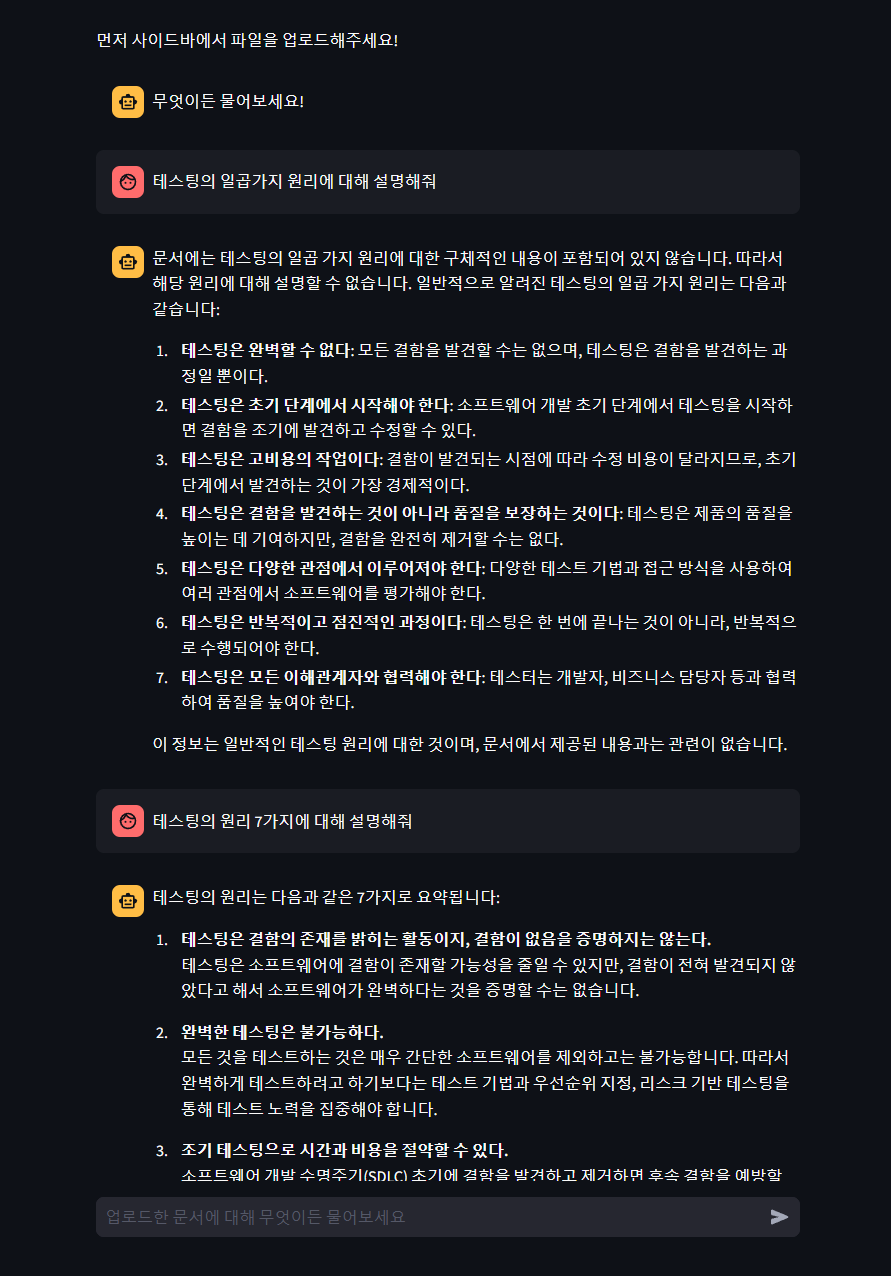
테스트 인사이트
비슷해 보이는 두 질문에 대해 LLM은 서로 다른 응답을 생성했다.
이는 질문 표현 방식에 따라 LLM이 사전 학습된 지식에 기반해 답변하거나,
외부 문서에서 실제 정보를 검색해 답하는 차이 때문이다.
👉 표현 방식 하나만 달라도 결과가 확 달라질 수 있음.
5️⃣ LangSmith로 로깅 분석
LangSmith는 LLM 실행 로그를 추적하여
"어떤 질문이 어떤 문맥을 불러왔는지" 확인하는 데 유용하다.
첫 번째 질문
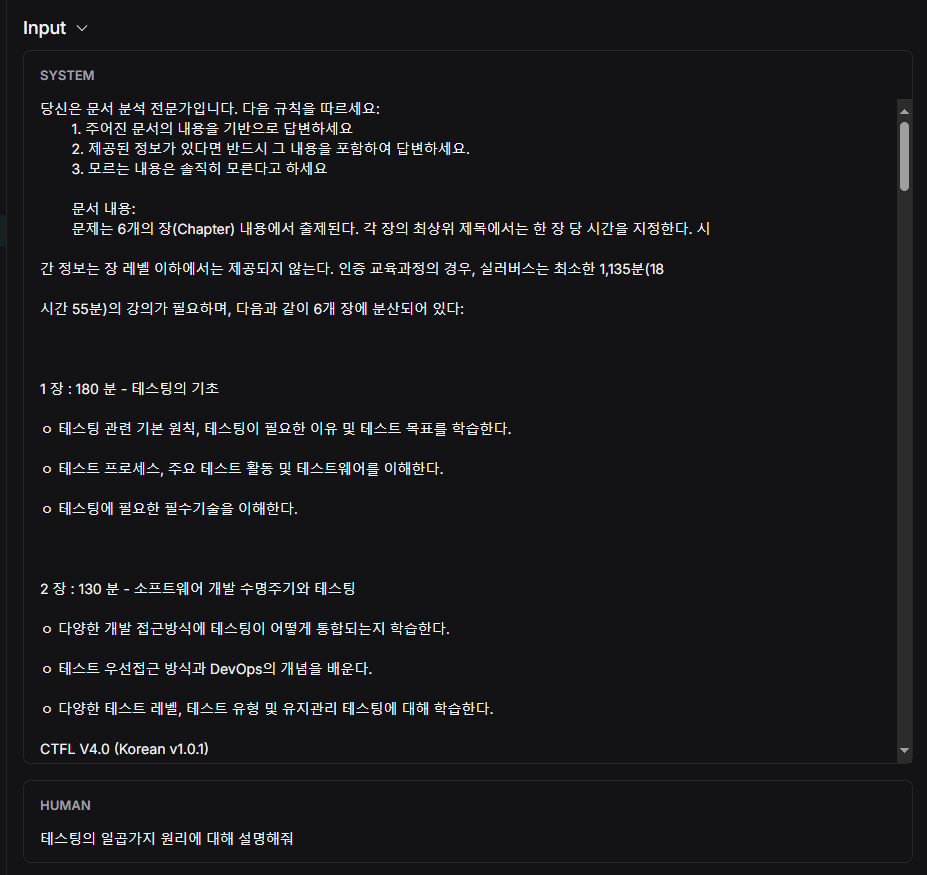
→ 관련 Context를 찾지 못함 → 사전 지식 기반 답변
두 번째 질문
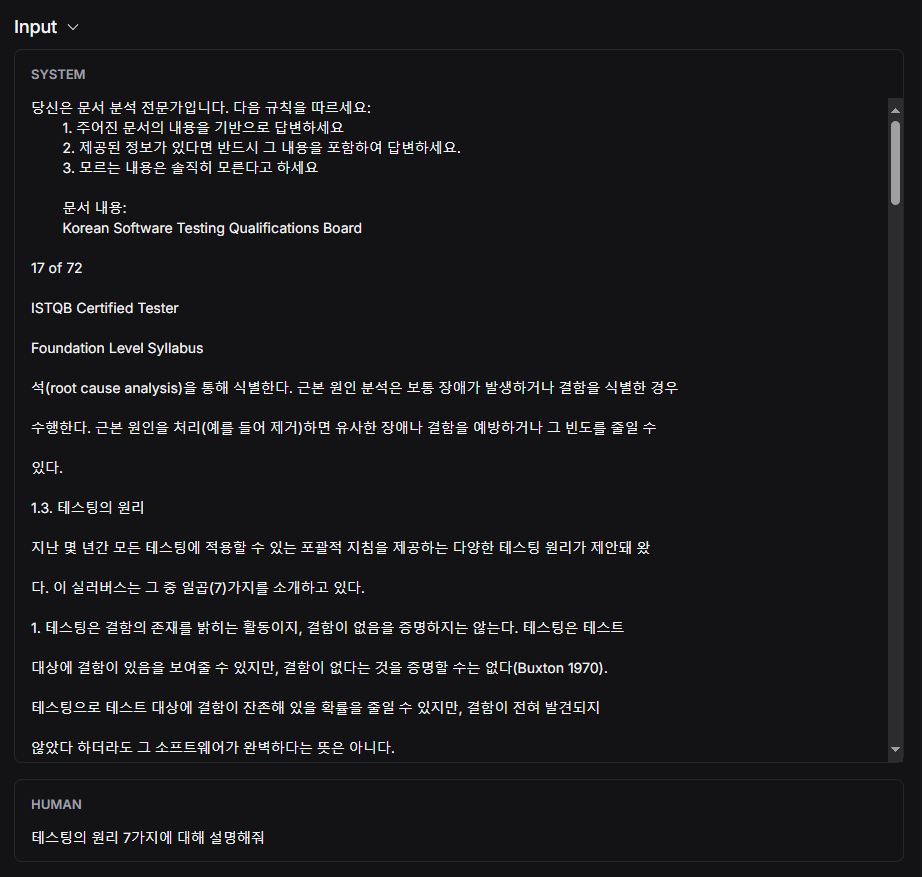
→ 문서 내 관련 정보를 정확히 검색해 context로 활용함
전체 코드
최종 정리
- 문서 기반 챗봇은 표현 방식, 검색기 종류, 프롬프트 설계에 민감하다.
- 캐싱, 스트리밍, 하이브리드 검색을 통해 실제 사용 가능한 성능과 UX를 끌어올릴 수 있다.
- LangSmith는 RAG 디버깅과 정확도 향상에 매우 유용한 도구다.
