RAG, 파인튜닝, 그리고 RAFT와 RAG 2.0까지 한눈에 정리
RAG란?
LLM은 사전에 학습된 데이터에 대한 응답은 뛰어나지만,
특정 도메인 질문이나 환각(hallucination) 문제에 취약하다.
이런 한계를 극복하기 위해 등장한 개념이 바로 RAG(Retrieval-Augmented Generation)이다.
2020년 논문
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks 에서 처음 등장했다.
RAG는 LLM에게 외부 데이터를 주고, 그 데이터를 참고해 응답을 생성하도록 유도하는 구조다.
RAG의 3단계 구조
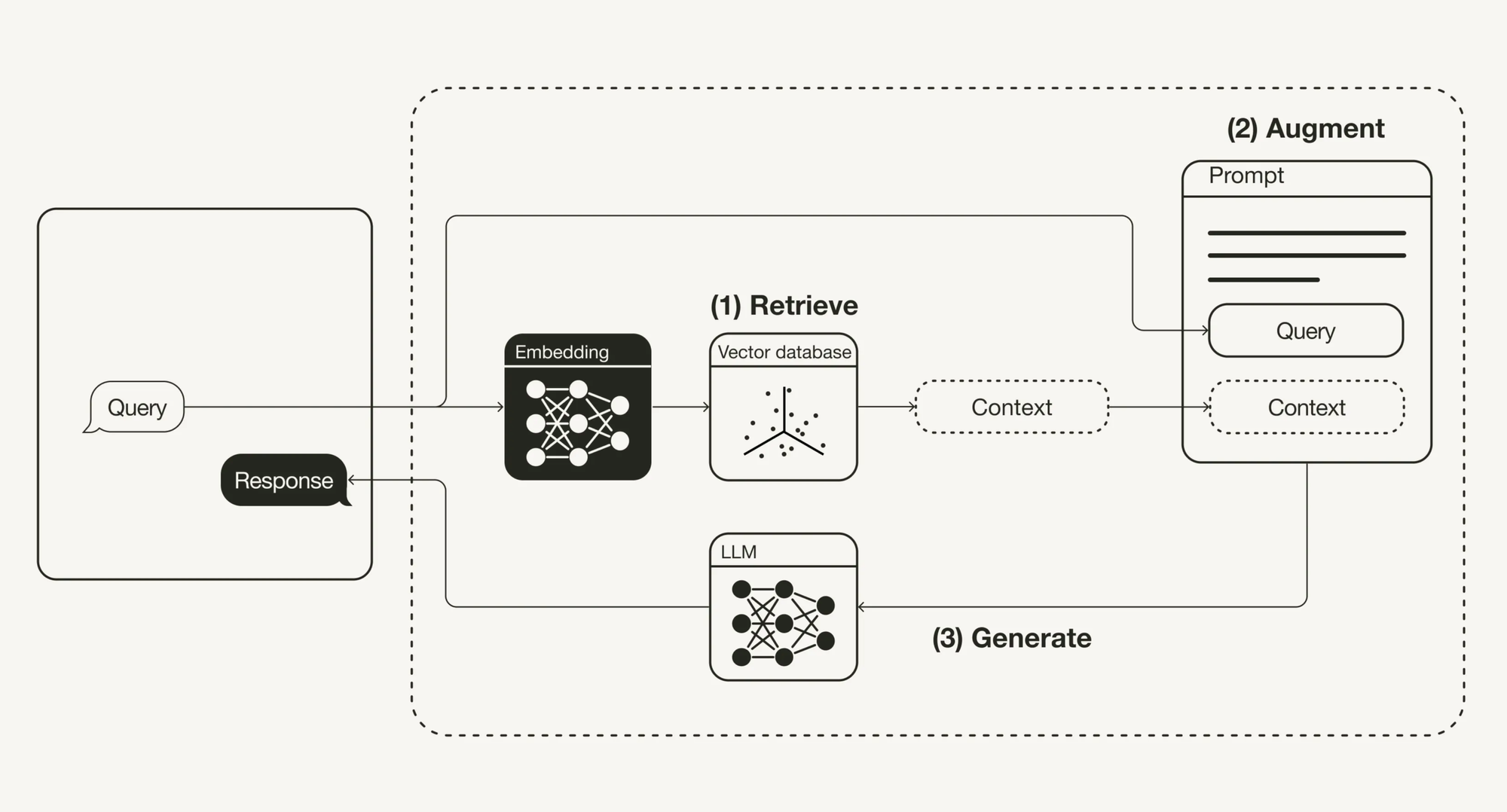
-
Retrieve (검색)
- 사용자의 Query와 관련된 문서를 vector DB에서 검색
- 이때 문서는 임베딩되어 저장되어 있음
-
Augment (증강)
- 검색된 정보를 사용자의 질문과 결합해 하나의 프롬프트 구성
- 템플릿 + Query + Context 형태
-
Generate (생성)
- LLM에 프롬프트를 전달해 최종 응답 생성
- 결과를 검토하고 프롬프트를 튜닝 가능
파인튜닝과의 차이점
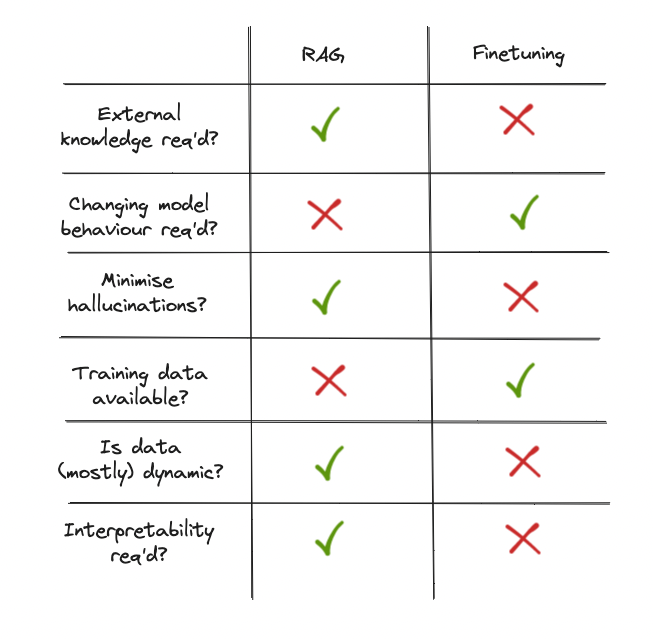
| 항목 | 파인튜닝 | RAG |
|---|---|---|
| 방식 | 모델 자체 재학습 | 외부 데이터로 응답 증강 |
| 장점 | 도메인 맞춤 최적화, 빠른 응답 | 최신 정보 활용, 유연한 적용 |
| 단점 | 비용 큼, 업데이트 어려움 | 검색 지연, 리소스 추가 필요 |
| 적용 | 법률, 의료, 감성 분석 등 | 뉴스, 문서 요약, 실시간 QA 등 |
요약: 파인튜닝은 모델을 바꾸고, RAG는 입력을 바꾼다.
개인적인 생각
- 나는 RAG가 더 실용적이라 느꼈다.
- 파인튜닝은 비용도 크고 실시간 정보 반영이 어려운 반면,
RAG는 문서 기반 QA나 캐릭터 챗봇 등에 유연하고 빠르게 대응 가능하다.
RAFT란?
RAG + 파인튜닝을 결합한 하이브리드 방식
→ RAFT: Retrieval-Augmented Fine-Tuning
- 질문-응답 문서와 무관한 문서를 함께 학습에 포함
- LLM은 CoT(Chain-of-Thought) 형태로 추론하고
정답 근거 문서만 참고하는 법을 배우게 된다
RAG의 단점인 “검색 오류에 대한 취약성”을 보완
RAG 2.0 (2024.03 발표)
기존 RAG의 한계
- 정적인 인덱스
- 복잡한 맥락의 작업 대응 어려움
RAG 2.0의 개선점
- 동적인 인덱스 활용
- Retriever와 LLM을 통합 훈련 (역전파 방식)

인덱스와 모델을 하나의 시스템으로 파인튜닝하여
정확도와 유연성을 동시에 향상
마무리 요약
| 용어 | 핵심 아이디어 | 강점 | 약점 |
|---|---|---|---|
| RAG | 외부 문서 검색 + 프롬프트 생성 | 최신성, 빠른 적용 | 검색 지연, 리소스 사용 |
| 파인튜닝 | 모델 재학습 | 정확도, 고정 응답 | 비용, 업데이트 불가 |
| RAFT | 둘을 결합 | RAG 취약성 보완 | 구현 난이도 |
| RAG 2.0 | LLM + Retriever 공동 학습 | 통합성, 동적 정보 활용 | 기술적 복잡성 |
