
해시란?
-
배열의 장점은 탐색이 O(1)인 것이다. 하지만 배열의 인덱스(key)와 데이터(value)간에 연관관계가 없다는 문제가 있다.
-
Value의 값을 해싱하여 key를 지정 후 Key:Value 로 저장하는 것이 해시의 기본원리이다.
-
해싱 결과가 같아 동일한 key를 부여받는 경우인 Collision이 일어날 수 있다.
-
충돌이 없다면 삽입, 삭제, 탐색의 시간복잡도가 모두 O(1)이다.
-
충돌이 많아질수록 O(n)에 가까워짐.
충돌(Collision) 해결
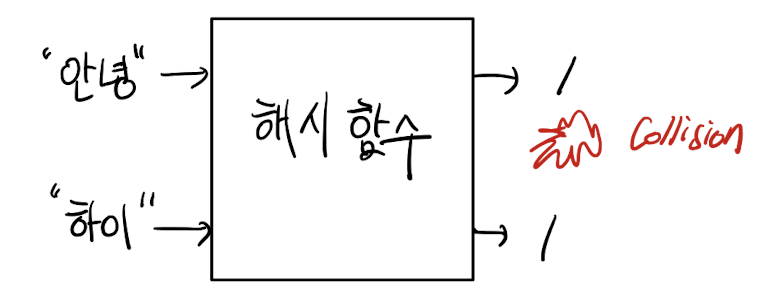
"안녕" 과 "하이"의 해싱 결과 동일하게 1이 Key값으로 설정되었다고 가정해보자.
1) Open Addressing (개방 주소법)
이미 데이터가 존재하면, 다른 해시 버킷에 데이터를 넣는 방식을 말한다.
-
Linear Probing
- 순차적으로 비어있는 버킷을 탐색하는 방식
-
Quadratic probing
- 2차함수를 이용해 탐색할 위치 찾는 방식
-
Double hashing probing
- 충돌 발생시 2차 해시함수로 다른 위치 찾는 방식
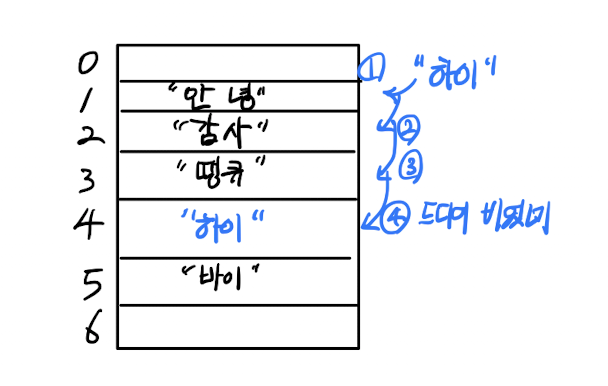
위 그림은 개방 주소법 중 Linear Probing의 예시이다. 순차적으로 비어있는 버킷을 탐색하다가 4번 인덱스가 비어있어 "하이"가 해당 버킷에 저장된다.
2) Separate Chaining (분리 연결법)
이미 데이터가 존재하면, 해당 인덱스에 링크드 리스트나 트리를 추가하여 데이터를 삽입한다.
체인으로 연결된 데이터 수가 많을 수록, 탐색시 속도가 더 빠른 트리가 유리하다.
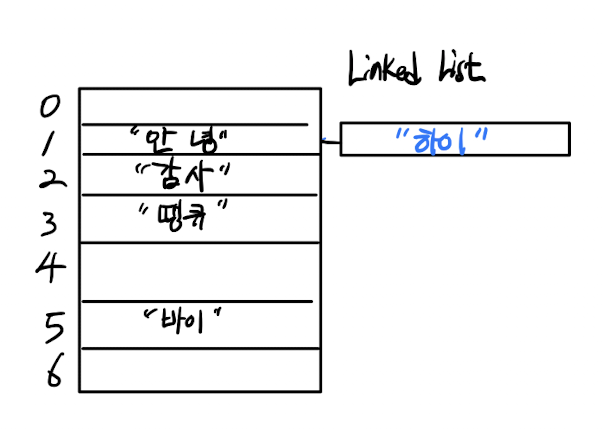
위 그림은 체이닝 솔루션 중 링크드 리스트를 활용한 예시이다. 1번 인덱스에 링크드 리스트로 버킷을 추가하여 데이터를 삽입한다.
Open Addressing vs Separate Chaining
-
두 방식 모두 최악의 시간복잡도는 O(n)이다.
-
Open Addressing은 연속된 공간에 저장하기에 캐싱 효율이 높아, 데이터 수가 적을 때 유리하다.
-
Chaining 방식의 시간복잡도 증가량이 더 적기에, 데이터 수가 많아질 수록 유리하다.
HashMap 라이브러리
import java.util.HashMap;
public class HashMapExam {
public static void main(String[] args) {
HashMap<Integer, String> hashMap = new HashMap<>();
hashMap.put(1, "감자");
hashMap.put(2, "고구마");
hashMap.put(3, "사과");
hashMap.put(1, "딸기");
System.out.println("hashMap = " + hashMap);
hashMap.remove(1);
System.out.println("hashMap = " + hashMap);
System.out.println(hashMap.get(2));
}
}
-
HashMap<key,value> 로 생성한다.
-
데이터 삽입 : put(key, value)
-
데이터 삭제 : remove(key)
-
중복된 키값이 들어오면 값이 대체된다.
