[논문 번역]Deep Counterfactual Regret Minimization(2)
(1)에서 계속 . . .
만약 플레이어가 infoset I에 대하여 매번 regret matching을 반복하면, iteration T에서, 이다(대충 upper bound가 있고 수렴한다는 뜻)
이래저래해서 결국 결론은 average strategy 는 내쉬균형으로 수렴한다는 것이다.
실전에서 한번에 두명의 regret을 업데이트 하는 대신 번갈아가며 하므로써 더 빠른 수렴이 가능하다. 우리 논문에서도 이런 방식을 사용한다.
Monte Carlo Counterfactual Regret Minimization
Vanilla CFR에서는 게임트리의 모든 부분을 돌아야 하는데, 거대한 게임에서 이는 불가능하다. 반면 Monte Carlo CFR(MCCFR)은 각 iteration 마다 게임트리의 일부분만을 방문한다. MCCFR에서는 이터레이션 t에서 노드의 부분집합인 만 방문하는데, 는 어떠한 분포 에서 샘플링 된다. 이렇게 샘플링 된 regrets 는 실제의 regret 대신 추적된다. iteration t에서 샘플링된 infoset I에 대하여, 는 를 I가 샘플링될 확률로 나눠준 값과 같다. 샘플링 되지 않은 infoset에 대하여 이다.
MCCFR 에는 다양한 종류가 있는데, 이 논문에서 우리는 간단하고, 강력한 성능을 보여주는 external sampling 기법에 초점을 둔다. external sampling MCCFR에서 게임트리는 한번에 한 플레이어의것만 번갈아가며 돈다. 우리는 현재 게임트리를 돌고있는 플레이어를 traverser 라고 부른다. Regret은 해당 iteration의 traverser것만 업데이트 한다. traverser가 행동하는 infosets에서는 모든 액션이 탐험된다. 다른 infoset이나 chance 노드에서는 오직 하나의 액션만 explored 된다.
External 샘플링 MCCFR은 확률적으로 균형에 수렴한다.
Related Work
CFR만이 규모가 큰 정보 불균형 게임을 풀 수 있는 반복적 알고리즘인건 아니다. First-order 방법은 CFR보다 이론적으로 훨씬 적은 바운더리 안에서 내쉬균형에 수렴한다. 그러나 실전에서 가장 빠른 종류의 CFR은 확실히 first-rder method보다 빠르다. 더 나아가서, CFR은 에러에 더 강력하고, 따라서 함수근사법과 연계됐을때 더 잘 작동한다.
NFSP은 헤즈업 리밋 텍사스 홀덤 AI를 만들기위해 딥러닝 함수 근사법과 Fictitious Play 를 합친 알고리즘이다. 그러나 Fictitious Play는 CFR보다 이론적으로 더 약한 수렴을 보장하고, 실전에서 수렴도 느리다. 우리는 이 논문에서 우리의 알고리즘과 NFSP를 비교한다. Model-Free 정책 그라디언트는 파라미터들이 제대로 튜닝됐을 때 regret을 최소화 했고, NFSP와 비슷한 퍼포먼스를 보였다.
이전의 work에서는 딥러닝을 사용하여 제한된 깊이의 subgame에서의 value를 측정했다. 하지만 subgame에서는 테이블 형태의 CFR이 사용됐다. 단일 에이전트를 위한 큰 규모의 함수 근사 CFR은 이전에 개발 됐지만, 우리 알고리즘은 다중 에이전트를 위한거고 상당히 다르다.
(이하 중략.. 그냥 대충 앞에 ~~한 논문이 있었는데, 그거랑 다르고 우리꺼는 특별하다 이런 느낌)
Description of the Deep Counterfactual Regret Minimization Algorithm
이번 섹션에서 우리는 Deep CFR을 묘사한다. Deep CFR의 목적은 DNN 함수 근사법을 통해 비슷한 infoset들을 일반화 하므로써 각 infoset에서 regret을 계산하고 축적하는 과정 없이 CFR의 행동을 근사하는 것이다.
각 iteration t 에서, Deep CFR은 상수 K만큼의 부분적인 게임트리만 탐색하는데, 이 탐색 경로는 external sampling MCCFR에 의해 정해진다. 그것이 마주하는 각각의 infoset I에서, Deep CFR은 뉴럴넷 의 결과값들로 regret matching을 하여 만든 strategy 를 플레이 한다.
뉴럴넷 는 에 의해 정의되고, input 으로 infoset 를 받고, output으로 을 받는다.
우리의 목적은 이 테이블 CFR이 도출 해냈을 에 대략적으로 비례하는것이다.
터미널 노드에 도착했을때, 밸류 값은 다시 위로 패스된다. 찬스노드와 상대의 인포셋에서, 샘플링 된 액션의 밸류 값은 변하지 않고 위로 올라간다. traverser의 infoset에서, 위로 가는 밸류 값은 가중된 모든 액션의 평균값이다(여기서 액션 a의 가중치는 이다.) 이러한 절차는 다양한 액션에 대한 이번 iteration의 즉각적 regrets의 샘플들을 만들어낸다. 이 샘플들은 메모리 에 추가된다(여기서 는 traverser이고, 용량이 초과되면 reservoir 샘플링 기법을 사용한다.)
external sampling으로 샘플링된 즉각적 regrets은 다음과 같은 속성을 띈다.
Lemma 1.
external sampling MCCFR 에서, 샘플링된 즉각적 regrets은 편향되지 않은 advantage 의 estimator 이다.
ex/ 양쪽 플레이어가 로 플레이 할 때, infoset I에서 a를 플레이 하는것과 를 플레이하는것 사이의 기댓값의 차이.
심층 강화 학습의 최근 논문들은 NN이 거대한 state space를 가진 어려운 환경에서도 효율적으로 advantage를 예측하고 일반화 하고, 그걸 이용해 좋은 정책을 학습한다는걸 보여왔다. 플레이어의 번째 traversal이 끝나면, 새로운 네트워크는 예측된 advantage 와 (메모리에 저장 해놓은)이전 iterations 에서의 즉각적 regrets의 샘플들 사이의 MSE를 최소화 하므로써, 파라미터 를 구하기 위해 처음부터 학습된다. 샘플링된 즉각적 advantages 의 평균은 총 샘플 regret 에 비례하므로, 샘플이 한번 메모리에 들어가면, 그것은 reservoir sampling을 통해서가 아니면 다음 CFR iteration이 시작 돼도 절대 나오지 않는다.
손실 함수로는 Bregman Divergence를 만족하는 어떤것이든 써도 된다.
샘플들이 제대로 가중되는 어떠한 샘플링 기법도 사용 가능한데, external sampling 은 한 iteration 내 모든 샘플들에 똑같은 가중치를 할당하므로써 우리의 두가지 목표 모두 달성한다는 점에서 편리하다. 추가적으로 traverser의 모든 액션을 탐험 하는것은 분산을 줄여준다. 그러나 external sampling은 정말 극단적으로 큰 게임에서는 실용적이지 못하므로(traverser의 모든 액션을 탐험하기 때문에) 그런 task에는 outcome sampling 같은 기법이 더 잘 맞을것이다.
Value 네트워크에 추가적으로, 정책 네트워크 는 마지막에 평균 strategy를 근사하는데, 왜냐하면 모든 iteration의 strategy의 평균 이 내쉬균형으로 수렴하기 때문이다. 이걸 위해 우리는 분리된 메모리 에 샘플링된 infoset의 양 플레이어의 확률 벡터를 저장한다. 플레이어 p의 infoset 가 external sampling을 통해 상대 플레이어의 traversal 의 게임트리에서 탐험 될 때마다, infoset 확률 벡터 는 에 추가되고, 가중치 t를 할당 받는다.
만약 Deep CFR의 반복 횟수와 각각의 밸류 네트워크 모델이 작으면, final training policy를 학습 하는 대신 각각의 iteration의 밸류 네트워크를 저장하므로써 해결할 수 있다. 실제로 플레이 할 때, 밸류 네트워크는 무작위로 샘플링 되고 플레이어는 그 네트워크의 예측된 advantages로 부터 파생된 CFR 전략을 플레이한다. 이런 방법은 final average 정책 네트워크의 함수 근사 에러(function approximation error)를 해결해주지만, 이전의 모든 밸류 네트워크를 저장해야 한다. 그럼에도 불구하고, 강력한 성능과 낮은 Exploitability는 이전 밸류 네트워크들의 부분집합만 저장하므로써 얻을 수 있다.
Theorem 1은 만약 메모리 버퍼가 충분히 크면 높은 확률로 deep CFR의 average regret은 상수 K로 bound 된다. K는 function approximation error의 루트값이다. (theorem 1은 생략한다)
5. Experimental Setup
우리는 Deep CFR의 성능을 헤즈업 플랍 홀덤 포커에서 측정한다(FHP). FHP는 개의 노드와 개의 infosets을 가지는 큰 게임이다. 반면 우리가 사용하는 네트워크는 98948개의 파라미터를 가지고 있다. FHP는 헤즈업 리밋 텍사스 홀덤(HULH) 포커와 비슷하지만, 4번의 베팅 대신 두번만 하고, 커뮤니티카드는 플랍 까지만 본다. 또한 우리는 HULH 포커에서 추상화 테크닉과도 성능을 비교해본다. HULH는 개의 노드와 개의 infosets을 가진다.
두 게임에서 우리는 deep cfr의 퍼포먼스를 NFSP(deep cfr 이전 최강 함수근사법 알고리즘)와 포커 도메인의 최신 추상화 기술과 비교한다.
5.1 Network Architecture
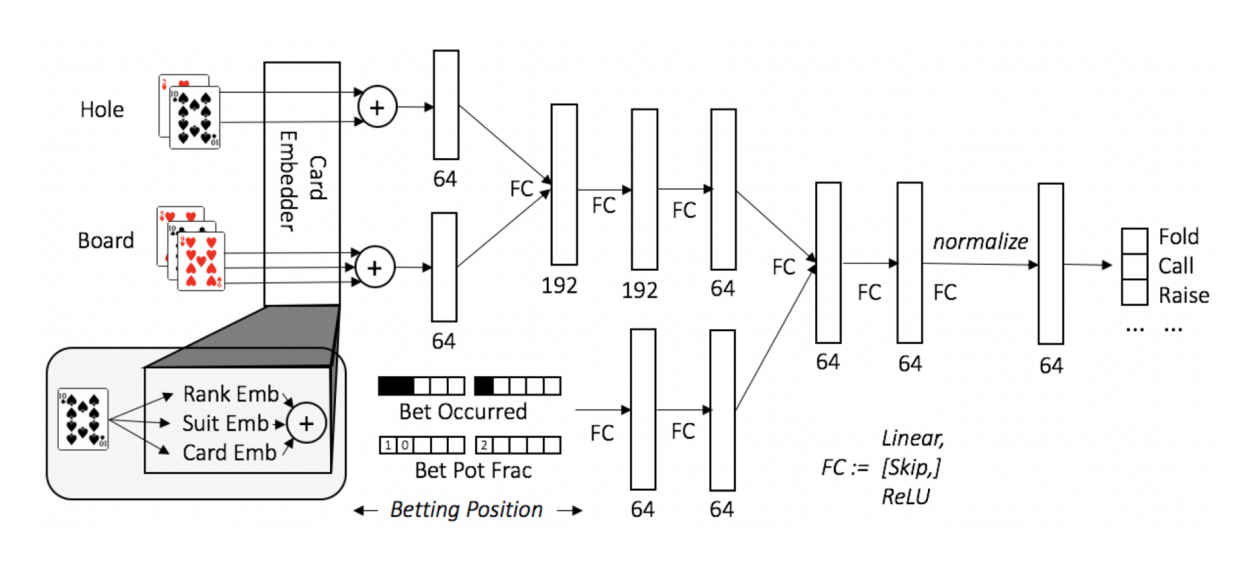
우리는 각각의 플레이어들의 advantages를 계산하는 밸류 네트워크 와 final average strategy를 근사하는 네트워크 모두에 위와 같은 NN을 사용 할 것이다. 이 네트워크는 7 레이어의 깊이와 98,948개의 파라미터를 가진다. Infoset은 카드셋과 베팅 히스토리로 구성돼있다. 카드는 3가지 임베딩의 합으로 표현된다: rank embedding(1-13), suit embedding(1-4), card embedding(1-52). 이 임베딩들은 각각의 순열 불가변의(카드 순서에 따라 어떤 상황도 변하지 않는) 카드셋(hole,flop,turn,river)에서 더해지고, 이어진다. 각 베팅 라운드 는 최대 6개의 연속적인 액션이 될 수 있으므로, 총 unique 베팅 포지션이 있다. 각 베팅 포지션은 그 벳이 일어났는지에 대한 이진 value와, 벳 사이즈를 저장하는 실수 value 로 인코딩 된다.
NN 모델은 카드와 벳 두가지 분리된 가지로 시작한다. 이 가지들은 각각 3개, 2개의 레이어를 가지고 있다. 두 가지에서 나온 피처들은 합쳐지고, 3개의 추가적인 FC 레이어가 적용된다. 각각의 FC 레이어는 로 구성된다. 추가적인 skip connection 는 인풋과 아웃풋 디멘션이 같을때만 적용된다. (평균0, 분산 1의)정규화는 마지막 레이어 피쳐에 적용된다. 네트워크 아키텍쳐는 정교하게 튜닝되지는 않았지만 정규화와 skip connections는 사용됐는데, 이는 FHP에서 미리 계산된 equilibrium strategies에서 실험 했을때 빠른 수렴에 중요한 영향을 끼친다는것이 밝혀졌기 때문이다.
밸류 네트워크에서 아웃풋 벡터는 인풋 infoset의 각각의 액션에 대한 예측된 advantage이다. Average strategy 네트워크에서 아웃풋은 액션들의 확률 분포의 logit으로 해석된다.
5.2 Model training
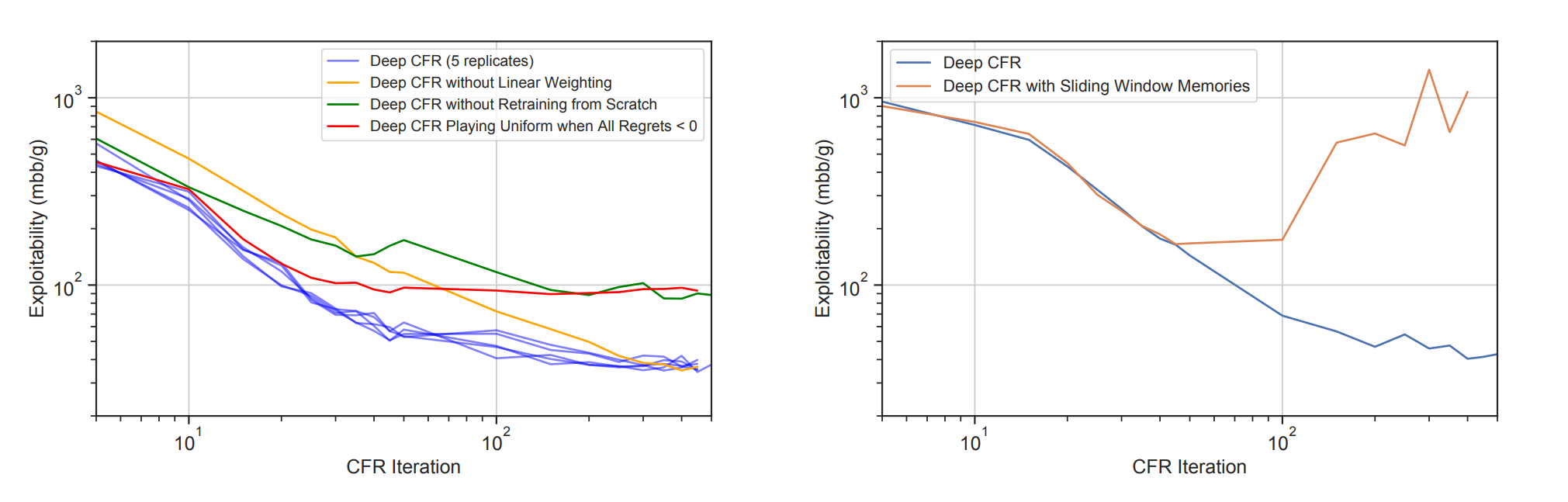
우리는 각 플레이어의 advantage 메모리 에 40 million 인포셋의 최대 사이즈를 할당한다. 각 CFR에서 밸류 모델은 처음(random init 부터)부터 다시 학습된다. 우리는 배치사이즈 10000으로 4000 미니 배치 SGD iteraion을 수행하고, lr 0.001의 Adam으로 파라미터를 업데이트 한다(gradient norm clipping to 1). HULH에서는 32000 SGD 이터레이션과 20000의 배치사이즈를 사용한다. 위 그림은 모델은 매 반복마다 처음부터 학습하는것이 이전의 weight를 사용하는 것보다 더 잘 수렴한다는걸 보여준다.
5.3 Linear CFR
CFR에는 vanilla CFR에 비해 훨씬 빠르게 수렴하는 다양한 종류가 있다. 그러나, 대부분의 이런 빠른 CFR은 근사 에러(Approximation Error)를 잘 다루지 못한다. 이 논문에서 우리는 Linear CFR(LCFR)을 사용한다. LCFR은 CFR보다 빠르고 근사 에러도 잘 잡는 CFR의 한 종류이다. LCFR이 필수인건 아니고 점근적으로 더 좋은 성능을 보이는건 아니지만, 우리 실험에서 더 빠르게 수렴했다.
LCFR은 iteration t가 t로 가중된다는 점을 제외하면 CFR과 비슷하다. 구체적으로, 우리는 advantage 메모리와 strategy 메모리에 저장된 각각의 항목의 가중치(이 항목이 추가됐을때의 t)를 보관한다. 각 iteration T에서 를 학습할 때, 우리는 모든 배치 가중치를 로 rescale 하고 weighted error를 최소화 한다.
