Basic concepts in Tianshou
Tianshou 는 강화학습 학습 절차를 다음과 같이 나눈다: Trainer, Collector, Policy, and Data Buffer. 일반적인 과정은 다음과 같다.
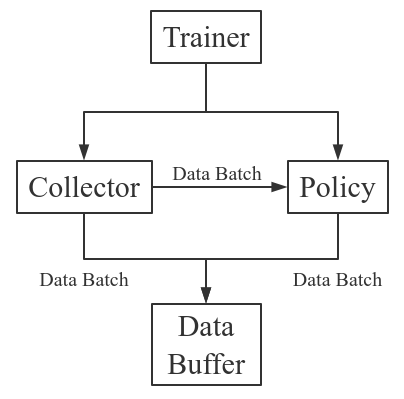
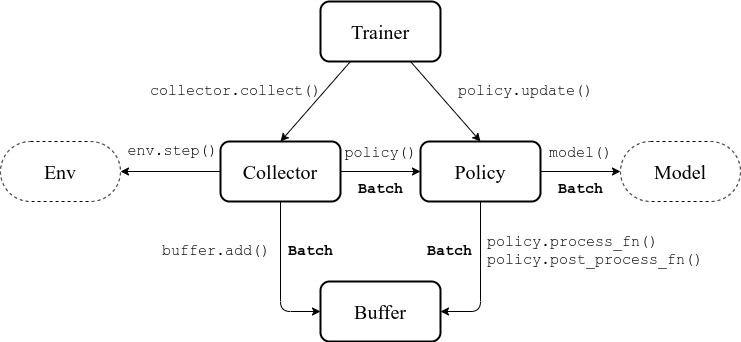
좀 더 자세하게 표현하자면 다음과 같다. 여기서 Env 는 환경이고, Model 은 신경망이다.
Batch
Tianshou 는 어떤 종류의 데이터든 다른 메소드로 보낼 수 있는 internal data structure Batch 를 제공한다. 예를들어, 컬렉터는 정책의 학습을 위해 Batch 를 보내준다. 이 스크립트를 보자.
>>> import torch, numpy as np
>>> from tianshou.data import Batch
>>> data = Batch(a=4, b=[5, 5], c='2312312', d=('a', -2, -3))
>>> # the list will automatically be converted to numpy array
>>> data.b
array([5, 5])
>>> data.b = np.array([3, 4, 5])
>>> print(data)
Batch(
a: 4,
b: array([3, 4, 5]),
c: '2312312',
d: array(['a', '-2', '-3'], dtype=object),
)
>>> data = Batch(obs={'index': np.zeros((2, 3))}, act=torch.zeros((2, 2)))
>>> data[:, 1] += 6
>>> print(data[-1])
Batch(
obs: Batch(
index: array([0., 6., 0.]),
),
act: tensor([0., 6.]),
)위 코드처럼, Batch 는 어떤 key-value pair 로든지 정의 할 수 있고, 그 사이 공통된 작업을 수행 할 수 있다.
Understand Batch 는 Batch 개념 이해를 위해 쓰여진 자세한 튜토리얼이다. 이것도 조만간 번역할거임
Buffer
ReplayBuffer 는 정책과 환경의 상호작용으로 만들어진 데이터들을 저장한다. ReplayBuffer 는 Batch 의 한가지 특수한 형태이다. 이것은 Batch 에 있는 모든 데이터를 원형 큐 스타일로 저장한다.
현재 Tianshou 에서는 7 가지 Batch 에 저장된 7 가지 key 를 사용한다.
obs: step t 에서의 observationact: step t 에서의 actionrew: step t 에서의 rewarddone: step t 에서의 done flageobs_next: step t+1 에서의 observationinfo: step t 에서의 info (gym.env에서env.step()함수는 네가지 argument를 반환 하는데, 그 마지막 값이info이다.)policy: step t 에서 정책에 의해 계산된 데이터
밑에 코드는 다음을 포함하는 사용법을 보여준다.
- 기본적인 데이터 저장소:
add() - 속성값 받기, 데이터 슬라이싱 하기, ...
- 버퍼에서 샘플링 하기:
sample_index(batch_size),sample(batch_size) - 에피소드 안에서 전/후 트랜지션 인덱스 받기:
prev(index),next(index) - 버퍼에 데이터를 저장하거나 불러오기: pickle and HDF5
>>> import pickle, numpy as np
>>> from tianshou.data import Batch, ReplayBuffer
>>> buf = ReplayBuffer(size=20)
>>> for i in range(3):
... buf.add(Batch(obs=i, act=i, rew=i, done=0, obs_next=i + 1, info={}))
>>> buf.obs
# since we set size = 20, len(buf.obs) == 20.
array([0, 1, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
>>> # but there are only three valid items, so len(buf) == 3.
>>> len(buf)
3
>>> # save to file "buf.pkl"
>>> pickle.dump(buf, open('buf.pkl', 'wb'))
>>> # save to HDF5 file
>>> buf.save_hdf5('buf.hdf5')
>>> buf2 = ReplayBuffer(size=10)
>>> for i in range(15):
... done = i % 4 == 0
... buf2.add(Batch(obs=i, act=i, rew=i, done=done, obs_next=i + 1, info={}))
>>> len(buf2)
10
>>> buf2.obs
# since its size = 10, it only stores the last 10 steps' result.
array([10, 11, 12, 13, 14, 5, 6, 7, 8, 9])
>>> # move buf2's result into buf (meanwhile keep it chronologically)
>>> buf.update(buf2)
>>> buf.obs
array([ 0, 1, 2, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 0, 0, 0,
0, 0, 0, 0])
>>> # get all available index by using batch_size = 0
>>> indice = buf.sample_index(0)
>>> indice
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12])
>>> # get one step previous/next transition
>>> buf.prev(indice)
array([ 0, 0, 1, 2, 3, 4, 5, 7, 7, 8, 9, 11, 11])
>>> buf.next(indice)
array([ 1, 2, 3, 4, 5, 6, 6, 8, 9, 10, 10, 12, 12])
>>> # get a random sample from buffer
>>> # the batch_data is equal to buf[indice].
>>> batch_data, indice = buf.sample(batch_size=4)
>>> batch_data.obs == buf[indice].obs
array([ True, True, True, True])
>>> len(buf)
13
>>> buf = pickle.load(open('buf.pkl', 'rb')) # load from "buf.pkl"
>>> len(buf)
3
>>> # load complete buffer from HDF5 file
>>> buf = ReplayBuffer.load_hdf5('buf.hdf5')
>>> len(buf)
3위 코드에서 잘 봐야하는 부분은
indice쪽이다.sample_index(batch_size: int)함수는 원래 배치 사이즈 크기의 인덱스의 array를 반환하지만batch_size=0일때는 모든 index의 array를 반환한다.
buf.prev(indice)를 잘 보면, 숫자가 1 씩 순차적으로 오르다 중간 중간 비어있는게 보이는데, 이는 새 에피소드가 시작할 때 보이는 현상이다.prev()는 매개변수 index의 한단계 앞 transition의 index를 반환하는데, 에피소드 첫 transition 에는 이전 index 라는게 있을 수 없고, 그냥 자기 index를 반환한다.buf.next(indice)도 vice-versa.
ReplayBuffer 는 또한 (RNN을 위한)frame_stack sampling, 다음 obs 저장 무시하기, multi-modal observation 을 지원한다.
Advanced usage of ReplayBuffer
Tianshou 는 (세그먼트 트리와 numpy.ndarray 에 기반한) PrioritizedReplayBuffer, (다른 에피소드들의 데이터를 시간적 순서를 잃지 않고 저장해주는) VectorReplayBuffer 등을 제공한다. 자세한 사용법은 나중에 찾아보자.
Policy
Tianshou 는 RL 알고리즘의 모듈화를 지향한다. Tianshou에는 몇가지 정책의 클래스가 있다. 이 모든 정책 클래스들은 반드시 BasePolicy 를 상속받아야한다. 정책 클래스에는 일반적으로 다음과 같은 파트가 있다.
__init__(): 정책을 시작한다. Target-Policy 를 복사하는 등의 일이 여기에 속한다.forward(): 받은 observation 으로 action 을 계산한다.process_fn(): Replay Buffer 에서 받은 데이터를 전처리한다.learn(): 받은 배치 데이터로 정책을 업데이트 한다.post_process_fn(): 받은 배치 데이터로 버퍼를 업데이트 한다.update(): 학습을 위한 메인 인터페이스. 이 함수는 버퍼에서 데이터를 샘플링 하고, 전처리하고, 데이터로 학습하고, 후처리 한다. 짧게 말하자면 다음과 같다.
`process_fn -> learn -> post_process_fn'
States for policy
학습 과정에서 정책은 training state 와 testing state 를 가진다. training state 는 더 자세하게 collection state 와 updating state 로 나뉘어진다.
각 상태의 의미는 자명하다. training state 는 agent 가 환경과 상호작용 하고, 학습 데이터를 모아서 업데이트를 하는것이고, testing state 는 학습 도중 현재 정책의 퍼포먼스를 평가하는 것이다.
collecting state 는 환경과 상호작용하고 학습 데이터를 버퍼에 모으는 것이라면, updating state 는 update() 함수를 통해서 모델을 업데이트 하는것이다.
이러한 상태들을 구별하기 위해 `policy.training 과 policy.updating 을 통해 정책 상태를 확인할 수 있다. 상태의 세팅은 다음과 같다.
State for policy |
policy.training |
policy.updating |
|
|---|---|---|---|
Training state |
Collecting state |
True |
False |
Updating state |
True |
True |
|
Testing state |
False |
False |
policy.updating 은 다른 탐색 상태를 구별할 때 유용하다. 예를들어 DQN 에서는 순수 네트워크 업데이트에서 epsilon-greedy 를 사용할 필요가 없으므로 이경우 policy.updating 이 엡실론을 설정하는데 유용하다.
policy.forward
forward 함수는 받은 observation 을 토대로 action 을 계산한다. input 과 output 은 알고리즘에 따라 다르지만 일반적으로는 (batch, state, ...) -> batch 와 같다.
입력 배치는 (observation, reward, done flag, and info 와 같은) 환경 데이터이다. 이는 일반적으로 collect() 나 sample() 로부터 온다. input batch 의 모든 변수의 첫번째 차원은 batch-size와 같아야 한다.
output 또한 Batch 인데, act 를 반드시 포함해야 하며, (정책의 히든 스테이트인) state 나 (버퍼에 저장돼야 하는 정책의 중간 결과인) policy, 그리고 알고리즘에 따라 다른 key 들을 포함할 수 있다.
예를들어 현재 정책으로 한 에피소드를 평가하는 코드는 다음과 같다.
obs, done = env.reset(), False
while not done:
batch = Batch(obs=[obs])
act = policy(batch).act[0]
obs, rew, done, info = env.step(act)여기서 Batch(obs=[obs]) 는 자동으로 0 차원을 배치사이즈로 만든다. 그렇지 않으면, 네트워크는 배치사이즈를 분별하지 못한다.
policy.process_fn
process_fn 함수는 N-step 이나 GAE returns 같이 시계열(Time-series)에 기반한 몇몇 변수들을 계산한다.
예를들어, 2-step return DQN 에서 각 transition 의 리턴값을 다음과 같이 계산한다.
여기서 는 할인계수이다. 아래 수도 코드는 Tianshou 프레임워크 없이 학습하는 과정이다.
# pseudocode, cannot work
s = env.reset()
buffer = Buffer(size=10000)
agent = DQN()
for i in range(int(1e6)):
a = agent.compute_action(s)
s_, r, d, _ = env.step(a)
buffer.store(s, a, s_, r, d)
s = s_
if i % 1000 == 0:
b_s, b_a, b_s_, b_r, b_d = buffer.get(size=64)
# compute 2-step returns. How?
b_ret = compute_2_step_return(buffer, b_r, b_d, ...)
# update DQN policy
agent.update(b_s, b_a, b_s_, b_r, b_d, b_ret)딱 봐도 배치에 저장해뒀다가 랜덤으로 샘플링 해와서 2-step 리턴을 계산하기는 어려워보인다. 그래서 우리는 이를 계산하기 위해 시간과 관련된 인터페이스가 필요하다. process_fn() 는 리플레이 버퍼와, sample index, 그리고 sample batch data 를 제공하므로써 이러한 작업을 끝낸다. 모든 데이터를 시간 순으로 저장하기 때문에, 다음과 같이 2-step return 을 간단하게 계산할 수 있다.
class DQN_2step(BasePolicy):
"""some code"""
def process_fn(self, batch, buffer, indice):
buffer_len = len(buffer)
batch_2 = buffer[(indice + 2) % buffer_len]
# this will return a batch data where batch_2.obs is s_t+2
# we can also get s_t+2 through:
# batch_2_obs = buffer.obs[(indice + 2) % buffer_len]
# in short, buffer.obs[i] is equal to buffer[i].obs, but the former is more effecient.
Q = self(batch_2, eps=0) # shape: [batchsize, action_shape]
maxQ = Q.max(dim=-1)
batch.returns = batch.rew \
+ self._gamma * buffer.rew[(indice + 1) % buffer_len] \
+ self._gamma ** 2 * maxQ
return batch이거 다시 보셈
위 코드는 done flage를 고려하지 않으므로, 제대로 작동하지 않을 수 있지만, 대충 process_fn() 을 통해서 를 쉽게 구하는 방법을 보여준다.
Collector
collector 는 정책이 다른 종류의 환경들과 편리하게 상호작용 할 수 있게 해준다.
collect() 는 콜렉터의 메인 메서드이다. collect() 는 정책이 지정된 수 만큼의 n_step 이나 n_episode 를 실행하고 그 데이터를 리플레이 버퍼에 저장하고, 에피소드의 총 리워드와 같은 데이터의 통계를 반환하게 해준다.
아래는 예시 코드이다.
policy = PGPolicy(...) # or other policies if you wish
env = gym.make("CartPole-v0")
replay_buffer = ReplayBuffer(size=10000)
# here we set up a collector with a single environment
collector = Collector(policy, env, buffer=replay_buffer)
# the collector supports vectorized environments as well
vec_buffer = VectorReplayBuffer(total_size=10000, buffer_num=3)
# buffer_num should be equal to (suggested) or larger than #envs
envs = DummyVectorEnv([lambda: gym.make("CartPole-v0") for _ in range(3)])
collector = Collector(policy, envs, buffer=vec_buffer)
# collect 3 episodes
collector.collect(n_episode=3)
# collect at least 2 steps
collector.collect(n_step=2)
# collect episodes with visual rendering ("render" is the sleep time between
# rendering consecutive frames)
collector.collect(n_episode=1, render=0.03)(한 스텝에 시간이 오래 드는) 비동기적인 환경 세팅을 지원하는 AsyncCollector 도 있다. 하지만 AsyncCollector 는 비동기적 환경의 속성 때문에 n_step 과 n_episode 만 지원한다.
Trainer
컬렉터와 정책을 생성했다면, 학습을 시작할 수 있다. Trainer 는 사실 아주 심플한 wrapper 이다. trainer 는 니가 학습 루프를 짜는 에너지를 절약해준다. 또한, 커스터마이즈 된 트레이너를 직접 짜는것도 가능하다.
Tianshou 는 onpolicy_trainer(), offpolicy_trainer(), offline_trainer() 를 제공한다.
A High-level Explanation
아래 주석은 이전에 policy.process_fn 섹션에서 사용됐던 코드를 통한 a high-level explanation 이다.
# pseudocode, cannot work # methods in tianshou
s = env.reset()
buffer = Buffer(size=10000) # buffer = tianshou.data.ReplayBuffer(size=10000)
agent = DQN() # policy.__init__(...)
for i in range(int(1e6)): # done in trainer
a = agent.compute_action(s) # act = policy(batch, ...).act
s_, r, d, _ = env.step(a) # collector.collect(...)
buffer.store(s, a, s_, r, d) # collector.collect(...)
s = s_ # collector.collect(...)
if i % 1000 == 0: # done in trainer
# the following is done in policy.update(batch_size, buffer)
b_s, b_a, b_s_, b_r, b_d = buffer.get(size=64) # batch, indice = buffer.sample(batch_size)
# compute 2-step returns. How?
b_ret = compute_2_step_return(buffer, b_r, b_d, ...) # policy.process_fn(batch, buffer, indice)
# update DQN policy
agent.update(b_s, b_a, b_s_, b_r, b_d, b_ret) # policy.learn(batch, ...)