RL from zero to hero
1.강화학습 개념정리(1) - 강화학습 정의, state, observation, action space, policy, trajectory, reward, return

최근 몇개월 RL공부를 열심히 하다보니, 기본적인 용어나 개념이 헷갈리는 경우가 종종 있어서이참에 기본부터 개념정리를 싹 하고자 한다. 본 글은 OpenAi Spinning Up - Introduction to RL을 바탕으로 작성하였다.RL(Reinforcement
2.강화학습 개념정리(2) - rl problem, 벨만 방정식, Q 함수, advantage function, value function
Intro 1편에 이어 2편도 바로 작성하게 됐다. 기본적으로 내 머릿속 정리를 위해 쓰는거라 다소 배려가 부족하긴 하지만, 그래도 최대한 보는사람도 도움을 얻을 수 있게끔 쓰도록 노력하겠다. RL Problem > 정책의 종류나 리턴 측정의 종류에 상관없이, RL의
3.강화학습 개념정리(3) - 알고리즘 종류, on-policy, off-policy, Q러닝, Policy Gradient, Model-Free, Model-Based
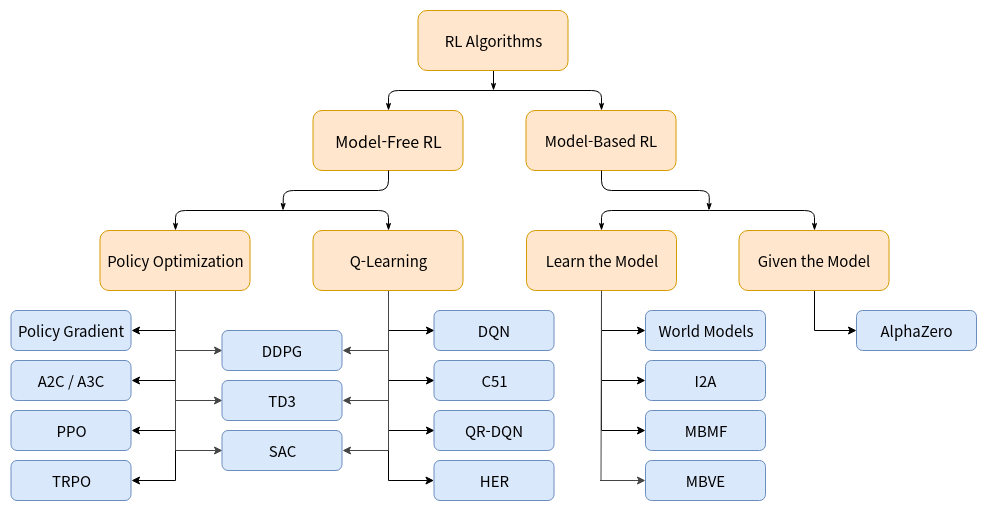
미리 말하자면, 위 분류는 완벽하지 않다. RL의 특성 상 트리 구조로 엄밀하게 분류하기가 힘들기 때문이다. 예를들어 Policy Gradient 와 Value Function을 둘다 사용하는 DDPG, TD3, SAC는 세부적으로 다르게 작동하지만 트리구조 상에서는
4.강화학습 개념정리(4)
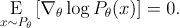
Intro to Policy Optimization
5.DDPG
우리는 DQN의 성공에 깔려있는 아이디어들을 차용해서 연속적인 액션 공간(continous action domain)으로 옮겼다. 우리는 확정적 정책 그라디언트(Deterministic Policy Gradient)에 기반한 연속적인 액션 공간에서 사용할 수 있는 Ac
6.Tianshou 사용법(1) - Quick Start Tutorial(DQN)
강화학습은 여러 분야에서 많은 성공을 거뒀고, DQN은 그 첫번째 사례이다. 이번 튜토리얼에서는 Tianshou를 이용하여 DQN Agent로 Cartpole 환경을 차근차근 학습해볼것이다. hyper-parameter, network 등의 specification
7.Tianshou 사용법(2) - Basic concepts in Tianshou
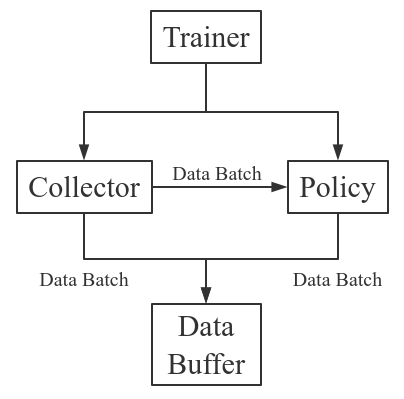
Tianshou 는 강화학습 학습 절차를 다음과 같이 나눈다: Trainer, Collector, Policy, and Data Buffer. 일반적인 과정은 다음과 같다.좀 더 자세하게 표현하자면 다음과 같다. 여기서 Env 는 환경이고, Model 은 신경망이다.T