학술제를 준비하며, Linguistics 관련 논문 Abstract 데이터가 필요했다. 좋은 사이트를 찾기 위해서 정말 많이 찾아보았지만, 아래의 사이트가 그나마 괜찮았다.
크롤링 사이트
lingbuzz - archive of linguistics articles
URL 구조 및 설명
-
Base url : https://ling.auf.net/
-
카테고리 및 페이지 url : https://ling.auf.net/lingbuzz/_listing?community=카테고리&start=시작번호
-
가져올 카테고리는 총 4개 → semantics, syntax, phonology, morphology
-
시작 번호 : 처음 페이지에는 논문 30개씩 존재 → 이후 부터는 100개씩 존재
base_url = base + "lingbuzz/_listing?community=" + cate + "&start=" + str(start) res = requests.get(base_url) html = bs(res.text, 'html.parser')
-
-
논문 detail 페이지 : https://ling.auf.net/lingbuzz/논문id
base = 'https://ling.auf.net/' detail_page = requests.get(base + detail_url)
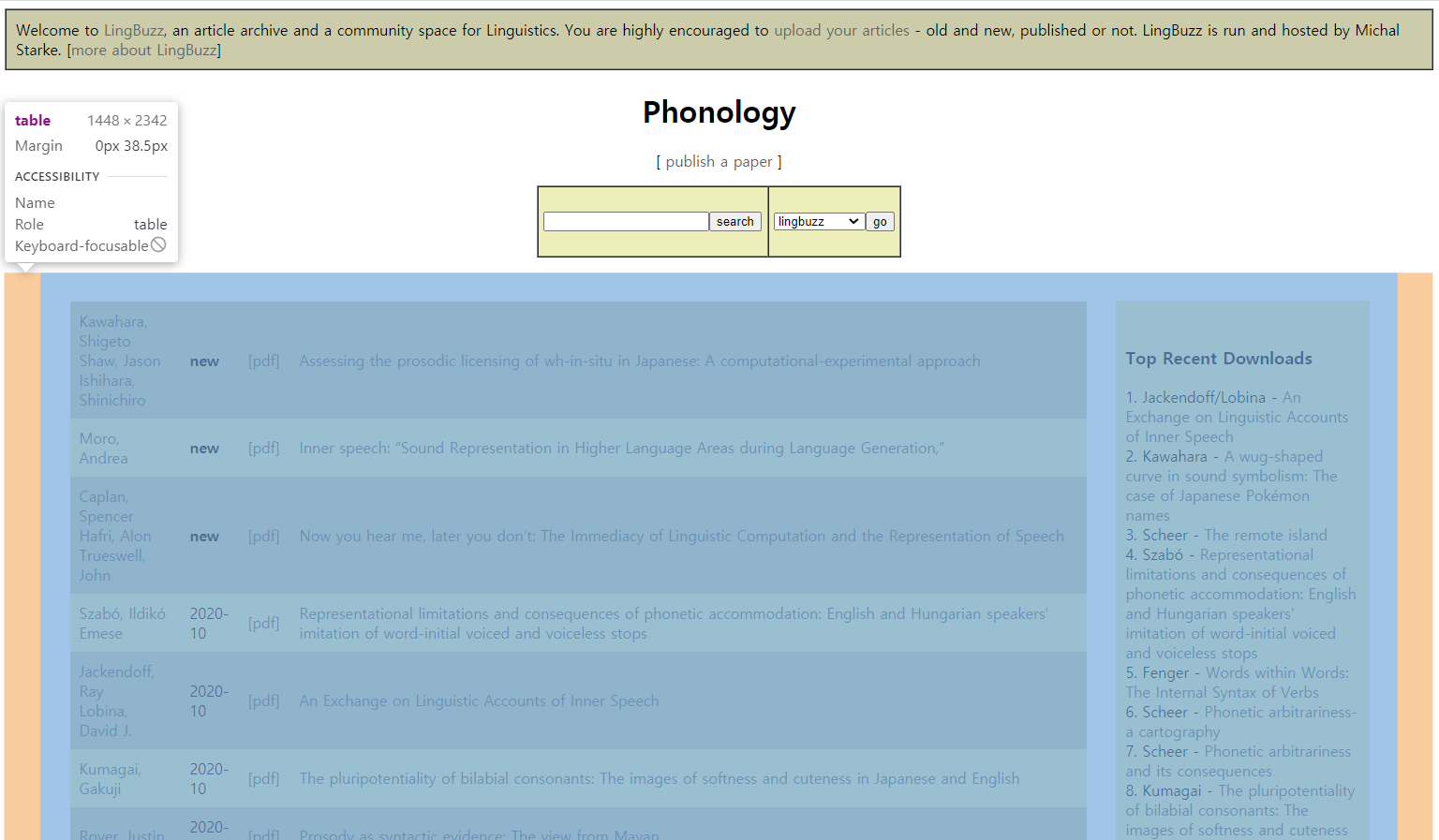
카테고리 페이지
-
논문을 담고있는 테이블은 html 중 2번째 테이블, table > tbody > tr 의 td 첫번째 자식
tables = html.select('table') temp_table = tables[2] paper_table = temp_table.select_one('table') -
td 안에 또 table이 존재하고, 그 안의 tr들이 각 논문을 담고 있다.
rows = paper_table.select('tr') -
tr 안에 td 중 마지막 요소가 논문 detail 페이지의 href를 가지고 있다.
for row in rows: detail_url = row.select('td')[-1].select_one("a")['href'] detail_page = requests.get(base + detail_url) detail_page_html = bs(detail_page.text, 'html.parser')
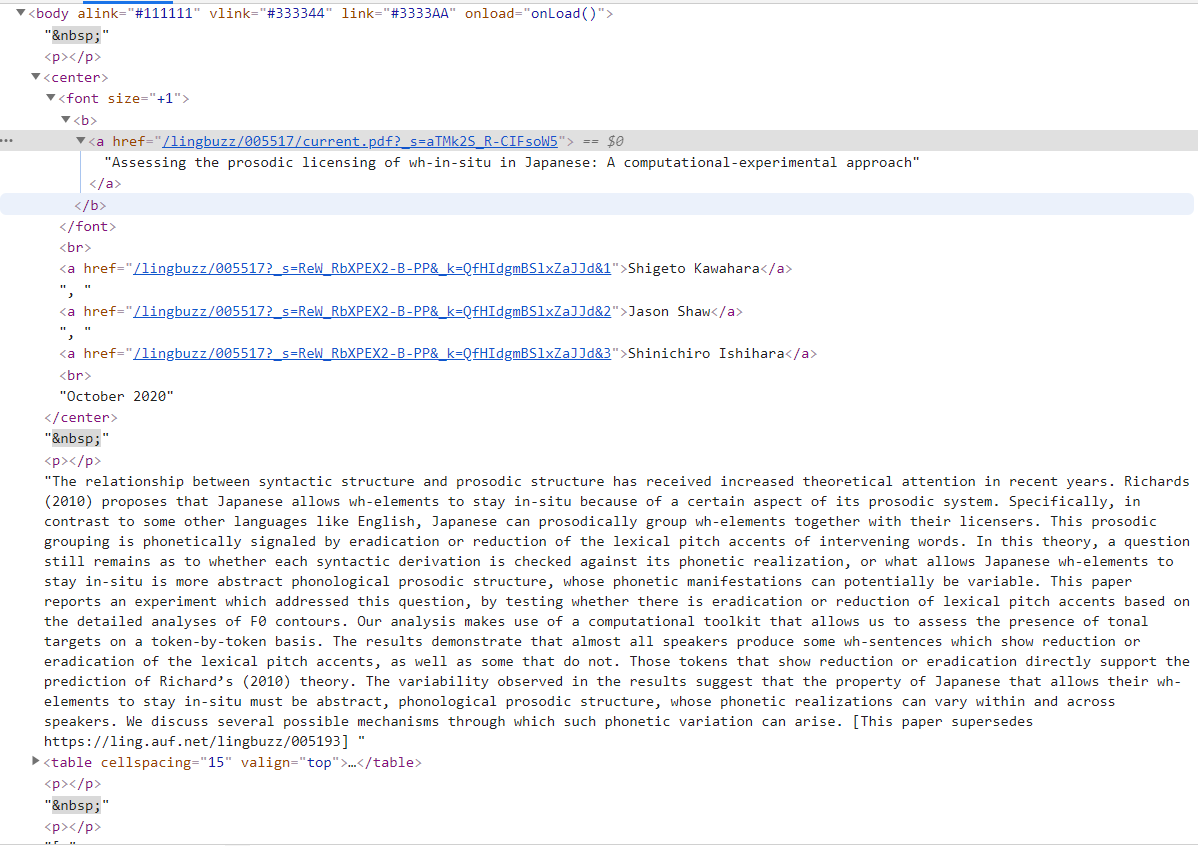
Detail Page
-
논문 제목 : center > font > a 태그
-
bs4객체.제거할태그.extract() : 제거 + 해당 태그를 return
title = detail_page_html.select_one("center").font.extract().text
-
-
논문 저자 : center > a 태그
author_list = detail_page_html.select("center a") # author 추출 author = '' for person in author_list: author += person.text + ', ' author = author.strip(', ') -
논문 내용 : body태그 내에 아무 태그 없이 존재 → 나머지 태그를 제거해야됨
-
bs4객체.제거할태그.decompose() : return 값 없이 태그 제거
# abstract 만을 남겨놓기 위한 태그 삭제 detail_page_html.center.decompose() detail_page_html.title.decompose() detail_page_html.table.decompose() detail_page_html.table.decompose() detail_page_html.p.decompose() abstract = detail_page_html.text
-
기타
논문 Abstract에 프랑스어와 같은 인코딩 없이 들어갈 수 없는 문자들이 있어서 utf-8-sig로 인코딩을 해주었다. 하지만 utf-8로도 인코딩이 불가한 특수문자들이 존재했다. 예를 들어 작은따옴표(’), 쌍따옴표(”)과 같은 것들이 일반적으로 쓰는 문자가 아닌 특수문자로 되어있어서 replace를 해주었고, 간혹 text에 JS 코드가 섞인게 있어서 그것 또한 replace를 해주었다.
전체 코드
import requests
from bs4 import BeautifulSoup as bs
def crawl(cate):
total = []
base = 'https://ling.auf.net/'
'https://ling.auf.net/lingbuzz/_listing?community=Phonology&start=31'
print(cate)
print()
start = 1
while True:
base_url = base + "lingbuzz/_listing?community=" + cate + "&start=" + str(start)
res = requests.get(base_url)
html = bs(res.text, 'html.parser')
tables = html.select('table')
temp_table = tables[2]
paper_table = temp_table.select_one('table')
if len(paper_table.text.strip()) == 0:
break
rows = paper_table.select('tr')
for row in rows:
paper = {'category' : cate}
detail_url = row.select('td')[-1].select_one("a")['href']
detail_page = requests.get(base + detail_url)
detail_page_html = bs(detail_page.text, 'html.parser')
# title 추출 및 제거
title = detail_page_html.select_one("center").font.extract().text
print(cate, len(total), title)
paper['title'] = title
author_list = detail_page_html.select("center a")
# author 추출
author = ''
for person in author_list:
author += person.text + ', '
author = author.strip(', ')
paper['author'] = author
# abstract 만을 남겨놓기 위한 태그 삭제
detail_page_html.center.decompose()
detail_page_html.title.decompose()
detail_page_html.table.decompose()
detail_page_html.table.decompose()
detail_page_html.p.decompose()
abstract = detail_page_html.text.replace('’',"'").replace('“','"').replace("혻혻","").replace("/*<![CDATA[*/function onLoad(){};/*]]>*/", "").replace('”', '"').replace("—","-").replace("‘","'").strip()
paper['abstract'] = abstract
paper['url'] = base + detail_url
total.append(paper)
# 시작페이지 수 증가
if start == 1:
start += 30
else:
start += 100
# csv로 저장
import pandas as pd
data = pd.DataFrame(total)
data.to_csv(cate + ".csv", encoding='utf-16')
# 4개 토픽 스레드로 처리
import threading
category = ['phonology', 'semantics', 'syntax', 'morphology']
thread_count = len(category)
threads = []
# 새로운 스레드 생성/실행 후 스레드 리스트에 추가
for i in range(thread_count):
thread = threading.Thread(target=crawl, args=( (category[i], ) ))
thread.start()
threads.append(thread)
# 메인 스레드는 각 스레드의 작업이 모두 끝날 때까지 대기
for thread in threads:
thread.join()
{kind=link}