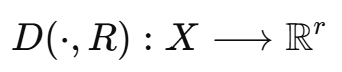
abstract
대부분의 패턴 인식 기법은 전통적으로 feature space을 기반으로 개발되어 왔다. 그러나 최근 연구들은 dissimilarity space과 같은 대안적 데이터 표현이 더 풍부한 정보를 제공하여 지식 발견 과정을 향상시킬 수 있음을 보여준다. 본 논문은 가장 가까운 이웃 세 개(triplet) 를 이용하는 2-order 비유사도 측정을 적용해 새로운 비유사도 공간을 생성하는 방법을 제안한다. 전통적인 유클리드 거리와 비교할 때, 비유사도 측정은 데이터의 희소성(sparsity)에 더 적합하다. 클래스 간 중첩(overlap) 을 줄이고 특징의 판별력을 높여 데이터를 더 잘 설명한다. 그 결과, 비유사도 공간에서 클러스터링 알고리즘을 적용하면 원래의 특징 공간이나 유클리드 비유사도 공간보다 오류율이 감소한다.
📏 비유사도 공간(dissimilarity space)
이미지에서 직접 특징을 뽑는 대신, 미리 고른 프로토타입들과의 거리만을 차례대로 나열해 숫자 벡터로 바꾸는 방법이다. 어떤 자료형이든 기존 벡터 기반 알고리즘에 그대로 넣을 수 있어 특징 추출의 번거로움을 줄이고 다양한 데이터 유형을 한꺼번에 다룰 수 있다.
introduction
일반적으로 객체는 객체를 특징짓고 클래스 구분에 유용한 feature들의 집합으로 표현된다. 특히 유클리드 벡터 공간이 가장 널리 쓰인다. 그러나 feature 기반 표현은 객체를 완전하게 기술하기 어렵기 때문에 클래스 간 중첩(overlap)이 발생하여 학습 효율이 떨어진다.
특징 기반 표현의 한계를 극복하기 위해, 두 객체 쌍을 비교해 얻는 dissimilarity에 기반한 표현을 사용한다. 비유사도 표현에서는 클래스 중첩 문제를 해결한다. 각 객체에 대해 비유사도 벡터를 구성하여 비유사도 공간을 만든다.
본 논문은 최근접 이웃 삼중항(triplet)에 기반한 second-order 비유사도 측정을 이용해 비유사도 증가 공간(Dinc space)을 제안한다. 이 비유사도 공간은 객체와 대표 객체 집합 사이의 비유사도를 기반으로 구축된다. 대표 객체는 프로토타입과 그 최근접 이웃이 이루는 간선(edge) 으로 정의된다. 공정한 비교를 위해 동일한 대표 객체 집합에 대해 유클리드 거리 기반 비유사도 공간(Euclidean space)도 함께 구축하였다. 실험 결과, 2차 비유사도 공간은 원래 특징 공간에 비해 정확도가 상당히 향상됐다.
Dissimilarity Representation
비유사도 표현은 한 대상과 여러 prototype 사이의 비유사도로 채워진 행렬로 정의된다. 이 행렬의 각 행은 비유사도 공간에서 하나의 벡터를 이루며, 그 차원 수는 대표 객체 집합의 크기와 같다.
데이터 집합: X = {x1, x2, ..., xn} (xi는 특징 벡터)
prototype 집합: R = {e1, e2, ...,er}
비유사도 벡터: 각 원소는 xi가 prototype ej와의 비유사도를 나타내는 거리 스칼라값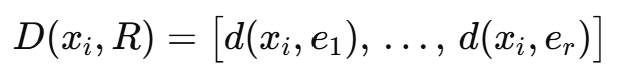
본 논문에서는 실험의 단순화를 위해 대표 객체 집합을 전 데이터셋으로 설정하여 비유사도 공간은 정방행렬로 표현된다. 두 가지 비유사도 공간을 실험한다.
① Euclidean Space (유클리드 공간)
비유사도 함수로 유클리드 거리 사용 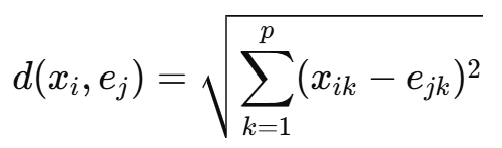
행렬 D의 원소 Dij는 샘플 i와 j 사이의 유클리드 거리이다.
② Dinc Space(Dissimilarity Increments Space) (비유사도 증가 공간)
최근접 이웃 세 개(triplet)를 활용한 second-order 비유사도 측정에 기반한다. 다음 절에서 자세히 설명한다.
Dissimilarity Increments Space(비유사도 증분 공간)
우선 비유사도 증분(dissimilarity increments)의 개념을 정의한다. 임의의 객체 xi에 대해, triplet (xi, xj, xk)은 다음과 같이 얻는다. 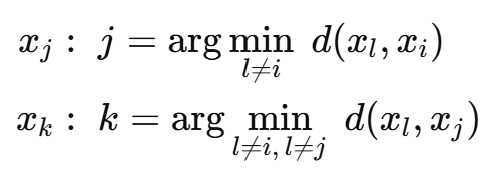
xi: 현재 객체
xj: xi에서 가장 가까운 다른 점
xk: xj에서 가장 가까운 또다른 점
인접 객체 간 비유사도 증분은 삼중항 (xi, xj, xk)에서 거리의 차로 정의된다.
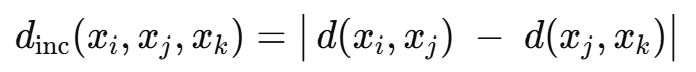
여기서 d(⋅,⋅)는 임의의 비유사도 함수이며, 본 논문에서는 유클리드 거리를 사용한다. 이 척도는 단순한 distance보다 데이터 구조를 잘 드러낸다. 인접 객체들 사이에서는 값이 작고, 클래스 간 간격이 넓을수록 값이 커진다. 특히 희소 클래스에 속한 객체를 쉽게 식별할 수 있다.
대표 객체 집합은 두 객체를 잇는 간선이다. 대표 객체 ej는 프로토타입 mj와 그 최근접 이웃 xmj로 이뤄진 간선이다. 간선의 가중치는 간선의 길이와 같다.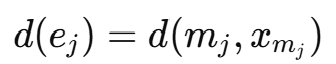
임의의 객체 xi와 대표 객체 ej 사이의 거리는 간선의 끝점중에서 짧은 쪽을 택한다. 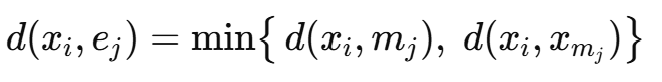
본 논문에서는 위 증분 척도를 기반으로 한 새로운 표현인 비유사도 증분 공간(Dinc space)을 제안한다. 각 객체는 n-차 비유사도 벡터로 나타내되, d(⋅,⋅)는 유클리드 거리가 아니라 객체–대표 간 증분 거리다. 따라서 Dinc 공간의 (i,j) 원소는 간선의 길이와 간선 끝점까지의 거리의 차이다.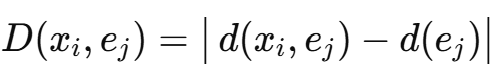
Dinc 공간은 대표 객체(프로토타입–이웃 간선)을 기준으로, 객체가 그 간선에서 얼마나 더 멀어졌는지를 각 축으로 삼아 데이터를 표현한다. 이는 2차원의 정보까지 포섭한다는 점에서 전통적인 유클리드 기반 비유사도 공간보다 풍부한 표현력을 제공한다.
Characterization of the Dissimilarity Spaces(비유사도 공간 특성 분석)
지금까지 객체 집합을 표현하기 위해 비유사도 공간을 구축했다. 유클리드 공간과 Dinc 공간 모두 feature 공간 위에 만들어졌다. 분류 문제의 기하학적 복잡도 지표를 이용해 두 공간의 특성을 평가하고, 학습 문제가 특징 공간보다 비유사도 공간에서 더 쉬워지는지 확인하자. 지표는 다음 세 범주로 나뉜다.
① 클래스 간 특성 값 중첩(overlap): 각 클래스 내부 값의 분포를 살펴 상호 중첩 정도를 측정한다.
② 클래스 분리 가능성(separability) 측정: 클래스 경계 존재 여부와 형태를 바탕으로 두 클래스의 분리 정도를 평가한다.
③ 기하·위상·밀도 지표: 각 클래스를 하나 또는 여러 manifold로 가정하고, 그 형태·위치가 클래스 분리에 끼치는 영향을 측정한다.
표 1을 통해 두 비유사도 공간이 F1‧F4 모두에서 특징 공간보다 높은 값을 보임을 알 수 있다. 이는 차원이 증가했음에도 불구하고, 특징 판별력이 향상되고 클래스 중첩이 감소했음을 의미한다. 또한 L2와 N2 값이 두 비유사도 공간에서 감소하여, 클래스 간 겹침이 줄어들고 서로 다른 클래스 샘플을 분리하기가 더 쉬워졌음을 시사한다. 반면, 매니폴드의 기하·위상 복잡도를 나타내는 N4는 오히려 증가했는데, 이는 클래스가 더 잘 분리되어도 1-최근접 이웃 기준으로는 비선형 경계가 형성되었음을 뜻한다.
Conclusion
본 논문에서는, 최근접 이웃 삼중항을 이용한 2차 비유사도 척도로 데이터를 표현하는 Dinc 공간을 제안한다. 각 원소는 객체 – 대표 간선 사이 비유사도 증가값으로 정의되어 희소 클래스까지 잘 식별한다. 실험에서는 전체 데이터셋을 대표 객체로 사용해 차원이 늘었음에도, Dinc 공간의 특징이 더 판별력 높고 클래스 중첩이 감소함을 확인했다. 36개 벤치마크에 대해 계층적 클러스터링을 적용한 결과, Dinc 공간이 원본 특징 공간과 유클리드 비유사도 공간보다 낮은 오류율을 기록했다. 추후에는 차원을 줄이고 계산 효율을 높이기 위해 프로토타입 선택 전략을 탐색할 예정이다. Dinc 공간은 기존 표현보다 클래스 분리와 클러스터링 정확도를 크게 개선하며, 추후 대표 객체를 최적 선택해 더 가벼운 모델을 만드는 것이 과제로 남는다.
