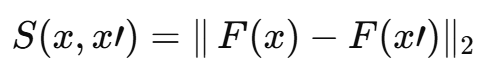
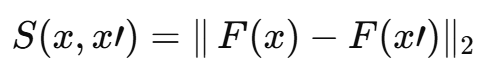
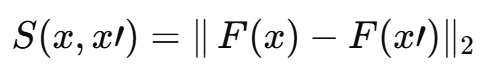
Abstract
본 논문은 거리 비교를 통해 유용한 표현을 학습하도록 고안된 triplet network 모델을 제안한다. 유사한 아이디어가 제시된 바 있으나, 본 논문은 다양한 데이터셋에서 더 뛰어난 표현을 학습함을 보여 준다. 또한 이 모델이 향후 비지도 학습 프레임워크로 활용될 가능성도 논의한다.
Introduction
지난 몇 년간 딥러닝 모델은 다양한 기계학습 과제를 해결하기 위해 폭넓게 활용돼 왔다. 특히 CNN과 같은 깊고 계층적인 모델은 데이터를 효과적으로 embedding 하여, 이후 주어진 클래스를 구별하는 데 도움을 준다. 하지만 이렇게 중요한 feature representation과 그에 의해 정의되는 metric은 분류 작업의 부산물로 간주되고, 별도로 학습 대상이 되지 않았다. 지금까지 metric 학습을 시도한 대표 사례는 시암 네트워크(Siamese Network) 계열로, 여기서는 contrastive loss을 이용해 유사 쌍은 가깝게, 비유사 쌍은 멀게 학습한다. 그러나 Siamese Network가 만들어 내는 표현은 다른 딥러닝 모델보다 분류 특성이 떨어지고, 유사와 비유사의 기준이 문맥에 따라 달라지는 보정(calibration) 문제에도 민감하다. 실제로 우리는 실험 과정에서 Siamese Network 사용의 어려움을 직접 경험한다.
본 연구는 Chechik이 제안한 작업과 유사한 목표를 따른다. 샘플 집합 P와 대략적 유사도 척도 r(x,x')가 주어질 때, 우리는 normed metric이 유도하는 유사도 함수 S(x,x')를 학습하고자 한다. 다른 연구와 달리, 우리의 라벨은 삼중항(triplet) 형태 r(x, x1) > r(x, x2) 로 주어진다. 즉 모든 객체 x에 대해 (x, x1)이 (x, x2)보다 더 가깝다는 비교 정보만 확인한다. 실험에서는 다중 클래스가 달린 데이터셋에 대한 메트릭 임베딩 F(x)을 찾는다. 여기서 x와 같은 클래스인 샘플을 x+, 다른 클래스를 x− 로 두고, S(x,x+) > S(x,x−) 조건을 만족하도록 L2 임베딩 F(x) 를 학습한다. 우리는 이 접근을 트리플릿 네트워크(Triplet Network) 라 부른다.
The Triplet Network
트리플릿 네트워크(Triplet Network)는 Siamese network에서 영감을 받아 동일한 구조와 파라미터를 공유하는 feed forward network 3개로 이루어진다. 3개의 샘플 x(앵커), x+(양성), x−(음성)을 동시에 입력하면, 네트워크는 두 개의 L2 거리를 중간층에서 산출한다. 각 행은 기준 x와 다른 두 샘플 사이의 임베딩 거리 한 쌍을 담는다.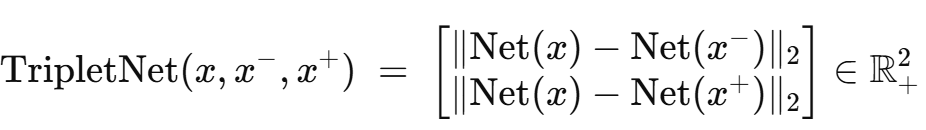
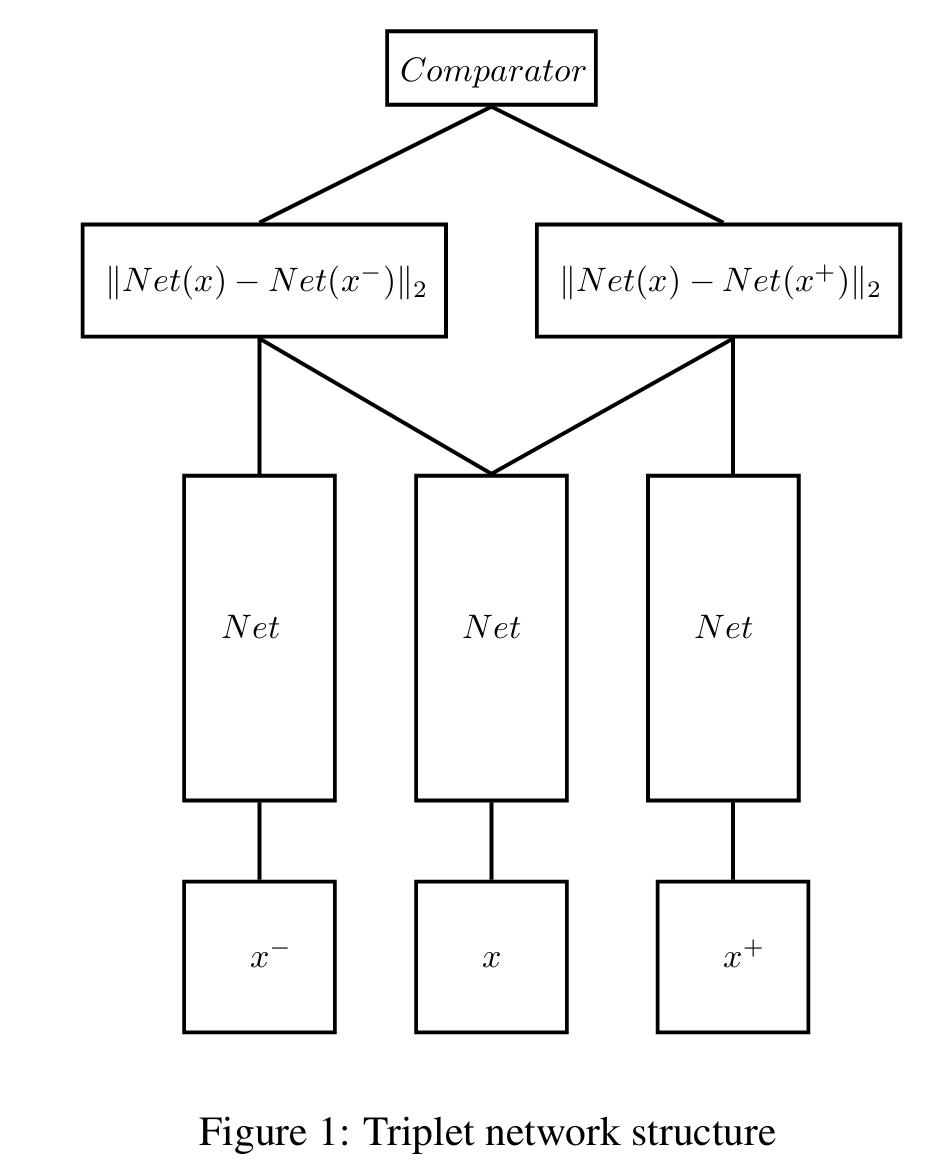
❓Net(x)는 입력 샘플 x 을 triplet network의 합성곱->풀링->완전연결 계층들을 차례로 통과시켜 얻은 최종 임베딩 벡터다. 이 벡터들 간의 L2 거리가 곧 모델이 학습한 metric이므로, Triplet Loss는 Net(x)들 사이의 거리를 직접 줄이고 벌리며 임베딩 공간을 정렬한다.
샘플 구성: x, x+(x와 같은 클래스), x−(x와 다른 클래스)
'x와 더 가까운 쪽이 어느 샘플인가?' 를 맞히는 문제로 보면, 네트워크 전체를 이진 분류기처럼 다룰 수 있다. 두 거리에 Softmax를 씌워 d+, d− (가까울수록 1에 가까운 확률)로 변환한다.
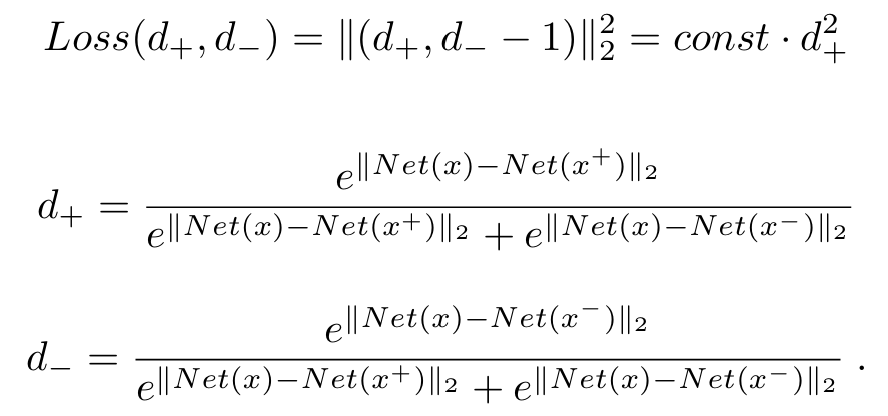
손실이 0으로 수렴하려면 양성 거리가 음성 거리보다 충분히 작아져야 한다. 세 네트워크가 동일한 파라미터를 공유하므로, back propagation 과정에서 3개의 샘플의 정보가 한꺼번에 모델을 업데이트한다.
Tests And Results

Triplet Network는 라벨 없이 단순 비교만으로 학습했음에도 전통 CNN 수준의 정확도를 달성했다. 특히 STL-10처럼 데이터가 적은 환경에서 무증강 최고 성능을 기록해 Siamese 대안으로서 우수성을 입증했다.
Future Work
Triplet 네트워크는 정확한 레이블이 아니라 샘플 간 비교 정보만으로도 학습이 가능하므로, unsupervised 학습 프레임워크로 확장될 여지가 크다. 저자들은 다음과 같은 방향을 제안한다. 공간 정보 활용 같은 이미지에서 공간적으로 가까운 두 객체는 의미적으로도 유사할 가능성이 높다. 따라서 한 이미지 안 패치 간 기하학적 거리를 대략적인 유사도 오라클 r(x, x')로 삼아 Triplet 네트워크를 비지도로 학습할 수 있다. 사람은 절대 레이블을 붙이는 것보다 “A와 B 중 더 비슷한 것은?” 같은 label 제공이 더 쉽고 정확하다. Triplet 네트워크는 이러한 비교식 라벨을 그대로 받아들일 수 있어, Tamuz의 방식과 비교되는 크라우드소싱 학습 환경에 적합하다. 또한 같은 장소에서 찍힌 사진, 공통 태그·주석처럼 손쉽게 얻어지는 비교 정보만으로도 학습 데이터를 대량 수집할 수 있다는 이점이 있다.
Conclusions
본 논문에서는 Triplet Network 모델을 제안하였다. 이 모델은 딥러닝 신경망을 이용한 embedding을 직접적으로 학습하도록 설계되었다. 여러 데이터셋에 대한 실험 결과, 본 모델이 학습한 표현은 전통적인 분류용 네트워크가 학습한 표현과 동등한 수준으로 분류 작업에 효과적임을 보여준다.
또한 Network-in-Network, Inception 등의 최신 임베딩 구조를 결합하면, 기존 분류 문제에서 그러했듯 트리플릿 네트워크의 성능도 더욱 향상될 것으로 기대된다.
트리플릿 네트워크는 간단한 비교 정보만 알면 된다는 점에서 큰 잠재력을 지닌다. 이러한 특성은 딥러닝 네트워크가 학습하는 방식을 이해하는 데 새로운 통찰을 제공할 수 있으며, 명확한 라벨이 없거나 라벨 정의가 모호한 새로운 데이터 소스를 활용하는 길을 열어 준다.
본 연구는 비교 기반(supervised by comparisons) 학습만으로도 고품질 표현을 얻을 수 있음을 입증하며, 추후 임베딩 네트워크 고도화 및 라벨 부족 환경에서의 확장 가능성을 중요한 미래 과제로 제시한다.
