Abstract
합성곱 신경망은 discriminative features을 학습하는 데 있어 뛰어난 성능을 보여 왔지만, 보지 못한 도메인에 대해서는 일반화 성능이 낮은 경우가 많다. 도메인 일반화는 여러 source domains으로부터 학습한 모델이 임의의 보이지 않는 도메인에서도 잘 일반화되도록 만드는 것을 목표로 한다.
본 논문에서는 서로 다른 source domain에 속한 학습 샘플들의 인스턴스 수준 특징 통계를 확률적으로 혼합하는 새로운 접근법을 제안한다. 제안하는 방법인 MixStyle은 시각적 도메인이 이미지의 스타일과 밀접하게 연관되어 있다는 관찰에서 출발한다. 이러한 스타일 정보는 CNN의 하위 계층에서 포착되며, MixStyle의 스타일 혼합 또한 이 계층에서 수행된다.
학습 인스턴스들의 스타일을 혼합함으로써, 새로운 도메인이 암묵적으로 합성되며, 이는 source domain의 다양성을 증가시켜 결과적으로 학습된 모델의 일반화 성능을 향상시킨다. MixStyle은 미니배치 학습 과정에 자연스럽게 통합될 수 있으며, 구현 또한 매우 간단하다. 본 논문에서는 분류, 인스턴스 검색, 강화학습 등 다양한 과제를 통해 MixStyle의 효과를 실험적으로 입증한다.
Introduction
디지털 이미지를 자동으로 이해하기 위한 핵심은 간결하면서도 정보가 풍부한 특징 표현을 계산하는 것이다. 합성곱 신경망은 표현 학습에서 뛰어난 성능을 보여 왔으며, ImageNet에서 1000개 범주의 사진 이미지를 분류하는 작업이나 강화학습을 이용해 Atari 게임을 수행하는 작업 등 다양한 시각 인식 과제에서 그 효과가 입증되었다. 그러나 CNN의 성공은 i.i.d. 가정(independent and identically distributed assumption)—즉, 학습 데이터와 테스트 데이터가 동일한 분포에서 샘플링된다는 가정—에 크게 의존한다는 사실이 오래전부터 알려져 있다. 실제 환경과 같이 이 가정이 조금만 위배되더라도, 심각한 성능 저하가 발생할 수 있다.
도메인 일반화는 이러한 문제를 해결하고자 하는 연구 분야이다. 특히 동일한 시각적 클래스들을 포함하는 여러 source domain이 학습에 주어졌다고 가정할 때, 도메인 일반화의 목표는 도메인 간 데이터 분포 변화, 즉 domain shift에 강건한 모델을 학습하여, 보지 못한 어떤 도메인에서도 잘 일반화되도록 하는 것이다. 이와 밀접하게 관련되었고 더 널리 연구된 도메인 적응 문제와 비교하면, 도메인 일반화는 훨씬 어렵다. 이는 도메인 적응과 달리, 분포 차이를 분석하고 그 부정적 영향을 완화하기 위해 활용할 수 있는 target domain 데이터가 전혀 주어지지 않기 때문이다. 따라서 도메인 일반화 모델은 source domain에만 의존하여, target domian에서도 여전히 구별력을 유지할 수 있기를 기대하며 도메인 불변 특징 표현을 학습해야 한다.
도메인 일반화에 대한 가장 직관적인 해결책은 가능한 한 다양한 source domain으로 모델을 학습시키는 것이다. 보다 구체적으로, 다양한 source domain의 데이터가 제공될수록 도메인 불변적이며 일반화 가능한 특징 표현을 학습하는 문제는 더 쉬워진다. 이는 도메인 일반화를 위해 특별한 모델 구조나 학습 알고리즘을 설계해야 하는 부담을 줄여준다. 실제로 다양한 도메인을 포함하는 대규모 데이터로 모델을 학습하는 방식은 상용 얼굴 인식 시스템이나 비전 기반 자율주행 시스템의 성공 배경이기도 하다. 최근 연구 또한 분포 외 일반화를 위해 학습 분포의 다양성이 중요함을 강조한다. 그러나 현실적으로 다양한 도메인의 데이터를 수집하는 것은 비용이 많이 들거나 아예 불가능한 경우가 많아, 도메인 일반화에 대한 보편적인 해결책이 되기는 어렵다.
본 논문에서는 서로 다른 source domain에 속한 학습 샘플들의 인스턴스 수준 특징 통계를 확률적으로 혼합하는 새로운 접근법을 제안한다. 제안하는 모델인 MixStyle은 시각적 도메인이 이미지의 스타일과 밀접하게 관련되어 있다는 관찰에서 출발한다.
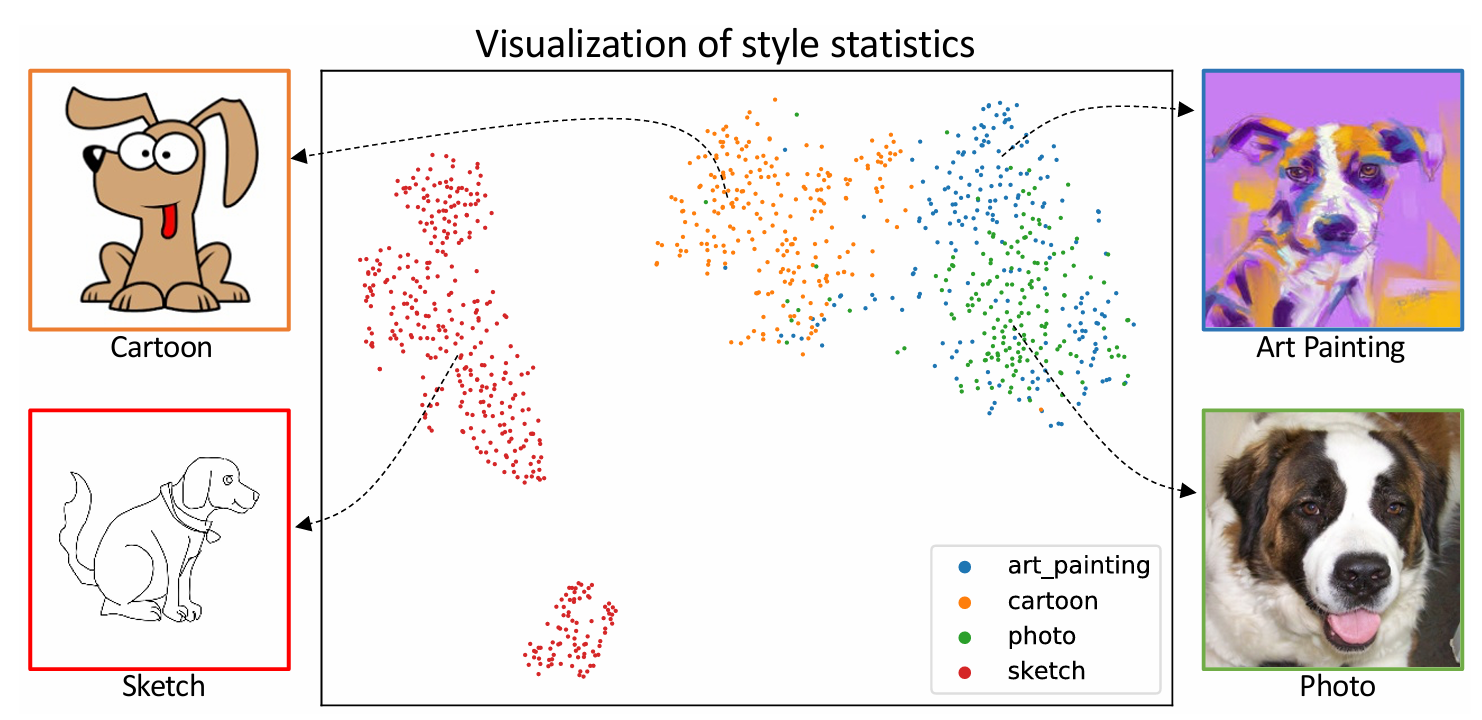
서로 다른 네 개의 도메인에서 가져온 이미지는 동일한 의미적 개념을 묘사하지만, 색상이나 질감과 같은 스타일 특성은 서로 다르다. 이러한 이미지들이 원시 픽셀 값을 범주 레이블로 매핑하는 딥 CNN에 입력되면, 출력 단계에서는 스타일 정보가 제거된다. 그러나 최근의 스타일 전이 연구들에 따르면, 이러한 스타일 정보는 CNN의 하위 계층에서 인스턴스 수준 특징 통계(mean, std)의 형태로 보존된다. 중요한 점은, 이 통계를 다른 값으로 대체하더라도 이미지의 의미적 내용은 유지된 채 스타일만 변경된다는 것이다. 따라서 서로 다른 도메인의 이미지들로부터 스타일을 혼합하면, 새로운 혼합된 스타일의 이미지가 생성된다고 가정하는 것이 합리적이다. 이는 곧, 보다 다양한 도메인/스타일을 학습에 활용할 수 있음을 의미하며, 결과적으로 도메인 일반화 성능이 향상된 모델을 학습할 수 있다.
구체적으로, MixStyle은 서로 다른 도메인에 속한 두 인스턴스를 무작위로 선택하고, CNN 하위 계층의 인스턴스 수준 특징 통계 사이에서 확률적 볼록 결합을 적용한다. 기존의 스타일 전이 연구와 달리, 새로운 스타일의 이미지를 명시적으로 생성할 필요가 없으므로 모델 설계가 훨씬 단순하다. 또한 MixStyle은 현대적인 미니배치 학습 과정에 자연스럽게 통합될 수 있으며, 몇 줄의 코드만으로 쉽게 구현할 수 있다. MixStyle의 효과와 범용성을 검증하기 위해, 본 논문에서는 분류, 인스턴스 검색, 강화학습을 포함한 다양한 데이터셋과 과제에 대해 광범위한 실험을 수행한다. 그 결과, MixStyle이 CNN의 cross-domain 일반화 성능을 크게 향상시킬 수 있음을 보인다.
Methodology
ⓐ background
인스턴스별 평균과 표준편차를 이용해 특징 텐서를 정규화하는 방식은, 스타일 전이 모델에서 이미지 스타일을 제거하는 데 효과적임이 알려져 있다. 이러한 연산은 인스턴스 정규화라고 불린다.
배치 크기, 채널 수, 높이, 너비를 각각 B,C,H,W라 할 때, 입력 특징 텐서를 x∈R(B×C×H×W)라고 정의하면, IN은 다음과 같이 표현된다.
여기서 γ,β는 학습 가능한 affine 변환 파라미터이며, μ(x),σ(x)는 각 인스턴스와 각 채널에 대해 공간 차원(H×W)에서 계산된 평균과 표준편차이다. 구체적으로, 평균은 다음과 같이 계산된다.
표준편차는 다음과 같이 정의된다.
적응형 인스턴스 정규화는 scale과 shift 파라미터를 스타일 입력 y의 특징 통계로 대체함으로써 임의의 스타일 전이를 가능하게 한다.
ⓑ Mixstyle
제안하는 방법인 MixStyle은 AdaIN에서 영감을 받았지만, 이미지 생성을 위한 디코더를 추가하는 대신, source domian 학습 인스턴스의 스타일 정보를 교란함으로써 CNN 학습을 정규화하는 것을 목표로 한다. MixStyle은 지도 학습 CNN 분류기와 같은 모델의 CNN 계층 사이에 삽입되는 plug-and-play 모듈로 구현될 수 있으며, 새로운 스타일의 이미지를 명시적으로 생성할 필요가 없다.
보다 구체적으로, MixStyle은 두 개의 인스턴스에서 계산된 특징 통계를 무작위 볼록 가중치로 혼합하여 새로운 스타일을 모사한다. 구현 관점에서 MixStyle은 미니배치 학습에 매우 쉽게 통합될 수 있다. 입력 배치 x가 주어지면, MixStyle은 먼저 x로부터 참조 배치 x~를 생성한다.
도메인 레이블이 주어지는 경우, x는 서로 다른 두 도메인 i와 j에서 샘플링되며, 예를 들어 x=[xi, xj]와 같이 구성된다. 이후 xi와 xj의 위치를 서로 교환한 뒤, 각 배치에 대해 배치 차원에서 shuffle 연산을 적용하여 x~=[Shuffle(xj),Shuffle(xi)]를 얻는다. 도메인 레이블이 없는 경우에는, x를 학습 데이터로부터 무작위로 샘플링하고, x~=Shuffle(x)을 통해 참조 배치를 생성한다.
셔플 이후, MixStyle은 다음과 같이 혼합된 특징 통계를 계산한다.
여기서 λ∈R(B)는 인스턴스별 가중치로, 베타 분포에서 샘플링된다. α∈(0,∞)는 하이퍼파라미터이며, 본 논문에서는 별도의 언급이 없는 한 α=0.1로 설정한다. 마지막으로, 이렇게 얻은 혼합 통계를 스타일 정규화된 입력 x에 적용한다.
실제 구현에서는, 순전파 시 확률 0.5로 MixStyle을 적용할지 여부를 결정한다. 테스트 단계에서는 MixStyle을 사용하지 않는다. 또한 μ(⋅)와 σ(⋅)에 대해서는 그래디언트가 차단되어 역전파 시 업데이트되지 않는다.
Related work
ⓐ Domain generalization
도메인 일반화는 일반적으로 여러 개의 서로 관련되어 있지만 구별되는 도메인으로 구성된 소스 데이터만을 사용하여, 분포 외 상황에서의 일반화를 연구하는 분야이다. 많은 도메인 일반화 방법들은 서로 다른 소스 간의 feature alignment에 기반하고 있으며, 보지 못한 데이터에 대해서도 모델이 domain shift에 불변적이기를 기대한다. 예를 들어, Li et al. (2018b)은 최대 평균 차이를 이용해 오토인코더의 은닉 표현에서 분포 정렬을 달성하였고, Li et al. (2018c)은 보조 도메인 분류기를 활용한 적대적 학습을 통해 도메인에 독립적인 특징을 학습하였다. 또한 도메인별 가중치 행렬이나 도메인별 배치 정규화와 같이 domain-specific 파라미터화를 탐구한 연구들도 있다. 최근에는 메타러닝이 도메인 일반화 연구 커뮤니티에서 큰 주목을 받고 있는데, 이는 source domian으로부터 구성된 가상의 학습/테스트 도메인을 사용하여 학습 과정 중에 모델이 domain shift를 직접 경험하도록 하는 방식이다. 이와 더불어, 도메인 불변 모델을 학습하기 위한 데이터 증강 기법들도 연구되어 왔다. Shankar et al. (2018)은 도메인 분류기로부터 얻은 적대적 그래디언트를 이용해 소스 데이터를 증강하는 CrossGrad 방법을 제안하였다. Gong et al. (2019)은 도메인 적응 문제를 위해 DLOW를 제안했는데, 이는 도메인 정도를 통해 소스와 타깃 사이의 중간 도메인을 모델링하고, 중간 도메인 이미지를 생성하는 이미지 변환 모델을 학습한다. 이후 Zhou et al. (2020a)은 L2A-OT를 제안하여, 최적 수송 기반 거리 측정을 최대화함으로써 소스 데이터를 가상의 새로운 도메인으로 매핑하는 신경망을 학습하였다. MixStyle은 이러한 DLOW 및 L2A-OT와 마찬가지로 새로운 도메인을 합성하려는 목적을 공유한다. 그러나 MixStyle은 feature-level의 스타일 통계를 활용하는 훨씬 단순한 방식으로 이를 암묵적으로 수행하며, 표준 지도 학습 분류기에 몇 줄의 코드만 추가하면 구현할 수 있음에도 불구하고 더 효과적이다. 본질적으로 MixStyle은 feature-level augmentation으로 볼 수 있으며, 이는 이미지 수준 증강에 기반한 DLOW나 L2A-OT와 명확히 구별된다.
ⓑ generalization in deep RL
딥 강화학습에서의 일반화는 오랫동안 어려운 문제로 여겨져 왔으며, RL 에이전트는 학습 환경에 과적합되어 서로 다른 시각적 패턴이나 난이도를 가진 보지 못한 환경에서는 성능이 급격히 저하되는 경우가 많다. 일반화를 향상시키는 자연스러운 방법으로는 가중치 감쇠와 같은 정규화가 있으며, 이는 여러 연구에서 효과가 입증되었다. 그러나 Igl et al. (2019)은 드롭아웃이나 배치 정규화처럼 확률적인 정규화 기법들이, RL에서는 학습 데이터가 본질적으로 모델 의존적이기 때문에 오히려 부정적인 영향을 미칠 수 있음을 지적하였다. 이에 따라 이들은 확률적 기법과 결정론적 기법을 결합한 선택적 노이즈 주입을 제안하고, 이를 정보 병목 액터-크리틱과 결합한 IBAC-SNI로 확장하여 그래디언트 분산을 줄였다. 또한 Justesen et al. (2018)은 학습 난이도를 점진적으로 증가시키는 커리큘럼 학습을 탐구하였고, Gamrian & Goldberg (2019)은 GAN 기반 image-to-image 변환 기법을 활용해 target data를 에이전트가 학습한 source domain으로 매핑하였다. Tobin et al. (2017)은 프로그래머블 시뮬레이터를 이용해 다양한 시각 효과를 가진 이미지를 렌더링함으로써 학습 데이터를 다양화하는 도메인 랜덤화를 제안하였다. 이와 유사한 데이터 증강 목표 하에서, Lee et al. (2020)은 무작위로 초기화된 네트워크를 이용해 입력 이미지를 사전 처리하는 방법을 제안하였다. 최근 연구들은 회전, 이동, Cutout과 같은 레이블 보존 변환을 다양하게 결합하는 것이 효과적임을 보였다. 이러한 기존 방법들과 달리, MixStyle은 feature-level에서 작동하며 대부분의 기존 기법들과 직교적이다. MixStyle은 IBAC-SNI 대비에서도 유의미한 성능 향상을 보인다.
Conclusion
본 논문에서는 MixStyle라 불리는 단순하면서도 효과적인 도메인 일반화 방법을 제안하였다. MixStyle은 두 인스턴스의 특징 통계를 혼합하여 새로운 도메인을 합성하는데, 이는 특징 통계가 스타일 및 도메인 관련 정보를 담고 있다는 스타일 전이 연구의 관찰에 기반한다. 분류, 인스턴스 검색, 강화학습을 포함한 다양한 과제를 아우르는 광범위한 실험을 통해, MixStyle이 세 가지 서로 다른 과제에서 새로운 최고 성능을 달성함을 입증하였다.
