Abstract
Cross-domain few-shot learning(CDFSL)은 데이터가 충분한 source domain에서 학습한 지식을 데이터가 매우 부족한 target domain으로 전이하는 것을 목표로 한다. Vision Transformer(ViT)는 다양한 비전 과제에서 뛰어난 성능을 보여주었지만, CDFSL과 같이 도메인 간 차이가 매우 큰 환경에서의 전이 성능에 대해서는 아직 충분히 연구되지 않았다. 본 논문에서는 흥미로운 현상을 발견하였다. Source domain 학습 과정에서 ViT를 학습하는 일반적인 방법인 prompt tuning이 오히려 target domain에서의 일반화 성능을 저하시킬 수 있는 반면, 프롬프트를 random noises로 설정한 경우(=random registers)에는 target domain 성능이 일관되게 향상된다는 것이다.
이후 우리는 이러한 현상에 대한 해석을 제시한다. 분석 결과, 학습 가능한 프롬프트(learnable prompts)는 source dataset에서 학습되는 동안 도메인 정보를 흡수하며, 실제로는 인식과 무관한 시각적 패턴을 중요한 단서로 간주하게 된다. 이는 일종의 overfitting으로 볼 수 있으며, 손실 지형의 sharpness를 증가시킨다. 반면, random registers는 어텐션을 교란하는 새로운 방식으로 작동하며, 이는 sharpness-aware minimization(SAM)의 관점에서 모델이 더 평탄한 손실 최소값을 찾도록 도와 전이 성능을 향상시킨다.
이러한 현상과 해석을 바탕으로, 우리는 CDFSL을 위한 간단하지만 효과적인 방법을 제안한다. 구체적으로, 이미지 토큰의 의미적 영역에 random registers를 추가함으로써 어텐션 맵에 가해지는 교란을 강화하고, random registers의 효과성과 효율성을 동시에 향상시킨다. 네 개의 벤치마크 데이터셋에서 수행한 광범위한 실험을 통해, 제안한 해석의 타당성과 최신 성능을 입증하였다.
Introduction
대규모 모델은 대규모 데이터셋으로부터 학습할 수 있는 능력 덕분에 다양한 과제에서 큰 성공을 거두었으며, 특히 비전 분야에서는 Vision Transformer(ViT) 기반 아키텍처가 주류를 이루고 있다. 그러나 실제 환경에서는 모든 도메인에 대해 충분한 데이터를 수집하는 것이 항상 가능하지 않기 때문에, 극단적인 cross-domain 저데이터 환경에서 ViT의 일반화 성능은 여전히 충분히 탐구되지 않았다. 이러한 문제를 해결하기 위해, Cross-Domain Few-Shot Learning(CDFSL)은 다수의 자연 이미지를 포함한 source domain에서 학습한 일반적인 지식을, 소수의 라벨만 존재하는 target domain으로 전이하는 것을 목표로 한다. 그러나 source domain과 target domain 사이의 domain gap으로 인해, source domain에서 학습된 ViT를 target domain의 few-shot 학습에 효과적으로 전이하는 것은 매우 어렵다.
이 문제를 다루기 위해, 본 연구에서는 ViT를 학습하는 일반적인 방법 중 하나인 Visual Prompt Tuning에 주목한다. 이 방법은 ViT의 입력 시퀀스에 학습 가능한 프롬프트(learnable prompts)를 추가로 연결하는 방식이다. 우리는 source domain 데이터셋에서 학습 가능한 프롬프트를 포함해 ViT를 학습한 뒤, 프로토타입 기반 방법으로 target domain 성능을 평가하였다. 그러나 이러한 일반적인 ViT 학습 방식이 오히려 target domain 데이터셋에서 현저한 성능 저하를 유발한다는 사실을 발견하였다. 반면, 흥미롭게도 프롬프트 학습을 완전히 포기하고, 이를 가우시안 노이즈로 무작위화한 경우, 얕은 프롬프트와 깊은 프롬프트 모두에서 프롬프트 수가 증가할수록 target domain 성능이 일관되게 향상되었다. 더 나아가, GPU 메모리가 허용하는 최대 개수의 프롬프트를 사용할 때 가장 높은 성능이 나타났다.
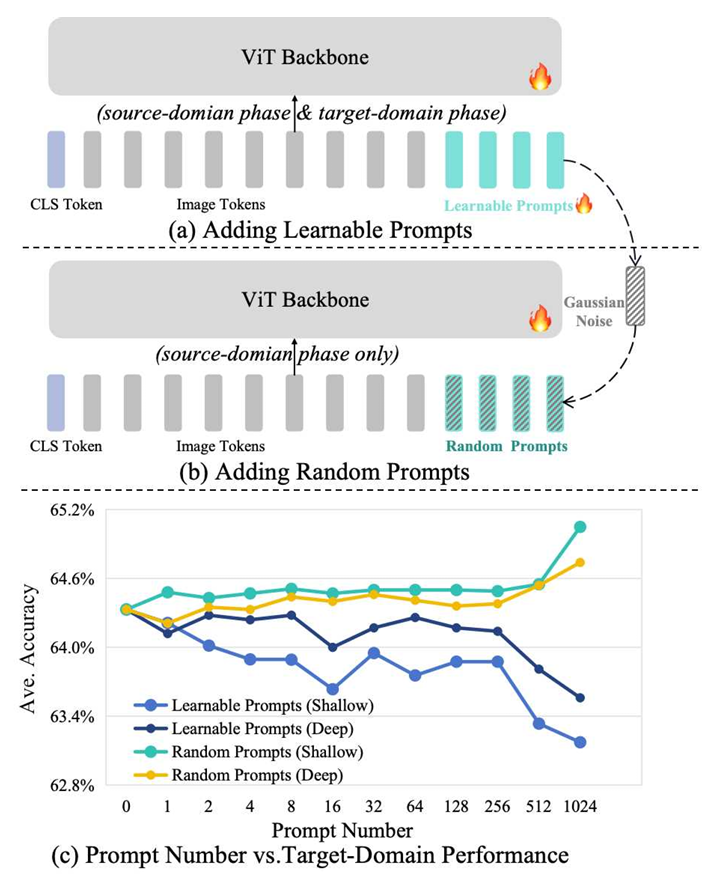
본 논문에서는 이러한 현상을 해석하기 위해 심층적인 분석을 수행한다. 얕은 프롬프트가 더 높은 성능을 보이면서 구조적으로도 단순하기 때문에, 우리는 주로 이 유형의 프롬프트에 초점을 맞추며, 이를 register라고 부른다. 먼저, target domain에서의 어텐션 맵을 분석한 결과, ViT의 어텐션 네트워크가 의미적 객체를 제대로 포착하지 못함을 관찰하였다. 이는 어텐션 자체가 도메인 간에 잘 전이되지 못했음을 시사한다. 이후, 어텐션에 가해지는 교란에 대해 손실 지형의 sharpness를 측정함으로써 어텐션의 전이 가능성을 정량적으로 평가하였다. 그 결과, 학습 가능한 registers는 전이 성능을 감소시키는 반면, random registers는 전이 성능을 향상시킨다는 사실을 확인하였다. 이에 착안하여, 우리는 random registers를 sharpness-aware minimization(SAM)을 수행하기 위한 어텐션 교란의 새로운 방식으로 해석하며, 이것이 target domain에서의 어텐션 전이를 개선한다고 설명한다. 반대로, 학습 가능한 registers는 source dataset 학습 과정에서 도메인 정보를 흡수하며, 이는 인식과 무관한 시각적 패턴을 중요한 단서로 간주하는 형태로 나타난다. 이러한 현상은 source domain에 대한 overfitting으로 볼 수 있으며, 손실 지형의 sharpness를 증가시키는 원인이 된다.
이러한 해석을 바탕으로, 우리는 random registers의 효과성과 효율성을 동시에 개선함으로써 ViT의 target domain 전이 성능을 향상시키는 간단하지만 효과적인 방법을 제안한다. Source domain 단계에서는 random registers의 핵심 역할이 어텐션 맵을 교란하는 데 있다는 점에 착안하여, 이미지 토큰의 의미적 영역에 random registers를 추가한다. 이는 클러스터링된 이미지 패치를 무작위 노이즈로 치환하는 방식으로 구현되며, 어텐션 맵에서 교란되는 정보의 비율을 증가시켜 random registers의 효율을 높인다. 반면, target domain 단계에서는 모든 토큰을 입력으로 유지한 채, 학습 가능한 registers를 프롬프트로 추가하여 파인튜닝을 수행함으로써 도메인 정보를 흡수하는 장점을 활용한다. 네 개의 데이터셋에서 수행한 실험 결과는 이러한 해석의 타당성을 입증하며, 제안 방법이 기존 state-of-the-art 기법들을 능가함을 보여준다.
마지막으로, 본 논문의 기여는 다음과 같이 정리할 수 있다.
-
source domain에서의 프롬프트 학습이 target domain으로의 전이 성능을 저해하지만, random registers를 사용하면 전이 성능이 일관되게 향상된다는 점을 최초로 발견하였다.
-
학습 가능한 registers는 도메인 정보를 흡수하여 인식과 무관한 영역에 주의를 집중시키는 반면, random registers는 어텐션 맵을 교란하여 sharpness-aware minimization을 유도한다는 해석을 제시하였다.
-
이러한 해석을 바탕으로, 이미지 토큰의 의미적 영역에 random registers를 추가하여 어텐션 교란을 강화하고, 모델 전이 성능을 향상시키는 새로운 방법을 제안하였다.
-
네 개의 벤치마크 데이터셋에서의 광범위한 실험을 통해, 제안 방법의 타당성과 최신 성능을 검증하였다.
Delve into the Registers in ViT-based
Cross-Domain Few-Shot Learning
ⓐ Preliminaries
본 논문에서는 DINO로 사전학습된 Vision Transformer(ViT)를 백본 네트워크로 사용한다. 얕은 프롬프트가 성능 변화에 더 큰 영향을 미치며 구조적으로도 단순하기 때문에, 이후 분석에서는 주로 이 유형의 프롬프트 학습에 초점을 맞춘다. 이 프롬프트는 CLS 토큰과 유사하게 입력 토큰 시퀀스에 추가되는 학습 가능한 토큰이다. 이러한 프롬프트를 registers라고 부른다.
이때 ViT의 입력 P는 다음과 같이 구성된다.
는 cls 토큰
는 이미지 토큰
는 register 토큰
ⓑ How do registers affect the attention?
Vision Transformer(ViT)는 self-attention 메커니즘을 핵심으로 하는 모델이기 때문에, 우리는 먼저 학습 가능한 registers와 random registers를 사용했을 때 target domain에서의 어텐션 맵을 시각화한다. ViT의 마지막 블록에서 추출된 CLS 토큰의 특징이 백본 네트워크의 최종 출력으로 사용되므로, 마지막 블록에서 CLS 토큰이 이미지 토큰들에 부여하는 어텐션 맵을 시각화하였다. 시각화 결과에서 빨간색은 높은 어텐션 값, 파란색은 낮은 어텐션 값을 의미한다.
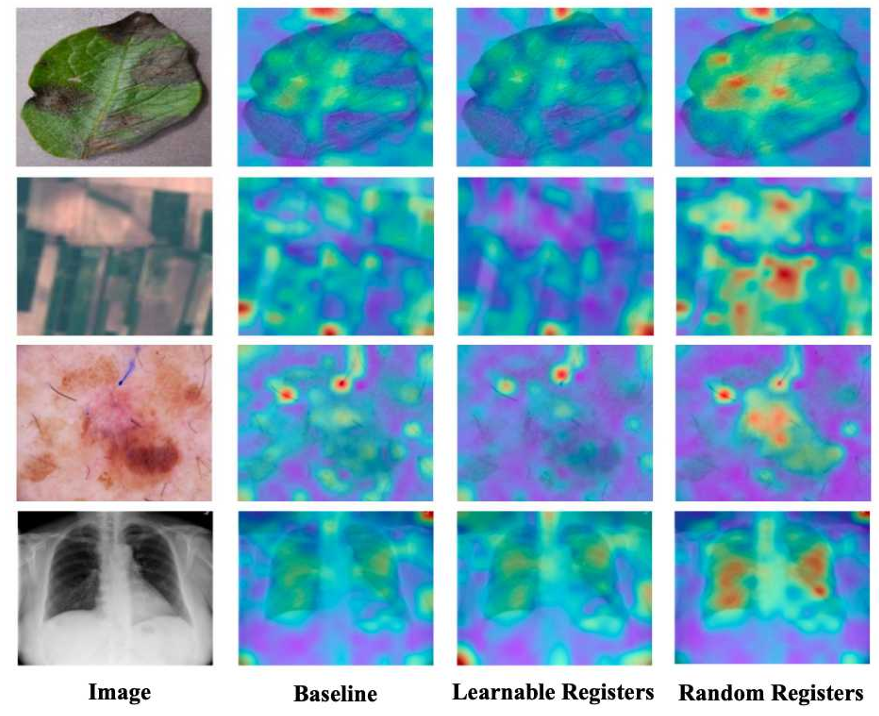
baseline 모델은 target domain으로 전이되었을 때 의미적인 영역을 제대로 포착하지 못한다. 여기에 학습 가능한 registers를 추가하면, 모델은 오히려 인식과 무관한 영역에 더욱 집중하게 된다. 반면, random registers를 추가한 경우에는 모델의 어텐션이 target domain에서의 의미적 객체로 효과적으로 유도된다. 이를 통해 우리는 ViT의 핵심 요소인 어텐션 네트워크 자체가 target domain으로 잘 전이되지 못하고 있을 가능성을 가설로 세운다.
이 가설을 검증하기 위해, 우리는 어텐션에 가해지는 교란에 대한 손실 지형의 sharpness를 측정함으로써 어텐션 네트워크의 전이 가능성을 정량적으로 평가한다. 구체적으로, source domain에서 잘 학습된 모델에 대해, 각 가중치 또는 표현은 손실 값에 대응되는 하나의 점으로 볼 수 있으며, 손실 지형에서의 각 최소점은 우수한 가중치 또는 표현을 의미한다. Sharpness는 데이터가 source domain에서 target domain으로 이동할 때 손실 값이 얼마나 크게 변하는지를 측정하며, 손실 변화가 작을수록 도메인 이동에 대한 강건성이 높음을 의미한다. 어텐션 네트워크의 sharpness를 평가하기 위해, 우리는 어텐션 맵에 가우시안 노이즈 형태의 교란을 추가한다.
여기서 A는 어텐션 맵을 의미하고, ϵ은 교란의 크기를 조절하는 노이즈 항이다. 모든 모델은 이러한 교란이 가해질 때 손실 값이 증가한다. 학습 가능한 registers를 사용하는 모델은 다른 모델들에 비해 일관되게 훨씬 높은 sharpness를 보이며, 이는 해당 모델이 도메인 변화에 덜 강건함을 의미한다. 반면, random registers를 사용하는 모델은 baseline보다도 손실 증가 폭이 작게 나타나며, 이를 통해 random registers가 어텐션의 전이 가능성을 향상시킨다는 점을 정량적으로 확인할 수 있다.
ⓒ Why do registers contribute to transferability?
앞선 분석을 바탕으로, 본 논문에서는 random registers를 sharpness-aware minimization(SAM)의 한 형태로 해석한다. SAM은 다음과 같이 정식화된다.
여기서 ω는 domain shift에 취약한 모델 구성 요소를 의미한다. 반면, 입력 시퀀스에 random registers를 추가하면 이는 어텐션 맵에서 다음과 같이 반영된다.
여기서 n은 이미지 내 전체 패치 수, n~은 ViT 입력 시퀀스에 추가된 register의 개수이다. 각 이미지 토큰 또는 CLS 토큰에 대해, 해당 토큰의 쿼리 Qi는 random register TiR로부터 생성된 무작위 키 K~와 곱해진다. 따라서 분모에 포함된 항 은 확률적으로 무작위 노이즈 항으로 작용하게 된다. 이러한 노이즈를 ϵR로 표기하면, SAM은 다음과 같이 다시 쓸 수 있다.
즉, random registers는 어텐션 맵 A 자체에 교란을 가하는 역할을 하며, 이는 SAM에서 가중치나 표현에 노이즈를 추가하는 것과 동등한 효과를 가진다. 어텐션은 domain shift에 특히 취약한 요소이므로, 어텐션 맵에 직접 노이즈를 추가하는 것은 합리적인 선택이다. 종합하면, random registers를 추가하는 것은 어텐션 맵에 교란을 가하는 새로운 방식의 SAM으로 볼 수 있으며, 이를 통해 모델은 더 평탄한 손실 최소값을 찾게 되고, 결과적으로 target domain으로의 전이 성능이 향상된다.
ⓓ Why do registers influence sharpness?
이제 우리는 register가 왜 손실 지형의 sharpness와 전이 성능에 영향을 미치는지를 보다 깊이 분석한다. CDFSL에서 전이 성능을 저해하는 가장 큰 요인은 source domain과 target domain 간의 domain gap이므로, 본 논문에서는 기존 연구들을 따라 CKA(Centered Kernel Alignment) 유사도를 사용하여 source domain과 target domain 간의 도메인 유사성을 측정한다.
구체적으로, 백본 네트워크를 소스 데이터셋으로 학습한 후, 서로 다른 도메인에서 이미지 특징을 추출하고 이들 사이의 CKA 유사도를 계산한다. CKA 값이 높을수록 source domain과 target domain 간의 표현이 더 유사함을 의미하며, 이는 백본 네트워크가 domain-agnostic 정보를 더 많이 학습했음을 나타낸다.
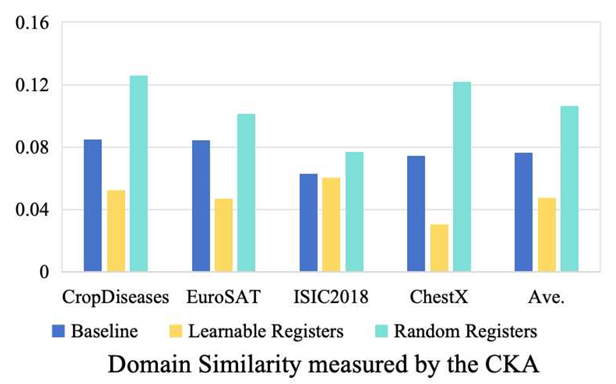
source domain에서 학습된 learnable registers를 추가하면 CKA 유사도가 크게 감소한다. 이는 registers가 소스 데이터셋으로부터 학습된 도메인 정보를 포함하고 있음을 의미한다. register의 개수가 증가할수록 더 많은 도메인 정보가 registers에 흡수되며, 그 결과 모델은 source domain 분류에만 유효한 domain-specific 정보를 더 많이 학습하게 된다.
반면, 가우시안 노이즈로 추가된 random registers는 CKA 유사도를 일관되게 증가시킨다. random registers는 target domain 단계에서 제거되므로, 이러한 결과는 random registers가 모델로 하여금 여러 도메인에 공통적으로 유효한 정보, 즉 domain-agnostic 정보를 학습하도록 유도함을 의미한다. 이는 앞서 설명한 sharpness-aware minimization(SAM) 관점과도 일치한다.
이러한 관찰을 바탕으로, 본 논문에서는 sharpness 증가의 원인을 registers가 흡수한 도메인 정보로 해석한다. 이 도메인 정보는 source domain에서는 효과적이지만, target domain으로 데이터 분포가 이동하면 더 이상 유효하지 않다. 따라서 이러한 모델은 도메인 이동이 발생했을 때 효과적인 특징을 추출하지 못하고, 그 결과 손실 값이 급격히 증가하게 되는데, 이것이 바로 큰 sharpness로 나타난다.
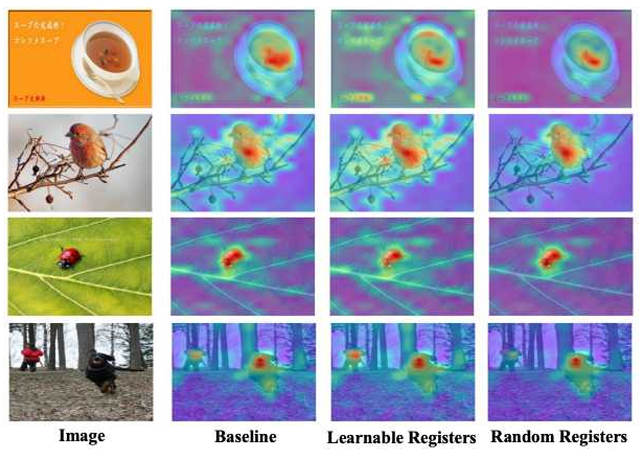
도메인 정보가 실제로 어떤 방식으로 패턴 학습에 반영되는지를 더 잘 이해하기 위해, 저자들은 source domain에서의 어텐션 맵을 시각화한다. 그 결과, learnable registers를 추가한 모델은 객체 인식과 무관한 영역에 더 많은 주의를 기울이는 반면, random registers를 사용한 모델은 객체 자체에 더 집중하는 경향을 보인다.
learnable registers의 경우, 이는 모델이 분류와 직접적으로 관련 없는 영역을 중요한 단서로 사용하고 있음을 의미한다. 이러한 현상은 해당 영역들이 클래스와 무관하면서 source domain에 특화된 특징일 가능성이 높다는 점에서, source domain에 대한 과적합으로 해석할 수 있다. 반대로 random registers의 경우, 모델은 객체 외부와 같은 불필요한 영역에 덜 집중하게 되며, 이는 클래스와 더 밀접하게 관련되고 도메인 간 전이가 가능한 특징에 집중하도록 만든다. 즉, 모델은 domain-agnostic 정보를 학습하게 되며, 이는 앞선 분석과 일관된 결과이다.
ⓔ Conclusion and Discussion
앞선 분석을 종합하면, 본 논문은 다음과 같이 해석할 수 있다. 학습 가능한 registers를 적용하면, 모델은 객체 인식과 직접적으로 관련이 없는 영역에 더 많은 주의를 기울이게 된다. 이는 source domain에 특화된 도메인 정보를 과도하게 학습하는 결과로 이어지며, source domain에 대한 과적합의 한 형태로 볼 수 있다. 이러한 과적합은 손실 지형의 sharpness를 증가시키고, 결과적으로 target domain으로의 일반화 성능을 저해한다.
반면, random registers를 적용하는 것은 모델에 입력되는 어텐션 맵을 교란하는 효율적이고 새로운 방법이며, 이는 sharpness-aware minimization(SAM)의 한 형태로 해석할 수 있다. 이를 통해 모델은 손실 지형에서 보다 평탄한 최소값을 찾도록 학습되며, 그 결과 target domain으로의 전이 성능이 향상된다. 이러한 설정에서 모델은 객체 외부의 불필요한 영역에 덜 집중하게 되고, target domian에 대해서도 더 나은 일반화 성능을 보이게 된다.
Method
앞선 분석과 해석을 바탕으로, 본 논문에서는 Random Registers Enhanced Attention Perturbation (REAP)이라는 간단하지만 효과적인 방법을 제안한다. 이 방법은 random registers의 효과성과 효율성을 동시에 향상시켜, Cross-Domain Few-Shot Learning(CDFSL) 과제에서 모델의 전이 성능을 강화하는 것을 목표로 한다. 또한, 두 가지 서로 다른 성질을 지닌 register의 특성에 따라, two-stage 학습 전략을 함께 제안한다.
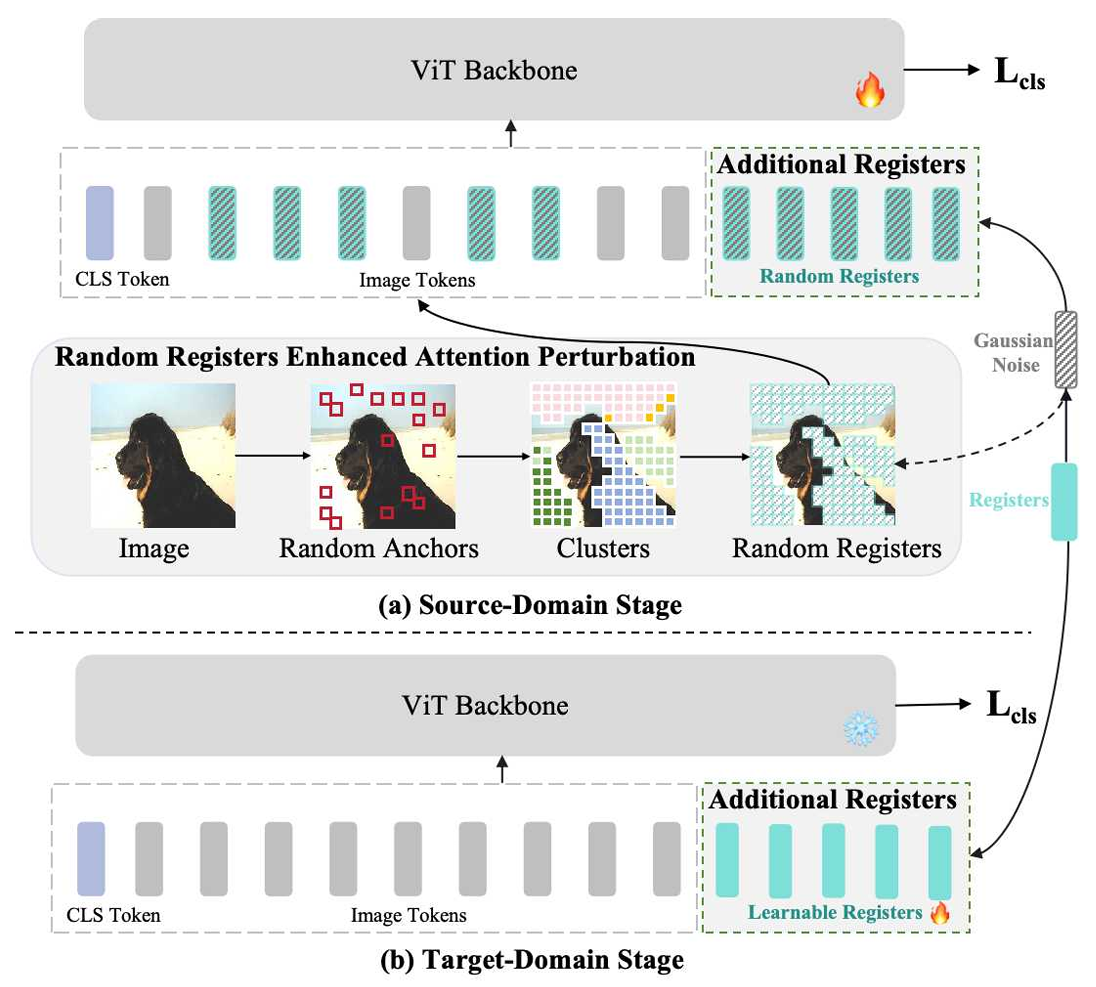
구체적으로, source-domain 단계에서는 random registers 기반의 개선된 방법을 사용하여 손실 지형에서 평탄한 최소값을 학습하도록 유도한다.
target-domain 단계에서는 도메인 정보를 교란하는 random registers 대신, 학습 가능한 registers를 다시 사용하여, 데이터가 매우 제한적인 target domian에 효과적으로 적응하도록 한다.
ⓐ Random Registers Enhanced Attention Perturbation (REAP)
기존의 random register 방식은 register의 개수가 매우 많을 때, 즉 GPU 메모리 한계에 도달할 정도로 많을 때에만 효과를 보인다. 이는 계산 비용 측면에서 비효율적이며 실용적이지 않다.
이 문제를 해결하기 위해, 본 논문에서는 random registers가 어텐션 맵에 얼마나 많은 교란된 정보를 제공하는지, 즉 교란 비율에 주목한다. random register의 개수를 많이 늘려야 했던 이유는, 어텐션 맵이 이미 입력 이미지로부터 풍부한 정보를 포착하고 있기 때문에, 기존에 포착된 패턴의 영향을 상쇄하기 위해서는 매우 강한 교란이 필요했기 때문이다. 교란을 강화하는 가장 직관적인 방법은 random register의 개수를 늘리는 것이지만, 이는 비효율적이다. 이에 저자들은 다음과 같은 질문을 던진다.
“이미 캡처된 어텐션 정보 자체를 직접 방해하면 어떨까?”
이를 위해, 저자들은 어텐션 맵에 가장 크게 기여하는 의미적 영역을 포함한 이미지 토큰들에 직접 교란을 가하는 방법을 설계한다. 이 방식은 어텐션 맵에서 다음과 같이 표현된다.
여기서 m은 유지된 원본 이미지 패치의 수, n−m은 교란된 이미지 패치의 수, n~은 추가된 random register의 개수이다. 즉, 기존 이미지 패치뿐 아니라, 의미적 이미지 패치 자체를 random register로 치환함으로써 어텐션 맵에 더 강한 교란을 가한다.
ⓑ Source-domain stage
source domain 단계에서의 목표는, 모델이 domain-agnostic 정보를 학습하도록 만드는 것이다. 앞선 분석과 해석을 바탕으로, 본 논문에서는 REAP을 활용하여 random registers의 잠재력을 최대한 끌어내고, 손실 지형에서 평탄한 최소값을 학습하도록 유도한다. 이를 통해 이후 모델이 target domain으로 원활하게 전이될 수 있도록 한다. 이 단계에서 모델의 학습 목표는 다음과 같다.
ⓒ Target-domain stage
target domain 단계의 목표는, 아주 적은 데이터만을 사용해 모델이 새로운 도메인에 빠르게 적응하도록 하는 것이다. random register는 도메인 정보 학습을 억제하는 특성을 가지므로, 이 단계에서는 적합하지 않다. 따라서 저자들은 도메인 정보를 흡수하는 성질을 가진 learnable register를 다시 사용한다.
구체적으로, 추가된 registers를 학습 가능한 상태로 활성화하고, 각 에피소드의 support set을 이용해 분류기를 포함한 파인튜닝을 수행한다. 이때의 학습 목표는 다음과 같다.
Experiments
ⓐ Implementation Details
기존 연구들을 따라, 본 논문에서는 miniImageNet 데이터셋을 source domain으로 사용하여 모델을 학습한 후, 네 개의 target domian 데이터셋—CropDiseases, EuroSAT, ISIC2018, ChestX로 전이한다. 모든 실험은 k-way n-shot 분류 설정에서 수행된다.
source domain 학습 단계에서는 ViT-S를 백본 네트워크로 사용하며, ImageNet에서 DINO로 사전학습된 가중치를 초기화 값으로 적용한다. 이미지에 대한 cluster-dropping 과정에서, anchor 비율과 최소 drop 비율을 모두 70%로 설정하고, 해당 영역을 Random Registers로 치환한다. 랜덤 가우시안 노이즈는 학습 가능한 표준편차를 사용해 생성하며, 초기값은 0.1로 설정한다. 또한, 재구성된 패치들에 더해 추가적인 16개의 random registers를 입력 시퀀스에 연결하여 모델의 입력으로 사용한다. 모델은 Adam 옵티마이저를 사용하여 50 에폭 동안 학습하며, 학습률은 백본 네트워크에 대해 10^−5, 분류기에 대해 10^−3으로 각각 설정한다. target domain에서의 few-shot 평가 단계에서는, 입력 이미지에 대해 동일한 개수의 학습 가능한 registers를 ViT 입력으로 제공하고, target domain의 domain-specific 정보를 효과적으로 흡수할 수 있도록 registers에 대해 10^−3의 학습률을 사용한다.
ⓑ Comparison with State-of-the-ArtWorks
네 개의 target domain 데이터셋에서 ViT-S 백본을 사용한 1-shot 및 5-shot 설정에 대해, 본 논문에서 제안한 방법과 기존 최신 기법들의 성능 비교 결과를 제시한다. 공정한 비교를 위해, 기존 연구들을 따라 파인튜닝 여부(FT)와 전이적 설정(transductive setting)의 사용 여부에 따라 방법들을 그룹화하였다.
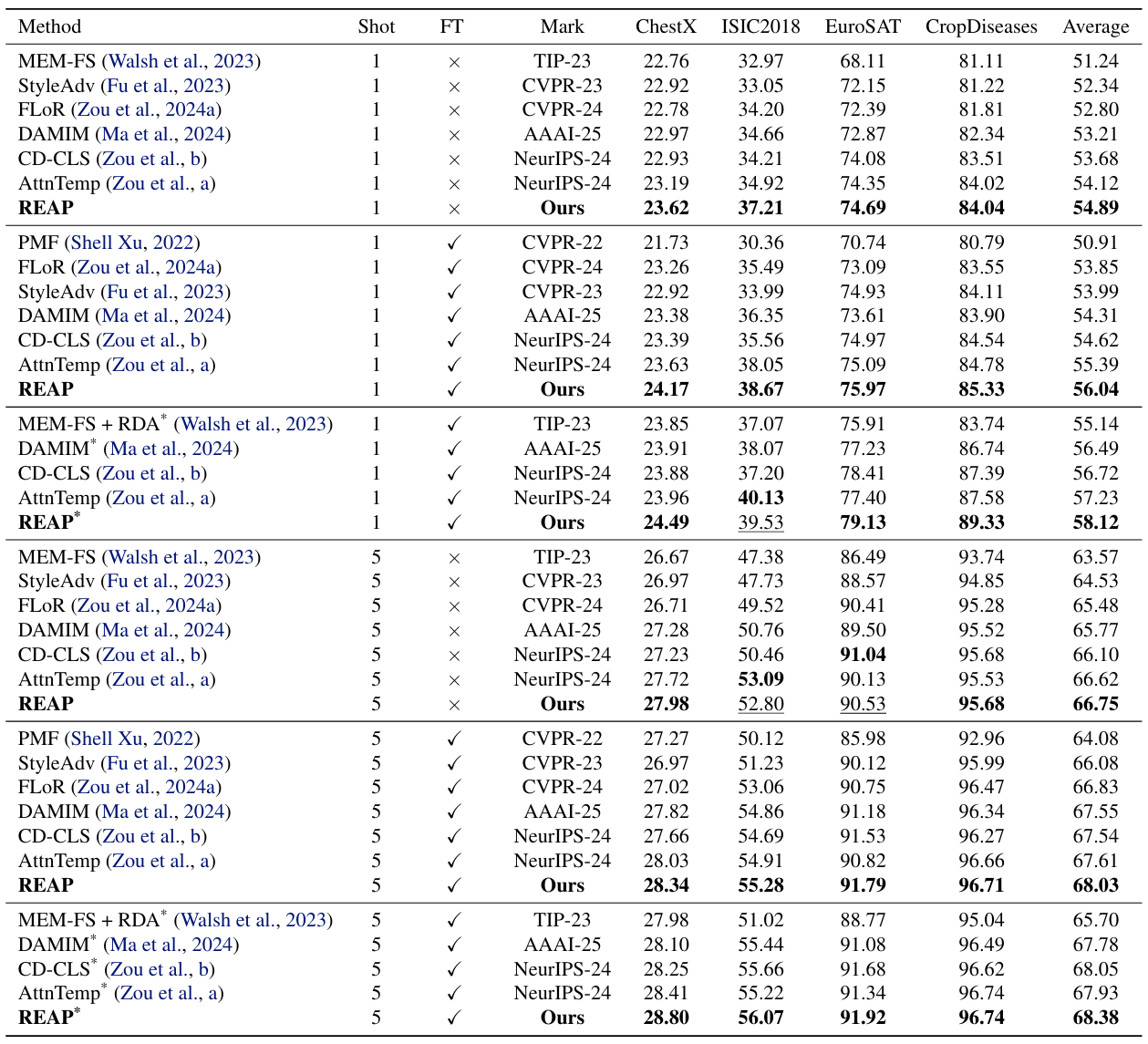
🔹 파인튜닝(FT)
target domian의 support set을 사용해 모델 파라미터를 실제로 업데이트하는가
🔹 전이적 설정(Transductive Setting)
테스트 시 query 데이터 전체를 라벨 없이 미리 활용하는 설정
(데이터의 분포, 클러스터 구조 등을 사용 가능)
Related Work
Cross-Domain Few-Shot Learning(CDFSL)은 FWT(Tseng et al., 2020)에서 처음 제안되었으며, 이후 BSCD-FSL(Guo et al., 2020)을 통해 새로운 벤치마크가 구축되었다. 최근에는 여러 연구들을 통해 활발히 탐구되고 있으며, 이들 연구는 공통적으로 source domain에서 학습한 모델이 소량의 예제만으로도 target domain에 잘 일반화될 수 있도록 하는 것에 초점을 맞추고 있다. 기존 연구들은 크게 두 가지 범주로 나눌 수 있다.
첫째는 meta-learning 기반 접근법으로, 새로운 과제를 효율적으로 학습하기 위한 task-agnostic 지식을 학습하는 방식이다.
둘째는 전이학습 기반 접근법으로, 베이스 클래스 데이터셋에서 학습된 모델을 재사용하여 target domain으로 전이하는 방식이다.
그러나 이러한 연구들에도 불구하고, 극단적인 cross-domain 환경에서 ViT의 성능에 대한 심층적인 분석은 여전히 부족한 상황이다.
프롬프트(prompt)는 자연어 처리(NLP) 분야에서 널리 사용되는 개념으로, 모델이 특정 출력이나 응답을 생성하도록 유도하는 하나 또는 일련의 텍스트 입력을 의미한다. 대규모 언어 모델의 발전과 함께, 프롬프트는 모델 성능을 좌우하는 핵심 요소로 자리 잡았다. 컴퓨터 비전 분야에서도 ViT가 주요 백본으로 널리 활용되고 있으며, ViT의 CLS 토큰 역시 분류 성능에 결정적인 역할을 하는 일종의 프롬프트로 볼 수 있다.
최근에는 다양한 비전 다운스트림 과제를 위해 프롬프트 기반 접근법이 제안되고 있다. 예를 들어, Darcet et al.(2024)은 입력 시퀀스에 프롬프트를 추가하되, 출력 이전에 이를 제거함으로써 부작용을 효과적으로 회피하는 방법을 제안하였다. 또한 ProD(Ma et al., 2023)는 두 개의 병렬 프롬프트를 사용하여 domain-general knowledge과 domain-specific knowledge을 분리함으로써 도메인 간 격차를 완화하고자 하였다.
그러나 이러한 기존 연구들은 프롬프트를 활용하는 데 초점을 맞출 뿐, source domain에서의 프롬프트 튜닝이 초래하는 과적합 문제를 명시적으로 고려하거나 설명하지는 못한다. 요약하면, 큰 도메인 격차가 존재하는 환경에서의 프롬프트 학습은 아직 충분히 탐구되지 않은 연구 주제이다.
Conclusion
본 논문에서는 추가적인 학습 가능한 registers를 제공하는 것이 CDFSL 성능에 해롭고, 반대로 registers에 무작위 노이즈를 추가하면 성능이 개선되는 현상을 발견하였다. 우리는 이 현상을 해석하기 위해 심층 분석을 수행했으며, 그 결과 학습 가능한 registers는 자연스럽게 도메인 정보를 흡수하는 반면, random registers는 도메인 정보를 교란하여 모델이 전이성이 좋은 손실 지형의 최소점을 찾도록 돕는다는 점을 확인하였다. 이러한 통찰에 기반하여, 우리는 random registers를 더 효과적이고 효율적으로 만들기 위한 방법을 추가로 제안하였다. 실험 결과는 우리의 해석과 방법의 효과성을 입증한다.
