Abstract
본 논문에서는 few-shot 학습 문제를 위해 MetaGAN이라 부르는 개념적으로 단순하고 범용적인 프레임워크를 제안한다. 대부분의 few-shot 분류 모델들은 MetaGAN과 통합될 수 있다. task에 조건화된 적대적 생성기를 도입함으로써, 일반적인 few-shot 분류 모델에 real와 fake를 구분하는 능력을 추가한다. 이 GAN 기반 접근법이 few-shot 분류기가 더 날카로운 결정 경계를 학습하도록 도와 향후 과제에 대한 일반화 성능을 높일 수 있음을 주장한다.
또한 MetaGAN 프레임워크를 통해 few-shot 지도학습 모델을 unlabeled data에도 자연스럽게 확장할 수 있다. 본 알고리즘은 sample-level과 task-level 모두에서 처리할 수 있다.
마지막으로 MetaGAN의 이론적 정당성을 제시하고, 도전적인 few-shot 이미지 분류 벤치마크에서 그 효과를 검증한다.
INTRODUCTION
심층 신경망은 데이터가 부족하거나 소수의 샘플만으로 새로운 과제에 적응해야 할 때에 성능이 급격히 떨어진다. 반면 인간은 몇 개의 예시만으로도 새로운 개념을 빠르게 익힌다. 이러한 성능 격차는 인간이 과제를 학습할 때 과거 경험과 지식을 효과적으로 활용하는 반면, 인공지능 학습자는 충분한 사전 지식 없이 과적합되는 경향이 있기 때문이다.
Meta-learning은 유사한 과제들의 분포에 대해 적응 전략을 학습하여, 여러 과제에 걸쳐 전이 가능한 패턴을 추출함으로써 이 문제를 해결하고자 한다. 최근에는 다양한 형식의 meta-learning few-shot 학습 알고리즘이 제안되었다. 이들 알고리즘은 각 클래스에서 단 몇 개의 샘플만 관측해도 올바른 결정 경계를 형성할 수 있는 전략을 학습한다.
본 연구에서는 MetaGAN이라 명명한 개념적으로 단순하고 범용적인 few-shot 학습 프레임워크를 제안한다. 대부분의 최첨단 few-shot 분류 모델들은 MetaGAN에 원리적이고 직관적으로 통합될 수 있다. 지도 및 준지도 few-shot 학습은 모두 MetaGAN이라는 통일된 틀 아래 자연스럽게 확장한다. 특히 MetaGAN은 준지도 학습을 sample-level 과 task-level 양쪽에서 다룬다.
① sample-level: 하나의 과제 내에서 일부 학습 샘플이 레이블 없이 주어진다.
② task-level: support set과 query set 모두 레이블이 전혀 없는 비지도 과제도 학습에 포함된다.
MetaGAN의 핵심 아이디어는 불완전한 generator가 실제 클래스 매니폴드 사이에 fake 샘플을 생성하여 discriminator에 추가적인 학습 신호를 제공함으로써, 더 날카로운 결정 경계를 학습하도록 만드는 것이다. 이로써 소수의 샘플만으로도 더욱 일반화 가능한 경계를 형성할 수 있다.
마지막으로, 지도 및 준지도 설정에서 도전적인 few-shot 이미지 분류 벤치마크를 통해 MetaGAN을 검증하였다. 대표적 few-shot 모델인 MAML과 Relation Network에 MetaGAN을 결합했을 때, 모든 시나리오에서 성능이 일관되게 향상됨을 보여준다.
BACKGROUND
ⓐ few-shot learning
Few-Shot 학습 문제를 다음과 같이 정식화한다. 과제 분포 P(T)가 주어졌을 때, 이 분포로부터 추출된 한 과제 T는 결합 분포 PT(X×Y)(x,y)에 의해 정의되며, 과제의 목표는 주어진 입력 x에 대해 정답 y를 예측하는 것이다. 훈련용 과제 샘플 {Ti}(i=1)N의 집합이 주어지고, 각 과제 T는 튜플 T=(ST,QT)로 표현된다.
support set ST = STs ∪ STu
① supervised support set STs는 N개 클래스 각각에서 K개의 레이블된 샘플을 포함한다. (K-shot N-way 분류)
② unlabeled support set STu는 N개 클래스의 레이블 없는 샘플
query set QT = QTs ∪ QTu
① supervised query set QTs
② unlabeled support set STu
모델의 목표는 support set ST를 입력으로 주었을 때, query set QT에 대한 예측 손실을 최소화하는 것이다.
② Adversarial Training
생성적 적대 신경망(Generative Adversarial Networks, GAN) 프레임워크는 생성 모델링에서 널리 쓰인다. generator와 discriminator라는 두 개의 신경망을 서로 적대적으로 학습시킨다. 최근 이 적대적 학습은 다양한 분야에 적용되어 왔다. 그러나 few-shot 학습과 적대적 학습을 성공적으로 결합한 연구는 드물다.
Antoniou et al. (2018)은 클래스 조건부 GAN(class-conditioned GAN, DAGAN)을 훈련시켜 데이터 증강에 활용하는 방법을 제안했다. 하지만 이 접근법은 두 가지 측면에서 MetaGAN과 다르다. 첫째, DAGAN 모델은 분류기와 분리되어 오직 추가 데이터를 제공하기 위한 용도로만 학습된다. 둘째, 생성된 이미지를 해당 클래스의 실제 훈련 데이터로 간주한다. 이에는 두 가지 단점이 있다. GAN은 ImageNet과 같은 복잡한 데이터셋에서 현실적인 샘플을 생성하는 데 여전히 한계가 있어, 생성된 이미지를 진짜 데이터로 취급하는 것이 적절치 않다. 또한 DAGAN은 mode collapse에 쉽게 빠져, 종종 입력 이미지를 그대로 복원하는 항등 함수로 수렴하기도 한다.
반면 MetaGAN은 생성기가 완벽할 필요가 없다. 불완전한 생성기로부터도 이득을 얻을 수 있도록 설계되었다.
OUR APPROACH
MetaGAN은 few-shot 학습 문제를 위한 개념적으로 단순하면서도 유연한 프레임워크다. 기존의 강력한 K-shot N-way 분류기 위에, 특정 task에 조건화된 적대적 생성기를 도입하여, real 데이터와 fake 데이터를 구별하도록 분류기를 확장한다. 이때 분류기의 출력 차원을 N에서 N+1로 늘려 ‘가짜 클래스’에 대한 확률을 모델링하며, 생성기와 분류기를 적대적 방식으로 함께 학습한다.
ⓐ basic algorithm
Few-shot N-way 분류 문제 P(T)와 과제 집합 {Ti}(i=1)M에서, 기존 분류기에 추가 출력을 더해 확장한다.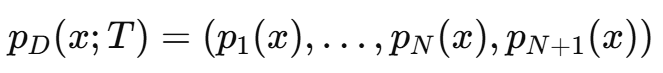
분류기 손실은 지도학습 손실과 비지도학습 손실을 결합하여 구한다. Lunsupervised에서 첫 항은 QTu가 real 클래스(1~N)로 예측되도록 유도하고, 둘째 항은 생성기가 만든 샘플이 fake 클래스(N+1)로 예측되도록 유도한다.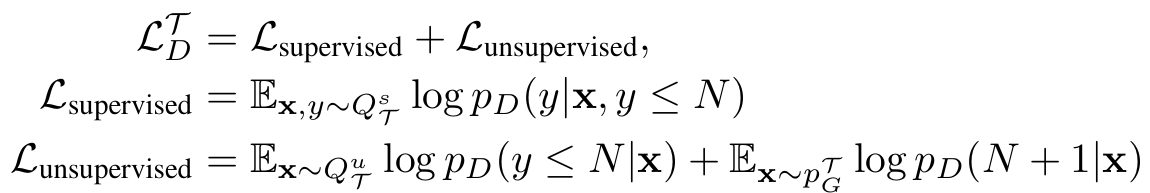
생성기는 비포화(non-saturating) 손실을 사용해, 자신의 샘플을 분류기가 real 클래스 중 하나로 잘못 분류하도록 학습한다.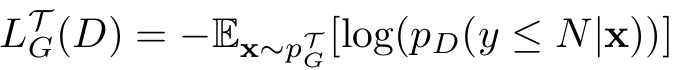
ⓑ discriminator
MetaGAN은 discriminator의 설계에 별다른 제약을 두지 않아, 사실상 거의 모든 최첨단 few-shot 학습 모델에 적용할 수 있다. 본 연구에서는 MAML과 Relation Network를 판별기로 채택했다.
① MetaGAN with MAML
MAML은 단 한 번의 그래디언트 하강으로도 새로운 과제에 빠르게 적응할 수 있는 전이 가능한 초기화를 학습한다. 판별기 D는 파라미터 θd로 매개되며, 과제 T∼P(T)가 주어졌을 때 손실식에 따라 파라미터를 업데이트한다. 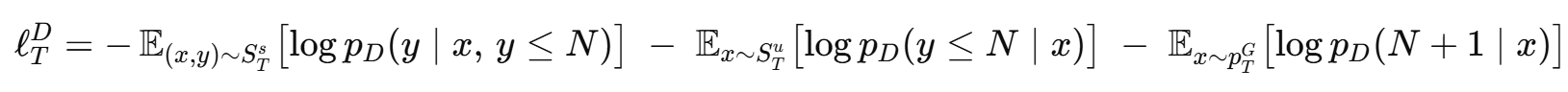
support set의 레이블된 샘플은 올바른 클래스를 맞추도록, 레이블 없는 샘플은 real 클래스(1~N) 중 하나를 맞추도록, 생성된(fake) 샘플은 가짜 클래스(N+1)를 맞추도록 학습한다.
이렇게 얻은 적응된 판별기 D(θd')를 고정한 채 query set에 대한 기댓값 손실을 최소화하여 초기 파라미터 θd를 메타-업데이트하고, 동시에 generator도 D(θd')를 이용해 학습한다.
❓model-agnostic meta learning(MAML) 이란?
MAML은 여러 task에서 얻은 경험을 바탕으로 어떤 task에도 빠르게 적응할 수 있는 파라미터 초기값을 학습하는 알고리즘이다.
meta-learning 단계에서는 다양한 task들에 대해 파라미터 θ를 학습하고, 새로운 과제가 주어질 때마다 support set의 소량의 레이블된 샘플로 θ를 한두 번의 그래디언트 업데이트만으로 θ'로 빠르게 적응시킨다. 적응된 θ'을 고정한 채 query set에 대한 성능을 평가하고, 이 평가 손실을 역전파해 원래의 θ를 갱신하는 과정을 반복함으로써 θ를 점진적으로 개선한다.
② MetaGAN with Relation Network
Relation Network은 이미지들 사이의 심층 distance metric을 학습해 분류를 수행하는 few-shot 학습 모델이다. MetaGAN은 이 RN을 원리적이고 직관적인 방법으로 확장한다. 특정 과제 T∼P(T)에 대해, support set STs의 각 이미지 xi와 query set QTs의 각 이미지 xj 간의 유사도 점수 r(i,j)는 이미지 xj가 클래스 i일 때의 로짓을 의미한다. 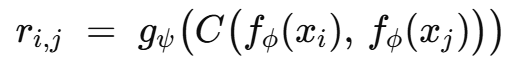
fϕ: feature embedding network
gψ: relation module
C: 두 특징 벡터의 연결 연산
기존 Relation Network와 달리, r(i,j)를 (0,1) 범위로 제한하지 않고 소프트맥스 분류의 logit으로 직접 사용한다. 쿼리 이미지 xj가 클래스 k일 확률은 아래와 같다. 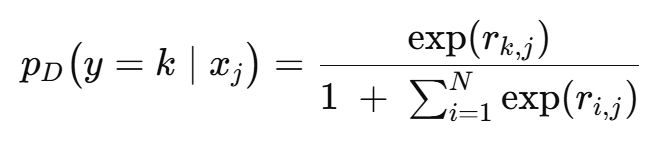
MetaGAN의 fake 클래스 N+1에 해당하는 로짓을 0으로 고정하여 가짜 클래스를 모델링한다.
ⓒ GENERATOR
본 연구에서는 특정 과제 T의 실제 데이터 매니폴드에 근접한 가짜 데이터를 생성하기 위해 조건부 생성 모델을 도입한다. 데이터셋 인코더 E를 사용해 support set STs의 정보를 벡터 hT로 압축한다. 그다음 hT를 임의 노이즈 z와 연결하여 생성기의 입력으로 제공한다. 데이터셋 인코더 E는 다음 두 모듈로 구성된다.
① Instance-Encoder
support set의 각 샘플 xi를 개별적으로 임베딩 ei=Instance-Encoder(xi)로 변환하는 신경망이다.
② Feature-Aggregation
ei를 받아 평균 풀링 또는 맥스 풀링 등의 연산을 통해 전체 과제의 통계 벡터 hT를 생성한다.
ⓓ Learning Settings
본 절에서는 MetaGAN 프레임워크가 지도 학습과 준지도 학습 두 가지 설정을 어떻게 통일적으로 다루는지 설명한다.
① 지도 Few-Shot 학습
전통적인 few-shot 분류에서는 각 과제 T에 대해 레이블 없는 support set STu나 query set QTu가 없다. 이때 MetaGAN은 손실 식에 등장하는 STu와 QTu항을, 각각 레이블된 support set STs와 query set QTs로 대체하여 학습한다.
② Sample-Level 준지도 Few-Shot 학습
하나의 과제 내에 일부 샘플이 unlabeled 상태로 들어오는 경우다. MetaGAN은 support set 또는 query set 어느 쪽에 unlabeled 샘플이 섞여도 처리할 수 있지만, query set 쪽에만 unlabeled 샘플을 배치했다.
③ Task-Level 준지도 Few-Shot 학습
훈련용 과제 집합중 일부는 완전히 레이블이 없는 과제로 포함시킬 수 있다. 레이블된 과제는 지도 학습과 동일하게 STs, QTs를 사용해 학습하고, 순수 비지도 과제는 지도 손실 항을 제거하여 비지도 손실로 학습한다. 학습 과정에서는 레이블된 과제와 비지도 과제를 번갈아 뽑아 함께 최적화한다.
WHY DOES METAGAN WORK?
이 절에서는 MetaGAN의 핵심 아이디어와 모델 개선을 정당화하는 직관적이고 이론적 근거를 제시한다.
일반적인 few-shot 분류 문제에서는, 각 task마다 클래스마다 몇 개 안 되는 샘플만 보고 적절한 결정 경계를 찾아야 한다. 단지 소수의 예시만으로 경계를 완전히 규정하는 것은 사실상 불가능하다. 가능한 경계가 무수히 많아 대부분의 선택지가 새로운 과제에 잘 일반화되지 않기 때문이다.
Meta-learning은 여러 과제에서 공통으로 통하는 경계 형성 전략을 학습해, 소량의 샘플만으로도 잘 적용되는 일반화 가능한 방법을 찾고자 한다. 그런데 이 접근에도 한계가 있다.
GAN의 generator가 실제 데이터 매니폴드에서 약간 어긋난 장소에 fake 샘플을 찍어내면, discriminator는 real 클래스 간 경계뿐 아니라 real과 fake 경계도 함께 학습하게 된다. 이로써 분류기는 두 클래스 매니폴드 바깥의 가짜 데이터까지 분별하는 훨씬 날카로운 경계를 익히게 된다.
이 아이디어를 few-shot 설정에 적용하면, 불완전한 생성기가 만들어 내는 가짜 샘플조차도 실제 클래스 간 경계를 좁고 명확하게 다듬는 역할을 할 수 있다. 생성기는 결코 완벽할 필요가 없고, 오히려 매니폴드 주변을 조금씩 벗어나는 샘플을 공급함으로써 분류기를 더 강건하게 만드는 보조적 신호가 된다.
특정 과제 T에서 판별기는 특징 추출기 fT를 사용해 분류를 수행한다고 하자. 또 G(⋅;T)가 과제별 분리 보완 생성기라고 하자. 이는 생성기 G(z;T)의 분포 pTG가 다음 두 조건을 만족함을 뜻한다.
① 실제 모든 클래스 매니폴드와 겹치지 않는 고밀도 영역을 가진다.
② 이 고밀도 영역이 서로 다른 클래스 매니폴드를 분리할 수 있다.
각 과제 T∼P(T)에 대해 GT가 분리 보완 생성기라 가정하고, support set ST와 생성된 가짜 데이터 FT를 확장한 학습으로부터 강건한 결정 경계를 얻을 수 있는 판별기 DT를 학습했다고 하자. 이때
∣FT∣→∞이면 DT는 과제 T의 실제 데이터 분포 pT(x) 아래 모든 real 샘플을 거의 확실히 올바르게 분류할 수 있다.
완벽하지 않지만 real 매니폴드 주변을 적절히 커버하는 fake 생성기와 소수의 real 샘플만으로도, 올바른 결정 경계를 학습할 수 있다.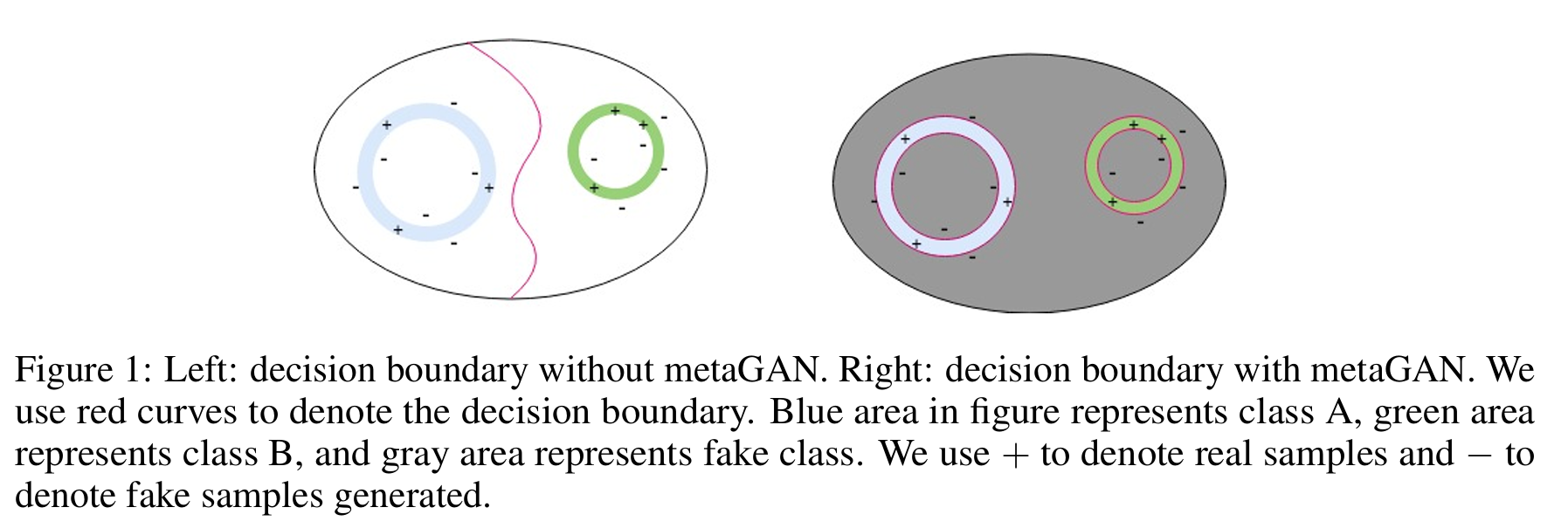
EXPERIMENTS
ⓐ Datasets
Omniglot
Omniglot은 50개 언어의 손글씨 문자 이미지로 구성된 데이터셋으로, 총 1623개 클래스가 있으며 각 클래스당 20장의 예시가 있다. 본 논문에서는 모든 이미지를 28×28 해상도로 축소한 뒤, 무작위로 1200개 클래스를 학습용, 432개 클래스를 테스트용으로 분할했다. 또한 각 이미지를 90도 단위로 무작위 회전시켜 새로운 클래스를 생성했다.
Mini-Imagenet
Mini-Imagenet은 잘 알려진 ILSVRC-12 데이터셋의 하위집합으로, 100개 클래스에서 클래스당 600개의 84×84 컬러 이미지를 포함한다. 64개 클래스를 학습용, 16개 클래스를 검증용, 20개 클래스를 테스트용으로 사용했다.
ⓑ Supservised Few-shot Learning
Omniglot 데이터셋에서는 MetaGAN+MAML이 일반적인 MAML과 동일한 구조와 설정을 공유한다. Relation Network(RN) 기반 MetaGAN의 경우, 1-shot 5-way와 5-shot 5-way 분류 모두에서 클래스당 쿼리 이미지를 15장씩 배치했고, 1-shot 20-way와 5-shot 20-way에서는 클래스당 쿼리 이미지를 5장씩 배치했다.
생성기와 분류기 모두 Adam 옵티마이저를 사용해 학습했다. Omniglot에서는 배치 업데이트 10000회마다 학습률을 반으로 감소시키고, 이후에도 10000회마다 절반으로 줄였다. Mini-Imagenet에서는 배치 업데이트 30000회부터 학습률을 반으로 줄이기 시작하고, 그 이후 10000회마다 반감시켰다.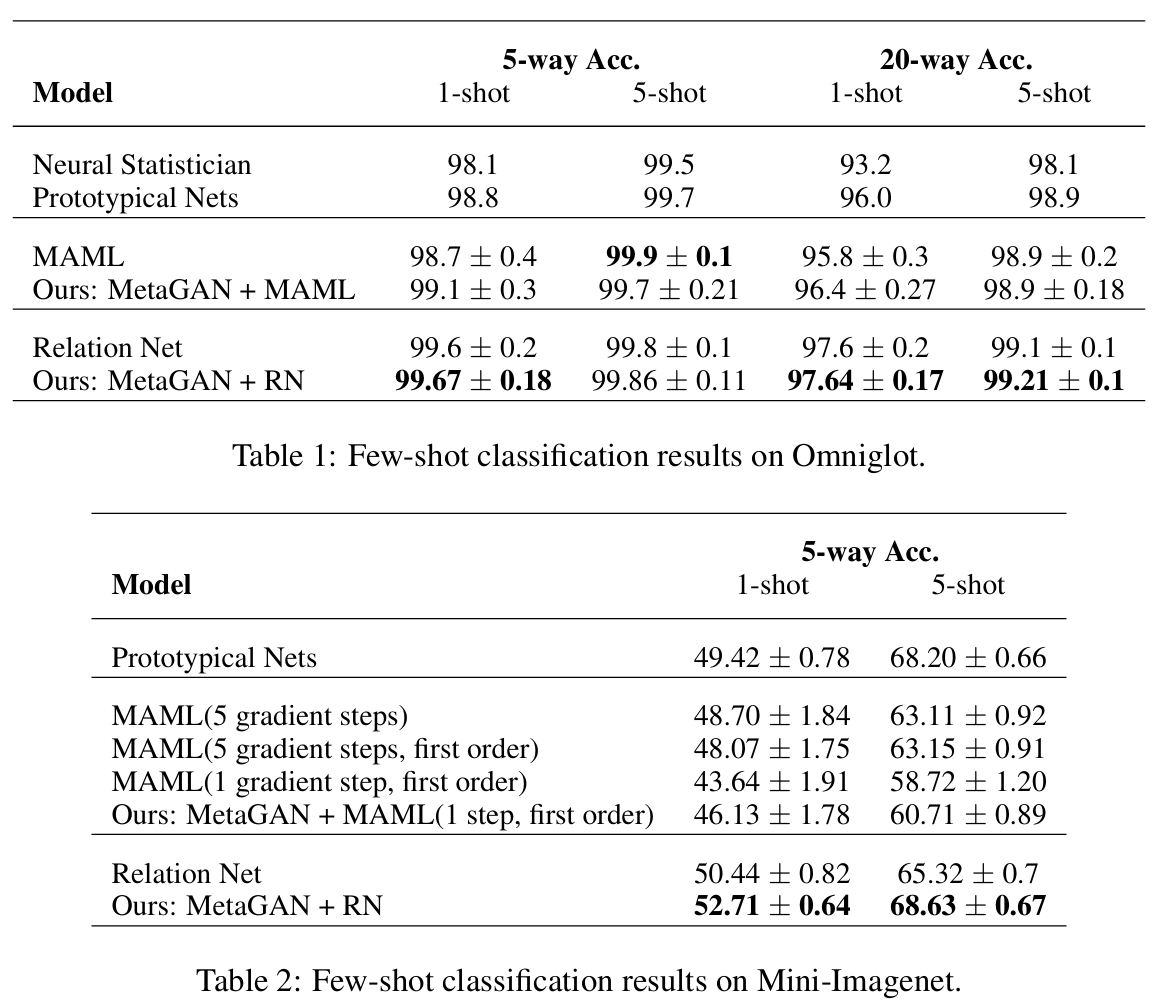
제안한 MetaGAN이 모든 설정에서 베이스라인 분류기를 일관되게 능가했다. 특히 어려운 Mini-Imagenet 벤치마크에서도 최첨단 성능과 대등하거나 더 우수한 결과를 달성했다.
ⓒ Sample-level Semi-supervised Few-shot Learning
본 연구에 sample-level 준지도 Few-Shot 학습 설정에서 MetaGAN의 효과를 평가한다. Omniglot 데이터셋에서는 각 클래스의 이미지 중 10%를 레이블이 있는 집합으로, 나머지를 레이블 없는 집합으로 사용한다. Mini-Imagenet에서는 각 클래스 이미지 중 40%를 레이블된 집합으로 샘플링하고, 학습 에피소드당 클래스별로 5장의 이미지를 추가로 뽑아 레이블 없는 집합으로 사용한다.
본 모델은 학습 단계에서만 레이블 없는 샘플을 활용한다. 반면 k-means 기반 정제 모델은 학습과 평가 모두에서 레이블 없는 샘플을 사용한다. 따라서 평가 시 얻는 정보가 MetaGAN 쪽이 오히려 적다. MetaGAN으로 학습된 분류기는 학습 단계에 fake 샘플을 활용해 경계를 날카롭게 다듬으며, 테스트 단계에는 오직 레이블된 샘플만으로 예측할 수 있다는 점에서 차별화된다.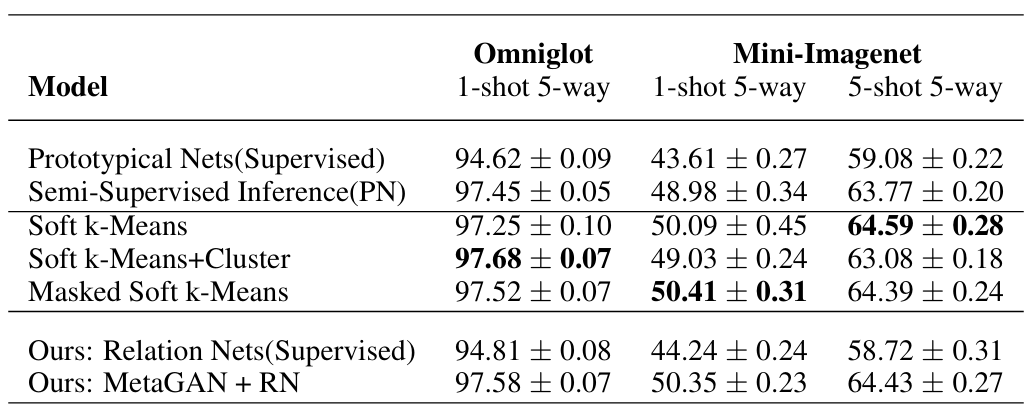
앞서 언급한 바와 같이, 본 모델은 k-means 기반 정제 모델과 직접 비교하기는 어렵다. 본 모델은 최첨단 수준의 성능을 달성하였으며, 순수 감독 학습 기반 베이스라인 모델들에 비해 유의미한 성능 향상을 보인다.
ⓓ Task-level Semi-supervised Few-shot Learning
task-level semi-supervised few-shot 학습은, support set과 query set이 모두 레이블 없이 구성된 순수 비지도 과제까지 모델이 학습에 활용할 수 있도록 한다.
Omniglot과 Mini-Imagenet 데이터셋에 대해 새로운 클래스 분할을 만들었다. Omniglot은 훈련용 1623개 클래스 중 무작위로 10%를 레이블된 클래스로, 나머지 90%를 레이블 없는 클래스로 지정한다. Mini-Imagenet은 100개 클래스 중 40%를 레이블된 클래스로, 60%를 레이블 없는 클래스로 지정한다.
검증 및 테스트 단계에서는 두 데이터셋의 전체 클래스를 그대로 사용해 모델 성능을 평가한다. 학습 단계에서는 레이블된 클래스 풀에서만 과제를 샘플링해 지도 과제를 만들고, 레이블 없는 클래스 풀에서만 과제를 샘플링해 비지도 과제를 구성한 뒤, 이 둘을 번갈아가며 MetaGAN을 학습한다. 기준이 되는 베이스라인 모델은 감독 과제만 이용해 학습한다.
MetaGAN을 적용한 모델은 순수 비지도 과제에서도 전이 가능한 패턴을 효과적으로 학습하여 성능을 향상시켰다.
CONCLUSION
본 논문에서는 few-shot 학습 모델의 성능을 향상시키기 위한 개념적으로 단순하면서도 범용적인 프레임워크인 MetaGAN을 제안한다. 본 접근법은 생성기가 만들어 내는 가짜 샘플이, 소수의 실제 샘플만으로도 분류기가 서로 다른 클래스 간에 더욱 날카로운 결정 경계를 학습하도록 도울 수 있다는 아이디어에 기반한다.
few-shot 학습과 준지도 학습은 모두 소수의 레이블된 데이터만을 사용한다는 공통점이 있으며, 불완전한 생성기로부터 이득을 얻을 수 있다는 점에서도 유사하다. 이에 GAN을 활용한 준지도 학습 기법을 few-shot 학습 시나리오에 맞게 수정·확장하였고, 제안한 방법에 대한 직관적 설명과 이론적 정당성을 함께 제시하였다.
마지막으로, 다양한 few-shot 학습 및 준지도 few-shot 학습 과제에서 MetaGAN의 유효성을 검증하였다. 향후 연구로 few-shot 모방 학습 설정으로 MetaGAN을 확장할 계획이다.
