Abstract
attention은 인간이 시각 정보를 인식하고 해석할 때 중요한 역할을 한다. attention이 컴퓨터 비전과 자연어 처리와 같은 인공 신경망에도 중요한 역할을 할 수 있다. 본 연구에서는 CNN에 대해 attention을 적절히 정의하고, 강력한 교사 네트워크의 attention map을 모방하도록 학생 CNN 네트워크를 학습시켜 그 성능을 크게 향상시킬 수 있음을 보여준다. 이를 위해 우리는 여러 새로운 attention transfer 방법을 제안한다. 그리고 다양한 데이터셋과 CNN 아키텍처 전반에서 일관된 성능 향상을 입증한다.
INTRODUCTION
인간은 주변 환경을 제대로 인식하기 위해 attention을 기울인다. attention은 우리의 시각적 경험에서 핵심적인 요소며, 지각과 밀접하게 관련되어 있다. 우리는 세부적이고 일관된 시각적 표현을 형성하기 위해 attention을 유지해야 한다.
최근 몇 년 동안 인공 신경망이 컴퓨터 비전 및 자연어 처리 분야에서 널리 사용되면서, 인공적인 attention 메커니즘 또한 개발되기 시작했다. attention 메커니즘은 시스템이 특정 객체에 더 집중해서 자세히 살펴볼 수 있게 해준다. 이 메커니즘은 심리학에서 사용되는 주의 개념처럼, 신경망 내부 작동 방식을 이해하는 연구 도구로도 활용된다.
심리학에서는 non-attentional과 attentional 지각 과정이 존재한다는 가설이 있다. non-attentional 과정은 장면 전체를 관찰하고 고수준 정보를 수집하는 데 사용된다. 이 정보가 다른 사고 과정과 결합되면 attention 과정을 조절하고 장면의 특정 부분에 집중하게 해준다. 지식과 목표가 다른 사람들은 같은 장면을 다르게 인식할 수 있는 것이다.
CNN에서 attention은 어떻게 다를까? 그리고 이러한 주의 정보를 이용해 CNN의 성능을 향상시킬 수 있을까? 강력한 교사(teacher) 네트워크가 주의를 어디에 두는지를 학생(student) 네트워크에 전달하면서 학생의 성능을 향상시킬 수 있을까?
이러한 질문을 탐구하기 위해, 먼저 CNN에서 attention을 다음과 같이 정의한다. attention은 CNN의 다양한 계층에 대해 정의된 공간적 맵으로 본다. 이 맵은 입력의 어떤 공간적 영역이 네트워크의 출력 결정에 가장 중요한 역할을 하는지를 나타낸다. 이 맵은 CNN의 저수준, 중간수준, 고수준 표현을 포착할 수 있도록 여러 계층에 대해 정의된다. 본 논문에서는 다음과 같은 두 가지 주의 맵을 제안한다.
① 활성 기반 주의 맵(attention based on activation)
② 그래디언트 기반 주의 맵(attention based on gradient)
이 두 가지 방식의 주의 맵이 다양한 데이터셋과 CNN 구조에 따라 어떻게 달라지는지 탐색한다. 이 정보가 실제로 CNN의 성능을 크게 향상시킬 수 있다.
본 논문은 강력한 교사 네트워크의 주의 정보를 작은 학생 네트워크에 transfer하는 새로운 방법들을 제안하며, 이를 통해 학생 네트워크의 성능 향상을 목표로 한다.
RELATED WORK
초기 attention-based tracking 연구들은 인간 주의 메커니즘 이론(Rensink, 2000)에서 영감을 받아 Restricted Boltzmann Machines을 통해 구현되었다. 이후에는 순환 신경망을 기반으로 한 신경 기계 번역과 여러 자연어 처리 관련 작업에도 적용되었다. 이 주의 메커니즘은 이미지 캡셔닝, 시각적 질문 응답, 약지도학습 객체 위치 추정과 같은 컴퓨터 비전 작업에도 활용되었으며, 이 모든 작업에서 주의 메커니즘은 유용한 것으로 입증되었다.
CNN에서의 주의 맵 시각화는 아직도 연구 중인 문제다. 가장 간단한 그래디언트 기반 시각화 방법은 입력에 대한 네트워크 출력의 자코비안(Jacobian)을 계산하는 것이다. 하지만 이 방식은 class-discriminative 정보는 제공하지 못한다.
기존 주의 시각화 방법 중에서 주목할 만한 것은 Class Activation Maps (CAM)이다. 이는 상위 평균 풀링 층을 제거하고 선형 분류층을 합성곱 계층으로 변환하여 각 클래스에 대한 주의 맵을 생성한다. Grad-CAM은 CAM에 guided backpropagation을 결합하여 클래스 구분이 가능한 주의 맵에 디테일을 추가한다.
지식 증류(Knowledge Distillation)는 강력한 교사 네트워크의 지식을 학생 네트워크에 전이시켜 학습 성능을 높이는 방법이다. 특별한 경우에는 얕은 네트워크도 깊은 네트워크를 정확도 손실 없이 근사할 수 있지만 깊은 네트워크가 더 나은 표현을 학습한다는 가정에 기반한다. 그러나 특정 깊이 이상에서는 성능 향상이 깊이보다 파라미터 수의 증가, 즉 네트워크의 용량 증가에 기인한다. 예를 들어, 단 16개의 층을 가진 넓은 Wide ResNet이, 1000층짜리 매우 얇은 ResNet과 같은 수준의 표현 학습이 가능하다. 이러한 사실에 얇고 깊은 네트워크는 병렬 처리에 불리하다는 점 때문에 우리는 깊이가 덜한 학생 네트워크를 학습시키는 방법을 제안한다.
ATTENTION TRANSFER
이 절에서는 CNN의 공간적 주의 맵을 정의하는 데 사용한 두 가지 방법과 교사 네트워크로부터 학생 네트워크로 주의 정보를 어떻게 전이하는지에 대해 설명한다.
ⓐ Activation-Based Attention Transfer
CNN의 한 계층과 그에 대응하는 활성화 텐서를 생각해 보자. 이 텐서는 C개의 특성 맵으로 구성되어 있으며, 각각의 특성 맵은 H×W의 공간적 차원을 가진다. 활성 기반 주의 매핑 함수 F는 이 3차원 텐서 A를 입력으로 받아 2차원 공간적 주의 맵으로 변환하는 함수이다.
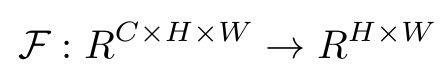
입력에 대해 네트워크를 실행했을 때, 은닉 뉴런의 활성화 절댓값은 해당 뉴런이 그 입력에 대해 얼마나 중요한지를 나타내는 지표로 사용할 수 있다고 가정한다. 따라서 텐서 A의 각 원소의 절댓값을 기반으로 하여, 채널 차원(C)에 대한 통계 처리를 통해 공간적 주의 맵을 구성할 수 있다. 본 논문에서는 다음과 같은 활성 기반 주의 맵을 고려한다.
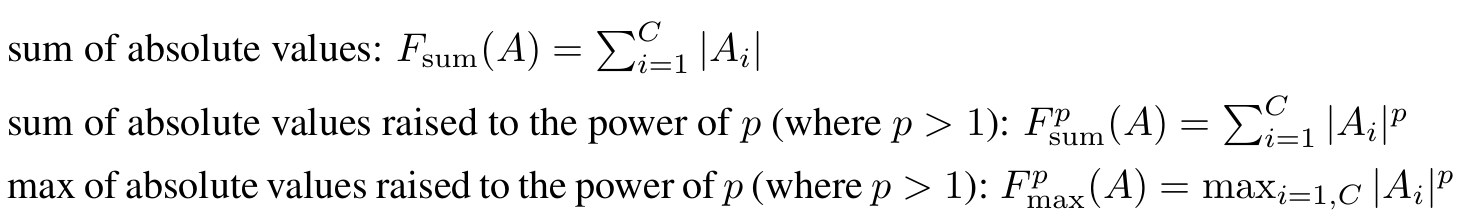
Ai: H×W 크기의 채널 i번째 feature map
우리는 다양한 데이터셋에 대해 여러 네트워크의 활성화 값을 시각화해보았다. 주로 최상위에 밀집 선형 계층이 없는 간결한 합성곱 구조를 갖춘 현대적인 아키텍처들에 집중하였다.
그 결과, 앞서 소개한 은닉층 활성화 통계 값들은 단지 이미지 수준에서 예측된 객체와 공간적으로 상관관계를 가질 뿐 아니라, 정확도가 높은 네트워크일수록 그 상관도가 더 높아진다는 것을 발견했다. 강한 네트워크는 약한 네트워크가 주목하지 않는 부분에서도 attention의 peak를 보인다.
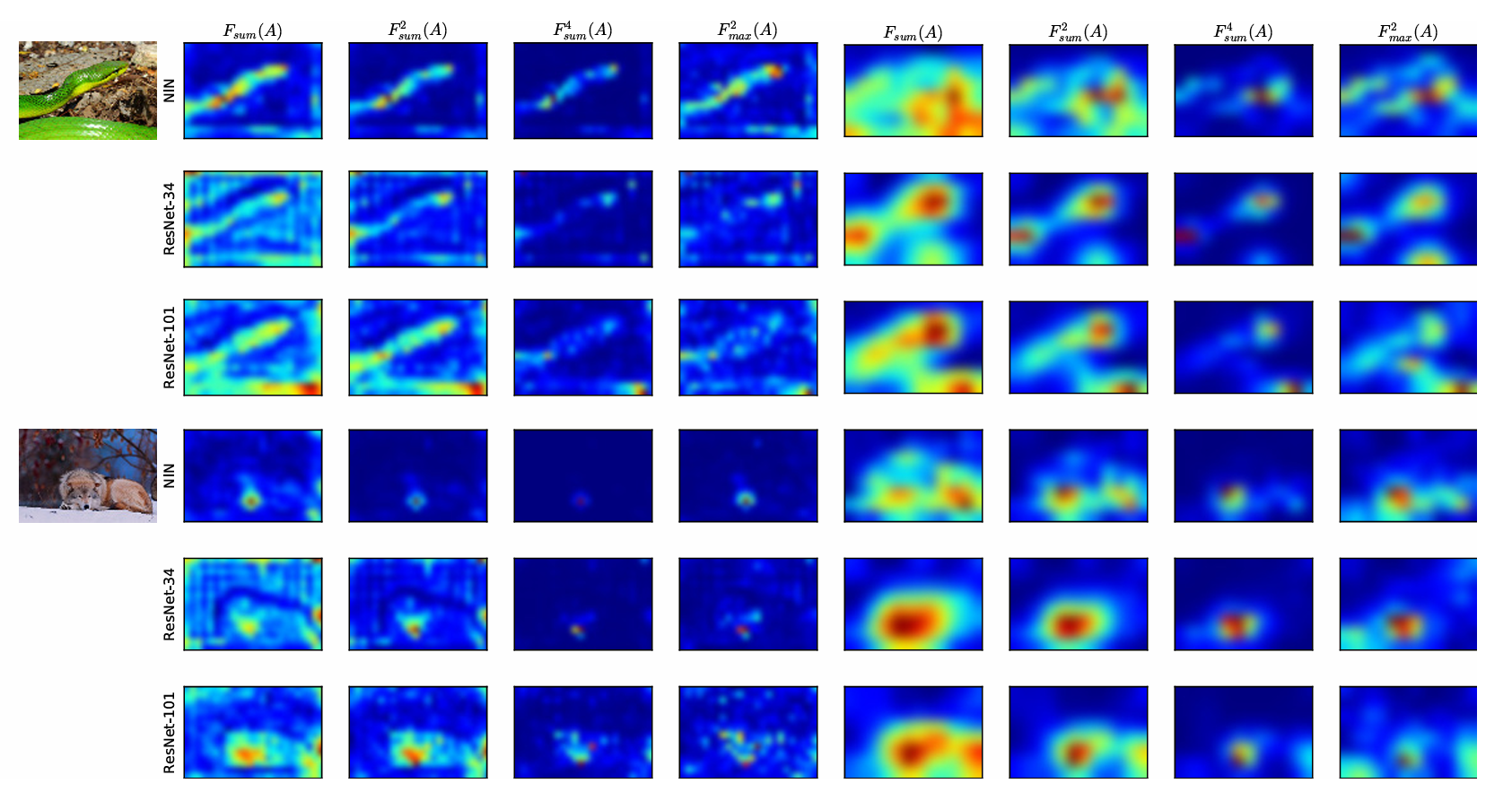
또한, 주의 맵은 네트워크의 계층에 따라 서로 다른 부분에 집중한다. 초기 계층에서는 저수준 경계나 기울기에 반응이 크고, 중간 계층에서는 가장 판별력 있는 영역(눈)에서 높은 활성화가 나타나며, 상위 계층에서는 전체 객체 전체(얼굴)를 반영하는 주의가 나타난다.

앞서 정의한 주의 맵 함수들은 각각 다소 다른 특성을 가진다. 예를 들어, Fsum(A)와 비교했을 때, Fsump(A)는 p>1일 경우 활성화가 높은 뉴런들이 있는 위치에 더 많은 가중치를 부여한다. 가장 판별력 있는 부분에 더 집중하게 된다.
또한, Fmaxp(A)는 여러 뉴런 중에 하나만 선택하여 가중치를 부여한다. 반면 Fsump(A)는 여러 뉴런이 동시에 높은 활성화를 갖는 위치를 더 선호한다.
이 함수들 간의 차이를 좀 더 명확히 보여주기 위해, 우리는 분류 성능에 충분한 차이를 보이는 세 개의 네트워크에 대해 attention map을 시각화했다.
① Network-In-Network (62% top-1 검증 정확도)
② ResNet-34 (73% top-1 검증 정확도)
③ ResNet-101 (77.3% top-1 검증 정확도)
각 네트워크에서, 다운샘플링 직전의 활성화 맵을 가져왔다.
왼쪽이 mid-level, 오른쪽이 top-level 계층의 활성화 맵이다.
top-level 맵은 원래의 해상도가 7×7로 매우 작기 때문에 흐릿하다. 하지만, 주의가 집중된 영역, 가장 판별력이 높은 부분은 확실히 더 높은 활성화 값을 가지는 것이 명확하게 나타난다. 또한, 지수 파라미터 p가 커질수록 형태의 디테일은 점점 사라지고, 가장 강한 반응을 보이는 위치에만 집중하게 된다.
attention transfer에서 교사 네트워크의 공간적 주의 맵이 주어졌을 때 목표는 단순히 학생이 정확한 예측을 하도록 학습시키는 것뿐만 아니라, 학생 네트워크의 주의 맵도 교사의 것과 유사하게 만들도록 학습시키는 것이다.
일반적으로, 여러 계층에서 계산된 주의 맵을 기반으로 transfer loss을 걸 수 있다. 예를 들어 ResNet 구조에서는 교사와 학생의 깊이에 따라 다음 두 가지 경우를 생각할 수 있다.
① 깊이가 같은 경우: 모든 residual 블록마다 attention transfer를 적용할 수 있다.
② 깊이가 다른 경우: residual 블록들을 몇 개씩 묶은 그룹의 출력 활성화마다 attention transfer를 적용한다.
유사한 방식이 다른 아키텍처들에도 적용된다. 예를 들어 Network-In-Network 구조에서도, 하나의 그룹이 합성곱 계층으로 구성된 블록을 의미한다.
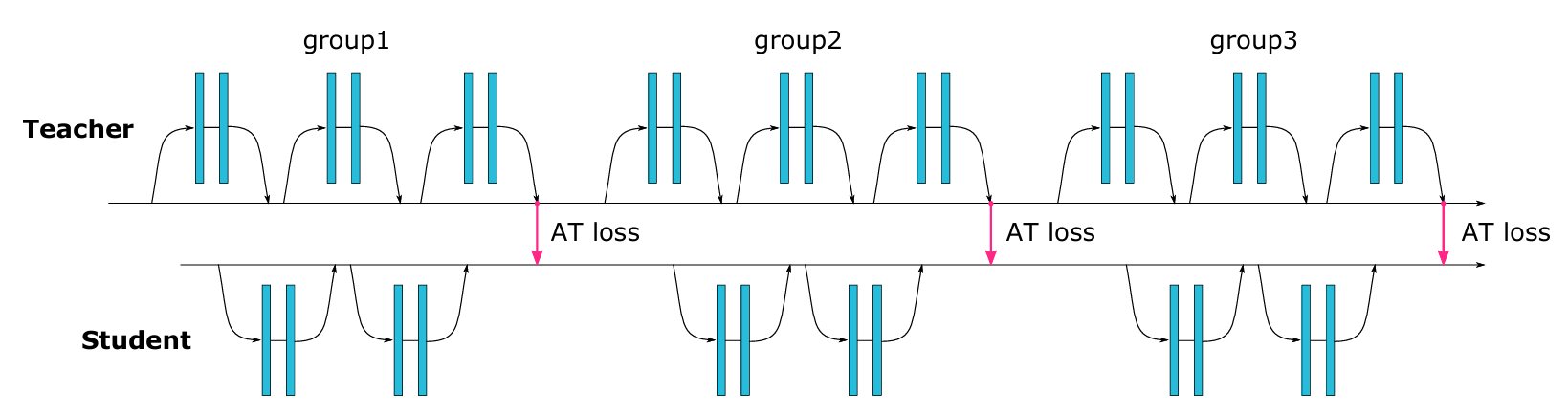
우리는 transfer loss이 공간 해상도가 동일한 학생과 교사의 attention map 사이에 적용된다고 가정한다. 단, 해상도가 다를 경우에는 주의 맵을 보간하여 크기를 맞출 수 있다.
우리는 다음과 같은 전체 손실 함수를 정의할 수 있다.
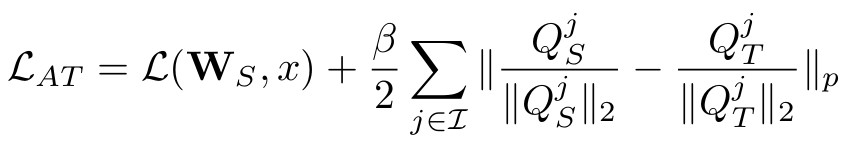
S, T: student와 teacher의 네트워크
Ws, Wt: 학생과 교사의 가중치
L(W,x): 교차 엔트로피 손실 함수
I: attention map을 전이하고자 하는 교사-학생 계층 쌍의 인덱스 집합
Qjs, Qjt: vec(F(AjS)), vec(F(Ajt)) 학생과 교사 네트워크의 j번째 attention map 쌍을 벡터 형태로 변환한 것이다. p는 사용하는 노름의 종류를 나타낸다. (실험에서는 p=2)
attention transfer를 수행할 때, 우리는 L2 정규화된 attention map을 사용한다. 각 attention map 벡터 Q는 다음처럼 정규화된다. attention map을 정규화하는 것이 학생 네트워크 학습의 성능에 매우 중요한 요소다.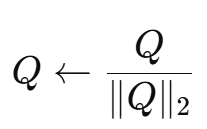
Attention Transfer는 또한 지식 증류(Knowledge Distillation)와 함께 사용할 수 있다. 교사와 학생의 soft label 분포의 교차 엔트로피 손실 항을 위 손실 함수에 추가하면 된다. 두 방법을 함께 사용할 때에도 추가 계산량은 적다. 교사의 attention map은 지식 증류를 위해 이미 수행되는 순전파 과정 중 쉽게 얻을 수 있기 때문이다.
📚 지식 증류(Knowledge Distillation)란?
출력값에는 정답 이외의 soft label이 숨어 있다. 이 정보를 활용해 학생 모델이 교사처럼 정교하게 학습되도록 한다. 학생은 교사의 분류 기준, 유사성 인식까지 흉내 낸다.
ⓑ GRADIENT-BASED ATTENTION TRANSFER
활성 기반 주의 전이에서 우리는 중간 계층의 출력을 이용하여 주의 맵을 정의했다. 하지만 또 다른 방법으로, 입력 x에 대한 손실 함수의 그래디언트(gradient)를 이용해 주의 맵을 만들 수도 있다. 이 접근 방식에서는, 교사와 학생 네트워크 각각의 손실 함수 L(W,x)에 대해
입력에 대한 그래디언트를 다음과 같이 정의한다.
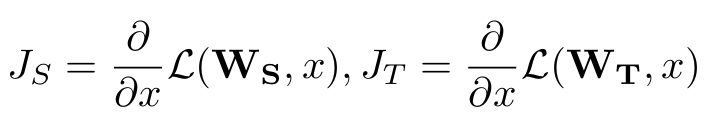
Ws, Wt: 학생과 교사의 가중치
Js, Jt: 입력에 대한 그래디언트
이 그래디언트는 네트워크가 입력의 어떤 부분에 민감하게 반응하는지에 대한 attention을 나타낸다. 주의 전이 손실 함수는 학생이 정답을 맞추는 것뿐 아니라, 입력에 대해 교사처럼 반응하도록 유도한다.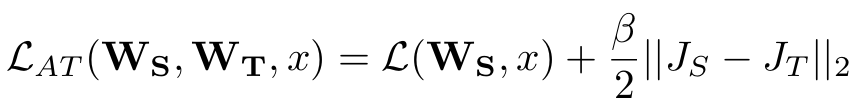
L(Ws,x): 학생의 분류 손실 (cross-entropy)
β: 주의 전이 손실 항의 가중치
EXPERIMENTAL SECTION
다음 섹션에서는 다양한 이미지 분류 데이터셋에서의 attention transfer를 탐구한다.
① CIFAR 데이터셋에서의 활성 기반 주의 전이와 그래디언트 기반 주의 전이 실험
② 활성 기반 주의 전이 실험을 더 큰 이미지 데이터셋에서 수행
활성 기반 주의 전이 실험에 사용한 네트워크 아키텍처는 Network-In-Network와 ResNet 기반 구조가 있다. 그래디언트 기반 주의 전이는 복잡한 자동 미분이 필요하기 때문에, 배치 정규화가 없는 Network-In-Network 모델과 CIFAR 데이터셋으로 실험을 제한하였다.
ⓐ CIFAR EXPERIMENTS
우리는 먼저 이미지 크기가 작고 널리 사용되는 CIFAR 데이터셋에서 실험을 시작한다. 이러한 작은 해상도에서는, 다운샘플링 이후 최상위 계층의 출력은 매우 작아져서 주의 전이를 적용할 수 있는 유의미한 해상도가 많지 않다. 이러한 불리한 조건에서도 주의 전이는 일관된 성능 향상을 가져왔다. 모든 실험에서 주의 전이를 적용하면 기본 모델 대비 성능이 꾸준히 향상되는 결과를 보여주었다.
데이터 증강은 horizontal flip과 random crop을 사용하였다.
이 실험에서는 Fsum2을 주의 맵 생성 함수로 사용하였다. 사용된 교사-학생 네트워크 조합은 다음과 같다. (WRN은 ResNet의 변형 구조)
① WRN-16-2 (교사) / WRN-16-1 (학생)
② WRN-40-1 (교사) / WRN-16-1 (학생)
③ WRN-40-2 (교사) / WRN-16-2 (학생)

모든 실험 조합에서 주의 전이(AT)는 의미 있는 성능 향상을 보여준다. 지식 증류(KD)와 함께 사용할 경우 성능이 더욱 향상된다.
우리는 또한 주의 전이 손실을 어디에 적용하느냐에 따라 결과가 어떻게 달라지는지도 실험했다. WRN-16-2 / WRN-16-1 조합에서 group1, group2, group3 각각에 하나씩 손실을 적용한 결과 오류율은 다음과 같다. 각 residual block group마다 attention transfer를 적용해도 성능 향상이 가능함을 보여준다.
① group1에만 적용: 8.11%
② group2에만 적용: 7.96%
③ group3에만 적용: 7.97%
④ 모든 group에 적용: 7.93% (가장 낮은 오류율)
또한 다양한 주의 맵 생성 함수들도 비교했다. WRN-16-2 (교사) / WRN-16-1 (학생) 조합에서 결과는 다음과 같다. sum 기반 함수들이 max 기반 함수보다 더 잘 작동하는 경향이 있다. 따라서 이후의 모든 실험에서는 성능이 우수한 Fsum2를 사용한다.

활성 기반 주의 전이가 단순히 전체 중간 특징 맵을 복사하는 방식보다 더 효과적인지 비교한다. 우리는 중간 계층의 전체 활성화 값들을 정규화한 후, 학생이 교사의 활성화와 유사해지도록 L2 손실을 적용하는 실험을 수행했다.
주의 전이(AT)와 전체 활성화 전이(F-ActT) 모두 학습 수렴 속도는 빠르게 만들었지만, 최종 정확도 향상은 AT가 훨씬 컸다. activation보다 attention map이 전이에 더 중요한 정보를 담고 있다는 것이다.
우리는 그래디언트 기반 주의 전이 실험들에서 Network-In-Network(NIN) 모델을 사용했다. 앞으로는 배치 정규화가 포함된 교사-학생 네트워크 쌍에 대해 그래디언트 기반 주의 전이를 탐구할 계획이다. 왜냐하면 그래디언트 기반 전이에 필요한 두 번째 역전파 단계에서 배치 정규화가 어떻게 작동해야 하는지가 아직 명확하지 않기 때문이다.
활성 기반 주의 전이와 마찬가지로, 그래디언트 기반 주의 전이 역시 성능 향상을 가져온다는 것을 확인했다. 같은 학습 조건에서 활성 기반 주의 전이(AT)를 적용해 훈련한 결과가 가장 좋은 성능을 기록했다.
ⓑ LARGE INPUT IMAGE NETWORKS
입력 이미지 크기가 224×224인 ImageNet 네트워크를 대상으로
은닉 활성화 기반 주의 전이 실험을 수행한다. 공간 해상도가 더 높기 때문에, 이러한 종류의 네트워크에서는 attention이 더 중요한 역할을 할 것으로 예상된다.
주의 전이가 finetuning에서 어떻게 작동하는지를 확인하기 위해, 두 개의 데이터셋을 선택했다.
① Caltech-UCSD Birds-200-2011 (CUB): fine-grained 분류를 위한 데이터셋
② MIT Indoor Scene Classification (Scenes) (Quattoni & Torralba, 2009)
두 데이터셋 모두 훈련 이미지가 약 5천 장 정도이다. 우리는 ImageNet 사전학습된 ResNet-18과 ResNet-34 모델을 사용해
각 데이터셋에서 파인튜닝을 수행했다.
CUB의 경우, 바운딩 박스를 기준으로 크롭한 뒤, 한 변을 256으로 리스케일하고 랜덤 크롭을 수행했다. 배치 정규화 계층은 파인튜닝 동안 고정하였고, 첫 번째 residual block 그룹은 동결시켰다.
파인튜닝된 ResNet-34를 교사 네트워크로 삼고, ImageNet 사전학습된 ResNet-18을 학생 네트워크로 하여 마지막 두 그룹의 출력에 Fsum2 기반 주의 전이 손실을 적용했다. 그 결과, 두 경우 모두에서 주의 전이는 성능을 유의미하게 향상시켜 ResNet-18과 ResNet-34 사이의 정확도 격차를 줄였다.

CUB 데이터셋에서는 주의 전이(AT)가 KD보다 훨씬 더 좋은 성능을 보였다(?) 이는 fine-grained 분류에서는 중간 단계의 attention이 특히 중요하기 때문이라고 추정한다. 파인튜닝 이후에도 주의 전이 과정을 통해 학생의 주의 맵이 교사의 것과 유사해진다.
ImageNet에서 활성 기반 주의 전이의 효과를 보이기 위해, 우리는 ResNet-18을 학생 네트워크, ResNet-34를 교사 네트워크로 사용하여
ResNet-18의 정확도를 향상시키고자 했다. 주의 전이 손실은 마지막 두 그룹의 residual block에만 적용했으며, 주의 맵 함수로는 F2sum을 사용했다. 하이퍼파라미터는 파인튜닝 실험에서 사용한 설정을 그대로 유지했다.
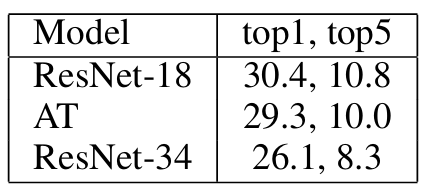
주의 전이를 적용한 ResNet-18은 Top-1 정확도에서 1.1%, Top-5 정확도에서 0.8% 향상된 검증 성능을 기록했다.
반면, ImageNet에서는 지식 증류(KD)를 사용했을 때 긍정적인 결과를 얻지 못했다. ResNet-18과 ResNet-34 조합의 경우 수렴 속도가 오히려 나빠졌다. KD는 교사와 학생의 구조나 깊이가 다를 경우 잘 작동하지 않는다.
그래서 우리는 동일한 아키텍처 및 깊이를 갖는 경우로 실험을 바꿔보았고, CIFAR에서는 AT와 KD 모두 수렴 속도와 정확도를 향상시켰다. 활성 기반 주의 전이 방법이 ImageNet에 성공적으로 적용된 최초의 지식 전이 방법이다.
CONCLUSIONS
우리는 한 네트워크에서 다른 네트워크로 주의를 전이하는 여러 방법을 제시하였고, 이를 다양한 이미지 인식 데이터셋에서 실험적으로 검증하였다. 향후에는 공간적 정보가 더 중요한 분야에서 attention transfer가 어떻게 작동하는지를 확인할 계획이다.
전반적으로, 우리가 제시한 흥미로운 결과들이 지식 증류의 발전,
그리고 CNN에 대한 이해를 심화하는 데 기여할 것이라 믿는다.
