abstract
few-shot classification 문제에서, 분류기는 훈련 세트에 포함되지 않은 새로운 클래스를 각 클래스당 소수의 예시만으로도 일반화해야한다. 본 논문에서는 이 문제를 위해 prototypical networks를 제안한다. prototypical networks는 각 클래스의 prototype representations과의 거리를 계산하여 분류를 수행할 수 있는 metric space을 학습합니다. 최근의 few-shot 학습 접근법과 비교할 때, 본 방법은 제한된 데이터 환경에서 유용한 더 단순한 귀납적 편향(inductive bias)을 반영하며, 우수한 성능을 보인다. 또한 복잡한 구조적 선택이나 meta-learning을 수반하는 최근 접근법에 비해, 몇 가지 단순한 설계 결정만으로도 상당한 성능 향상을 이끌어낸다. 마지막으로, 제안한 prototypical networks를 zero-shot learning으로 확장하여 CU-Birds 데이터셋에서 state-of-the-art 결과를 달성한다.
introduction
Few-shot classification은 훈련 세트에 포함되지 않은 새로운 클래스에 대해, 각 클래스당 아주 적은 수의 예시만을 이용해 분류기를 일반화해야 하는 과제다. 두 가지 최근 접근법이 few-shot 학습 분야에서 큰 진전을 이루었다.
① Matching Networks
학습된 임베딩 공간 위에서 support set과 query set 간의 attention 메커니즘을 이용해 가중치 기반 nearest-neighbor 분류를 수행한다. 학습 시 episode라는 미니 배치 구성 방식을 도입하여, 매번 few-shot 과제를 모방하도록 클래스와 샘플을 서브샘플링함으로써 테스트 환경과 유사한 조건에서 학습을 진행한다.
② Meta-Learner LSTM
episode를 입력으로 받아 분류기 파라미터의 업데이트를 생성하는 LSTM을 meta-learning한다. 단일 모델을 여러 episode에 걸쳐 학습하는 대신, 각 에피소드마다 맞춤형 분류기를 학습하는 방식을 취한다.
❓Matching Networks와 Meta-Learner LSTM
둘다 meta-learning 방식을 활용한다. 하지만 Matching Networks는 support set와 query set 간의 attention-weighted 거리 계산에 집중한 metric learning 기반이고, Meta-Learner LSTM은 gradient descent을 LSTM으로 학습하는 meta-optimization 접근이다.
본 논문에서는 데이터가 적기 때문에 발생하는 overfitting 문제를 핵심 이슈로 보고, 매우 단순한 inductive bias만을 가진 분류기를 설계하여 few-shot 학습 문제에 접근한다. Prototypical Networks는 각 클래스에 대해 하나의 prototype representation 주위로 점들이 군집하는 임베딩 공간이 존재한다는 생각에 기반한다.
Prototypical Networks: 이미지를 신경망 fϕ를 통해 비선형 임베딩 공간으로 매핑한다. support set의 각 클래스 샘플 임베딩의 평균을 해당 클래스의 프로토타입으로 정의한다. query sample x의 임베딩 fϕ(x) 을 계산한 뒤, 각 클래스 프로토타입과의 거리를 측정하여 가장 가까운 프로토타입으로 분류한다.
동일한 아이디어를 zero-shot learning에도 확장하여, 클래스 별 메타데이터를 별도 임베딩하여 프로토타입으로 사용한다.
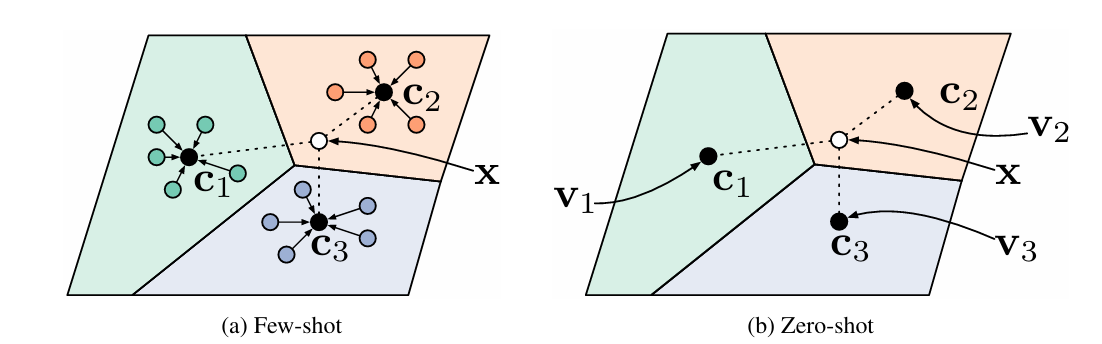
❓zero-shot learning이란?
각 클래스는 소수의 라벨링된 예시 대신 클래스에 대한 고수준 설명을 제공하는 meta-data가 제공된다. 본 논문에서는 이 meta-data를 공통의 임베딩 공간으로 매핑하여 각 클래스의 프로토타입으로 사용하도록 학습한다.
Prototypical Networks
ⓐ Notation
Few-shot 분류 문제에서는 소수의 레이블된 예시로 이루어진 support set가 주어진다.
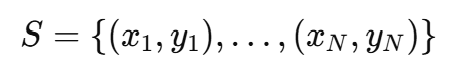
xi: D차원 특징 벡터(이미지)
yi: 클래스 레이블
ⓑ Model
Prototypical Network는 학습 가능한 매개변수 ϕ를 가진 임베딩 함수 fϕ를 통해 각 클래스에 대해 M차원 벡터 Ck(프로토타입)을 계산한다. 각 프로토타입은 해당 클래스 k에 속하는 support set의 예시들을 임베딩한 후 그 평균을 취하여 정의된다.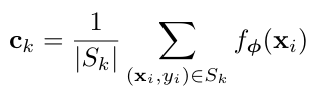
거리 함수(d)가 주어지면 쿼리 점 x에 대한 클래스 확률 분포는 각 프로토타입과의 거리를 소프트맥스에 적용하여 계산한다.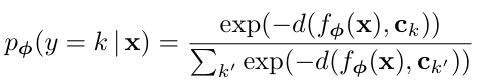
학습은 확률 분포 pϕ(y=k∣x)의 음의 로그 우도를 확률적 경사하강법으로 최소화하는 방식으로 진행된다.
ⓒ Prototypical Networks as Mixture Density Estimation
ProtoNet은 통계학의 혼합 밀도 추정(mixture density estimation) 관점에서 해석할 수 있다. ProtoNet은 혼합 밀도 추정(mixture density estimation)을 거리 기반으로 구현한 것이다. ProtoNet은 임베딩 공간에서 각 클래스가 하나의 분포 성분(component)이라고 보고, 이 성분들이 균등 비율로 결합된 혼합 모델을 가정한다. 각 성분 분포를 지수족 분포로 가정하면, 그 성분의 중심이 바로 클래스 프로토타입(mean)과 대응한다. 거리 함수로 정칙 Bregman 발산 dφ를 사용할 때, Protonet의 목적 함수는 지수족 분포를 이용한 혼합 밀도 추정(mixture density estimation)과 동치다. 따라서 정칙 Bregman 발산 dφ를 사용할 때 프로토타입을 클래스 평균으로 잡는 것이 통계적으로 최적의 선택임을 정당화한다.
ⓓ Reinterpretation as a Linear Model
제곱 유클리드 거리 d(z,z')=∥z−z'∥^2를 사용할 경우, 프로토타입 네트워크 분류기는 사실 선형 모델과 동등하다.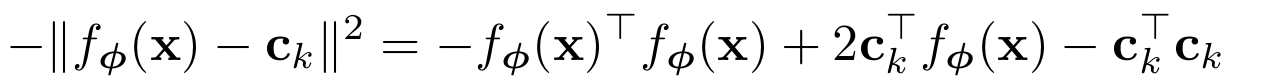
첫번째 항은 모든 클래스에서 동일하므로 소프트맥스 정규화때 사라지므로 무시한다.
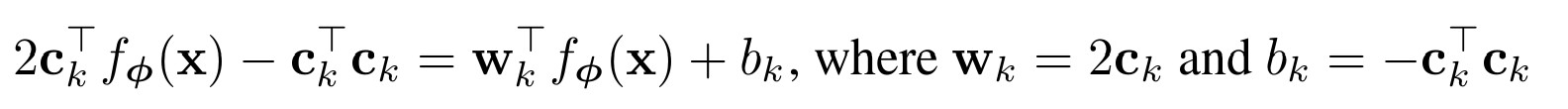
프로토타입 네트워크는 임베딩 함수 fϕ를 통해 비선형 변환된 피처 위에서 각 클래스별로 가중치 wk, 편향 bk를 갖는 선형 분류기를 수행하는 것과 동일하다. 유클리드 거리가 선형 모델과 동등함에도 불구하고 효과적인 이유는 필요한 모든 비선형성이 임베딩 함수 안에서 학습될 수 있기 때문이다.
ⓔ Comparison to Matching Networks
Prototypical Networks는 few-shot 환경에서는 Matching Networks와 차이를 보이지만, one-shot 설정에서는 두 모델이 동등해진다. Matching Networks는 가중치 기반 nearest-neighbor 분류를 수행하는 반면, Prototypical Networks는 선형 분류기를 생성한다(유클리드 거리를 사용할 경우). 특히 one-shot 학습에서는 클래스당 support sample이 하나뿐이므로 프로토타입 ck가 샘플 xk와 같아져, Matching Networks와 Prototypical Networks가 완전히 동일해진다.
ⓕ Design Choices
① 거리 함수 선택 (Distance metric)
기존 Few-shot 학습에서는 주로 코사인 유사도를 사용한다. 그러나 ProtoNet에서는 임의의 거리 함수를 쓸 수 있으며, 제곱 유클리드 거리(squared Euclidean distance)를 택했을 때 훨씬 나은 성능을 확인했다.
② 에피소드 구성 (Episode composition)
에피소드를 구성할 때는 “C-way K-shot” 형태를 테스트 환경과 동일하게 맞추는 것이 일반적이다. 예를 들어, 테스트 시 5-way 1-shot을 수행한다면, 훈련 에피소드도 클래스 개수를 5, 클래스 당 이미지를 1로 설정한다.
그러나 실험 결과, 훈련 시에는 테스트보다 더 많은 way를 쓰는 것이 성능 향상에 도움이 되었다. 논문에서는 검증 세트를 통해 탐색했다. 반면 shot은 훈련과 테스트에서 동일하게 유지하는 것이 보통 가장 좋은 결과를 보였다.
ⓖ Zero-Shot Learning
zero-shot 학습은 few-shot 학습과는 달리, 훈련 샘플의 support set이 주어지는 대신 각 클래스에 대해 클래스 meta-data 벡터 vk가 제공된다는 점에서 차이가 있다. meta-data 벡터들은 사전에 결정될 수도 있고, raw text로부터 학습될 수도 있다. 우리는 이 meta-data 벡터 vk를 또다른 임베딩 함수 gθ로 표현 공간에 매핑하여 프로토타입 ck=gθ(vk)을 생성한다. meta-data 벡터와 query 포인트가 서로 다른 함수에서 오는데, 경험적으로 프로토타입 임베딩 g의 출력을 정규화하여 단위 길이로 고정하는 것이 도움이 되었다.
Experiments
few-shot 학습을 위해 우리는 Omniglot과 miniImageNet에서 실험을 수행했다.
zero-shot 실험은 조류 데이터셋(CUB-200-2011)에서 수행했다.
ⓐ Omniglot Few-shot Classification
Omniglot은 1623개의 클래스로 이루어진 데이터셋이다. 각 문자는 20개의 예시를 갖고 있다.
먼저 grayscale 이미지를 28×28 크기로 리사이즈하고, 회전을 통해 문자 클래스를 4배로 증강한다. 훈련에는 1200개의 문자에 회전을 사용해 총 4800개의 클래스를 만들고, 나머지 문자 및 회전은 테스트에 사용한다.
임베딩 아키텍처는 4개의 convolution 블록으로, 각 블록은 64개의 3×3 filter convolution, batch normalization layer, ReLU, 2×2 max-pooling으로 이루어진다. 이 아키텍처를 28×28 Omniglot 이미지에 적용하면 64차원의 출력 벡터가 생성된다. support set과 query set 모두에 동일한 인코더를 사용한다. Adam을 사용한 SGD로 학습했으며, 초기 학습률은 10⁻³, 매 2000개 에피소드마다 학습률을 절반으로 줄였다.
Prototypical Networks는 60-way, 1-shot 및 5-shot 시나리오에서 유클리드 거리를 사용해 학습했다. 훈련 에피소드당 60개의 클래스와 클래스당 5개의 query를 포함했다. 우리는 훈련 시의 shot 수를 테스트 시와 일치시키고, 더 높은 way를 사용하는 것이 유리함을 발견했다. fine-tuning 및 non-fine-tuning 버전을 포함한 여러 기준 모델과 비교했다. 테스트 세트에서 무작위로 생성된 1000개의 에피소드에 대한 평균 분류 정확도를 계산했다. 이 데이터셋에서의 최첨단 성능을 달성했다.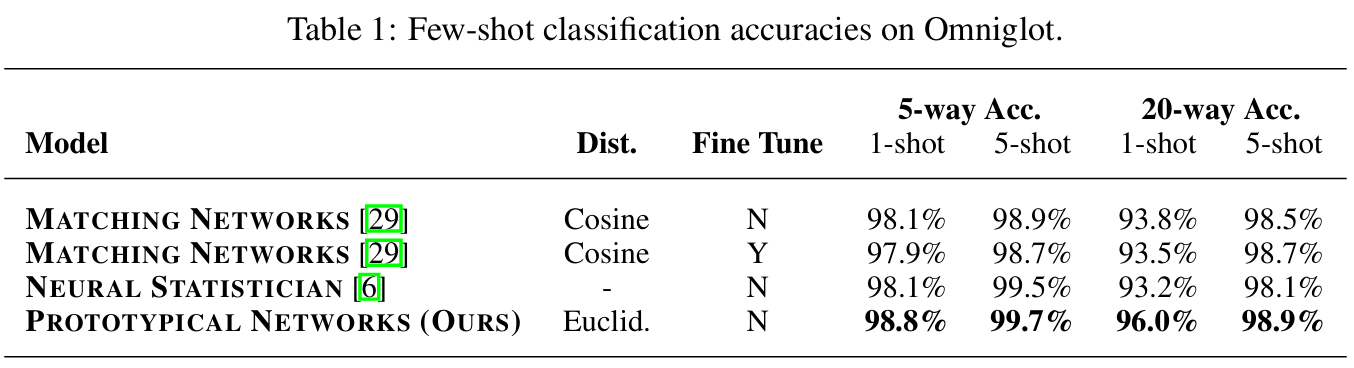
ⓑ miniImageNet Few-shot Classification
miniImageNet은 ILSVRC-2012에서 100개의 클래스를 무작위로 추출하고, 클래스당 600장의 이미지를 84×84 크기로 리사이즈한 소형 벤치마크 데이터셋이다. 우리는 훈련 64개, 검증 16개, 테스트 20개 클래스로 분할했다.
임베딩 네트워크 아키텍처는 Omniglot 실험에서 사용한 것과 동일한 구조를 사용한다. 학습률 스케줄도 Omniglot 실험과 동일하게 적용한다. 에피소드 구성은 1-shot 분류에 30-way, 5-shot 분류에 20-way를 사용했다. 학습 시 shot 수를 테스트 shot 수에 맞추고, 하나의 에피소드에 클래스당 15개의 query를 포함했다. Prototypical Networks는 여기에서도 큰 폭으로 최첨단 성능을 달성한다.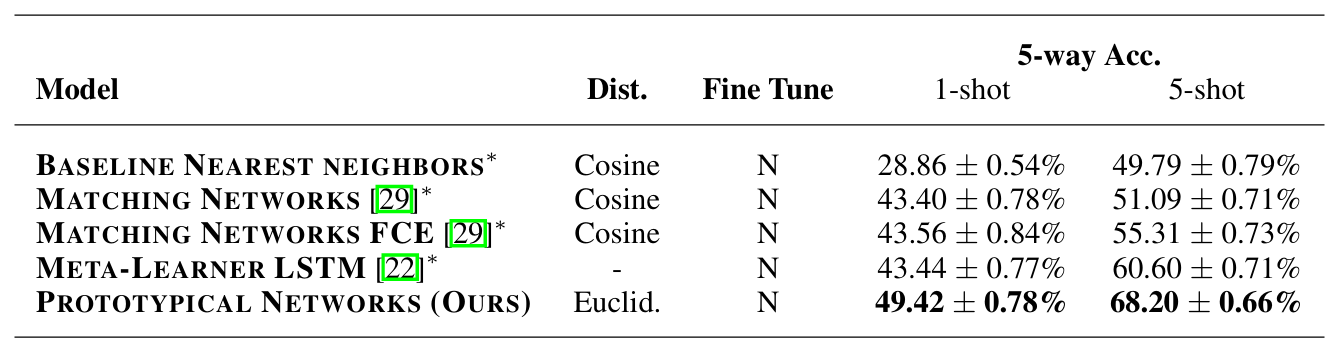
추가 분석으로 metric 선택과 에피소드당 훈련 클래스 수가 Prototypical Networks와 Matching Networks 성능에 미치는 영향을 조사했다. Prototypical Networks와 동일한 임베딩 아키텍처를 사용하는 Matching Networks 구현체를 자체적으로 작성했다.
1-shot 및 5-shot 시나리오에서 코사인 vs 유클리드 거리, 5-way vs 20-way 훈련 에피소드를 비교한다.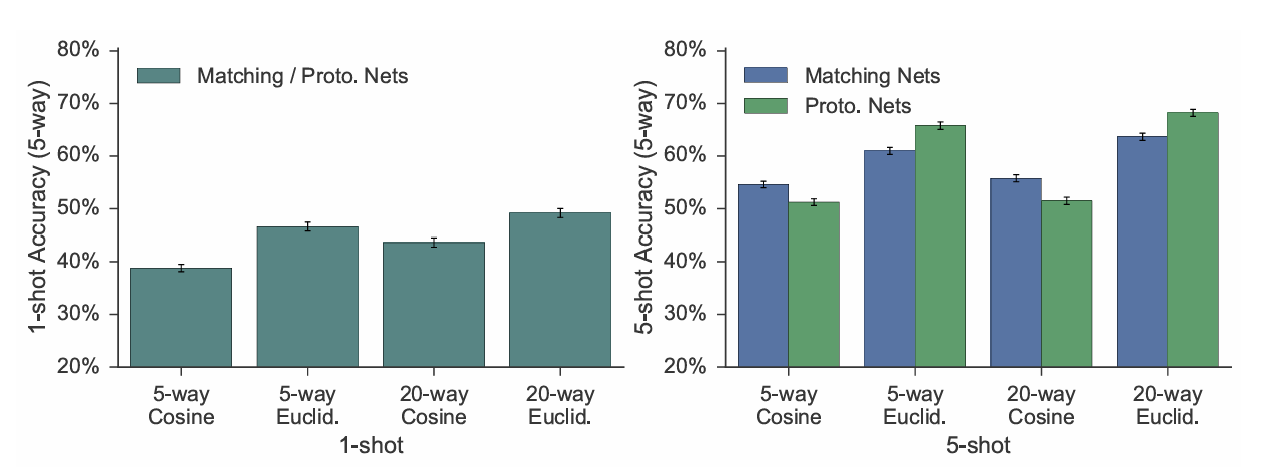
그 결과 20-way가 5-way보다 더 높은 정확도를 달성했으며, 이는 더 어려운 20-way 분류 과제가 임베딩 공간에서 보다 세밀한 결정을 강제함으로써 모델의 일반화 능력을 향상시키기 때문이라고 추측한다.
또한 유클리드 거리를 사용할 때 코사인 거리 대비 성능이 크게 개선되었는데, 특히 support set의 임베딩의 평균을 클래스 프로토타입으로 사용하는 Prototypical Networks에서는 코사인 거리가 Bregman 발산이 아니어서 자연스럽지 못한 반면, 유클리드 거리가 적합함을 확인했다.
CUB Zero-shot Classification
zero-shot learning에 우리의 접근법이 적합한지 평가하기 위해 Caltech-UCSD Birds (CUB) 200-2011 데이터셋에서도 실험을 수행한다. CUB 데이터셋은 200종의 조류에 대한 11788장의 이미지를 포함한다. 데이터 준비는 클래스를 100개(훈련), 50개(검증), 50개(테스트)로 분할한다.
이미지에 대해서는 원본 이미지와 수평으로 뒤집은 이미지 각각을 중앙, 좌상, 우상, 좌하, 우하 다섯 영역으로 크롭한 뒤, GoogLeNet을 적용하여 1024차원 특징 벡터를 추출한다. 테스트 시에는 원본 이미지의 중앙 크롭만 사용한다.
클래스 meta-data로는 CUB 데이터셋에 제공된 312차원 attribute 벡터를 사용한다. 이 속성들은 조류 종의 색상, 형태, 깃털 무늬 등 다양한 특성을 인코딩한 벡터다.
우리는 1024차원 이미지 특징과 312차원 속성 벡터 각각 위에 단순linear mapping을 학습하여 공통의 1024차원 임베딩 공간을 생성했다. 이 데이터셋에서는 속성 벡터가 이미지와 다른 도메인에서 오기 때문에, 클래스 프로토타입을 unit norm으로 정규화하는 것이 도움이 된다는 것을 경험적으로 확인했다.
훈련 에피소드는 50개 클래스, 클래스당 10개의 query 이미지로 구성했다. 임베딩은 Adam을 사용한 SGD로 학습했으며, 고정 학습률
10^−4와 weight decay 10^−5를 적용했다. 검증 손실이 더 이상 개선되지 않을 때 early stopping를 통해 최적의 에폭 수를 결정했다.
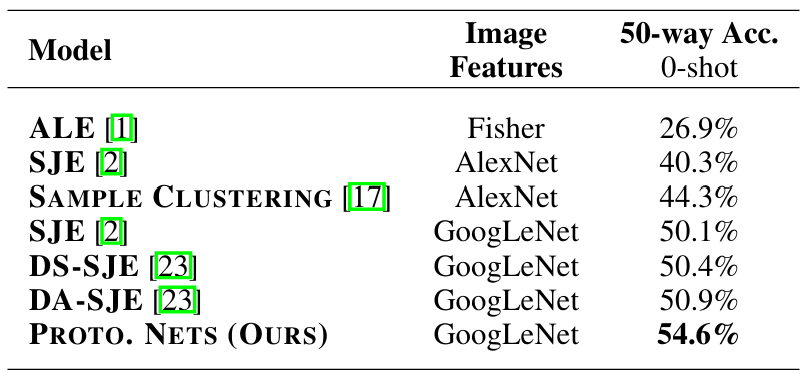
우리는 속성을 클래스 meta-data로 활용하는 기존 기법들과 비교했을 때 큰 폭으로 state-of-the-art 결과를 달성했다. 이 zero-shot 분류 결과는, 이미지와 클래스가 서로 다른 도메인에 있더라도 우리의 접근법이 충분히 일반적임을 보여준다.
Related Work
metric learning 분야의 연구는 방대하지만, 본 논문과 가장 밀접한 몇 가지를 요약하면 다음과 같다.
① Neighborhood Components Analysis (NCA)는 변환된 공간에서Mahalanobis distance를 학습해 KNN의 leave-one-out 정확도를 최대화한다. Salakhutdinov와 Hinton은 NCA의 선형 변환을 신경망으로 확장했다.
② Large Margin Nearest Neighbor (LMNN)은 hinge loss을 사용하여 각 점의 국소 이웃이 같은 레이블을 가진 점들로 이루어지도록 유도함으로써 KNN 정확도를 최적화한다.
③ DNet-KNN은 LMNN의 한계를 극복하기 위해, 단순 선형 변환 대신 신경망을 이용한 임베딩을 도입한 margin-based 방법이다.
이들 중 본 방법은 비선형 NCA와 가장 유사하다. 두 방법 모두 신경망 임베딩을 사용하고, 임베딩된 공간에서 유클리드 거리를 기반으로 소프트맥스를 최적화한다는 점이 공통적이기 때문이다. 그러나 비선형 NCA가 개별 데이터 포인트에 대한 소프트맥스를 구성하는 반면, Prototypical Networks는 클래스별 프로토타입(평균) 간의 거리로 곧바로 클래스 확률을 계산한다. 이로 인해 각 클래스는 support set 수와 무관하게 단일 벡터로 요약될 수 있으며, 예측 시 전체 support set을 저장할 필요가 없다.
또한, Nearest Class Mean 방법도 클래스당 예시들의 평균을 사용한다는 점에서 유사하다. 다만 선형 임베딩에 의존하며, 다수의 예시가 주어질 때 빠르게 새로운 클래스를 통합하는 데 초점이 맞춰져 있다. 이에 비해 Prototypical Networks는 신경망 기반의 비선형 임베딩과 episodic training을 결합하여, 적은 수의 support set만으로도 안정적인 분류 성능을 달성한다.
Mensink et al.도 클래스당 복수의 프로토타입을 허용하는 방법을 제안했으나, 이는 사전 처리 단계에서 k-means로 클러스터를 찾고 이를 선형 임베딩에 결합하는 방식이다. 반면 Prototypical Networks는 end-to-end 방식으로 단일 프로토타입만 학습하며, 다른 거리 함수에도 자연스럽게 확장된다.
센터 손실을 제안한 Wen et al.도 클래스 중심을 학습한다는 점에서 유사하지만, 두 가지 차이가 있다. 첫째, 그들은 클래스 중심을 모델의 파라미터로 직접 학습하는 반면, 우리는 에피소드 내 지원 샘플로부터 프로토타입을 계산한다. 둘째, 그들은 소프트맥스 손실과 결합해 표현이 0으로 붕괴하는 것을 방지하는 반면, Prototypical Networks는 프로토타입 기반 소프트맥스만으로도 자연스럽게 붕괴를 방지한다.
Few-shot meta-learning 관점에서는 Ravi와 Larochelle의 LSTM 기반 접근법이 있다. 이들은 LSTM의 동작이 그래디언트 하강(gradient descent)과 유사하다는 점에 착안해, LSTM 자체가 한 에피소드에서 모델 업데이트를 수행하도록 학습한다. MAML은 소수의 그래디언트 스텝만으로도 새 클래스를 잘 학습할 수 있는 표현을 meta-learning한다. Matching Networks와 Prototypical Networks 역시 에피소드마다 동적으로 분류기를 구성한다는 점에서 meta-learning으로 볼 수 있지만, 핵심 임베딩은 학습 이후 고정되어 있다는 차이가 있다.
Prototypical Networks는 생성 모델 분야의 Neural Statistician와도 관련이 깊다. Neural Statistician는 변분 오토인코더(VAE)를 확장하여, 개별 데이터 포인트가 아니라 데이터셋 전체의 생성 모델을 학습하는 방법론이다. 이 모델의 핵심 구성 요소 중 하나인 statistic network는 데이터셋 내 각 포인트를 인코딩한 뒤, 표본 평균을 구하고 추가 처리 네트워크를 적용하여 통계 벡터의 근사 후험 분포를 얻는다. Omniglot 데이터셋에서 각 문자를 하나의 데이터셋으로 간주하고, 테스트 이미지로부터 추론한 통계 벡터 후험 분포와 사전 계산된 클래스별 후험 분포 간의 KL 발산이 최소가 되는 클래스를 예측함으로써 one-shot 분류 성능을 평가했다.
이처럼 Neural Statistician와 마찬가지로 우리도 각 클래스에 대해 요약 통계를 생성하지만, 우리는 few-shot 분류에 초점을 맞추어, 생성 모델이 아니라 판별 모델로 설계했다.
zero-shot-learning 관점에서는, 프로토타입 네트워크의 임베디드 meta-data 활용 방식이 선형 분류기 가중치 예측(weight prediction) 기법과 유사하다. 또한 DS-SJE, DA-SJE는 이미지와 클래스 메타데이터를 위한 멀티모달 임베딩 함수들을 학습하지만, 이들은 경험적 위험 손실을 사용해 학습하며 episodic training을 사용하지 않는다. 반면, 우리의 접근법은 episodic training을 통해 학습 속도를 높이고 모델을 정규화할 수 있다.
conclusion
우리는 신경망으로 학습된 표현 공간에서 각 클래스의 예시들을 평균내어 하나의 프로토타입으로 표현할 수 있다는 아이디어에 기반하여, few-shot-learning을 위한 prototypical networks라는 간단한 방법을 제안했다. 이 네트워크를 few-shot 상황에서 잘 동작하도록 episodic training을 통해 특별히 학습시킨다. 이 방식은 최근의 meta-learning보다 훨씬 단순하고 효율적이며, Matching Networks에 적용된 정교한 확장 기법 없이도 최첨단 성능을 낸다.
또한, 거리 함수의 선택과 에피소드 구성 방식을 신중히 고려함으로써 성능을 크게 향상시킬 수 있음을 보였다. zero-shot 학습으로의 일반화 방법도 제시하여, CUB-200 데이터셋에서 최첨단 결과를 달성했다.
향후 연구 방향으로는, 제곱 유클리드 가우시안 이외의 클래스 조건부 분포에 대응하는 다른 Bregman 발산을 활용하는 것이다. 초기 탐색으로 클래스별 차원별 분산을 학습해보았으나, 별도의 파라미터 추가 없이도 임베딩 네트워크 자체의 표현력만으로 충분함을 확인했다.
전반적으로 프로토타입 네트워크의 단순성과 효과성은 few-shot learning을 위한 매우 유망한 접근법임을 시사한다.
