Abstract
이미지 분류에서의 Few-shot Learning은 각 클래스당 소수의 학습 데이터만으로 이미지를 분류할 수 있는 분류기를 학습하는 것이다. 본 논문에서는 DN4(Deep Nearest Neighbor Neural Network)를 제안하며, 이를 end-to-end 방식으로 학습시킨다. 본 방법의 핵심 차별점은 마지막 계층에서 이미지 수준 특징 기반 측정 대신 local descripter 기반의 image-to-class 측정을 사용하는 것이다. 이 측정은 합성곱 특징 맵의 local descripter에 대한 k-nearest neighbor search을 통해 수행된다. DN4는 image-to-class 측정을 위한 최적의 깊은 local descripter를 학습할 뿐만 아니라, 같은 클래스 내 이미지 간 시각적 패턴의 교환 가능성 덕분에 예제 부족 상황에서도 더 높은 효율성을 제공한다. 본 연구는 Few-shot Learning을 위한 간단하면서도 효과적이고 계산 효율적인 프레임워크를 제공하며, 벤치마크 데이터셋에서의 실험 결과는 관련 최신 기법보다 최대 17%까지 절대적인 성능 향상을 보여준다.
❓Local Descriptor란?
local Descriptor는 이미지를 부분별로 세밀하게 표현해 주는 벡터 세트다. few-shot learning처럼 데이터가 적을 때는, 이미지 전체 벡터 하나보다 이런 부분 기반 표현이 정보를 덜 잃고 클래스 간 차이를 잘 살려 준다.
Introduction
Few-shot learning은 소수의 예제만으로도 새로운 클래스에 즉시 적응할 수 있는 모델을 학습하는 것이다. 하지만 클래스마다 주어지는 예제가 극히 적기 때문에, 각 클래스의 분포를 온전히 대표하기 어렵고 이로 인해 문제가 매우 도전적이다.
이 과제를 해결하기 위해 지금까지 다양한 방법이 제안되었는데, 크게 meta-learning과 metric learning 두 가지로 구분할 수 있다. 전자는 meta-learning 기법을 도입해 여러 task을 아우르는 meta-learner를 학습함으로써 새로운 작업에 일반화한다. 보통 RNN이나 LSTM을 이용해 지식을 저장하는 메모리 네트워크를 학습한다. 후자는 상대적으로 단순한 구조를 사용해, 지식을 전달할 수 있는 딥 임베딩 공간을 학습하며, metric learning과 episodic training 기법에 의존한다. 두 계열 모두 few-shot learning 발전을 크게 이끌어 왔다.
하지만 기존 연구들은 knowledge transfer, concept representation, relation measure에 주로 집중했을 뿐, 최종 분류 단계에 대해서는 충분히 주의를 기울이지 않았다. image-level 풀링 특징이나 FC의 출력을 few-shot 환경에서도 사용해 왔다. 그러나 클래스별 예제가 부족하다는 few-shot learning의 특성을 고려할 때, 이러한 일반 관례는 적절하지 않다.
본 논문에서는 10여 년 전 제안된 Naive-Bayes Nearest-Neighbor(NBNN) 방법을 다시 살펴보고, 최신 few-shot learning 맥락에서 그 효과를 탐구한다. NBNN은 두 가지 핵심 통찰을 제공한다.
① 이미지의 local feature을 압축해 image-level 표현으로 요약하면 중요한 판별 정보를 크게 잃을 수 있고, 예제가 적을 때 이 손실은 복구되지 않는다.
② 예제가 적을 때 이미지 간 로컬 특징을 직접 비교하는 image-to-image 방식은 일반화가 어렵다. 대신 image-to-class 측정을 사용해, 같은 클래스 안 모든 이미지의 로컬 특징을 하나의 풀로 모아두고 쿼리 이미지의 특징과 비교한다.
❓Naive-Bayes Nearest-Neighbor(NBNN)란?
로컬 디스크립터 → 클래스 매칭을 직접 다루는 이미지 분류기다.
학습 단계: 각 클래스별로 모든 로컬 디스크립터를 모아 저장한다.
추론 단계: 이미지의 모든 로컬 디스크립터에 대해, 클래스별로 k-NN 거리를 계산해 합산한다. 이 합산 거리가 가장 작은 클래스가 추론된 클래스다.
이 통찰에 기반해 우리는 Deep Nearest Neighbor Neural Network(DN4) 라는 새로운 프레임워크를 제안한다. DN4는 최근의 episodic training 방식을 따르며 end-to-end로 학습된다. 기존 방법들과 달리 DN4는 마지막 계층에서 image-level 특징 기반 측정을 local descriptor 기반 image-to-class 측정으로 교체한다. 이는 합성곱 특징 맵에서 얻은 깊은 local descriptor들에 대해 k-NN 검색을 수행하여 온라인으로 계산된다. DN4는 예제가 적을수록 오히려 계산 효율성이 높아진다.
Related Work
최근 few-shot learning 연구 가운데 transfer learning 계열 방법이 본 논문과 가장 밀접하다. 따라서 이 방법을 크게 두 갈래로 나누어 살펴본다.
① Meta-learning based methods
meta-learning 기반 접근법은 meta-learner를 meta-learning(learning-to-learn) 패러다임으로 학습해 few-shot 문제를 해결한다. 이는 학습자의 모델 파라미터를 어떻게 갱신할지 결정하는 데 유리하다. 메타러닝 기반 방법은 few-shot 분류에서 우수한 성능을 보이지만, 복잡한 memory-addressing 구조 때문에 학습이 어렵다. 이에 비해 DN4는 일반적인 단일 CNN만으로도 end-to-end로 쉽게 학습할 수 있으며, 경쟁력 있는 성능을 보여 준다.
② Metric-learning based methods
metric-learning 기반 방법은 주로 유용한 유사도 메트릭을 학습하는 데 중점을 둔다. 본 논문의 DN4도 메트릭러닝 계열에 속하지만, 기존 방법들이 주로 image-level 특징을 사용한 반면, DN4는 딥 로컬 디스크립터와 image-to-class 측정을 채택한다. 이는 NBNN에서 영감을 받은 것으로, 실험 결과 DN4가 여러 최신 메트릭러닝 방법을 확실히 앞서는 성능을 보임을 확인할 수 있다.
The Proposed Method
ⓐ Problem Formulation(문제 정의)
support set S 는 서로 다른 C개의 이미지 클래스와, 클래스마다 K개의 라벨이 붙은 샘플로 구성된다. query set Q가 주어졌을 때, few-shot learning의 목표는 S를 이용해 Q 안의 모든 unlabeled 샘플을 올바른 클래스로 분류하는 것이다. 이 설정을 흔히 C-way K-shot 분류라 부른다. 그러나 S에 클래스당 샘플이 극소수에 불과할 경우, Q의 샘플을 효과적으로 분류할 모델을 학습하기가 어렵다. 이를 보완하기 위해 기존 연구들은 auxiliary set A를 사용해 전이 가능한 지식을 학습한 뒤, 그 지식을 Q 분류에 활용한다. A는 매우 많은 클래스와 라벨 샘플을 포함할 수 있지만, 라벨 공간은 S와 겹치지 않는다.
문헌에서 입증된 바와 같이, episodic training 기법은 A로부터 전이 지식을 효과적으로 학습하는 방법이며, 본 연구 역시 이를 채택한다. 구체적으로 학습의 각 iteration마다 few-shot 태스크를 모사한 episode를 구성해 분류 모델을 훈련한다. 하나의 에피소드는 보조 집합 A에서 무작위로 추출한 support set A_S 와 query set A_Q 로 이루어진다. 일반적으로 A_S 는 S와 동일한 C-way, K-shot 구성을 갖는다. 즉 A_S 안에는 정확히 C개의 클래스와 클래스당 K개의 샘플이 존재한다. 학습 단계에서는 수만 개의 에피소드를 생성해 모델을 훈련하며, 이를 episodic training 이라 한다. 테스트 단계에서는 지원 집합 S와 함께 학습된 모델을 사용해 질의 집합 Q의 각 이미지를 곧바로 분류한다.
❓auxiliary set이란?
수많은 support와 query 쌍의 episode을 뽑아낼 원천 데이터다. meta-training 단계를 수행할 데이터셋이다.
❓episodic training이란?
episodic training은 meta-learning을 구현하기 위한 핵심 훈련 전략 중 하나다. 훈련 데이터를 일반적인 방식(배치로 학습)으로 사용하지 않고, 각 step마다 episode를 생성해서 훈련한다.
ⓑ Motivation from the NBNN Approach(NBNN 접근법에서 얻은 동기)
본 연구는 주로 Naive-Bayes Nearest-Neighbor(NBNN) 방법에서 영감을 받았다. NBNN이 제시한 두 가지 핵심 관찰은 다음과 같다. 이것이 few-shot learning 상황에도 그대로 적용된다.
첫째, bag-of-features 기반 이미지 분류는 로컬 불변 특징들을 시각 단어로 양자화하여, 이미지마다 단어 분포를 만든다. 양자화 오차 때문에 image-level 표현에서 중요한 판별 정보가 크게 사라진다. 훈련 샘플이 충분하다면 이후 학습 과정이 어느 정도 그 손실을 복구하지만, 샘플이 적으면 손실을 되돌릴 수 없어 성능이 급격히 떨어진다. few-shot learning은 NBNN 당시보다 샘플이 훨씬 부족하다. 기존 방법들은 마지막 합성곱 특징 맵을 전역 평균 풀링이나 완전 연결층으로 압축해 image-level 표현을 만든 뒤 분류에 사용한다. 이때 역시 정보 손실이 발생하며, 예제가 적으면 복구가 불가능하다.
둘째, 두 이미지의 로컬 불변 특징을 직접 비교해 image-to-image 유사도로 분류해도 성능이 좋지 않다. 이런 유사도는 훈련 샘플 밖으로 일반화되지 않기 때문이다. 샘플 수가 적으면, 질의 이미지는 같은 클래스의 훈련 이미지들과도 모양·배경이 달라질 수 있다. 대신 image-to-class 측정을 사용해야 한다. 구체적으로, 같은 클래스의 모든 훈련 이미지에서 추출한 로컬 특징을 하나의 클래스 풀로 모은 뒤, 질의 이미지의 각 로컬 특징이 각 클래스 풀에 얼마나 가까운지를 계산해 분류한다.
❓로컬 불변 특징(Local Invariant Feature)이란?
작은 이미지 조각을 숫자 벡터로 표현한 것이다. local descriptor의 집합이다.
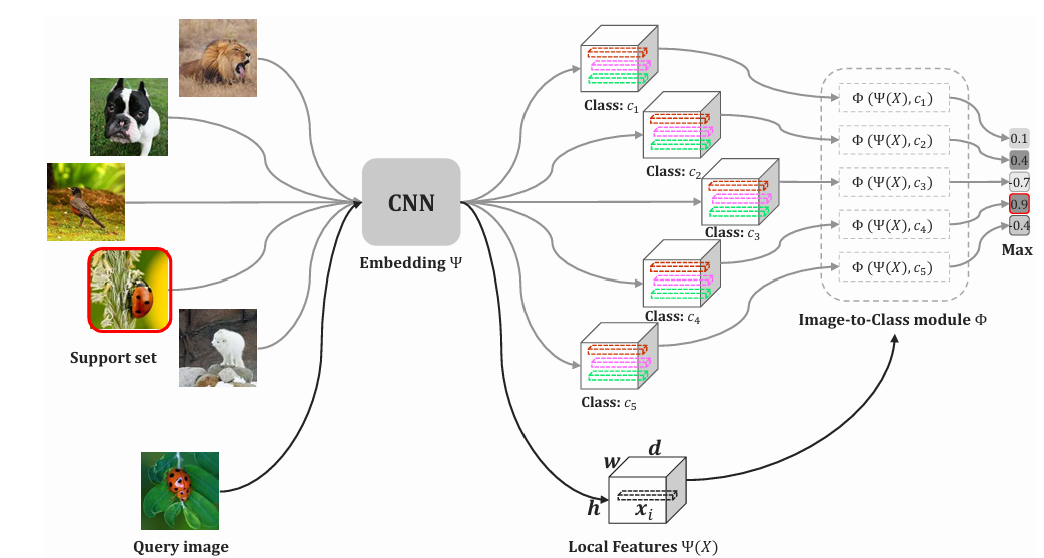
ⓒ The Proposed DN4 Framework(DN4 프레임워크)
DN4는 두 개의 구성 요소로 이루어진다. 딥 임베딩 모듈 Ψ, image-to-class 측정 모듈 Φ 이다. Ψ는 local descripter를 학습하고, Φ가 유사도를 계산한다. 이 두 모듈이 end-to-end 방식으로 학습된다.
① 딥 임베딩 모듈 Ψ
이미지에 대해 local descriptor를 학습·추출한다. Ψ는 합성곱 층만으로 이루어져 있으며 완전연결층은 없다. 이미지 X를 넣으면 h×w×d 텐서가 출력된다. 여기서 local descripter는 d차원 벡터로 개수가 h×w이다.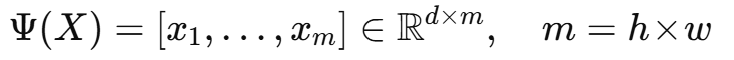
② image-to-class 측정 모듈 Φ
같은 클래스의 모든 학습 이미지에서 추출한 local descriptor를 한데 모아 클래스별 풀을 만든다. 쿼리 이미지 q 의 각 local descripter xi에 대해, 클래스 풀 안에서 k-최근접 이웃을 찾는다. q 와 클래스 c 사이의 image-to-class 유사도는 코사인 유사도를 사용하여 계산한다. 이렇게 얻은 유사도 값이 가장 큰 클래스가 쿼리 이미지의 예측 결과가 된다.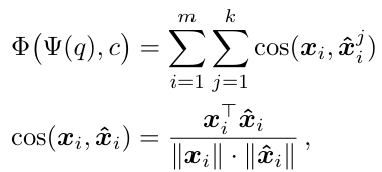
계산 효율성 측면에서 image-to-class 측정은 few-shot 분류에 특히 적합하다. NBNN에서 문제가 되었던 거대한 local descripter pool에서 k-NN을 검색해야 하는 계산 부담이 few-shot 환경에서는 클래스당 샘플 수가 훨씬 작아져 크게 완화된다. 따라서 제안한 프레임워크는 계산적으로 효율적이다. DN4의 image-to-class 모듈 Φ는 non-parametric이다. image-level 표현 위에 완전 연결층을 학습해야 하는 기존 few-shot 방법들에 비해 과적합 문제가 완화된다.
ⓓ Network Architecture
4층 합성곱 신경망을 임베딩 모듈로 채택하였다. 이 네트워크는 네 개의 합성곱 블록으로 이루어지며, 각 블록은 하나의 합성곱 층, 하나의 배치 정규화 층, 그리고 하나의 Leaky ReLU 층으로 구성된다. 또한 첫 번째와 두 번째 합성곱 블록 뒤에는 각각 2×2 max-pooling 층을 추가로 덧붙였다.
에피소드 학습의 각 iteration마다 지원 집합 S 와 질의 이미지 q를 모델에 입력한다. 임베딩 모듈 Ψ 를 거쳐 이들 이미지의 local descriptor을 얻는다. 이어서 모듈 Φ를 통해 q와 각 클래스 사이의 image-to-class 유사도를 계산한다. C-way K-shot 분류라면 유사도 벡터를 계산하며, 그 중 값이 가장 큰 항목에 대응하는 클래스가 q의 예측 결과가 된다.
Experimental Results
이 절의 주요 목적은 두 가지 흥미로운 질문을 탐구하는 데 있다.
① 에피소드 학습 없이 pre-trained deep features만을 사용한 NBNN은 few-shot 학습에서 어떤 성능을 보이는가?
② 제안한 DN4 프레임워크은 few-shot 학습에서 어떤 성능을 보이는가?
ⓐ Datasets
본 연구에서는 다음 네 개의 벤치마크 데이터셋을 사용하였다.
① miniImageNet: ImageNet의 축소 버전으로, 100개 클래스마다 이미지가 600장씩 포함되어 있다.
② Stanford Dogs: fine-grained 이미지 분류용 데이터셋으로, 개 품종 120종 총 20580장의 이미지로 구성된다.
③ Stanford Cars: fine-grained 이미지 분류용 데이터셋으로, 자동차 모델 196종 총 16185장의 이미지를 포함한다.
④ CUB-200: 200종의 새 이미지를 담고 있는 데이터셋으로, 총 6,033장이 수록되어 있다.
ⓑ Experimental Setting
모든 실험은 앞서 소개한 데이터셋들에 대해 C-way K-shot 분류 과제를 중심으로 진행되었다. 모든 데이터셋에서 5-way 1-shot 및 5-way 5-shot 분류를 수행하였다. 학습 단계에서 우리는 episode 학습 기법을 적용하여 300000개의 에피소드를 무작위로 샘플링하여 모든 모델을 학습시켰다. 모델 학습에는 Adam 옵티마이저를 사용했다. 테스트 단계에서는 테스트 세트에서 600개의 에피소드를 무작위로 샘플링하고, Top-1 평균 정확도를 평가 지표로 사용하였다. 이 절차를 다섯 번 반복하여 최종 평균 정확도를 보고하였고, 95 % 신뢰 구간도 함께 제시하였다. 모든 모델은 처음부터 end-to-end로 학습되었으며, 테스트 단계에서 별도의 파인튜닝은 필요하지 않았다.
ⓒ Comparison Methods
Baseline methods: 위 데이터셋들에서의 기본적인 분류 성능을 보여 주기 위해, 우리는 기준 방법으로 k-NN을 구현했다. 또한 4절 서두에 제시한 첫 번째 질문에 답하기 위해, k-NN 방법에서 FC 층을 잘라 낸 사전 학습 Conv-64F를 사용하여 NBNN 알고리즘을 다시 구현하였다.
Metric-learning based methods: 우리의 방법이 메트릭러닝 계열에 속하므로, 최신 메트릭러닝 기반 모델 네 가지(Matching Nets FCE, Prototypical Nets, Relation Net, Graph Neural Network(GNN))와 비교한다.
Meta-learning based methods: 최신 메타러닝 기반 모델 다섯 가지를 참고용으로 포함하였다. 해당 모델은 Meta-Learner LSTM, Model-Agnostic Meta-Learning(MAML), Simple Neural AttentIve Learner(SNAIL), MM-Net, Dynamic-Net이다.
ⓓ Few-shot Classification
일반적인 few-shot 분류 실험은 miniImageNet에서 수행되었다. NBNN는 k-NN보다 훨씬 높은 성능을 달성했다. 이는 local descripter가 image-level 특징보다 우수할 수 있음을 보여 주는 동시에, image-to-class 측정 방식의 잠재력을 입증한다.
그러나 NBNN은 최신 메트릭러닝 기법과 상당한 성능 차이를 보인다. 이는 NBNN이 lazy learning 알고리즘이라 별도의 학습 단계가 없고, episodic training도 적용되지 않기 때문이다. 에피소드 학습 없이 pre-trained deep features만을 사용한 NBNN은 few-shot 학습에서 좋은 성능을 보이지 않는다.
반면, 우리가 제안한 DN4는 image-to-class 측정을 깊은 신경망 내부에 내장하고, episodic training을 통해 깊은 local descripter를 함께 학습함으로써 확실히 더 우수한 결과를 얻었다. 기존 방법들은 image-level 특징 수가 너무 적은 반면, DN4는 학습 가능한 local descripter를 사용해 특히 5-shot 환경에서 더 풍부한 정보를 제공한다. 또한 로컬 디스크립터의 교환 가능성 덕분에 클래스 분포를 더 효과적으로 모델링할 수 있다. 제안한 DN4 프레임워크은 few-shot 학습에서 좋은 성능을 보인다.
ⓔ Fine-grained Few-shot Classification
일반적인 few-shot 분류 실험과는 별도로, 우리는 세 개의 fine-grained 데이터셋(Stanford Dogs, Stanford Cars, CUB-200)에서 fine-grained few-shot 분류 과제도 수행하였다. 이들 데이터셋에 대해 두 개의 베이스라인 모델과 세 개의 최신 모델을 구현하였다. 일반적으로 fine-grained few-shot 분류는 클래스 간 변별력이 작고 클래스 내 변동이 크기 때문에, 일반적인 few-shot 문제보다 더 어렵다. 세밀 데이터셋은 클래스 간 차이가 작으므로, 불필요한 시각 잡음을 줄이기 위해 우리 DN4에서는 k=1을 선택하였다. 5-shot 설정에서 DN4는 이들 데이터셋에서 놀라울 정도로 우수한 성능을 보인다. 1-shot 설정에서는 5-shot만큼 두드러지지 못했는데, 이는 우리 모델이 lazy learning인 k-최근접 이웃에 의존하며 k-최근접 이웃의 성능은 표본 수에 큰 영향을 받기 때문이다. 샷 수가 늘어날수록 DN4 성능이 점진적으로 향상된다.
ⓕ Discussion
Ablation study: image-to-class 측정이 image-to-image 측정보다 효과적임을 추가로 검증하기 위해, 우리는 DN4의 image-to-image 변형 모델로 소거(ablation) 실험을 수행하였다. miniImageNet 결과를 보면 DN4보다 낮은 성능을 보인다.
백본 네트워크의 영향: 일반적으로 사용하는 Conv-64F 외에도, 더 깊은 임베딩 모듈 ResNet-256F를 이용해 모델을 평가하였다. ResNet-256F를 사용했을 때 DN4의 5-way 1-shot 정확도는 조금 올라간다. 즉, 더 깊은 백본을 쓰면 나은 성능을 얻을 수 있다.
이웃(k) 값의 영향: image-to-class 모듈에서는 쿼리 이미지의 각 로컬 디스크립터에 대해, 지원 클래스에서 k-최근접 이웃을 찾아야 한다. 적절한 k를 고르는 것이 중요하기 때문에, miniImageNet에서 5-way 5-shot 실험을 수행하며 k = {1, 3, 5, 7}을 바꿔 보았다. k 값이 성능에 미치는 영향은 비교적 완만했다.
샷 수의 영향: 현재 few-shot 학습에서 널리 쓰이는 episodic training은 훈련과 테스트의 shot 수와 way 수를 일치시키는 것이 원칙이다. 그러나 실제 훈련 단계에서 일치 조건, 부족 조건, 과다 조건의 영향을 알고자 하였다. 실험 결과, 과다 조건(훈련 shot 수가 테스트보다 많은 경우) 이 일치 조건보다 우수하며, 부족 조건(훈련 shot 수가 더 적은 경우)보다 훨씬 낫다는 것을 확인했다.
Conclusions
본 논문에서는 local descripter 기반 image-to-class 측정을 재조명하고, few-shot 학습을 위해 단순하면서도 효과적인 DN4(Deep Nearest Neighbor Neural Network)를 제안하였다. 우리는 학습 가능한 깊은 local descripter가 image-level 특징보다 few-shot 문제에 더 적합하며, 분류 성능을 크게 끌어올릴 수 있음을 강조하고 실험적으로 입증하였다. 또한, 같은 클래스 내부에서 시각적 패턴이 교환 가능하다는 특성 덕분에, image-to-class 측정이 image-to-image 측정보다 우수하다는 사실도 확인하였다.
