Abstract
Cross-Domain Few-Shot Learning (CDFSL)은 데이터가 풍부한 소스 도메인에서 데이터가 부족한 타깃 도메인으로 지식을 전이하여 빠르게 적응하도록 모델을 학습시키는 과제로, 큰 도메인 간 격차가 문제를 어렵게 만든다. Masked Autoencoder (MAE)는 비지도 학습 방식으로 라벨이 없는 데이터를 효과적으로 활용하고 이미지의 전반적인 구조를 학습하는 데 뛰어나며, 이는 모델의 일반화 능력과 견고성을 향상시킨다. 그러나 도메인 변화가 큰 CDFSL 과제에서는 MAE의 성능이 오히려 기본적인 지도 학습 모델보다 떨어지는 현상이 나타난다.
본 논문에서는 이러한 현상을 해석하고자 분석을 수행하였다. MAE는 이미지 픽셀을 재구성하는 과정에서 저수준의 도메인 정보를 학습하는 경향이 있으며, 재구성 대상을 token features으로 변경하면 이러한 문제를 완화할 수 있음을 발견하였다. 그러나 모든 특성이 전이 학습에 유리한 것은 아니며, 고수준의 features을 재구성 대상으로 삼을 경우 오히려 전이 성능 향상이 어렵다는 점도 발견되었는데, 이는 도메인 정보의 필터링과 이미지 전반 구조 보존 사이의 트레이드오프를 시사한다. 즉, CDFSL 과제에서는 재구성 대상의 선택이 매우 중요하다.
이러한 분석을 바탕으로, 우리는 CDFSL을 위한 새로운 접근 방식인 Domain-Agnostic Masked Image Modeling (DAMIM)을 제안한다. DAMIM은 도메인에 구애받지 않는 정보를 학습하면서 이미지의 전반적 구조를 보존하기 위해 특성을 자동으로 통합하는 Aggregated Feature Reconstruction 모듈과, 인코더의 일반화 능력을 더욱 향상시키는 Lightweight Decoder 모듈을 포함한다. 네 개의 CDFSL 벤치마크 데이터셋에서의 실험 결과, 제안된 방법은 최신 성능을 달성하였다.
Introduction
딥러닝의 발전으로 신경망은 대규모 데이터셋을 효과적으로 처리할 수 있는 능력을 갖추게 되었다. 그러나 일부 분야에서는 대량의 데이터를 수집하는 것이 매우 어렵기 때문에 Cross-Domain Few-Shot Learning (CDFSL) 과제가 주목받고 있다. 이 과제는 대규모 사전 학습 데이터셋과 같은 일반적인 소스 도메인에서 모델을 먼저 학습시킨 뒤, 학습 샘플 수가 극히 제한적인 타깃 도메인으로 지식을 전이하는 방식이다. 하지만 소스 도메인과 타깃 도메인 간의 큰 격차는 전이 학습과 이후의 다운스트림 학습을 어렵게 만들며, 이러한 domain gap을 해결하는 것이 CDFSL의 핵심 과제가 된다.
Masked Autoencoder (MAE)는 이미지의 일부 영역을 마스킹하고 이를 복원하는 과제를 통해 이미지의 전반적인 정보를 학습하는 자기 지도 학습 방식으로, 다양한 다운스트림 작업에서 뛰어난 일반화 성능을 보여왔다. 하지만 CDFSL 과제에 MAE를 적용했을 때, 오히려 지도 학습된 Vision Transformer (ViT)보다 성능이 떨어지는 경우가 많다는 점이 확인되었다. 이러한 직관에 반하는 결과는 "도메인 간 격차가 클 경우 왜 MAE의 성능이 저하되는가?"라는 근본적인 질문을 유발한다.
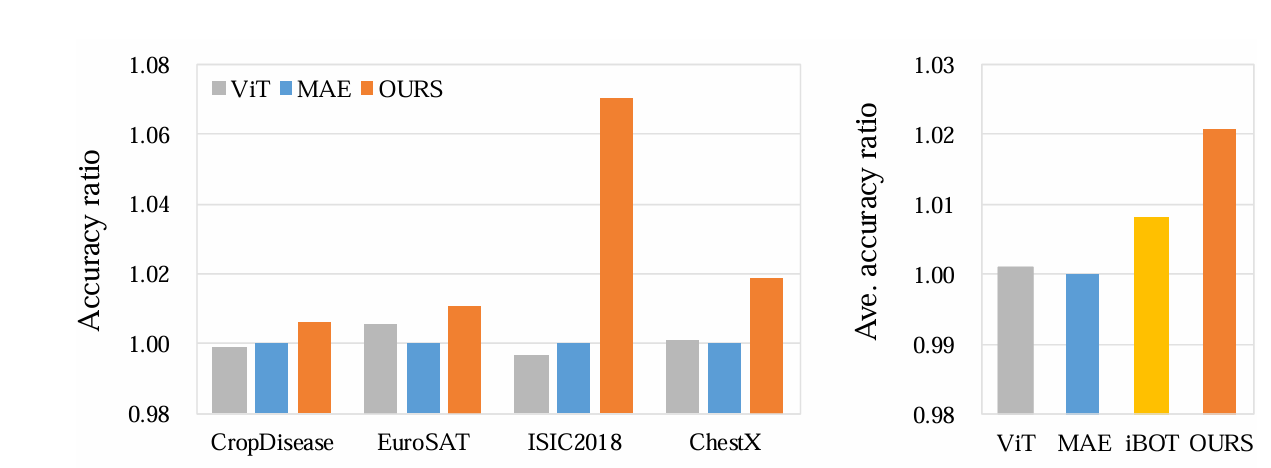
본 논문에서는 이러한 현상에 대한 해석을 위해 먼저 MAE의 상위 개념인 Masked Image Modeling (MIM) 전체를 조망한다. 그 결과, 마스킹된 토큰 특성을 재구성 대상으로 삼는 iBOT 모델은 이미지 픽셀을 대상으로 삼는 MAE보다 더 나은 성능을 보였으며, 이는 픽셀 기반 재구성 방식의 역할에 의문을 제기하게 만들었다. 분석 결과, MAE는 이미지 픽셀을 재구성하는 과정에서 픽셀에 내포된 저수준 도메인 정보를 학습하는 경향이 있음이 드러났다. 반면, 재구성 대상을 token features으로 변경하면 이러한 도메인 정보가 필터링되어 문제가 완화된다. 그러나 모든 특성이 유익한 것은 아니며, 고수준 features을 재구성 대상으로 사용할 경우에는 오히려 전이 성능 향상이 어렵다는 점도 확인되었다. 이는 도메인 정보 필터링과 이미지 전체 구조 보존 사이의 트레이드오프 문제를 시사한다. 결국, CDFSL 과제에서 재구성 대상의 선택은 매우 중요한 요소임이 밝혀졌다.
이러한 통찰을 바탕으로, 우리는 CDFSL 과제를 위한 새로운 접근 방식인 Domain-Agnostic Masked Image Modeling (DAMIM)을 제안한다. DAMIM은 두 가지 주요 구성 요소로 이루어져 있다.
① Aggregated Feature Reconstruction (AFR)
여러 층에서의 특성을 통합하여 도메인에 구애받지 않는 재구성 대상을 생성함으로써 도메인 특화 정보의 학습을 줄이고 이미지의 전반적 정보를 유지한다.
② Lightweight Decoder (LD)
재구성 대상이 픽셀에서 특징으로 단순화됨에 따라, 모듈을 추가하여 인코더가 디코더에 과도하게 의존하는 것을 방지하고, 인코더의 일반화 능력을 한층 더 향상시킨다.
광범위한 실험 분석을 통해 DAMIM의 장점이 입증되었으며, CDFSL 벤치마크 데이터셋에서 탁월한 성능을 달성하였다.
-Masked Image Modeling
Masked Image Modeling (MIM)은 이미지의 일부 영역을 마스킹한 후 이를 복원하는 과제를 통해 유용한 이미지 표현을 학습하도록 모델을 훈련시키는 자기 지도 학습 방식이다. MIM 연구는 주로 재구성 대상에 따라 다음과 같이 분류된다.
① 픽셀 기반 방식
② 토큰 기반 방식
픽셀 기반 MIM 방식에서는, 예를 들어 MAE처럼, 마스킹된 픽셀을 주변의 보이는 영역으로부터 원래의 픽셀 값을 복원하는 데 초점을 둔다. 반면, 토큰 기반 MIM 방식에서는 이미지에서 추출된 고수준 표현 또는 토큰을 예측 대상으로 삼는다.
토큰에는 의미적 정보가 내포되어 있어, 다양한 시각 인식 과제에서 매우 효과적인 것으로 알려져 있다. 이러한 기술적 진보에도 불구하고, MAE의 성능을 CDFSL 과제에 특화하여 분석한 연구는 아직 존재하지 않으며, 이는 향후 연구가 필요한 영역으로 남아 있다.
Delve into MAE’s limited performance in CDFSL
-MAE tends to learn low-level information
토큰 기반 방식인 iBOT 모델이 픽셀 기반인 MAE보다 CDFSL 과제에서 더 우수한 성능을 보이는 것을 관찰하였다. 이 결과는 픽셀 수준의 재구성이 CDFSL에서 어떤 역할을 하는지에 대한 의문을 불러일으킨다. 우리는 MAE가 픽셀 복원에 집중함으로써 오히려 CDFSL 성능이 낮아질 수 있다고 가정한다. 왜냐하면 픽셀 복원은 이미지의 밝기나 색상과 같은 저수준 시각 정보를 학습하도록 모델을 유도하는데, 이러한 정보는 도메인 특성과 강하게 연결되어 있기 때문이다.
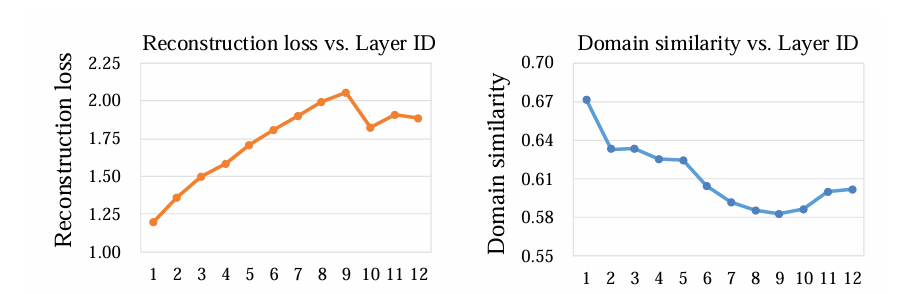
이러한 MAE의 학습 경향을 분석하기 위해, 우리는 Vision Transformer (ViT)의 서로 다른 층의 feature들을 재구성 대상으로 설정하였다. 얕은 층 feature을 재구성할 때 손실이 더 낮게 나타났으며, 이는 모델이 상대적으로 저수준 정보를 더 쉽게 포착하고 학습하려는 경향이 있음을 보여준다. 이러한 경향은 MAE가 고수준 표현보다는 저수준 정보에 더 집중하게 만들 수 있다.
-Low-level information exhibits domain specificity
저수준 정보의 성질을 더 깊게 분석하기 위해, 우리는 ViT의 서로 다른 계층에서 나온 출력을 마스킹하여 교란하는 실험을 수행하였다. 이후 소스 도메인과 타깃 도메인 간의 최종 출력 특성의 유사도를 CKA(Centered Kernel Alignment)로 측정하였다.
그 결과, 저수준 정보가 교란되었을 때, 고수준 특성이 교란되었을 때보다 도메인 유사도가 크게 증가하는 것을 확인할 수 있었다. 이는 저수준 정보가 도메인 특이성을 강하게 지니며, 소스 도메인에 특화된 중요한 도메인 정보를 많이 포함하고 있음을 의미한다.
따라서 MAE는 복원 과정에서 이러한 저수준 정보에 우선적으로 의존하는 경향을 보이며, 이 정보가 소스 도메인에 강하게 결부되어 있기 때문에 타깃 도메인으로의 일반화 성능을 저해하게 된다.
반면, 네트워크의 깊이가 깊어질수록 이러한 저수준 정보는 점차 필터링되어 사라지고, 모델은 보다 의미적이고 일반적인 정보를 학습하게 된다. 이러한 이유로, 복원 대상을 픽셀 대신 token features으로 변경하면 모델의 일반화 성능을 향상시킬 수 있음을 시사한다.
-Reconstruction with high-level features
픽셀 수준 또는 저수준 특성은 domain-specific한 정보가 풍부하므로, 우리는 고수준 특성을 재구성 대상으로 사용하는 전략을 추가로 탐구하였다. ViT의 서로 다른 층에서 추출한 특성을 재구성 대상으로 설정했을 때, 저수준 특성은 소스 도메인과 타깃 도메인 간 도메인 유사도가 낮게 나타났으며, 이는 앞선 섹션에서 논의한 결과와 일치한다.
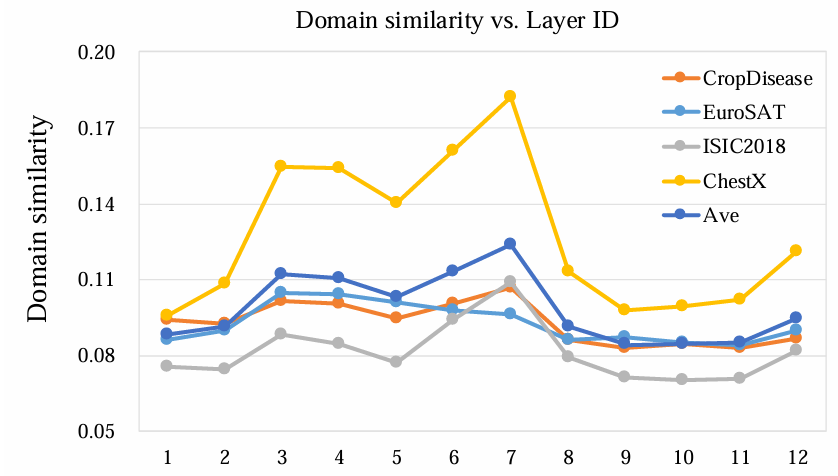
그러나 모든 층의 특성이 도메인 일반화에 유리한 것은 아니며, 특히 네트워크의 출력부와 가까운 고수준 특성은 그 효과가 제한적이다. 얕은 층에서는 모델이 주로 색상 분포, 밝기와 같은 저수준 정보를 포착하는데, 이러한 정보는 도메인별 차이가 크기 때문에 전이되기 어렵다. 반면 네트워크의 깊이가 깊어질수록, 모델은 점차 보다 추상적이고 의미적인 정보에 집중하게 된다.

하지만 이러한 고수준 특성은 이미지 내의 의미적 객체가 위치한 특정 영역만을 강하게 활성화시키는 경향이 있으며, 배경이나 부수적 영역에 대한 정보는 충분히 반영하지 못한다. 이는 MIM이 원래 목표로 하는 이미지 전체 구조 학습을 방해하게 된다. 그 결과, 고수준 특성을 재구성 대상으로 사용할 경우 도메인 유사도가 급격히 감소한다.
따라서, 저수준 도메인 특이 정보를 효과적으로 제거하는 것과 동시에 이미지의 전반적 구조를 보존하는 것 사이에는 본질적인 트레이드오프가 존재한다.
-Conclusion and Discussion
CDFSL 과제에서 Masked Image Modeling (MIM)의 성능은 재구성 대상에 크게 영향을 받는다. 저수준 특성이나 픽셀을 재구성 대상으로 사용할 경우, 색상 분포나 밝기와 같은 저수준 도메인 정보가 그대로 모델에 학습되어 일반화 성능을 저해한다.
반면, 고수준 특성을 재구성 대상으로 사용할 경우, 모델은 이미지 내 의미적 객체가 위치한 일부 영역에만 집중하게 되며, 이는 MIM이 본래 학습해야 하는 이미지의 전반적 구조를 충분히 포착하지 못하게 만든다.
따라서 적절한 재구성 대상을 자동으로 선택할 수 있는 방식을 설계하는 것이 필요하다.
Method
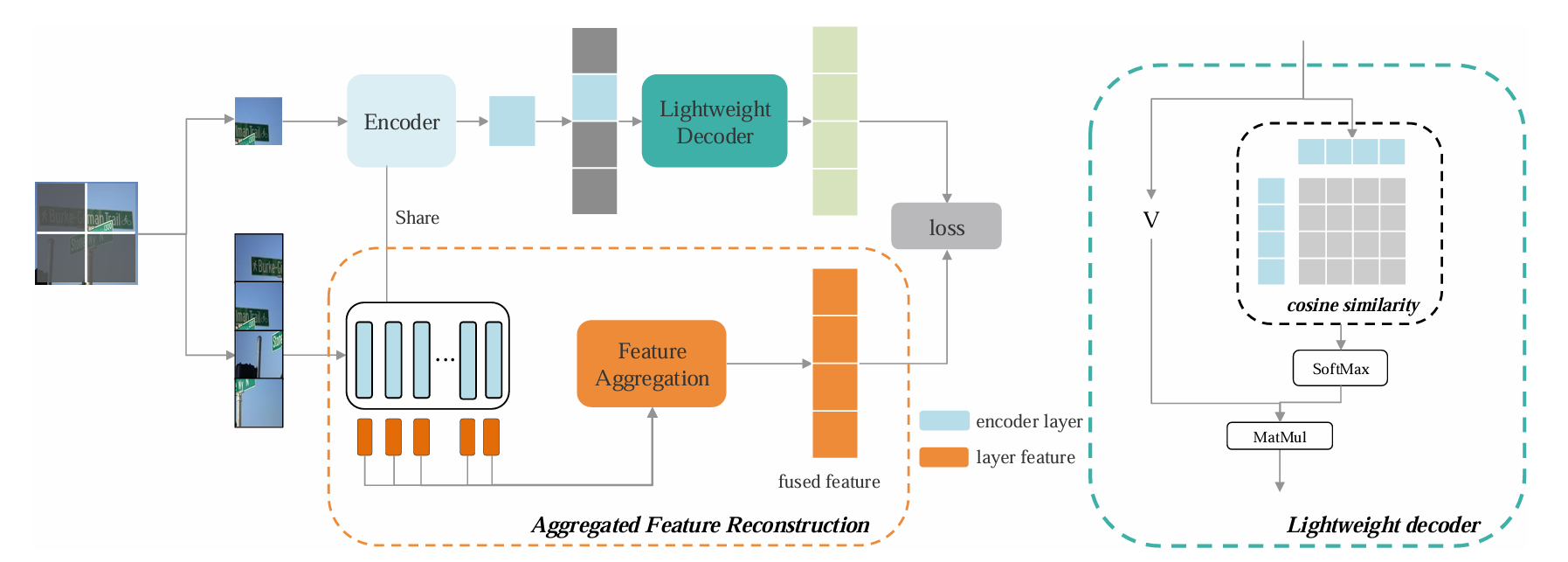
이 절에서는 CDFSL을 위한 Domain-Agnostic Masked Image Modeling (DAMIM) 접근 방식을 소개한다. 먼저, 우리는 Feature Aggregation Reconstruction (AFR) 모듈을 제안하는데, 이는 여러 계층에서 추출된 특성들을 통합하여 재구성 대상으로 활용한다. AFR을 보완하기 위해, 우리는 인코더가 재구성 과정에서 디코더에 과도하게 의존하는 것을 방지하고, 결과적으로 인코더의 일반화 성능을 향상시키는 Lightweight Decoder (LD) 모듈을 설계하였다. 이후의 절에서는 제안된 모델의 각 구성 요소를 상세히 설명한다.
-Aggreated Feature Reconstruction Module
저수준 도메인 정보를 필터링하면서도 이미지의 전반적 정보를 보존하기 위해, 우리는 가장 적합한 특성들을 자동으로 통합하여 재구성 대상으로 활용하는 AFR(Aggregated Feature Reconstruction) 모듈을 제안한다.
우선, 원래 인코더와 가중치를 공유하는 보조 인코더를 구축하여 여러 계층에서의 특성을 추출한다. 원래 인코더는 이미지의 visible patches만 처리하는 반면, 보조 인코더는 모든 패치를 입력으로 받아 처리한다.
MAE의 방식에 따라, 입력 이미지는 겹치지 않는 패치들로 분할된다. 이후 이 패치들 중 상당수를 무작위로 마스킹하여, visible patch 집합과 masked patch 집합을 생성한다. 원래 인코더는 visible patch를 입력받아 다음과 같은 잠재 표현을 생성한다.
동시에, 보조 인코더는 전체 패치를 입력받아 l-번째 계층의 feature을 다음과 같이 출력한다.
여기서 f(l)은 보조 인코더의 l번째 층 출력이다. 그다음, 층별 특성을 결합하기 위해 feature aggregation 모듈을 도입하며, 서로 다른 계층의 특성 공간을 맞추기 위해 projection 계층을 추가한다. 각 층 l에 대해 feature alignment은 다음과 같이 이루어진다.
정렬된 특성들을 통합하기 위해, 다음과 같은 weighted average pooling 메커니즘을 사용한다.
여기서 α(l)은 각 층의 재구성 손실에 기반해 선형 계층과 softmax를 통해 생성되는 가중치이다. 최종적으로, 집계된 특성 F는 재구성 대상으로 사용되며, 이는 여러 계층의 정보를 효과적으로 결합하도록 한다.
-Lightweight Decoder
재구성 대상이 feature 기반이므로, MAE의 재구성 과정에서 인코더가 디코더에 과도하게 의존하는 현상을 방지하기 위해 Lightweight Decoder를 설계하였다. 이를 통해 인코더가 보다 일반화 가능한 표현을 학습하도록 유도한다.
제안하는 디코더는 하나의 Transformer 블록과 단일 attention head로 구성되어 연산량을 크게 줄였다. 또한 기존의 query–key 기반 attention 대신, 토큰 간 cosine similarity를 사용한다.
여기서 ti는 image token을 의미한다. 이러한 대체는 구조를 단순화할 뿐만 아니라, 디코더의 영향력을 줄이려는 목적에도 부합한다. 또한 디코더 내 MLP 모듈을 완전히 제거하여 구조를 더욱 간결하게 만들었다.
이후 인코더가 생성한 가시 패치 표현 Z와 masked patch로부터 생성된 mask token M을 결합하여 디코더에 입력한다. 마스크 토큰은 마스크 패치를 임베딩하고 위치 정보를 더해 얻는다. 디코더의 최종 출력은 다음과 같다.
이렇게 생성된 R이 최종 재구성 결과가 된다.
-Reconstruction Loss
MAE와 동일하게, 재구성 손실은 masked patches에 대해서만 계산한다. 우리의 재구성 대상은 feature 기반이므로, 재구성된 특성과 target 특성 간의 MSE를 손실 함수로 사용한다. 재구성 손실은 다음과 같이 정의된다.
-Target domain evaluation and fine-tuning
타깃 도메인에서의 평가 및 파인튜닝 단계에서는 디코더는 제거하고, 인코더만 백본으로 유지한다. 최근 연구를 따라, 우리는 few-shot 에피소드 내에서 프로토타입 기반 분류를 수행하거나, 에피소드의 support set을 사용하여 백본을 fine-tuning하여 classifier 기반 분류를 진행한다.
Experiments
-Comparison wit SOTA Method
DINO로 사전학습된 ViT-S 백본을 사용하여 1-shot 및 5-shot 설정에서 기존 최신 SOTA 기법들과 우리 방법을 비교한 것이다. fine-tuning을 적용한 결과와 적용하지 않은 결과를 구분하였으며,
별표(*)는 transductive setting을 의미한다.
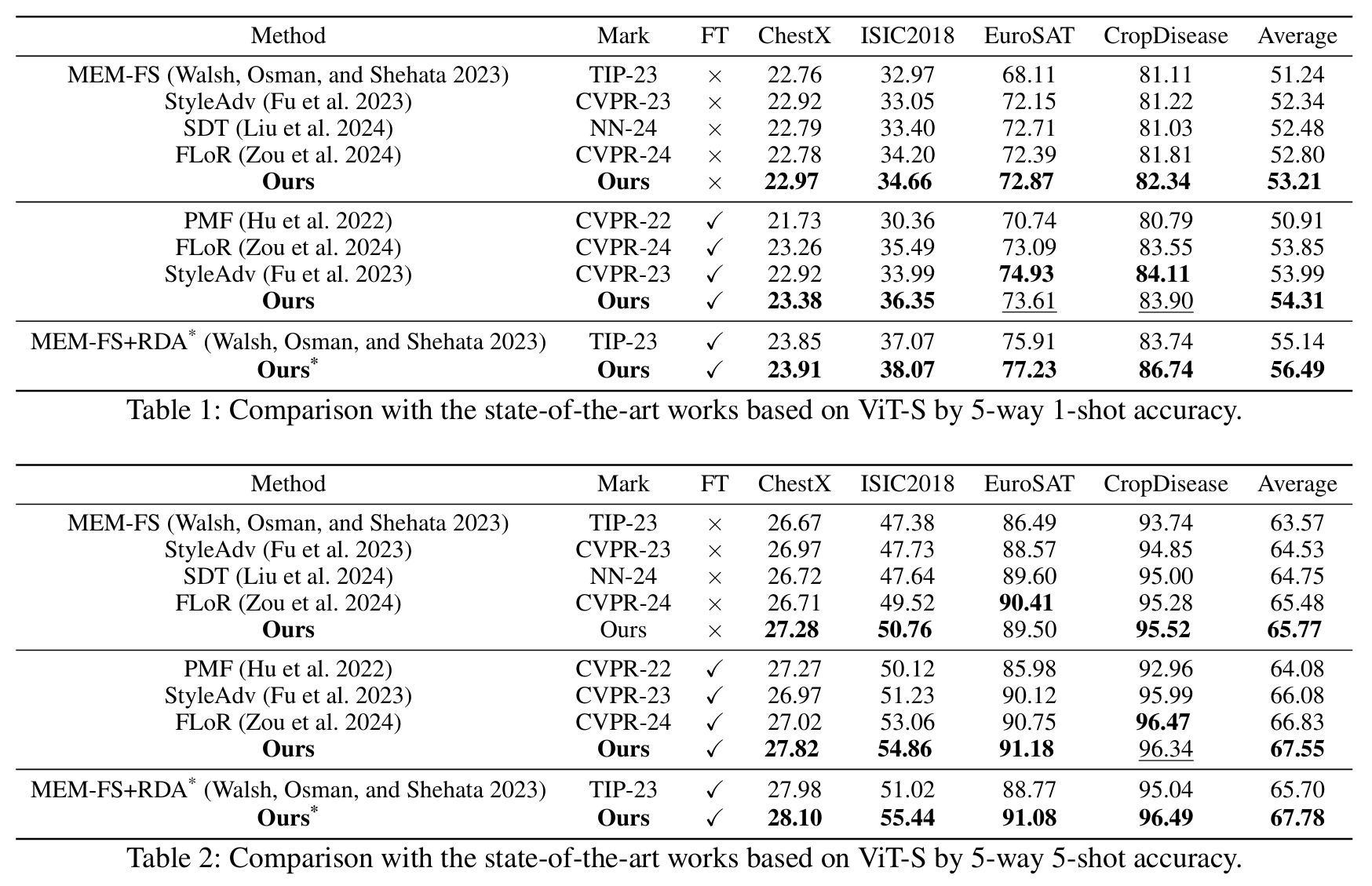
모든 설정에서 꾸준히 더 우수한 성능을 보임으로써, 우리의 DAMIM 방법이 높은 효과성을 지님을 확인할 수 있다.
Conclusion
본 논문에서는 MAE가 픽셀 재구성 과정에서 저수준 도메인 정보에 집중하는 경향이 있으며, 반면 고수준 특성 재구성은 전이 가능성 측면에서 어려움을 겪는다는 점을 밝혔다. 이는 도메인 정보를 얼마나 걸러내는지와 이미지 구조를 얼마나 보존하는지 사이에 트레이드오프가 존재함을 의미한다. 이를 바탕으로, 우리는 학습 균형을 위한 Aggregated Feature Reconstruction 모듈과 일반화 성능을 향상시키기 위한 Lightweight Decoder 모듈을 포함한 DAMIM을 제안하였다. 실험 결과, DAMIM은 최신 SOTA 기법들을 능가하는 성능을 보였다.
