항상 그렇듯이 유투브 알고리즘님의 인도로 2009년도 k-pop을 정주행하다가, 문득 든 생각이 있었다. 나는 2009년에 이런 가수들의 노래를 들었던 기억이 있어서 이런 좋은 노래가 있었던 것을 알기 때문에 나중에 내가 기억이 나면 찾아 듣기라도 하지, 이런 곡들이 있었다는 사실조차 모르는 사람들은 이런 고귀한 노래를 듣지도 못한 채 2세대 아이돌 처돌이 유투브 알고리즘님의 간택만을 기다려야 한다는 사실이 떠올랐다.
물론 자신이 사는 시대가 제일 최고인 것 같지만, 그걸 한눈에 볼 수 있는 k-pop 역사관이 있으면 좋겠다는 생각에 무작정 시작하게 되었다.
처음에는 크롤링이고 나발이고 그냥 timeLine만 깔끔한거 찾아서 원하는 대로 데이터를 나열하고 싶었는데, 생각보다 데이터의 양이 방대하였고(생각보다가 아니라 사실 당연한거다. 아이돌 2세대부터 하려고 했으니..) 일일이 찾아서 스프레드시트에 끼워넣으려니 현타가 씨게 왔다. 그래서 그냥 믿져야 본전이라는 마인드로 멜론을 어떻게 잘 크롤링 해보고자 한다.
사실 이 글은 내가 원한 대로 크롤링을 완벽하게 한 뒤에 그 과정을 서술하는 글이 아니다. 그냥 개발을 진행하면서 현재의 내가 알게 된 사실을 미래의 나는 분명히 까먹을 것이기 때문에 미래의 나를 위해 족적을 남기는 것이라고 할까...
잡설이 길었다. 크롤링을 시작하도록 하자.
크롤링을 처음 해 본 관계로, 구글링을 통해 여러 블로그의 도움을 받았다. 이로 인해 코드가 상당 부분 유사할 수 있으나, 코드에 대한 이해는 필수이기 때문에 아래의 내용은 코드 이해 + 내가 필요해서 추가적으로 개발한 것으로 이루어진다.
참고한 블로그들의 주소는 글 아래에 달아두겠다.
멜론 주간 차트 한개 크롤링하기
크롤링을 하는 이유?
밑에 부분 작성하다가 먼저 이걸 쓰고 지나가야 할 것 같아서 그냥 내 생각을 정리해 보자면, 인터넷에는 매우 다양하고 유용한 데이터들이 있음에도 불구하고 그 데이터를 API로 친절하게 제공하는 곳은 몇 없다. 물론 으른들만의 여러가지 사정이 있겠지..
하지만, 회사님들께서 데이터를 하사하시지 않는다고 하여 눈앞의 꿀 데이터를 그냥 보기만 하고 지나갈 수가 없으니... 웹 사이트가 뿌려질때 나오는 코드를 어떻게 잘 구워 삶아서 그 좋은 데이터들을 뽑아먹자는게 생각해보니까 굉장히 불법같은데 기분탓인가 크롤링의 본질^^ 이라고 나는 생각하련다.
그러니까 머기업님들 데이터좀 API로 주세요 예?
예전에 빅스비 해커톤 참가했다가 데이터만 있으면 만들 수 있는 다양한 아이디어들이 나왔는데, 그때 당시에 크롤링을 하지 못해 좋은 아이디어들을 못 써먹은게 너무 아쉽다. 이번 기회에 배워야지!
아 참고로 나는 이번이 크롤링 거의 처음이라고 할 수 있다. 1학년때 쓸데없이 불타오르는 의지로 크롤링 책을 사서 좀 해봤지만 머리에 남는게 없었으니 그냥 처음 해보는거랑 똑같다 :)....
requests를 이용하여 html 가져오기
먼저, 파이썬에는 requests라는 라이브러리가 있다. 이 라이브러리는 HTTP 요청을 보내는 모듈이다. 멜론 차트를 가져오려면 멜론 홈페이지로 HTTP 요청을 주고받아야 하기 때문에, 해당 라이브러리가 필요하다.
import requests아래의 header 부분은 https 요청에 같이 보내질 부분이다. 기본적으로 http의 header에는 여러 가지 헤더들이 존재하는데, User-Agent 헤더는 현재 사용자가 어떤 클라이언트를 이용해 요청을 보냈는지를 서버에 알려 주는 역할을 한다. (참고)
요청을 보낼 때 header부분을 항상 보내야 하는것은 아니지만, 내가 참고한 블로그 분은 header를 같이 보내지 않으면 가끔 튕겨나가는 현상이 있어서 header를 추가해 주셨다고 한다.
request.get()메소드를 이용하여 원하는 url의 https 요청을 받아온다. 이후 받아온 데이터를 text로 변환을 한다.
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Trident/7.0; rv:11.0) like Gecko'}
req = requests.get('https://www.melon.com/chart/week/index.htm', headers = header) ## 주간 차트를 크롤링 할 것임
html = req.text여기까지 진행하면 그냥 https 요청이 text로만 되어 있을 뿐이다. 크롤링을 하기 위해서는 html 태그를 쏙쏙 뽑아 먹어야 하기 때문에, BeautifulSoup 라이브러리를 이용하여 html로 파싱해 준다.
parse = BeautifulSoup(html, 'html.parser')HTML 태그로 데이터 뽑아먹기
위의 과정까지 진행했다면, 이제 열심히 데이터를 뽑아먹을 준비가 된 것이다.
위에서도 말했듯이, 크롤링의 본질은 웹사이트를 만들기 위해 뿌려지는 코드 속에 숨어있는 데이터를 잡아먹기 위함이므로 이 사이트가 어떤 코드에 의해 만들어졌는지를 알아야 한다.
크롬 브라우저에서는 F12 버튼을 누르면 해당 웹사이트의 여러가지 속사정을 볼 수 있다. 예를 들어 내가 지금 크롤링하고자 하는 멜론 차트에서 개발자 도구를 열면 다음과 같이 HTML 코드가 주루룩 나온다
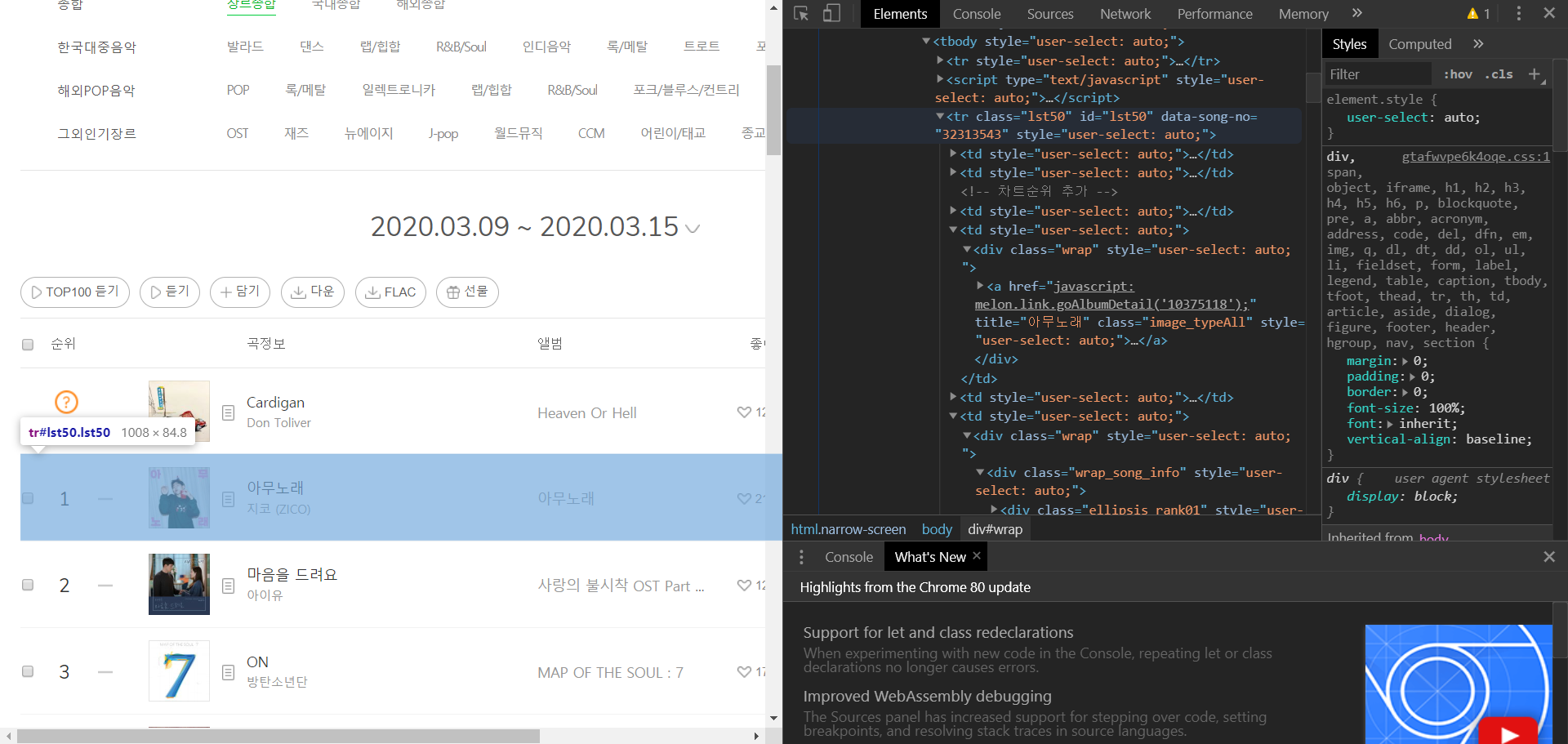
사진에서도 알 수 있듯이, 코드 위에 커서를 올리고 잘 탐색을 하다 보면 내가 뽑고 싶은 데이터가 어떤 코드에 의해 생겨났는지를 매우 상세하게 알 수 있다.
이제 여기서 가장 중요한 점이 있는데, 커서를 위에 올리면서 오 뭐야 신기해 라고 끝날게 아니라 div 태그를 계속 열고 tbody 태그를 열고 tr 태그를 열고 또 td 태그를 역로 div 태그를 열고 a 태그를 열고 쭉쭉쭉 진행하면서 내가 원하는 데이터가 어떤 html 태그들에 의해 싸여 있는지를 알아야 한다.
왜냐하면, 우리는 아까 받아온 html을 파싱해 놓았으니 태그를 이용하여 데이터를 찾을 수 있기 때문!
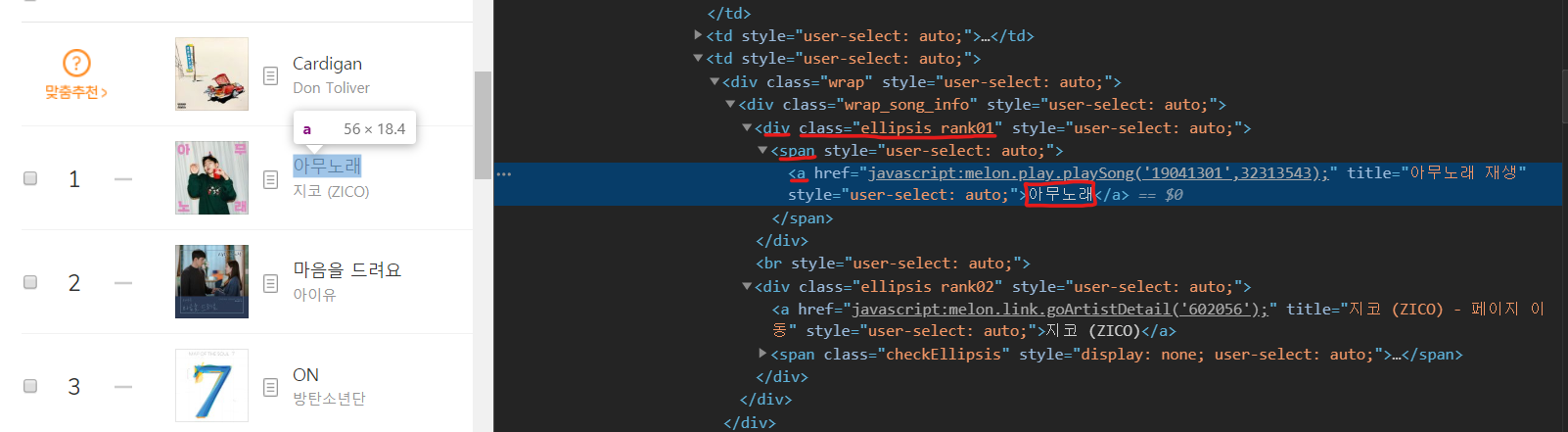
예를 들어, 저렇게 차트에서 곡의 이름을 뽑는다고 치면, 제일 안쪽 태그는 a가 될 것이고, 그 a 태그는 span에 싸여 있고, 그 span 태그는 div에 싸여 있는데 그 div는 특별하게 class가 정해져 있다.
보통 차트처럼 같은 구조가 반복되면서 나타나는 페이지는 각 데이터마다 같은 class를 사용하게 되는데, 이를 통해 class의 이름을 파악하면 그 데이터에 접근하기가 쉬워진다.
따라서, 음악 제목과 가장 가까이 위치한 이름(class)이 붙은 태그는 ellipsis rank01이 붙은 div 태그이므로, 아까 파싱해둔 데이터에서 div 태그 중 클래스가 ellipsis rank01인 모든 부분을 다 찾을 것이다.
이후, 그 안에 a 태그가 하나밖에 없기 때문에 바로 a 태그를 찾고, a 태그에 걸려 있는 text를 뽑아 내면 우리가 원하는 음악 제목이 나온다!
이런 과정을 곡명, 가수명, 앨범이름에 모두 적용하면 다음과 같은 코드를 작성할 수 있다.
titles = parse.find_all("div", {"class": "ellipsis rank01"})
singers = parse.find_all("div", {"class": "ellipsis rank02"})
albums = parse.find_all("div",{"class": "ellipsis rank03"})
title = []
singer = []
album = []
for t in titles:
title.append(t.find('a').text)
for s in singers:
singer.append(s.find('span', {"class": "checkEllipsis"}).text)
for a in albums:
album.append(a.find('a').text)코드 실행 결과
전체 코드는 다음과 같다.
import requests
from bs4 import BeautifulSoup
if __name__ == "__main__":
RANK = 100 ## 멜론 차트 순위가 1 ~ 100위까지 있음
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Trident/7.0; rv:11.0) like Gecko'}
req = requests.get('https://www.melon.com/chart/week/index.htm', headers = header) ## 주간 차트를 크롤링 할 것임
html = req.text
parse = BeautifulSoup(html, 'html.parser')
titles = parse.find_all("div", {"class": "ellipsis rank01"})
singers = parse.find_all("div", {"class": "ellipsis rank02"})
albums = parse.find_all("div",{"class": "ellipsis rank03"})
title = []
singer = []
album = []
for t in titles:
title.append(t.find('a').text)
for s in singers:
singer.append(s.find('span', {"class": "checkEllipsis"}).text)
for a in albums:
album.append(a.find('a').text)
for i in range(RANK):
print('%3d위: %s [ %s ] - %s'%(i+1, title[i], album[i], singer[i]))이를 실행하게 되면, 이걸 실행하는 지금은 2020년 3월 21일이기 때문에 http 요청을 보내는 해당 주소에 접속하게 되면 가장 먼저 뜨는 차트가 2020.03.09 ~ 2020.03.15 차트이다. 별도의 설정 없이는 접속 하자마자의 데이터를 뽑아오기 때문에 위의 코드를 다른 날에 실행한다면 결과는 다를 수 있다.
어쨌든 저걸 실행한 결과는 다음과 같다.

곡명, 가수명, 앨범명이 잘 나오는 것을 알 수 있다.
그 다음 해결해야 할 것
내가 굳이 이 크롤링을 하고자 한 것은 데이터의 방대한 양에 대한 문제도 있었지만, 앨범 아트를 꼭 구하고 싶은데 일일히 구글 검색을 하면서 신뢰할 수 있을 만한(나중에 가도 링크가 죽지 않을..) 사진의 링크를 구하기가 너무 힘들어서다. 적어도 멜론은 안죽겠지 ^^ 카카오가 먹여살리겠지 ^^
근데 음 여기서 난관에 봉착한게 이미지는 뭐 주소로 걸리는거 알고 있었는데 html 내의 javascript 코드를 이용하여 url이 던져지는 형식이었다. 다시 말하면 href = 함수이름(파라미터); 이런 식...
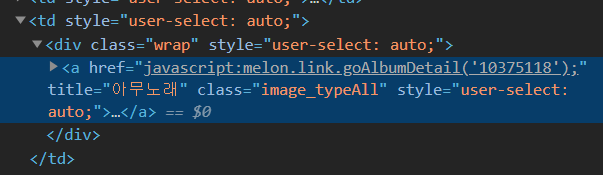
응 이거... 이게 그냥 크롤링을 갖다 뽑아먹으면 저 자바스크립트 함수 부르는 부분이 그대로 나오기 때문에 스크립트를 실행한 결과를 뽑아먹어야 하는데, 그건 다음 포스팅에서 알아보도록 하자..
참고 사이트
http://leechoong.com/posts/2018/python_webcrawling01/
https://rednooby.tistory.com/98

질문 좀 드려도될까요?